- The paper introduces COALA, a convex reformulation method that transforms LLM preference alignment into a tractable optimization problem on a single GPU.
- It employs a convex two-layer neural network and the Bradley-Terry model with ADMM-based optimization, ensuring stable, globally optimal reward improvements.
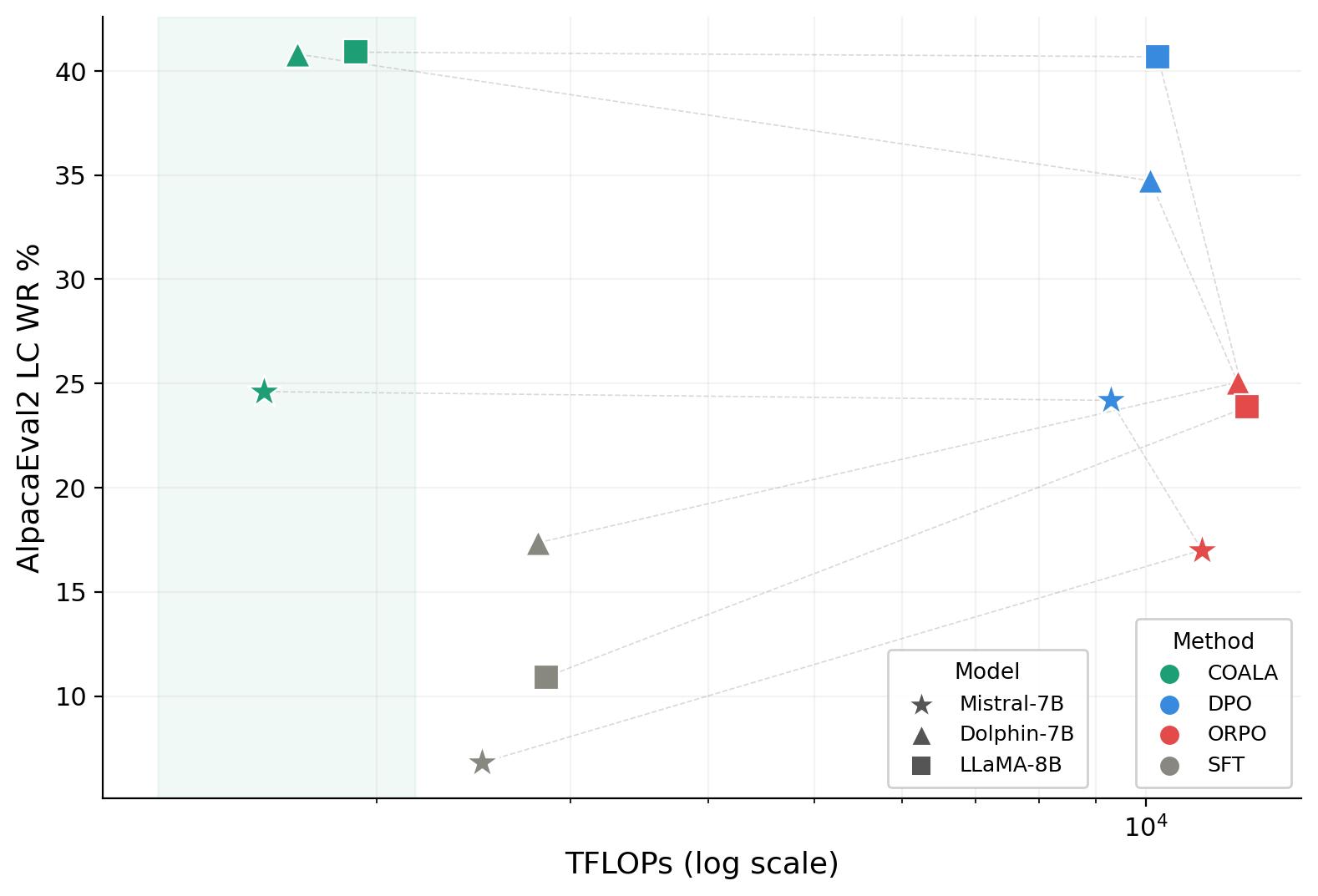
- Empirical results demonstrate COALA’s efficiency, achieving competitive alignment with only ~17.6% of DPO’s compute requirements and enhanced human-consistency.
