- The paper introduces Live Music Diffusion Models by decoupling clean context from noisy target frames, enabling efficient KV-Caching and 20–25% speedup per forward pass.
- The methodology applies custom attention masks and ARC-Forcing for RL-free post-training, effectively mitigating error accumulation over long musical rollouts.
- Empirical results show that LMDMs outperform autoregressive systems in inference efficiency and controllability, supporting real-time interactive music generation on modest hardware.
Live Music Diffusion Models: Efficient Architectures and RL-Free Post-Training for Interactive Music Generation
Motivation and Background
The paper "Live Music Diffusion Models: Efficient Fine-Tuning and Post-Training of Interactive Diffusion Music Generators" (2605.22717) addresses a persistent challenge in generative audio modeling: reconciling high-fidelity, controllable music generation with the computational efficiency and latency requirements of real-time musical interaction. Autoregressive discrete-block models, exemplified by state-of-the-art Live Music Models (LMMs), have offered substantial musical quality and control but are bottlenecked by extreme resource demands—often several billion parameters and prohibitive VRAM requirements for local inference and streaming.
Diffusion-based approaches, particularly latent DiT models, have proven more tractable in parameter count and enjoy broad adoption in open-source communities. However, standard diffusion architectures remain fundamentally non-streamable, due to full bidirectional attention across temporal blocks and lack of caching strategies comparable to KV-Caching in AR transformers. The paper both defines and resolves these inefficiencies, enabling diffusion models to match and outperform discrete-AR systems regarding inference complexity, controllability, and streamability.
Live Music Diffusion Models: Architectural Innovations
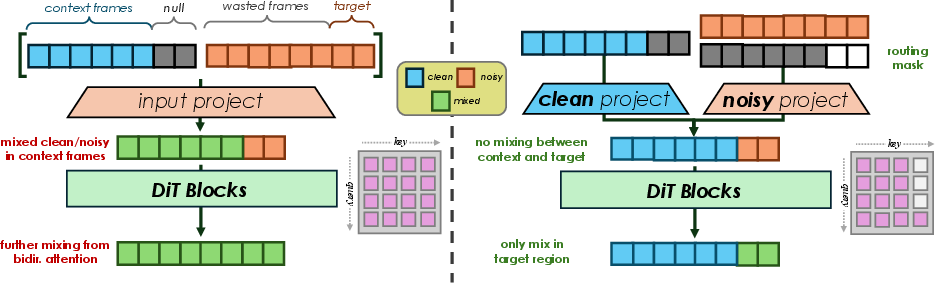
The primary contribution is the introduction of Live Music Diffusion Models (LMDMs), which enable streaming and real-time generation on consumer hardware by applying principled routing of clean context and noisy target frames combined with bespoke attention patterns. The core modification involves separating projections for past (clean) context and present (noisy) targets, along with custom attention masks which enforce strict causality and prevent clean context encoding from being influenced by noisy target frames.
Standard block-AR diffusion concatenates clean and noisy states, allowing full bidirectional attention and prohibiting caching, since the context encoding changes in every block (Figure 1).
