- The paper demonstrates that vanilla Diffusion Transformers with x-prediction in standardized DINOv2 space achieve state-of-the-art generative modeling performance.
- The paper introduces element-wise standardization and a dimension-aware noise schedule that simplify architectures and resolve issues like radial ambiguity.
- The paper empirically shows that RiT-XL outperforms prior methods with faster convergence, superior FID scores, and efficient few-step generation.
Theoretical Motivation and Manifold Geometry Analysis
The paper "RiT: Vanilla Diffusion Transformers Suffice in Representation Space" (2605.21981) presents a systematic study of diffusion modeling in pretrained representation spaces, focusing primarily on DINOv2 features. The authors begin with a geometric analysis that compares pixel space, SD-VAE latent space, and DINOv2 representation space across four axes: intrinsic dimensionality, effective rank, optimization conditioning, marginal Gaussianity, and on-manifold interpolation.
Despite comparable intrinsic dimensionality (d^≈33) between pixel and DINOv2 spaces, DINOv2 features exhibit substantially more favorable geometry for flow matching. Specifically, DINOv2 achieves 7.3× higher effective rank, 35× better covariance conditioning, 11.5× lower excess kurtosis, and 1.7× lower on-manifold interpolation error. These findings indicate that representation learning objectives, not simple compression, are responsible for making DINOv2 features particularly amenable to flow-matching regression and downstream image generation.
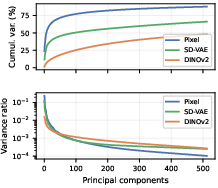
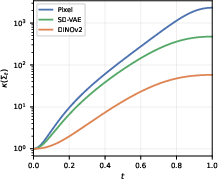
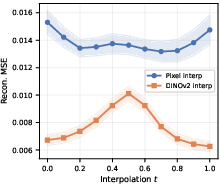
Figure 1: Manifold analysis across Pixel, SD-VAE, and DINOv2; DINOv2 geometry is markedly more favorable for flow-matching learning.
The analysis further shows that DINOv2 features concentrate near isotropic shells due to LayerNorm, but cross-token/channel variances are not perfectly uniform, necessitating element-wise standardization before modeling.
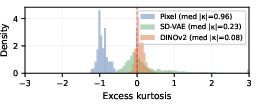

Figure 2: DINOv2 marginals have near-Gaussian kurtosis and support smooth cross-class interpolation, as opposed to strong pixel deviation and ghosting artifacts.
RiT Architecture and Flow Matching Recipe
RiT introduces the Representation Image Transformer (RiT): a vanilla Diffusion Transformer (DiT) trained in standardized DINOv2 representation space using x-prediction flow matching. The model is bracketed by a frozen DINOv2 encoder and a ViT-based decoder, employing a dimension-aware noise schedule and joint modeling of [CLS] and patch tokens.
The paper advocates for x-prediction, which regresses the clean data point rather than ambient velocity, thereby circumventing the radial ambiguity that arises when off-manifold intermediates are encountered during linear flow-matching paths. This eliminates the need for specialized prediction heads (as in DDT) or Riemannian flow matching, significantly simplifying the architecture in favorable representation spaces.
The recipe comprises: element-wise standardization to correct cross-channel variance, x-prediction target parameterization, joint diffusion of patch and [CLS] tokens for global context modeling, and a noise schedule adjusted for high per-token dimensionality.
Empirical Evaluation: Convergence, Efficiency, Few-Step Generation
RiT-XL (676M parameters) trained on ImageNet 256×256 with the smallest DINOv2 variant (DINOv2-S, d=384), achieves FID 1.45 without classifier-free guidance and 1.14 with guidance—surpassing DiT7.3×0-XL (839M params, larger DINOv2-B variant) and other representation diffusion baselines, while using fewer parameters and a simpler recipe.
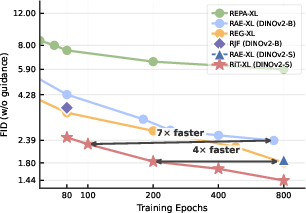
Figure 3: RiT-XL converges substantially faster than baselines in terms of both FID and wall-clock epochs.
Ablation studies confirm that every recipe component is critical, especially element-wise standardization (training diverges without it) and the time-shifted noise schedule (which closes a 7.3×1 FID gap).
Few-step generation is enabled by the geometry of DINOv2 space: guided FID improves from 2.0 (5 Heun steps) to 1.25 (10 steps), matching or surpassing prior baselines that typically require hundreds of sampler steps. Schedule ablation further shows that EDM, power-2, and time-shifted schedules outperform uniform or cosine spacing at low NFE, allocating steps to the high-noise regime where the velocity field varies most sharply.
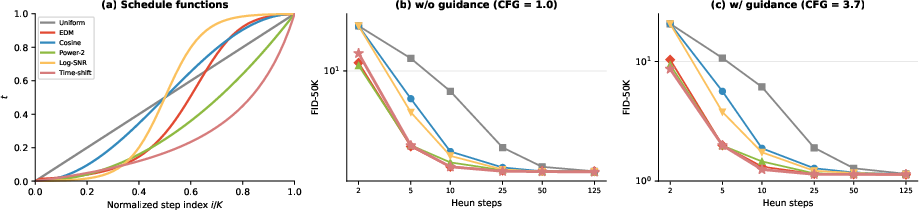
Figure 4: Sampling schedule comparison highlights regime-specific advantages for concentrated schedules.