Convex Optimization for Preference Alignment: The COALA Algorithm
Introduction
This work presents COALA (Convex Optimization for Alignment and Preference Learning Algorithm) (2605.23244), a novel framework for efficient alignment of LLMs via convex optimization techniques. COALA specifically targets the critical limitations of prevalent preference-tuning methods—such as RLHF and DPO—by offering a theoretically grounded, reference-free, and single-GPU-compatible alternative that eliminates non-convexity, reduces VRAM consumption, and dramatically cuts training computation without compromising reward alignment or human consistency.
COALA’s innovation is built upon convex reformulations of two-layer ReLU neural networks. By leveraging advances in convex analysis for neural architectures, particularly results showing that two-layer networks with ReLU activations and weight decay regularization can be formulated as convex programs, the authors re-architect the policy learning step in preference alignment into a tractable convex optimization problem. This is accomplished by:
- Stacking a convex two-layer neural network (cvxNN) atop a frozen, pre-trained LLM feature extractor.
- Reformulating the alignment loss, based on the Bradley-Terry preference model, into a convex minimization over the parameters of the convex head (while keeping the base LLM and the first layer of cvxNN frozen).
This theoretical backbone enables global optimality in training, mitigates the sensitivity to hyperparameters, and ensures robust monotonic reward improvements—addressing a persistent problem in prior heuristic-driven approaches like DPO and ORPO.
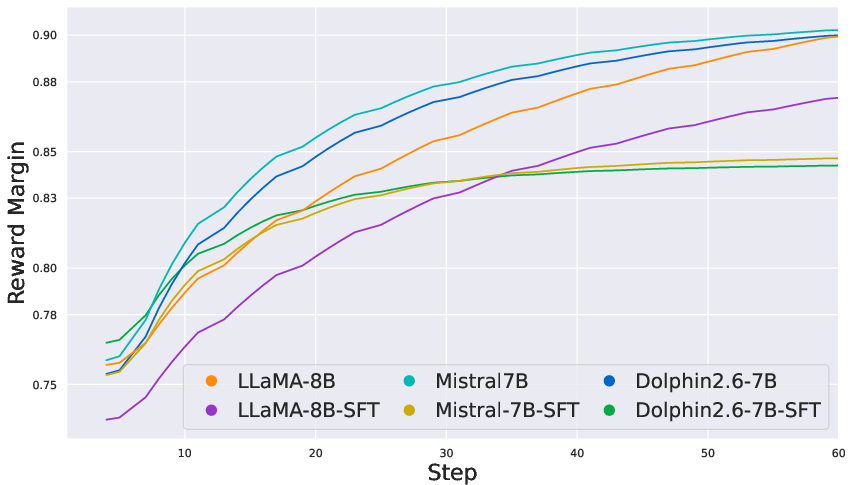
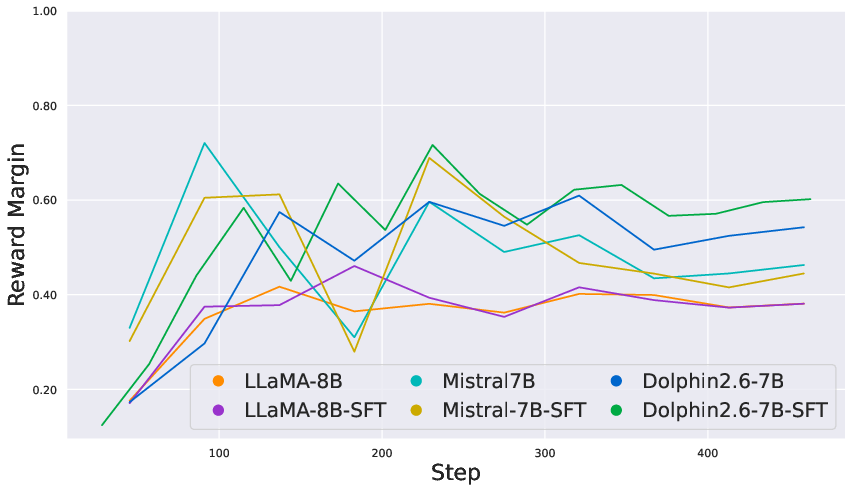
Figure 1: Overview of the COALA pipeline: feature extraction from a frozen LLM, convex head stacking, and preference optimization via convex methods.
