- The paper introduces a taxonomy integrating LLM-driven prompt-based and learning-based approaches into OR modeling and algorithm design.
- The paper reveals that LLMs can automate model formulation, heuristic optimization, and solution validation with measurable improvements on benchmark datasets.
- The paper identifies challenges in scalability, data heterogeneity, and explainability, outlining future research directions for industrial-scale applications.
LLMs for Operations Research: A Comprehensive Survey
Introduction
The intersection of LLMs and Operations Research (OR) has catalyzed a paradigm shift in decision science, enabling new modes of automation for modeling, algorithmic solution, and validation of complex optimization problems. "LLMs for Operations Research: A Comprehensive Survey" (2605.20849) establishes a detailed taxonomy of methodologies and emergent research directions in LLM4OR, incorporating both methodological advances and application-centric evaluations.
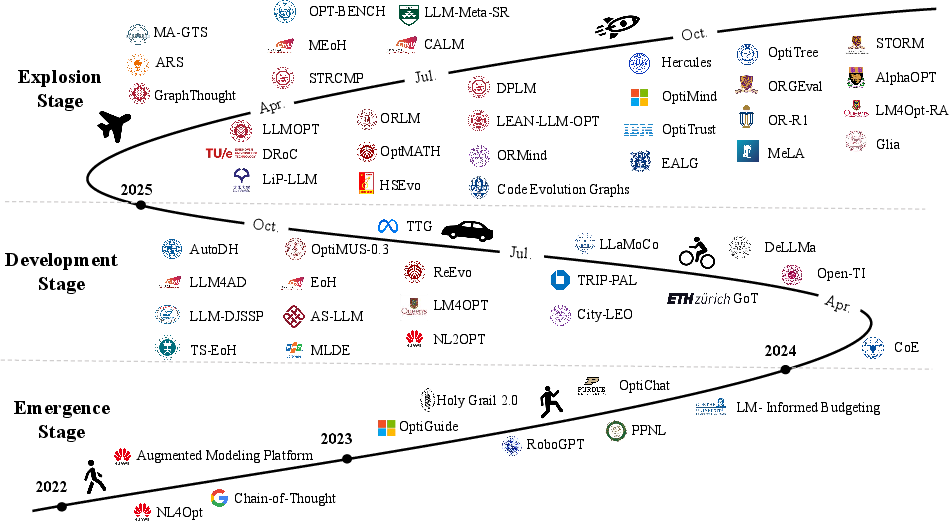
Figure 1: Evolution timeline of LLM4OR (2022-2025), demonstrating rapid development across core research stages.
The survey systematically addresses the foundational integration of LLMs into OR workflows, delineates algorithmic frameworks supporting model formulation and algorithmic synthesis, and critically assesses benchmark datasets and validation paradigms. The synthesis highlights limitations and frontier challenges impeding LLM deployment in real-world, industrial-scale OR scenarios.
Solution Process in LLM4OR
OR problems encompass diverse decision variable structures, primarily combinatorial and continuous optimization, each bringing distinct representational and computational properties. The traditional pipeline of model formulation, algorithm design, and solution validation is fundamentally restructured by the incorporation of LLMs.

Figure 2: Solution workflow for OR problems, with LLMs supporting all primary stages from problem description to solution verification.
LLMs, built on decoder-based transformer architectures with large-scale, diverse corpora, support prompt-driven and data-driven workflows, overcoming reliance on domain expert intervention for model construction and enabling adaptive, context-aware algorithm generation.
LLM-driven model formulation strategies are categorized as prompt-based or learning-based, each leveraging the natural language-to-mathematical model transformation capabilities of LLMs.
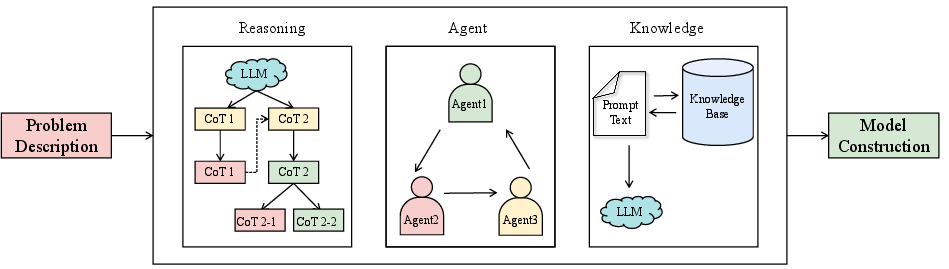
Figure 3: Illustration of three frameworks for prompt-based methods: reasoning, agent, and knowledge, enabling flexible prompt designs tailored to modeling requirements.
