Self-Policy Distillation via Capability-Selective Subspace Projection
Abstract: Self-distillation bootstraps LLMs by training on their own generations. However, existing methods either rely on external signals to curate self-generated outputs (e.g., correctness filtering, execution feedback, and reward search), which are costly and unavailable for the best-performing frontier models, or skip curation entirely and train on all raw outputs, an approach that is often domain-specific and hard to generalize. Both also share a deeper weakness that self-generated outputs entangle task-relevant capability with others, such as stylistic patterns, formatting artifacts, and model-specific errors, diluting the signal for the specific capability one aims to improve. In this paper, we propose Self-Policy Distillation (SPD), which achieves generalizable, capability selective without any external signal. Specifically, SPD extracts a low-rank capability subspace from the model's own gradients on correctness-defining tokens, projects key-value (KV) activations into this subspace during self-generation, and fine-tunes on the resulting raw outputs with standard next-token prediction loss. Through extensive experiments across code generation, mathematical reasoning, and multiple-choice QA, we show that SPD achieves up to 13% improvement over state-of-the-art self-distillation methods without external signals and up to 16% improvement over pre-trained baselines. Notably, SPD demonstrates superior generalizability, achieving 15% better performance under out-of-domain generalization settings.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
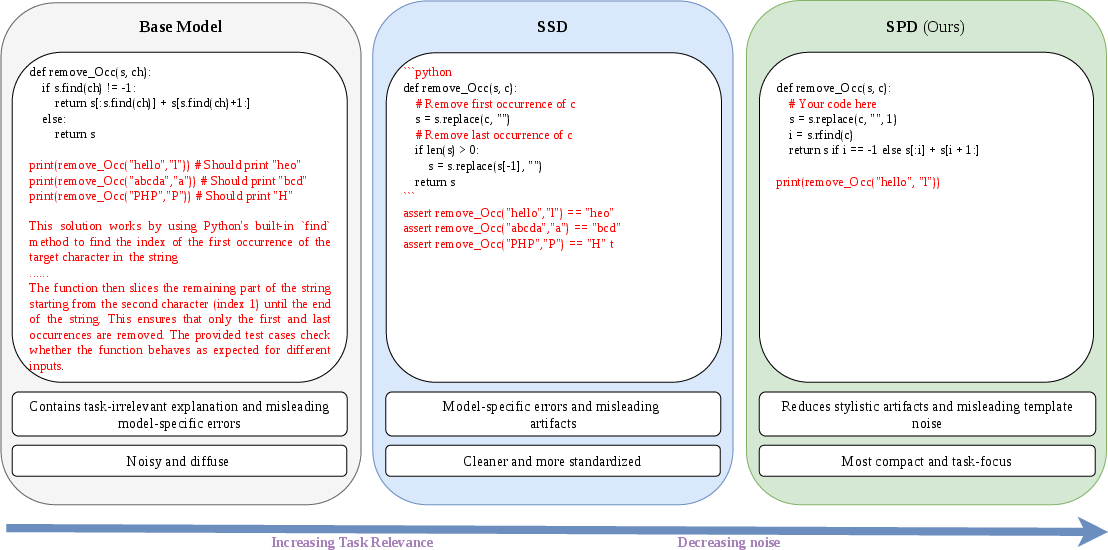
This paper introduces a new way to help LLMs improve themselves, called Self-Policy Distillation (SPD). Instead of needing extra tools or teachers to judge the model’s answers, SPD teaches the model using its own outputs while gently steering those outputs to focus on the most important parts of the task. The idea is to keep the helpful skills (like accurate reasoning) and avoid learning bad habits (like wordy explanations or formatting quirks).
Key Objectives and Questions
The paper asks a simple question: How can an LLM improve by training on its own answers without any outside help, while still learning useful skills that work across different kinds of tasks?
To do this, the authors aim to:
- Select the parts of the model’s “thinking” that most affect getting the right answer.
- Use those parts to guide the model’s self-generated training data.
- Show that this makes the model better not just on the original task (like coding), but also on other tasks (like math and multiple-choice questions).
