SkillOpt: Executive Strategy for Self-Evolving Agent Skills
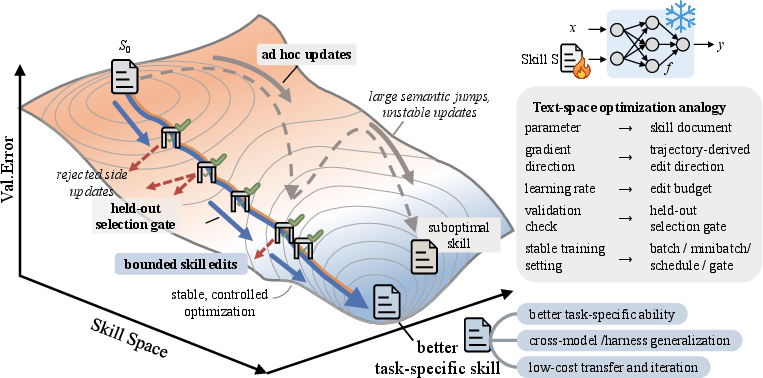
Abstract: Agent skills today are hand-crafted, generated one-shot, or evolved through loosely controlled self-revision, none of which behaves like a deep-learning optimizer for the skill, and none of which reliably improves over its starting point under feedback. We argue the skill should instead be trained as the external state of a frozen agent, with the same discipline that makes weight-space optimization reproducible. SkillOpt is, to our knowledge, the first systematic controllable text-space optimizer for agent skills: a separate optimizer model turns scored rollouts into bounded add/delete/replace edits on a single skill document, and an edit is accepted only when it strictly improves a held-out validation score. A textual learning-rate budget, rejected-edit buffer, and epoch-wise slow/meta update make skill training stable while adding zero inference-time model calls at deployment. Across six benchmarks, seven target models, and three execution harnesses (direct chat, Codex, Claude Code), SkillOpt is best or tied on all 52 evaluated (model, benchmark, harness) cells and beats every per-cell competitor among human, one-shot LLM, Trace2Skill, TextGrad, GEPA, and EvoSkill skills. On GPT-5.5 it lifts the average no-skill accuracy by +23.5 points in direct chat, by +24.8 inside the Codex agentic loop, and by +19.1 inside Claude Code. Transfer experiments further show that optimized skill artifacts retain value when moved across model scales, between Codex and Claude Code execution environments, and to a nearby math benchmark without further optimization.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces SkillOpt, a way to steadily improve an AI agent’s “skills” by editing a short, human‑readable instruction file instead of changing the AI’s internal code or retraining it. Think of a “skill” as a playbook the AI follows: how to look up information, how to use tools, what format to answer in, and what mistakes to avoid. SkillOpt acts like a disciplined coach that edits this playbook in small, careful steps whenever those edits actually help the AI do better.
The big questions the paper asks
- Can we improve an AI’s behavior by training its skill playbook (a text document) the same way we train models—carefully, step by step—rather than rewriting prompts at random?
- Can we make these improvements reliable and safe by only accepting changes that pass a separate test?
- Will this work across many kinds of tasks (like spreadsheets, documents, math, and games), different AI models, and different software environments?
- Do the learned skills transfer to other models and tasks without more training?