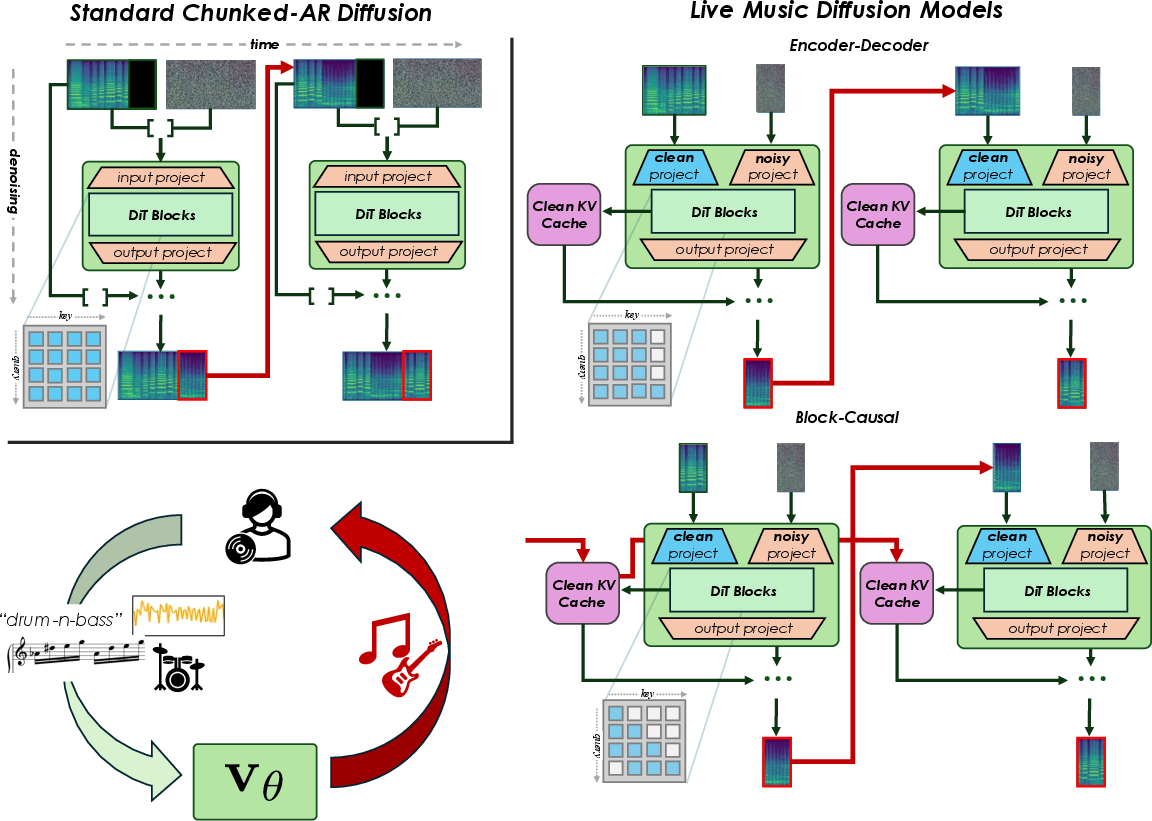
Figure 1: LMDMs route clean context and noisy target frames through separate projections and use custom attention masks, enabling KV-Caching and efficient interactive generation on consumer-grade hardware.
This routing enables inference schemes analogous to encoder-decoder architectures in text models: clean context frames are encoded once, and target frames are decoded iteratively across diffusion steps using cached key/value pairs, enabling a 20–25% speedup per forward pass. Two principal LMDM variants are provided:
ARC-Forcing: RL-Free Rollout-Based Post-Training
To address error accumulation—a known train-test mismatch in AR and diffusion models where successive generations compound drift—the paper introduces ARC-Forcing, combining Self-Forcing from video diffusion with the Adversarial Relativistic Contrastive (ARC) loss. The approach circumvents reward models and RL, leveraging the differentiability of diffusion sampling to perform adversarial rollout-based post-training.
ARC-Forcing entails generating multi-block musical rollouts from a distilled generator Gϕ using KV-Caching, then passing these alongside real music samples (with matched context and caption) into a bidirectional discriminator Dψ. The discriminator is trained on both a relativistic adversarial loss (comparing generated vs. real rollouts) and a contrastive loss (real music with correct vs. mismatched captions), providing supervision on global structure and text adherence (Figure 3).