Figure 5: Curated RiT-XL samples demonstrate coherent semantic coverage across diverse ImageNet categories.

Figure 6: Uncurated RiT-XL samples reveal robust generation across varied semantic classes.
Comparative Analysis and Architectural Implications
Metric-based comparisons with prior pixel-space, VAE-latent, and representation-based generative models show RiT's strong performance across FID, precision, recall, and IS metrics. Notably, RiT achieves the highest unguided precision at competitive recall, while using simpler architecture (no DDT head, no encoder fine-tuning, smallest DINOv2 variant).
RiT's capabilities are orthogonal to encoder-side adaptations explored in works like FAE; all improvements arise solely from denoiser-side optimizations, indicating composability with representation-latent modification methods. The joint modeling of [CLS] and patch tokens further enables global context integration naturally, without explicit representation alignment or loss augmentation.

Figure 7: Layer-wise attention analysis reveals global-to-local information flow between [CLS] and patch tokens.
Practical and Theoretical Implications
The results argue for a shift to 7.3×2-prediction in well-conditioned representation spaces, highlighting that target-side reformulations can obviate the need for architectural or path-specific modifications (DDT head, Riemannian flows). When the representation geometry is favorable—characterized by high effective rank, low condition number, near-Gaussian marginals, and on-manifold interpolants—a vanilla backbone suffices.
This finding has practical implications for unified vision pipelines. RiT demonstrates that a single standard backbone operating on an off-the-shelf semantic space like DINOv2 can provide competitive generative capabilities without the proliferation of task-specific encoder–decoder stacks. Further, the efficient ODE convergence in representation space enables low-latency, few-step generation suitable for online and interactive applications.
Future Directions
Potential extensions include text-to-image generation, larger resolutions, encoder co-adaptation, and investigation of geometric axes at higher model/data scales or in multimodal settings. RiT's geometry-centric recipe suggests broader applicability to other representation learning frameworks provided their distributions satisfy the identified geometric conditions.
Conclusion
RiT provides a formal justification and empirical demonstration that vanilla Diffusion Transformers can achieve state-of-the-art generative modeling in DINOv2 representation space using 7.3×3-prediction, element-wise standardization, and dimension-aware recipes. Its architecture-free approach outperforms prior baselines with fewer parameters and less complexity, and it supports highly efficient few-step generation without distillation. The results motivate a paradigm of leveraging favorable geometry in pretrained semantic representations for unified, scalable generative modeling in vision and beyond.