How SkillOpt works (in simple terms)
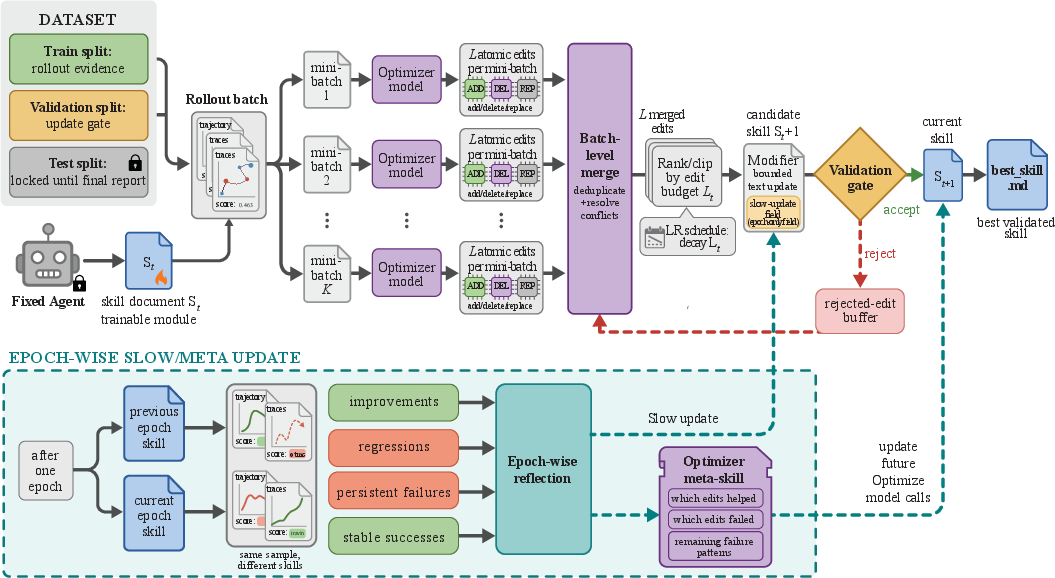
Imagine an AI agent playing many short practice games using its current playbook. A separate “coach” AI watches what happened and suggests small edits to the playbook. Only helpful edits get accepted. Here’s the loop:
- Practice rounds (rollouts): The agent tries a batch of tasks using its current skill playbook. This creates examples of what went right and wrong.
- Coach review (reflection): Another model reviews groups of successes and failures (like watching highlight reels) and proposes small, specific edits: add a rule, delete a bad rule, or replace a confusing one.
- Small steps (edit budget): There’s a limit on how many edits can be applied at once—like a “learning rate” for text—so the playbook doesn’t change too much too fast.
- Gatekeeper test (validation): The edited playbook is tested on a separate set of tasks it hasn’t practiced on. If performance improves, the edits stick; if not, edits are rejected.
- “What didn’t work” memory (rejected‑edit buffer): Rejected edits are remembered so the coach avoids repeating bad ideas.
- Slow, steady guidance (slow/meta update): After a chunk of time (an epoch), the system writes short “season notes” summarizing longer‑term lessons. These guide future edits without bloating the final playbook.
- Export the best playbook: The best‑performing version is saved as a compact text file (about 300–2,000 tokens) that can be reused.
Some simple translations:
- “Frozen agent” = the main AI model doesn’t change; only the skill text does.
- “Harness” = the environment the agent runs in (like direct chat, or code‑running tools).
- “Batch/minibatch” = reviewing a handful of tasks at a time, which helps spot patterns instead of chasing one-off mistakes.
A practical perk: once the skill is trained, deploying it adds zero extra model calls—just include the short skill text and run.
What did they test?
The authors tried SkillOpt on:
- Six types of tasks: question answering, spreadsheets, office document questions, document reading with images, math reasoning, and a virtual household game (ALFWorld).
- Seven different AI models, from big ones (frontier‑scale GPT) to smaller ones (Qwen).
- Three environments: direct chat, and two code‑tool harnesses (Codex and Claude Code).
Main results and why they matter
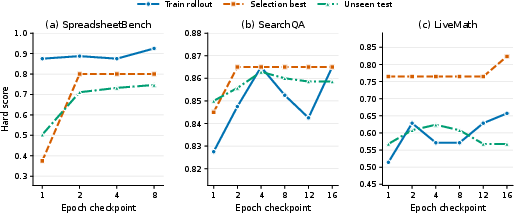
- Across 52 tested combinations (model × task × environment), SkillOpt was best or tied for best in all 52.
- On a strong model (GPT‑5.5) in direct chat, SkillOpt improved average scores by +23.5 points over using no skill. Inside tool loops, gains were +24.8 (Codex) and +19.1 (Claude Code).
- Biggest boosts were on procedural tasks that demand consistent rules and formats:
- Spreadsheet tasks roughly doubled in some cases (e.g., 41.8 → 80.7).
- Office document tasks saw large jumps (e.g., 33.1 → 72.1).
- Math tasks improved strongly too (e.g., 37.6 → 66.9).