Methods Explained Simply
Think of training a model like practicing for a test. You can learn from your own practice answers, but you should focus on the parts that actually decide whether your answer is correct—not the extra fluff. SPD does exactly that in two phases.
Here are the main ideas behind SPD, explained with everyday language:
- Correctness-defining tokens: These are the exact pieces of the model’s output that make the answer right or wrong. For example:
- In math, the final number or the key steps.
- In code, the function body that solves the task.
- In multiple-choice, the chosen letter.
- SPD looks closely at these (instead of every single token) to understand what matters for correctness.
- Gradients: A gradient shows how much each part of the model changes when it tries to fix its mistakes. You can imagine gradients as arrows pointing toward “what to adjust” to be more correct.
- Key and Value activations (“KV activations”): In a transformer (the type of model LLMs use), attention works like a smart “lookup system.” Keys are like labels for information, and Values are the information itself. SPD focuses on the model’s Keys and Values—its internal notes about “what to pay attention to.”
- SVD (Singular Value Decomposition): This is a math tool that finds the most important directions in a big set of arrows (the gradients). Imagine you have a bunch of arrows pointing in many directions; SVD finds the few main directions that matter the most. This gives a “capability subspace,” a small, focused area that captures the skill we want (like solving math accurately).
- Projection hooks: These are temporary “filters” placed inside the model. When the model generates text, the hooks nudge its internal notes (Keys and Values) to stay within the useful capability subspace. The model’s weights aren’t changed; it’s more like wearing glasses that sharpen your focus while you write your answer. After generating training data with these glasses, the hooks are removed.
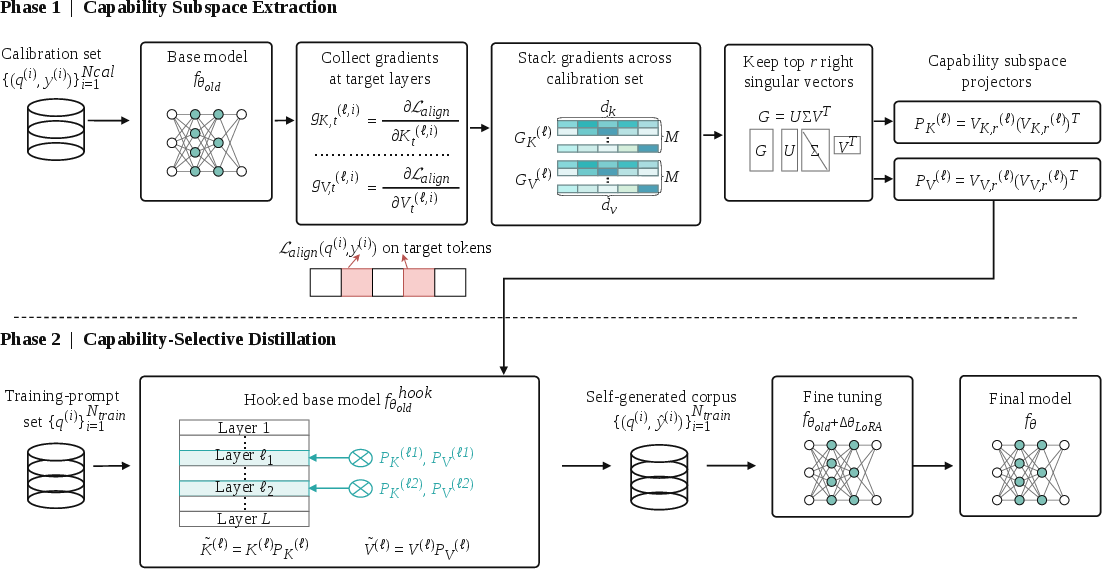
Putting it together, SPD works in two phases:
- Phase 1: Build the focus filter
- Use a small labeled set (calibration set).
- Compute gradients only on correctness-defining tokens.
- Use SVD to extract the main “skill directions” and build projection matrices (the filter).
- Phase 2: Generate and learn
- Attach the filters (projection hooks) to steer the model’s own generations toward correctness-focused content.
- Collect this self-generated data.
- Fine-tune the original model on that data using normal next-token prediction.