Convex Preference Learning with COALA
Unlike DPO, which requires maintaining both a policy and a reference model (incurring 2× the VRAM and coupling training stability to brittle learning rates), COALA eliminates the reference requirement and transforms the preference optimization problem into a smooth, convex logistic regression over preference triplets. The methodology can be summarized as follows:
- Feature Extraction: The pre-trained LLM extracts features per input.
- Convex Policy Head: A two-layer cvxNN scores these features for pairwise preferences.
- Preference Loss: The preference loss becomes a convex logistic objective as per the Bradley-Terry model, which is solved with ADMM (via CRONOS).
- Training Regime: Only the convex head’s output weights are optimized, guaranteeing polynomial-time convergence and addressing the inefficiency, inconsistency, and unreliability of standard DPO.
The authors provide proofs for the convexity of the program and derive convergence guarantees, showing that (i) Stage I (cvxNN pretraining) converges ergodically at rate O(1/k) (via CRONOS/ADMM), and (ii) Stage II (final logistic regression fine-tuning) achieves the optimal O(1/k2) rate for smooth convex objectives.
Empirical Validation
COALA is validated extensively on four preference datasets (including the novel EduFeedback corpus with over 26,000 conversations and 65,000 preference pairs via a sample-efficient Alternating Population Strategy) and six LLMs ranging from DistilGPT-2 to Llama-3.1-8B. All experiments are conducted with fair resource assignment (single A100 for baselines, single RTX-4090 for COALA).
Key empirical findings include:
- Stable Reward Monotonicity and Consistency: COALA yields stable, consistently increasing reward margins throughout optimization, unlike DPO/ORPO which exhibit high noise and frequent collapses during training.
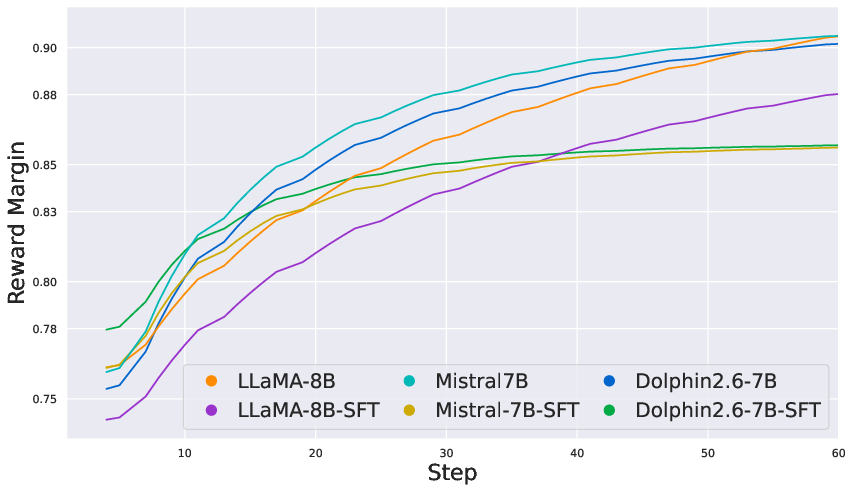
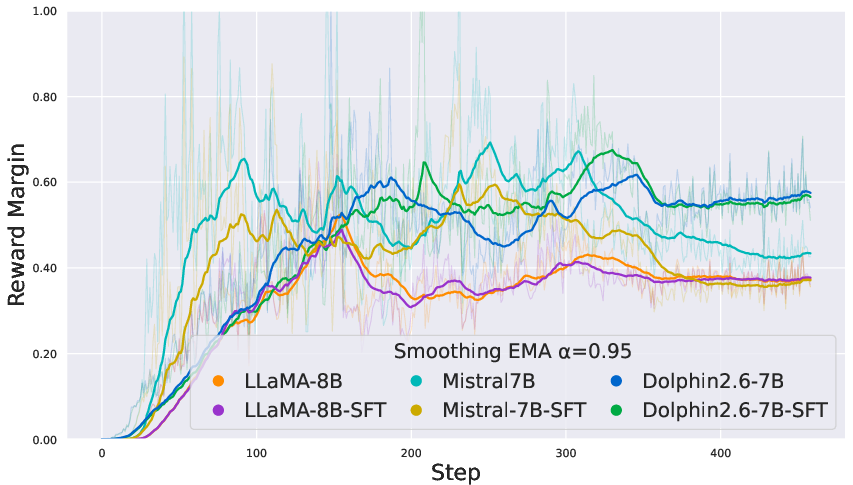
Figure 2: COALA’s reward margins on IMDb show stable and monotonic improvement, in contrast to DPO’s instability.