- Transfer worked: a skill trained for one model helped smaller models; a skill trained in one tool environment helped in another; a math skill even helped on a nearby math benchmark—without more training.
Why this is important: It shows you can make an AI significantly more reliable on practical, step‑by‑step work by improving a small text playbook—no retraining, no risky giant prompt rewrites.
What design choices made SkillOpt work?
Here are the key ideas, each designed to keep learning steady and safe:
- Bounded edits (“textual learning rate”): Only a few changes per round, so improvements build rather than swing wildly.
- Validation gate: Changes only stick if they improve performance on a separate test set (to avoid overfitting to recent practice).
- Rejected‑edit buffer: The system learns from bad edits so it doesn’t repeat them.
- Minibatch reflection: The coach looks at sets of similar successes/failures to spot recurring rules, not one‑off fixes.
- Slow/meta update: Short, protected “season notes” keep long‑term lessons without cluttering the deployed skill.
A useful detail: All of this improves training stability and adds no extra cost at deployment time.
Takeaways and potential impact
SkillOpt turns a skill document into a trainable, auditable playbook for AI agents. This matters because:
- It upgrades an AI’s real‑world reliability without touching the model’s internals or weights.
- The final skill is short, readable text—easy to review for safety and policy compliance.
- It travels well: a skill tuned once can help other models and environments.
- It’s especially helpful for smaller models and for tasks with strict procedures (like tools, formats, and multi‑step workflows).
In the future, this approach could help teams:
- Build libraries of high‑quality, reusable skills for domains like spreadsheets, coding, or document processing.
- Share and audit skills across products and partners.
- Cut deployment costs by improving behavior through text, not retraining.
In short, SkillOpt is like giving AI agents a carefully trained playbook that keeps getting better—one safe, proven edit at a time.
Knowledge Gaps
Below is a concise, actionable list of the paper’s unresolved knowledge gaps, limitations, and open questions to guide future research.
- Token/compute cost and efficiency: No end-to-end accounting of optimization-time tokens, wall-clock time, or energy across models/harnesses; sample efficiency vs. performance trade-offs are not quantified.
- Statistical robustness: Results are reported as point estimates without confidence intervals, multiple random seeds, or significance testing; sensitivity to dataset split seeds and scoring noise is unexamined.
- Selection-set overfitting: Repeated validation-gated testing risks overfitting to the selection split; no safeguards (e.g., cross-validation, sequential tests, significance thresholds) or leakage analyses are provided.
- Convergence and stability theory: No formal guarantees or empirical diagnostics for convergence, cycling, or stability of bounded textual updates; conditions under which the optimizer reliably improves are unclear.
- Acceptance criteria: The “strictly greater” validation gate may stall under noisy scores; effects of tie-handling, statistical thresholds, or A/B-style tests for acceptance are unexplored.
- Objective design: The scalar reward compresses diverse desiderata (accuracy, latency, cost, safety); multi-objective or Pareto optimization of skills is not studied.
- Baseline parity: Compute/token budgets, optimizer capacity, and tuning effort are not matched or reported across baselines (e.g., GEPA, EvoSkill), leaving uncertainty about fairness of comparisons.
- Optimizer–target mismatch: How optimizer model scale/type affects outcomes, especially when weaker/cheaper optimizers are used, is only cursorily addressed; robustness to optimizer-target distribution mismatch remains open.
- Edit representation: Edits are add/delete/replace or rewrite; no exploration of richer, structured representations (sections, templates, DSLs) that could improve precision, verifiability, or composability.
- Edit budget metric: “Textual learning rate” is defined as edit count, not semantic distance; alternative distance metrics (token diff, section-level changes, constraint-preserving edits) are not evaluated.
- Negative feedback design: The rejected-edit buffer is epoch-local; persistence across epochs, prioritization schemes, or alternative memory mechanisms (e.g., replay, experience weighting) are not investigated.
- Catastrophic forgetting: Whether bounded edits still cause loss of previously acquired procedures is not measured; no retention/forgetting metrics or safeguards beyond slow/meta update are presented.