Main Findings and Why They Matter
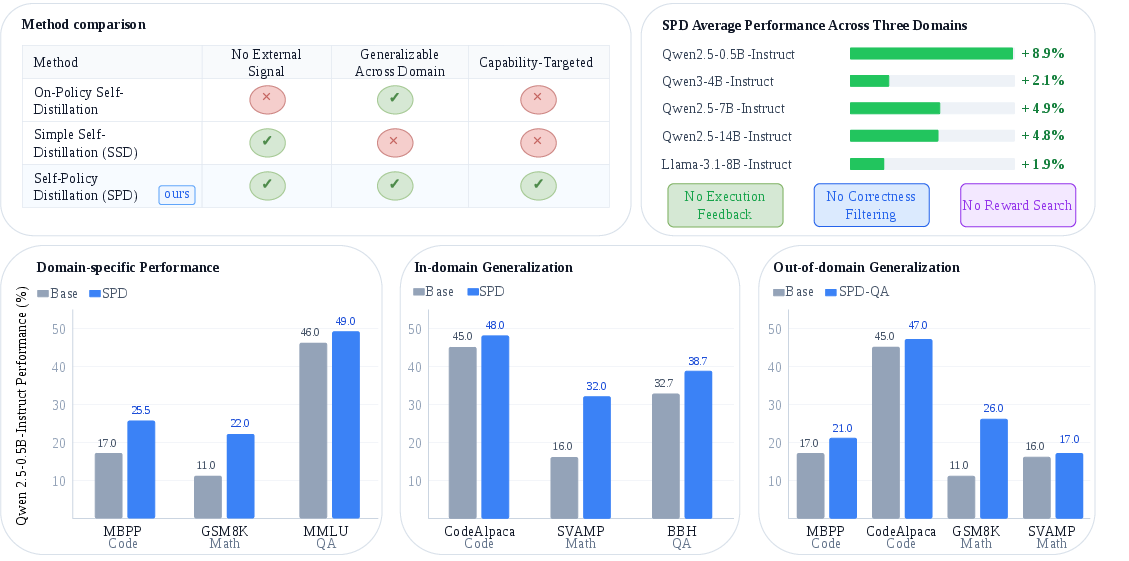
The authors test SPD on three types of tasks:
- Code generation (MBPP, CodeAlpaca)
- Math reasoning (GSM8K, SVAMP)
- Multiple-choice QA (MMLU, BBH)
Key results:
- SPD improves performance without any external judging or reward models.
- It beats other self-distillation methods that don’t use external signals, with up to 13% better results.
- It beats the starting/base models by up to 16%.
- It generalizes well:
- In-domain: Gains transfer to other datasets within the same skill area (e.g., from one math dataset to another).
- Out-of-domain: Gains also show up in different areas (e.g., calibrating with QA still helps on math and code), sometimes by as much as 15%.
Why this matters:
- Training on your own outputs often risks learning your own mistakes or style habits. SPD reduces that risk by focusing the training data on the “skill core” (correctness parts), not the fluff.
- This makes self-improvement more reliable, cheaper, and more general.
Implications and Potential Impact
- No external signals needed: SPD doesn’t rely on teachers, verifiers, reward models, or special tools. That’s helpful when such tools are costly or unavailable, especially for the strongest frontier models.
- Better generalization: By steering generation to correctness-focused content, the improvements carry over across tasks, not just within one domain.
- Data-efficient: SPD uses a small calibration set to build its focus filters. You don’t need tons of labeled examples.
- Practical training pipeline: SPD creates better self-generated training data and then uses standard fine-tuning, making it straightforward to apply.
A note on limitations:
- While tested across code, math, and QA with multiple model sizes, SPD should be validated further on more diverse and high-stakes tasks to confirm robustness.
In short, SPD is like teaching yourself by watching your own performances but only paying attention to the key moments that decide whether you win or lose. That focus helps you improve faster, more reliably, and across different types of challenges.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, to guide future research.
- Dependence on correctness-defining spans:
- Requires task-specific rules and ground-truth answers to mark correctness spans; unclear how to generalize to open-ended tasks (summarization, dialogue, translation) where “correctness” is ambiguous.