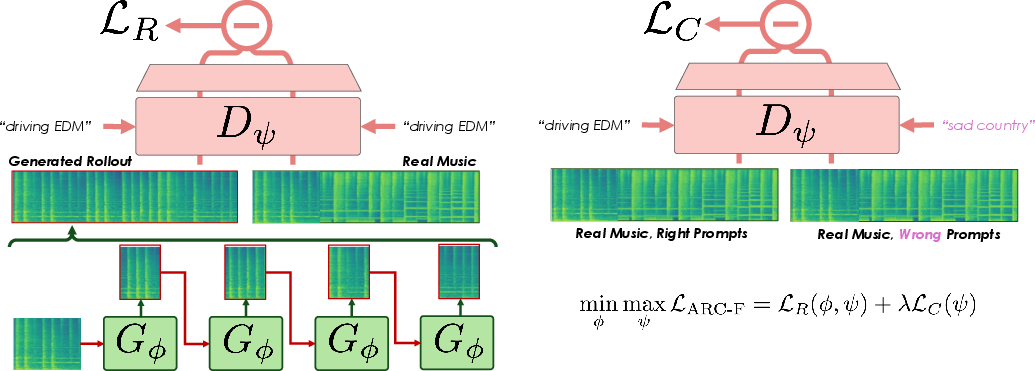
Figure 3: ARC-Forcing pipeline: Rollouts generated with KV Caching are evaluated by a bidirectional discriminator using relativistic and contrastive objectives.
ARC-Forced models stably support sampling in 1–8 steps without CFG and reduce round-trip latency for block generation to ≈30ms.
Controllability and Multi-Modal Conditioning
LMDMs are highly flexible in conditioning modalities. The models accommodate global text prompts (as in text-to-music), instrument-like sketch controls (variable pitch and dynamics sketches), and accompaniment-like conditioning (using separate audio streams as context). The architecture fully generalizes over control types without restrictions on their dimensionality or timing.
This generalization supports variable-length prompt transitions, local sketch controls, and multi-stem accompaniment with fixed future visibility to mitigate latency (Figure 4).
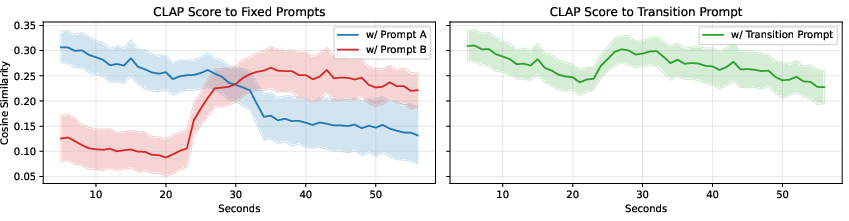
Figure 4: Enc-Dec LMDMs perform smooth transitions between prompt conditions, supporting real-time modulation of musical controls.
Empirical Results
LMDMs—finetuned and ARC-Forced—demonstrate strong numerical performance:
- Text-Conditioned Generation: LMDMs achieve competitive FD, KL, and CLAP scores relative to AR systems, but with drastically reduced D-NFE and TTFF. Encoder-Decoder LMDMs consistently outperform Block-Causal in text adherence and quality when primed with audio.
- Error Accumulation: Without ARC-Forcing, metrics degrade substantially over long rollouts; ARC-Forcing achieves significant mitigation of error accumulation (Figure 5).