- Skill length and context budget: Deployment-time context usage vs. tool traces and long conversations is not quantified; compression/ablation of skill text to meet context limits is not studied.
- Safety and security: Risks of evolving unsafe, biased, or policy-violating procedures are unaddressed; defenses against prompt injection, tool-misuse, or adversarial trajectories are not integrated.
- Distribution and model drift: Robustness of optimized skills to evolving target models, toolchains, or domain drift over time (without re-optimization) is not evaluated.
- Generalization breadth: Transfer is shown for nearby tasks/harnesses; broader generalization (multilingual domains, longer-horizon software eng., complex multimodal or continuous-control settings) remains open.
- Real-world deployment: No user studies, human-in-the-loop trials, or operational metrics (MTTR, task success under realistic constraints) to validate practical utility and maintainability.
- Coverage and scoring: Reliance on exact-match or benchmark-specific hard scores may misalign with real utility; partial credit, verifier quality, and noisy labeling effects are not examined.
- Causal attribution: Gains are attributed to “procedural” improvements without causal tests; ablations that remove specific skill sections/rules to quantify their contribution are missing.
- Library-scale skills: The method targets a single compact skill; discovery, routing, and conflict resolution for multi-skill libraries and composition strategies are unstudied.
- Online adaptation: SkillOpt is offline with zero inference-time updates; feasibility and safety of online/on-the-fly adaptation with bounded edits and regret guarantees are open.
- Harness dependence: Success depends on harness instrumentation (traces, verifiers); portability to less-instrumented or proprietary environments and minimal evidence requirements are unclear.
- Acceptance gate brittleness: If selection sets are small or unrepresentative, harmful edits can pass or beneficial ones be rejected; adaptive batching or uncertainty-aware gates are not explored.
- Data contamination risk: Given frontier models, potential training-set overlap with benchmarks is not assessed; contamination audits and decontamination procedures are absent.
- Ethical/governance issues: Versioning, auditability at scale, rollback policies, and accountability for automatically evolved skills are not formalized.
- Joint training with weights: Interactions between skill optimization and parameter fine-tuning (SFT/LoRA), or alternating/joint training protocols, are untested.
- Offline data reuse: Using logged trajectories (off-policy evidence) vs. fresh rollouts for efficiency and safety is not explored; replay-buffer or batch RL analogues are absent.
- Robustness to reward hacking: Skills might exploit quirks of scorers/verifiers; mitigation (adversarial validation, metric ensembles, red-teaming) is not considered.
- Edit safety constraints: Aside from a protected slow-update field, no invariant constraints (e.g., non-deletable safety sections) are enforced during patching.
- Cross-lingual and accessibility: Performance and editing behavior in non-English contexts or for accessibility-oriented tasks are unreported.
- Reproducibility details: Some key implementation specifics (e.g., exact prompts, optimizer-call temperature, seed handling across all cells) and environment versions for Codex/Claude Code are not fully enumerated.
Practical Applications
Below is a concise mapping from the paper’s findings and methods to practical, real‑world applications. Each item names concrete use cases, target sectors, possible tools/products/workflows that could emerge, and key assumptions/dependencies that affect feasibility.
Immediate Applications
The following use cases can be deployed now using the paper’s harness-agnostic SkillOpt loop (resulting in a compact, auditable best_skill.md artifact) without changing model weights.
- Software engineering (software, developer tools)
- Use case: Project-specific code agent skills that enforce coding standards, test-first workflows, commit/message formats, and tool invocation policies inside IDE-like execution harnesses (e.g., Codex-/Claude Code-style sandboxes).
- Tools/products/workflows: A “Skill Registry” per repo; SKILL.md checked into version control; CI gating that only accepts skill edits that improve held-out tests; SkillDiff/SkillLinter for code review of skill patches.
- Dependencies/assumptions: Access to rollout data (e.g., execution traces), a deterministic test/selection split, and an optimizer model to propose bounded edits; adherence to security and privacy when sending traces to an optimizer.
- Spreadsheet and back-office automation (operations, finance, energy, supply chain)
- Use case: Agents that operate Excel/Google Sheets via Python runtimes with reliable formula usage, data validation, and strict output schemas (large gains on SpreadsheetBench suggest strong ROI).