- No analysis of sensitivity to mis-specified or noisy correctness-span annotations.
- Lack of an automated, domain-agnostic procedure to infer correctness spans without labels.
- Calibration data requirements and domain shift:
- Although small calibration sets worked, sensitivity to label noise, domain mismatch, and sampling bias is untested.
- No investigation of cross-lingual or cross-genre calibration (e.g., calibrate on QA in one language, transfer to another).
- Missing guidelines for selecting calibration prompts to maximize transfer.
- Subspace extraction design choices:
- Fixed layer choice (middle and last) is not justified; no systematic study of layer selection, per-head vs. aggregated subspaces, or including additional components (queries, residual stream, MLPs).
- Rank r selection is ad hoc; no criterion or trade-off analysis between preserving capability and over-pruning useful variation.
- Alternatives to SVD on gradients (e.g., PCA on activations, Fisher/Hessian eigenvectors, CCA/CKA, randomized SVD) are not compared.
- Computational scalability:
- Gradient collection over KV activations across tokens and calibration examples may be costly for large models and long contexts; no profiling or memory/runtime analysis.
- SVD on large gradient matrices may be prohibitive; no discussion of streaming/approximate methods or distributed implementations.
- Hooking strategy and stability:
- Only K/V are projected; impact of also transforming Q or other submodules is unexplored.
- Distillation trains without hooks on data produced with hooks, creating a distribution mismatch; stability and retention of hooked behavior post-finetune are unquantified.
- No assessment of regressions in non-target capabilities (e.g., fluency, formatting, safety) caused by KV projection.
- Data generation policy:
- One completion per prompt is used; no exploration of multi-sample generation, temperature/nucleus sweeps, or sampling diversity to improve the self-generated corpus.
- Interaction between decoding settings and projection (e.g., temperature effects on capability selectivity) is unstudied.
- Iterative and multi-capability extensions:
- No experiments with multi-round SPD (recompute subspace after fine-tuning) to assess convergence, compounding gains, or collapse.
- Combining multiple subspaces (e.g., code + math) or gating/conditioning subspace selection per prompt remains open; potential interference/conflict between capabilities is unexamined.
- Generalization scope:
- OOD evaluation is limited to a few datasets; transfer to harder or broader distributions (e.g., MATH, HumanEval+, ARC-DA, DROP, CSQA, GSM-hard) is not tested.
- Only English benchmarks and text-only tasks are evaluated; multilingual and multimodal (vision-language) generalization is unaddressed.
- Long-context tasks and retrieval-augmented generation (where KV dynamics are crucial) are not evaluated.
- Comparisons and baselines:
- Baselines omit stronger teacher-free or representation-control methods (e.g., CoDI/KV-edits variants) and strong external-signal methods (verifier-/reward-based) under matched compute.
- No ablation against simpler projections (e.g., random low-rank, PCA on activations) to isolate gradient-specific benefits.
- Interpretability and analysis of the subspace:
- No qualitative/quantitative interpretation of learned directions (e.g., association with heads/neurons, attention patterns) or whether subspaces align across domains/backbones.
- Lack of diagnostics to verify that the subspace filters style/formatting rather than inadvertently dropping subtle task-relevant cues.
- Safety, bias, and alignment:
- No measurements of toxicity, bias, factuality/hallucination, or calibration; potential amplification of model-specific biases via self-generated data is unassessed.
- Effects on chain-of-thought quality and faithfulness (e.g., hiding reasoning vs. improving it) are not analyzed.
- Applicability to rationale-centric tasks:
- SPD appears to de-emphasize non-essential text; impact on tasks that require explicit, high-quality rationales or verifiable proofs is unknown.
- Robustness and reproducibility:
- No report of variance across random seeds, statistical significance, or sensitivity to hyperparameters (LoRA rank, learning rate, projection rank, layer set).
- Implementation details on hook placement and KV-cache interactions (e.g., for long sequences) are sparse.
- Training dynamics and error propagation:
- Although projection filters capabilities, self-generated outputs still contain errors; the risk of error accumulation/drift across distillation rounds is not quantified.