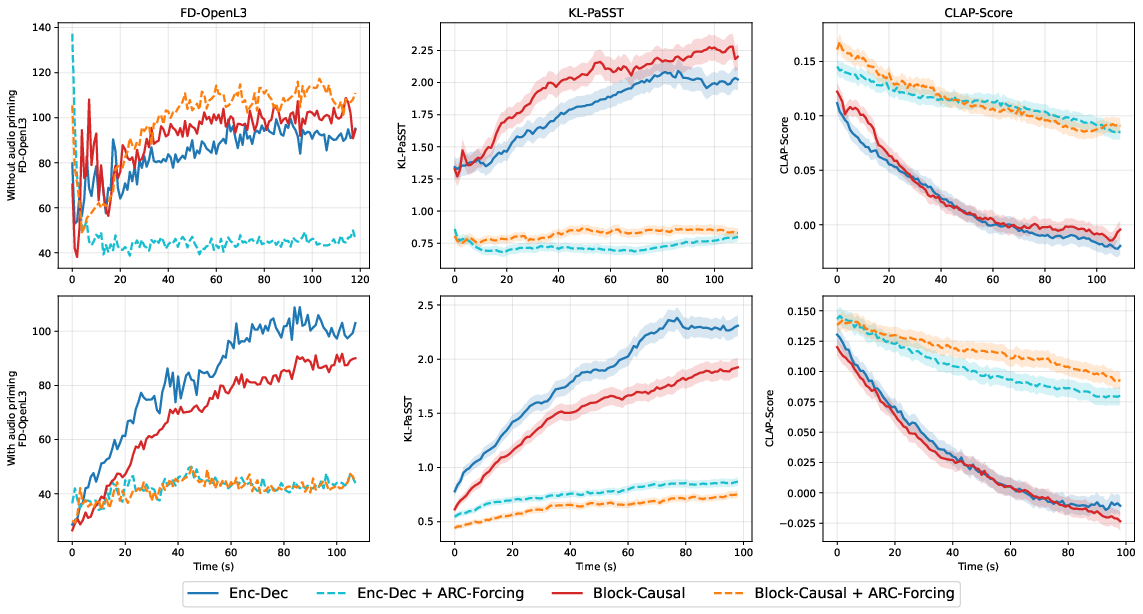
Figure 5: ARC-Forcing minimizes metric degradation over time, maintaining consistent output quality and control alignment across rollouts.
- Prompt Transitions: Enc-Dec LMDMs, with modifications to context drop and CFG++, enable prompt transitions equivalent to AR baselines.
- Accompaniment and Sketch-Based Generation: LMDMs maintain high inter-stem alignment (CoCoLA) even with reduced future visibility, outperforming prior streaming models. Sketch-conditioning yields comparable control following to bidirectional offline models.
- Live Interaction: LMDMs, exported via ONNX and deployed in C++/JUCE, operate as generative effects with Δ<1s latency on consumer-grade GPUs, supporting live musical improvisation and generative delay effects (Figure 6).
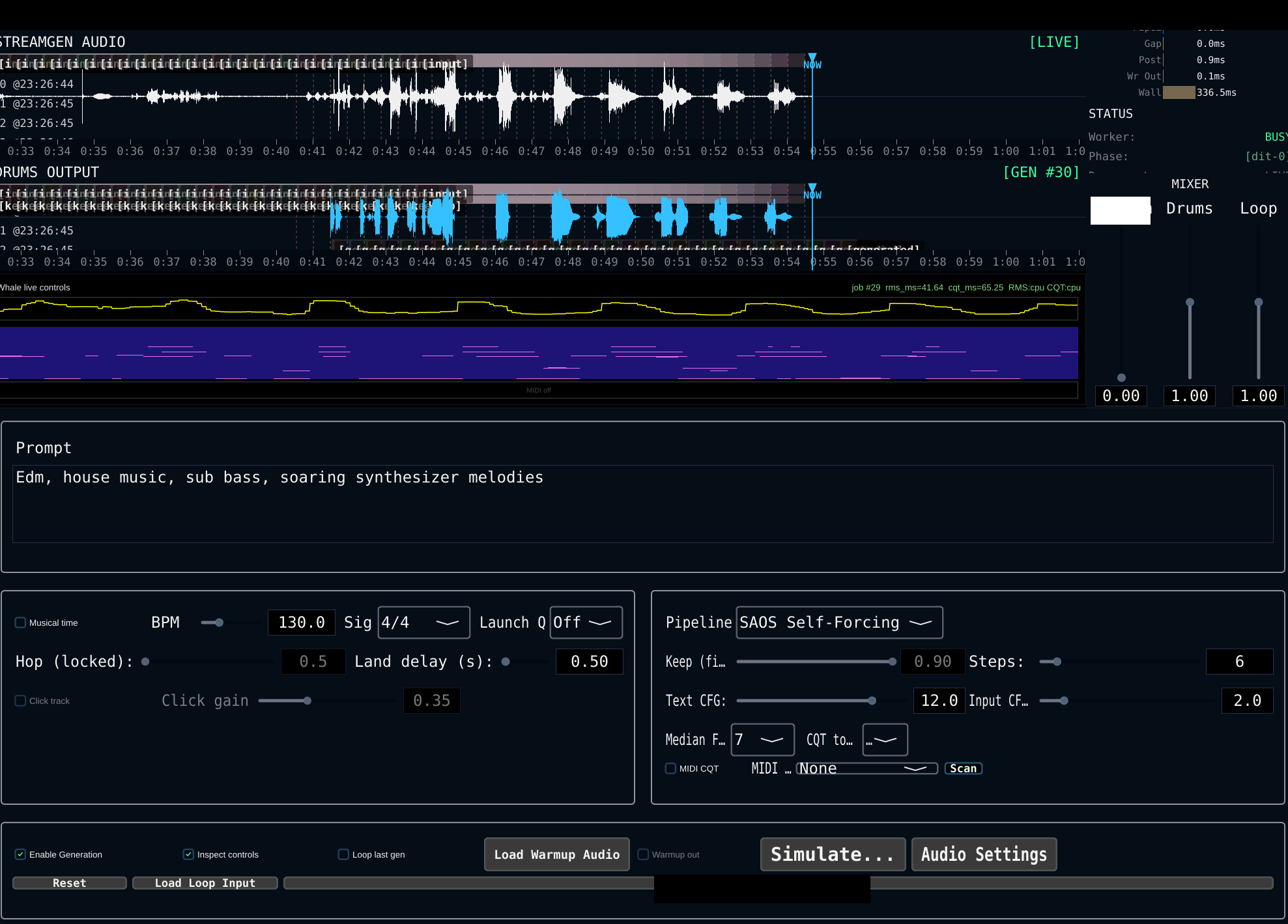
Figure 6: The JUCE-based user interface for live interactive sessions employing LMDMs as generative musical effects.
Deployment and User Studies
Instrumentalists participating in live sessions report that LMDMs function as musical partners, responding dynamically to input while introducing new ideas reminiscent of collaborative improvisation. Timbral explorations reveal nuanced responses to pitch and dynamics. Challenges remain in text-following under deployment pipelines, particularly in domains with uninformative controls.
Implications, Limitations, and Future Directions