- Tools/products/workflows: “Spreadsheet Skill Packs” for reconciliations, KPI reporting, budget variance analysis, energy meter aggregation, or inventory planning; versioned best_skill.md per workflow; execution harness adapters for enterprise RPA suites.
- Dependencies/assumptions: Instrumented harnesses (e.g., openpyxl/pandas runners), structured scoring for tasks, data governance for any sensitive spreadsheets.
- Document QA and retrieval-heavy workflows (legal, compliance, procurement, customer support)
- Use case: Domain skills for DocVQA/OfficeQA-like tasks—reference linking, section-aware extraction, citation style enforcement, redaction rules, and failure-mode checks.
- Tools/products/workflows: “Compliance Skill Profiles” that enforce formatting, PII redaction, and source-citation templates; validation-gated skill updates tied to a curated selection set; audit-ready skill artifacts.
- Dependencies/assumptions: Reliable scorers and curated evaluation sets; clear output schemas; governance for confidential documents in reflections.
- Customer support and knowledge operations (industry-agnostic; enterprise knowledge bases)
- Use case: Procedural skills for tool policies (search first, verify answer), output style constraints, escalation criteria, and self-check steps to raise exact-match/EM and customer resolution rates.
- Tools/products/workflows: SkillOps in LLMOps pipelines—batch rollouts against historical tickets, reflection minibatches, bounded edits, and held-out gating; skill versioning with rollback.
- Dependencies/assumptions: Access to representative historical tickets and outcome labels; policy approvals for using past interactions in optimizer prompts.
- Education and tutoring (education)
- Use case: Math and STEM tutoring agents with step-by-step verification, rubric-aligned formatting, and explicit error-check routines (paper’s LiveMath gains suggest value).
- Tools/products/workflows: “Curriculum Skills” per topic; skill libraries shared across model scales; classroom dashboards that A/B test skill revisions via validation gates.
- Dependencies/assumptions: Benchmarks/assessments mirroring target curricula; care to avoid overfitting to narrow exercises; content safety policies.
- Small-model augmentation and edge deployments (software, devices)
- Use case: Boost on-device or smaller LLMs by shipping optimized skills from larger-model optimization runs (positive cross-model transfer shown).
- Tools/products/workflows: “Skill Distillation Artifacts” distributed with lightweight models; periodic offline re-optimization on a larger optimizer model; device-side best_skill.md updates.
- Dependencies/assumptions: Stable cross-model transfer for target tasks; licensing permitting cross-provider optimization; memory/token budgets for skill context.
- Vendor/harness portability (platform strategy, procurement)
- Use case: Migrate agent workflows between execution environments (e.g., Codex ↔ Claude Code) while retaining learned procedures (demonstrated cross-harness transfer).
- Tools/products/workflows: A portability checklist and adapter interface; pre-migration rollouts to validate the skill in the new harness; vendor-neutral skill packaging.
- Dependencies/assumptions: Comparable tool availability and sandbox contracts across harnesses; adapter quality; consistent scoring functions.
- Model evaluation and LLMOps governance (industry, academia)
- Use case: Fair adaptation across models via a standardized, validation-gated skill training protocol; reproducible comparisons without weight changes.
- Tools/products/workflows: “Skill Gatekeeper” service that enforces held-out improvement; experiment tracking for accepted/rejected edits; publishable best_skill.md with benchmarks for transparency.
- Dependencies/assumptions: Public or internal benchmark splits; consistent evaluation harnesses; logging and privacy controls.
- Personal productivity assistants (daily life)
- Use case: Iteratively refine assistant behavior for email triage, calendaring, travel planning, or shopping by encoding procedural rules and formatting constraints into a personal skill.
- Tools/products/workflows: Personal “best_skill.md” managed like a config; periodic background optimization on user-approved rollouts; one-click rollback if validation doesn’t improve.
- Dependencies/assumptions: Opt-in data usage for personal content; simple local scoring heuristics (e.g., user corrections as labels); cost controls for optimizer calls.
Long-Term Applications
These require further research, integration, safety/scale work, or standardization beyond the current paper’s scope.