- No safeguards or lightweight correctness checks to mitigate propagation of systematic mistakes.
- Parameter adaptation choices:
- Only LoRA is used; the effect of other adaptation schemes (full fine-tuning, adapters, prefix-tuning, LoRA ranks) on absorbing the hooked policy is untested.
- Practical deployment:
- Real-time use of hooks at inference (without fine-tuning) to steer outputs is not evaluated.
- Potential efficiency gains (or slowdowns) from reduced effective KV rank during decoding are unmeasured.
- Task coverage and evaluation breadth:
- Limited to code, math, and multiple-choice QA; absence of instruction-following, multi-turn dialogue, information extraction, reasoning with tools/executors, and safety-critical domains.
- Subspace lifecycle:
- Subspace may become stale after fine-tuning; mechanisms for online/adaptive subspace updates or prompt-conditional subspaces are not explored.
- Failure modes and negative transfer:
- Cases where calibration domain harms unrelated domains (negative transfer) are not systematically sought or measured.
- Criteria for detecting and mitigating harmful subspaces are not provided.
Practical Applications
Immediate Applications
These applications can be built and deployed today by teams that have access to model weights (for gradient/backprop) and can insert inference-time hooks into attention KV activations.
- Targeted self-distillation for open-source or on-prem LLMs
- Sector: software/ML infrastructure
- What: Use SPD to upgrade a base model’s specific capability (e.g., code correctness, math reasoning, factual QA) without verifiers, reward models, or RL. Pipeline: small calibration set → correctness-aligned gradient collection on chosen layers → SVD to obtain low-rank KV subspaces → hook projections during self-generation → LoRA fine-tune on generated corpus.
- Tools/workflow: Hugging Face Transformers hooks; PyTorch autograd; SVD (e.g., PyTorch/NumPy); LoRA adapters; one-sample-per-prompt data generation; scheduled MLOps job.
- Assumptions/dependencies: Access to weights and KV activations; ability to identify correctness spans (e.g., final numeric answer, option letter, code output); modest GPU for gradient passes and LoRA; decoding config that matches domain.
- Capability-focused code assistant refinement
- Sector: software engineering/devtools
- What: Calibrate on unit tests or canonical function solutions to extract a “functional core” subspace; generate code with hooks to reduce boilerplate and stylistic detours; distill into a concise, correctness-oriented code assistant.
- Tools/products: IDE plugin or CI job that runs SPD monthly on a repository’s tests; “Capability Subspace Packs” versioned per repo/component; LoRA deltas checked into the monorepo.
- Assumptions/dependencies: Tests/ground truths that define correctness spans; access to model internals; guardrails to prevent catastrophic forgetting of style/conventions.
- Concise and accurate math tutor (reasoning over verbosity)
- Sector: education/edtech
- What: Use small sets of worked solutions with final answers marked as correctness spans to extract a reasoning subspace that steers self-generated rationales away from extraneous text and toward steps that determine correctness.
- Tools/products: LMS plugin to regularly generate improved synthetic solutions/explanations; teacher-facing dashboard comparing pre-/post-SPD error rates.
- Assumptions/dependencies: Clearly identified answer tokens; safeguards to avoid suppressing legitimate intermediate steps needed for pedagogy.
- Domain QA improvement without external verifiers
- Sector: customer support/enterprise search
- What: Calibrate on a small, curated set of Q&A pairs (correct answer letters or gold spans) to extract a “correctness” subspace; generate self-corpus under projection; LoRA fine-tune to get succinct, high-precision answers with fewer tangents.
- Tools/products: CRM/KM integration that feeds calibration examples; nightly SPD job producing updated LoRA; A/B rollout.
- Assumptions/dependencies: Annotation of correctness spans; access to internal LLM weights; monitored coverage to avoid domain drift.
- Privacy-preserving capability tuning in air‑gapped environments
- Sector: regulated industries (finance, government, defense)
- What: Improve models using only internal labeled snippets (20–500 examples suffice) and no external verifiers or human-in-the-loop feedback pipelines.
- Tools/products: Air-gapped SPD toolkit; policy-compliant LoRA deltas; reproducible calibration manifests.