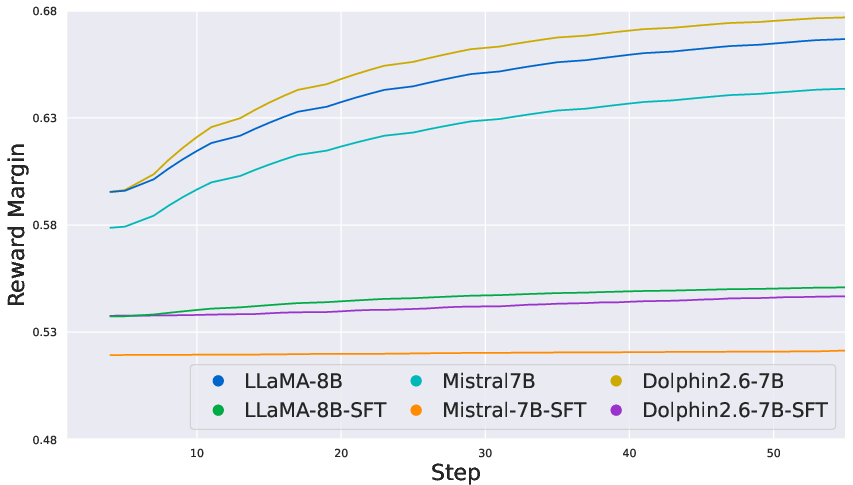
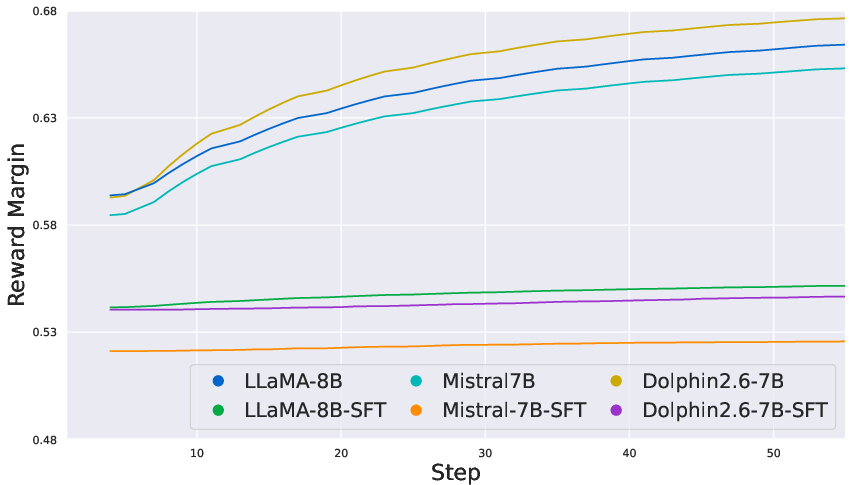
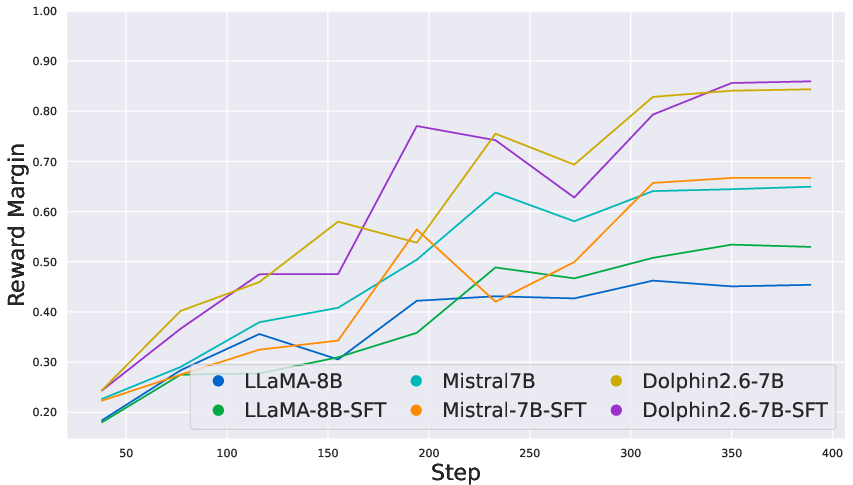
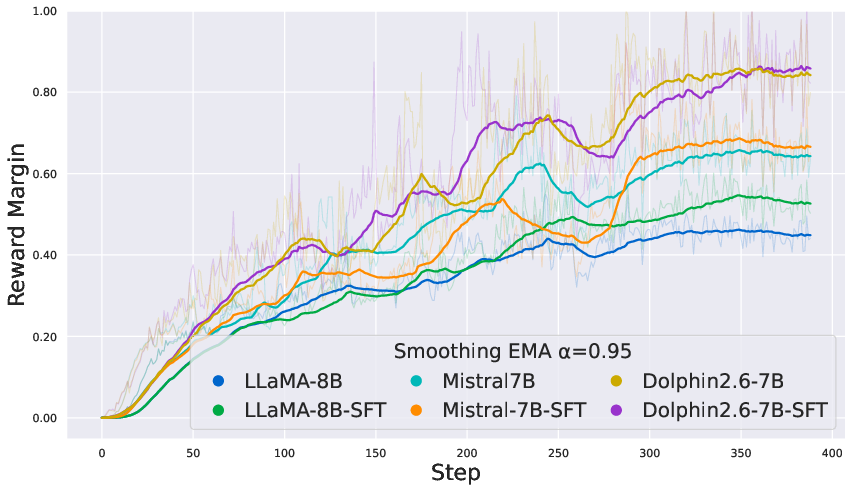
Figure 3: On the custom EduFeedback preference dataset, COALA maintains smooth reward gains while DPO remains volatile.
Dataset and Data Efficiency Innovations
A central contribution is the Alternating Population Strategy for dataset extraction, used to generate orders of magnitude more preference pairs from the same corpus without recourse to external LLMs or reward models. This approach, strictly utilized for the EduFeedback dataset, allows for scalable, sample-efficient preference data construction, though the authors acknowledge its dependence on objective, dialog-driven tasks and potential limitations for domains with less conversational structure.
Analysis of Expressiveness and Limitations
An explicit architectural tradeoff is acknowledged: COALA’s convex head is globally optimal with respect to the extracted features from the frozen LLM, but freezing the backbone may limit learning when alignment tasks demand deep, structural representational shifts. Nevertheless, the empirical results suggest that for objective and pedagogical alignment tasks—those targeting direct response helpfulness, factuality, or sentiment—the expressiveness of the frozen LLM is typically sufficient, and the convex head furnishes robust, efficient preference alignment without requiring expensive full-model tuning.
Practical and Theoretical Implications
COALA’s paradigm-shift—preference alignment as a convex task over frozen representations—carries several concrete implications:
- Resource Democratization: Single-GPU feasibility expands the accessibility of preference-aligned LLMs, making research and deployment practical for smaller labs and edge users.
- Reduction in Alignment Overheads: The removal of dependence on heuristic tuning, reference models, or compute-intensive grid search streamlines the alignment pipeline.
- Guaranteed Optimization Behavior: Theoretical convergence rates and global optimality significantly de-risk fine-tuning, vital for both reliable deployment and reproducibility in preference optimization research.
- Transfer to Other Modalities and Tasks: The convex stacking mechanism and ADMM-based large-scale optimization are transferable to multimodal architectures and can be extended toward plug-and-play alignment modules.
Conclusion
COALA establishes that convex optimization methods can be leveraged to yield efficient, robust, and human-aligned LLM preference tuning—facilitating both theoretical rigor and practical deployment. Its demonstration of strong real-world alignment on four diverse datasets, efficient compute usage, and stable convergence opens avenues for scalable, democratized, and reproducible alignment research. Further work should extend this approach to more general forms of alignment (including more expressive or creative tasks), investigate integration at inference-time, and push the boundaries of interpretability by linking convex head features to learned preference representations.