- Skill governance at enterprise scale (software, policy, compliance)
- Use case: End-to-end SkillOps with policy-as-code, change control, sign-offs, rollback, risk scoring, and continuous validation against regulatory suites.
- Tools/products/workflows: Signed skill artifacts; dependency graphs; “skill provenance” metadata; audit trails tying each edit to measured improvements and reviewers.
- Dependencies/assumptions: Standardized schemas for skills and edits; internal regulators and auditors; secure artifact registries; robust PII and trade-secret controls.
- Multi-skill orchestration and libraries (software, robotics, education)
- Use case: Composition and routing across interoperable skills—conflict resolution, priority rules, and curriculum/competency-based selection.
- Tools/products/workflows: Skill routers, ensembling and meta-optimizers that learn which skill to apply per context; “Skill Marketplace” with sector-specific packs.
- Dependencies/assumptions: Skill metadata standards (applicability conditions, tool policies); routing benchmarks; safe composition rules.
- Continual/lifelong skill learning with drift detection (industry, finance, healthcare)
- Use case: Always-on monitoring that triggers bounded skill updates when task distributions shift (seasonality, policy changes, product updates).
- Tools/products/workflows: Drift detectors; scheduled re-optimization; shadow validation gates; differential privacy for live data reflections.
- Dependencies/assumptions: Reliable online metrics; safe access to live trajectories; guardrails to prevent catastrophic regressions.
- Safety certification and formal verification of skill edits (healthcare, finance, safety-critical systems)
- Use case: Certifiable skill changes via static/dynamic analysis, red-team suites, and formal constraints that bound behavior (e.g., tool calls, data egress).
- Tools/products/workflows: “Skill Contracts” with verifiable invariants; conformance tests integrated into validation gates; model-agnostic safety checkers.
- Dependencies/assumptions: Sector standards (e.g., HIPAA/FDA, SOX/SEC); certifying bodies’ acceptance of text-artifact audits; robust red-team datasets.
- Healthcare and clinical operations (healthcare)
- Use case: EHR-integrated skills for documentation, coding, prior authorization, and guideline-conformant summarization with strict output templates.
- Tools/products/workflows: Hospital-specific best_skill.md with tool policies for EHR APIs; offline optimization using de-identified logs; validation on clinician-curated sets.
- Dependencies/assumptions: Regulatory approvals; de-identification pipelines; alignment with clinical safety practices; secure on-prem deployments.
- Financial decision support and compliance (finance)
- Use case: KYC/AML document workflows, report generation, and policy-constrained tool usage; later, cautious extensions to semi-automated decision pipelines.
- Tools/products/workflows: “Regulatory Skill Profiles” aligned to internal controls; continuous validation against synthetic and historical cases; immutable audit artifacts.
- Dependencies/assumptions: Regulator acceptance of validation-gated text artifacts; strong human-in-the-loop sign-off; sandboxed execution for tool calls.
- Real-world embodied agents and robotics (robotics, manufacturing, logistics)
- Use case: Procedural skills for tool use, safety checks, and recovery behaviors in physical environments; sim-to-real transfer of best_skill.md with on-robot validation gates.
- Tools/products/workflows: Bridged harness adapters from simulators to robot stacks; safety interlocks tied to validation; episodic logs for reflection minibatches.
- Dependencies/assumptions: High-fidelity scoring and safe testing in the real world; latency and reliability constraints; integration with robot safety standards.
- Government and standards bodies (policy)
- Use case: Procurement standards that require vendors to ship auditable skill artifacts, change histories, and validation procedures; open public skill libraries for civic tasks.
- Tools/products/workflows: “Skill SBOM” (software bill of materials) for agent procedures; conformance test suites; public registries of certified skills.
- Dependencies/assumptions: Consensus on schemas and certification protocols; privacy-respecting sharing; ongoing maintenance funding.
- Edge and multimodal expansions (devices, media, accessibility)
- Use case: Skills that govern multimodal tool policies (vision, speech) for document capture, accessibility workflows, and on-device assistants.
- Tools/products/workflows: Multimodal reflection contexts; device-friendly skill compaction; offline validation packs.