- Assumptions/dependencies: Compute on-prem; robust tokenization and span marking for compliance-critical answers.
- Higher-yield synthetic data generation
- Sector: data engineering/ML
- What: Use projection hooks to bias self-generation toward capability-relevant content before any training, yielding cleaner, more targeted synthetic datasets for downstream fine-tuning (even for other models).
- Tools/products: “SPD-Generate” job that emits labeled synthetic corpora; quality gates comparing pre-/post-hook sample utility metrics (e.g., pass@1, EM).
- Assumptions/dependencies: Meaningful correctness spans; careful rank/layer selection to avoid over-pruning useful variance.
- Lightweight interpretability and capability probing
- Sector: academia/research; ML platform teams
- What: Use correctness-aligned gradients to identify low-rank capability subspaces; characterize how capability signal localizes across layers; compare subspaces across domains (code/math/QA).
- Tools/products: Subspace explorer notebook; alignment diagnostics (singular value spectra, cross-domain transfer plots).
- Assumptions/dependencies: Labeled calibration examples and layer-wise KV access; reproducible seeds/decoding for comparison.
- Efficient continual learning for productized LLMs
- Sector: software/consumer apps
- What: Periodically recalibrate targeted capabilities (e.g., new API versions, product updates) with small labeled sets and distill improvements without reintroducing a reward model pipeline.
- Tools/products: MLOps job template (calibration → hooks generation → data → LoRA → canary rollout); drift detectors to trigger recalibration.
- Assumptions/dependencies: Stable span definitions across versions; CI/CD for model artifacts; monitoring for regressions in non-target capabilities.
Long-Term Applications
These require further research, platform support, or broader validation (e.g., closed-API access, safety/regulatory evidence, multimodal generalization).
- Runtime “capability toggles” via dynamic subspace hooks
- Sector: software/product
- What: Switch capability modes at inference (e.g., “concise-math,” “robust-facts,” “core-code”) by loading different projection matrices without retraining; per-task routing that composes subspaces.
- Potential products: User-selectable modes in chat/IDE; router that picks subspace based on detected task.
- Assumptions/dependencies: Stable, composable subspaces; framework support for safe, low-latency KV hooking at scale; conflict resolution between overlapping subspaces.
- Safety and hallucination mitigation subspaces
- Sector: safety/alignment; healthcare; finance; policy
- What: Define “correctness spans” as verifiable facts, citations, or structured fields; extract subspaces that de-emphasize unsupported claims during generation; distill into safer base behavior.
- Potential products: “Safety SPD” packs for toxicity/hallucination reduction; safety-tuned LoRA additives.
- Assumptions/dependencies: High-quality, domain-specific span annotations; rigorous external validation; risk controls to avoid suppressing necessary context.
- Multimodal SPD (vision-language, speech-language)
- Sector: robotics, autonomous systems, media
- What: Generalize correctness-aligned gradient collection and KV projections to multimodal attention blocks to steer model generations toward capability-relevant cross-modal evidence.
- Potential products: VQA systems that privilege evidence-bearing regions; instruction-following agents with reliable perception-to-action grounding.
- Assumptions/dependencies: Access to multimodal KV streams; span definitions for targets (e.g., bounding boxes, timestamps); compute for larger models.
- Subspace “patch” ecosystems and compliance distribution
- Sector: enterprise software/platform marketplaces
- What: Distribute capability improvements as small projection matrices and/or LoRA deltas (“capability patches”) rather than full model weights for modular upgrades (e.g., sector-specific compliance, jargon).
- Potential products: Capability Subspace Hub (catalog of audited subspaces); patch management in MLOps.
- Assumptions/dependencies: IP/licensing clarity; APIs for safe patch loading; standards for auditing and versioning subspaces.
- Continual, self-healing LLMs in production
- Sector: ML operations
- What: Online SPD cycles that detect capability drift, recalibrate subspaces with fresh labeled trickle data, and auto-distill improvements with minimal supervision.
- Potential products: Drift monitors; auto-calibration schedulers; rollback-aware LoRA managers.