The research asserts—contradicting prevailing intuition—that diffusion models, often dismissed as fundamentally non-streamable, can be architected not only to match but outperform autoregressive systems in terms of inference complexity, particularly for live music applications on consumer hardware. The KV-Caching and ARC-Forcing paradigms are generalizable to other generative tasks requiring real-time, multi-modal control and extension beyond music.
Practically, the work enables accessible generative instruments that foreground musician interaction, moving away from monolithic, offline song generation toward toolkits for live co-creation. Theoretical implications include the disentangling of context encoding from noisy generation via attention masks, promoting separation of inference and decoding steps.
Future research should further decrease block sizes and latency, refine text adherence during live deployment, and pursue more general caching schemes (e.g., layer-wise, spatial, and temporal) for even lower resource requirements. Advances in causal codecs and compressed latent representations are needed for millisecond-level live co-performance.
Conclusion
The paper demonstrates that simple architectural modifications to latent diffusion models—routing, custom attention masking, and ARC-Forcing adversarial post-training—enable efficient streaming music generation with competitive quality and strong controllability. LMDMs operate as generative musical instruments suitable for real-time collaboration, running locally on modest hardware. This work opens new directions in AI music generation emphasizing live musician partnership, efficient inference, and flexible multi-modal controls (2605.22717).