- Dependencies/assumptions: Stable multimodal harness adapters; efficient on-device scoring; privacy-preserving optimization.
- Tool marketplace integration and dynamic tool selection (software ecosystem)
- Use case: Skills that learn tool-selection policies across changing catalogs; safe, optimization-driven adoption of new tools with validation-gated edits.
- Tools/products/workflows: Tool capability schemas; “tool policy” sections in skills; auto-generated A/B sandboxes for new tools.
- Dependencies/assumptions: Reliable tool metadata; marketplace trust and security; robust fallback behavior on tool failures.
Notes on cross-cutting assumptions
- Requires an optimizer model to propose bounded edits, scored rollouts for evidence, and a reliable selection/validation split to gate updates.
- Data privacy and compliance are critical—reflection contexts and trajectories must be handled under appropriate policies.
- Transferability depends on harness parity and tool availability; portability may require adapters and careful score alignment.
- Cost/latency constraints apply: rollouts and optimizer calls should be budgeted; small models benefit from imported skills but may need careful token budgeting for context.
Glossary
Agent skill: A transferable policy expressed in natural language to enhance procedural adaptation of agents across different domains. Example: "Agent skills today are hand-crafted, generated one-shot, or evolved through loosely controlled self-revision."
Bounded text updates: Controlled modifications to a skill document, limited by a textual learning rate, to ensure gradual and stable improvements. Example: "The learning-rate analogue in SkillOpt is the edit budget : the maximum number of skill edits applied at step ."
Codex harness: An execution environment where the target model performs tasks in a Codex CLI sandbox, evaluating and scoring skill application. Example: "SkillOpt renders the current skill to a per-task SKILL.md alongside task files and reads back a compact execution trace (codex_trace_summary.txt)."
Claude Code harness: An execution platform allowing task execution and scoring, similar in function to the Codex harness, but specific to the Claude toolset. Example: "The Claude Code harness mirrors the same workspace contract through the claude CLI."
Deep-learning optimizer: A system or model employing techniques inspired by deep learning to optimize skills, characterized by controlled edits and validation. Example: "None of which behave like a deep-learning optimizer for the skill."
Execution harness: The operational environment where agent skills are applied and their effects executed and verified, including direct chat and tool-based platforms. Example: "We evaluate SkillOpt on six benchmarks... under three execution modes (direct chat, Codex harness, Claude Code harness)."
Epoch-wise slow/meta update: A periodic adjustment process that incorporates longitudinal performance insights to refine skill learning consistently across epochs. Example: "The epoch-wise slow/meta update retains longer-horizon lessons."
Meta skill: Guidance information extracted from optimization history, used internally by the optimizer to enhance future edits. Example: "The meta skill is optimizer-side only. It summarizes which edit patterns helped, which were rejected, and which failures persisted across epochs."
Reflection minibatch: A subset of evidence collected during skill execution, used to derive procedural insights and generate informed skill edits. Example: "It first separates failures from successes and partitions each group into reflection minibatches."
Skill artifact: A tangible output of the optimization process, containing validated and reusable procedural instructions for agents. Example: “Learned artifacts also transfer...across model scales, between Codex and Claude Code execution environments.”
Skill document: A portable natural-language asset embedding agent procedures, heuristics, and policies, enabling adaptation without altering model weights. Example: "A skill is a portable natural-language artifact that packages procedures, domain heuristics, tool policies, output constraints, and failure modes."
Textual learning-rate budget: Parameter controlling the extent of edits made during skill optimization, analogous to learning rate in model training. Example: "The learning-rate analogue in SkillOpt is the edit budget : the maximum number of skill edits applied at step ."
Trajectory batch: A collection of task executions under a current skill, forming the basis for proposing edits during the optimization process. Example: "At each optimization step, the target model runs a rollout batch from $D_{\mathrm{tr}$ with the current skill."
Validation gate: A mechanism to assess and approve skill edits, ensuring only beneficial modifications are kept, akin to a validation step in training. Example: "Every candidate skill is evaluated on $D_{\mathrm{sel}$... If it improves over the current selection score, it becomes the new current skill."
Collections
Sign up for free to add this paper to one or more collections.