- Assumptions/dependencies: Reliable drift signals; small, continuously labeled datasets; safeguards against feedback loops and catastrophic forgetting.
- Foundation model training curricula with subspace awareness
- Sector: foundation model research
- What: Incorporate capability subspace extraction into pretraining/finetuning curricula to encourage disentangled, steerable representations; train models to expose stable subspaces for key skills.
- Potential outcomes: Models with native “capability interfaces” for safer steering and faster adaptation.
- Assumptions/dependencies: Scalable training studies; metrics for disentanglement; impact on overall capacity and emergent behaviors.
- Regulation-ready tuning pipelines
- Sector: policy/government; regulated industries
- What: SPD-based tuning that operates entirely within jurisdictional and privacy constraints; audit trails showing that only correctness-aligned tokens influenced capability updates.
- Potential products: Compliance reports with span-level provenance; certifiable tuning playbooks.
- Assumptions/dependencies: Standardized documentation of span selection; third-party audits; sector-specific validation benchmarks.
- Agentic systems with skill-specific SPD stages
- Sector: robotics/software agents
- What: Apply SPD to distinct agent skills (planning, tool-use, verification) to obtain compact, high-utility self-generated corpora per skill; distill into more reliable tool-using agents.
- Potential products: Toolformer-like pipelines augmented with SPD; agent orchestrators that load subspace patches for each subtask.
- Assumptions/dependencies: Clear, verifiable correctness spans per skill; orchestration that avoids interference between skills.
- Personal/model-local customization
- Sector: consumer apps/daily life
- What: Hobbyists using local models calibrate concise answer styles, domain lexicons, or problem types with a handful of examples, then run SPD to personalize without cloud verifiers.
- Potential products: Desktop SPD app with “teach by examples” UI that extracts spans automatically.
- Assumptions/dependencies: Local GPUs/accelerators; easy span-selection UX; safe defaults for rank/layer choices.
Cross-cutting assumptions and risks
- Access: SPD needs weight-level access for gradient computation and KV-hooking; not applicable to black-box API models without special provider support.
- Correctness span definition: Feasible, low-cost span identification is task-dependent; poor span choices can misalign the extracted subspace.
- Interference: Over-aggressive projection (rank too low, layers poorly chosen) may suppress useful variance or degrade non-target capabilities; requires validation and guardrails.
- Compute/ops: Though data-efficient (20–500 calibration examples), SPD still needs GPU cycles for backward passes, SVD, self-generation, and LoRA fine-tuning; operationalization benefits from MLOps investment.
- Generalization claims: While the paper reports up to 16% over baselines (in-domain) and up to 15% out-of-domain, real-world gains depend on domain, prompts, decoding, and span quality; evaluate with A/B tests and holdouts before wide rollout.
Glossary
- Ablation: An experimental analysis technique that removes or varies components to assess their impact on performance. Example: "Ablation on loss functions"
- Answer-letter accuracy: An evaluation metric where the model must select the correct option letter (e.g., A/B/C/D) for multiple-choice questions. Example: "answer-letter accuracy on MMLU"
- Autoregressive generation: A decoding process where each next token is generated conditioned on all previous tokens. Example: "During autoregressive generation, we insert projection hooks at each target layer ."
- Calibration set: A small labeled dataset used to estimate task-relevant directions (e.g., gradient-based) for steering generation. Example: "uses a small calibration set to extract a low-rank capability subspace"
- Capability-selective: Designed to target and preserve signals pertinent to a specific capability while filtering irrelevant patterns. Example: "a generalizable and capability-selective framework"
- Capability subspace: A low-dimensional subspace in the model’s activation space that captures directions most relevant to a target capability. Example: "extracts a low-rank capability subspace"
- Consistency-driven rationale evaluation: A curation method that selects explanations or rationales based on their internal agreement or consistency. Example: "consistency-driven rationale evaluation~\citep{lee2025self}"
- Correctness-aligned loss: A loss computed only on token positions that directly determine task correctness, focusing gradients on capability-relevant tokens. Example: "we define a correctness-aligned loss"
- Correctness-defining token positions: Token indices whose correct prediction directly determines task success. Example: "correctness-defining token positions"
- Execution-based feedback: Supervision obtained by executing model-generated solutions (e.g., code) to assess correctness. Example: "consistency or execution-based feedback"
- Key-value (KV) activations: The key and value matrices used in the transformer attention mechanism, representing internal attention features. Example: "projects key-value (KV) activations into this subspace"
- KV-space representations: Latent representations specifically in the key/value activation space of attention layers. Example: "latent or KV-space representations rather than only at the output level"
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning technique that adds trainable low-rank updates to weight matrices. Example: "The last step applies LoRA~\citep{hu2022lora} to fine-tune the model"
- Negative log-likelihood (NLL): A probabilistic loss measuring how unlikely the true data is under the model; lower is better. Example: "along with negative log-likelihood on CodeAlpaca."
- Next-token prediction loss: The standard autoregressive training objective that maximizes the likelihood of each next token given previous tokens. Example: "with standard next-token prediction loss."
- Normalized exact-match: An evaluation metric that measures exact-match accuracy with normalization (e.g., formatting), often used for reasoning benchmarks. Example: "and normalized exact-match on BBH"
- Off-policy distillation: Distillation using trajectories or data not generated by the current student policy (e.g., from a teacher or offline set). Example: "Early off-policy distillation methods mainly focus on transferring information from a stronger teacher to a student model"
- On-policy distillation (OPD): Distillation where training trajectories are sampled from the current student policy while receiving teacher guidance. Example: "on-policy distillation (OPD)~\citep{agarwal2024policy, boizard2024towards}"
- Out-of-domain generalization: The ability of learned improvements to transfer to tasks or datasets outside the trained domain. Example: "out-of-domain generalization settings."
- Pass@1: A code-generation metric indicating the success rate with a single sample attempt. Example: "We report pass@1 on MBPP"
- Per-token supervision: Teacher guidance provided at each decoding step rather than only at the sequence level. Example: "per-token supervision from the teacher."
- Projection hooks: Runtime modules that project internal activations (e.g., KV) onto a selected subspace during generation without altering model parameters. Example: "Projection hooks are applied to the K and V activations:"
- Rank‑r orthogonal projection matrix: A projection operator onto an r-dimensional subspace, constructed from top singular vectors. Example: "The rank- orthogonal projection matrix is then defined as"
- Reward-guided search: A data-generation or selection procedure that uses a reward signal to guide which outputs are chosen. Example: "reward-guided search~\citep{zhang2024rest}"
- Reward model: A learned model that assigns scalar rewards to outputs to guide selection or training. Example: "without a verifier, reward model, or RL."
- Right-singular vectors: Vectors from SVD that span directions in feature space; used here to define the capability subspace. Example: "We retain the top- right-singular vectors,"
- Rollout policy: The policy used to sample trajectories (token sequences) during distillation or training. Example: "trajectories sampled from a rollout policy"
- Self-distillation: Training a model on its own outputs instead of relying on an external teacher. Example: "Self-distillation has emerged as a powerful paradigm for improving LLMs by training them on their own generations."
- Self-generated corpus: A dataset of prompt–completion pairs produced by the model itself for subsequent fine-tuning. Example: "we obtain a self-generated corpus"
- Self-policy: An internally transformed generation policy derived from the model itself (e.g., via projection hooks). Example: "it first induces a self-policy through an internal transformation:"
- Self-Policy Distillation (SPD): The proposed framework that steers self-generation via projection into a capability subspace and then distills that behavior. Example: "we propose Self-Policy Distillation (SPD), a generalizable and capability-selective framework that requires no external signals."
- Singular value decomposition (SVD): A matrix factorization used to identify dominant directions (e.g., capability-relevant) in gradients. Example: "we perform singular value decomposition (SVD) on these gradients"
- Truncation-based decoding: A decoding strategy that limits outputs (e.g., by cutting off at a length or after certain tokens), used to regularize generations. Example: "produced with truncation-based decoding."
- Verifier-based selection: Selecting self-generated outputs using an external verifier to filter or evaluate correctness. Example: "verifier-based selection~\citep{hosseini2024v}"
Collections
Sign up for free to add this paper to one or more collections.