Prompt-based methods utilize engineered prompts, agent-based decomposition, and retrieval-augmented techniques for zero- and few-shot performance on model extraction from unstructured descriptions. Reasoning frameworks such as CoT/ToT/GoT extract multi-step logic, while agent-based pipelines modularize model synthesis, e.g., via systems like OptiMUS.
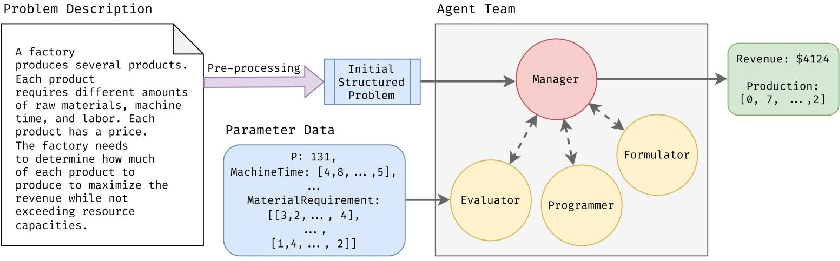
Figure 4: Workflow of OptiMUS leveraging modular agent cooperation, cross-validation, and external knowledge for scalable NLP-OR model construction.
Learning-based methods enhance LLM modeling capacity through supervised fine-tuning, reinforcement learning, and parameter-efficient adaptation (e.g., LoRA, PEFT), leveraging synthetic, reversed, and augmented data for improved accuracy and generalization.
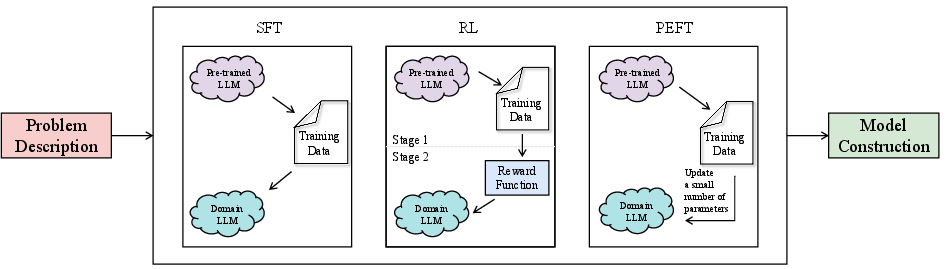
Figure 5: Illustration of three frameworks for learning-based methods (SFT, RL, PEFT), each targeting task-specific adaptation with varying resource and data constraints.
Empirical results indicate marked drops in modeling accuracy on realistic or complex datasets, substantiating the high data sensitivity and transfer limitations in current LLM4OR pipelines. The survey voices the imperative for robust data synthesis and unified evaluation metrics tailored to real-world industrial contexts.
Algorithm Design and Search Automation
LLMs can serve as evaluators, optimizers, or designers in algorithmic construction for OR.
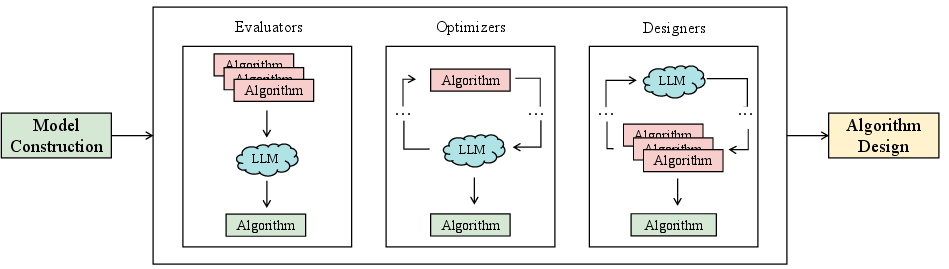
Figure 6: Illustration of three roles in algorithm design—evaluator, optimizer, and designer—each representing a unique mode of LLM intervention in the solution pipeline.
LLM-informed algorithms demonstrate quantifiable improvements in combinatorial and continuous optimization tasks but face pronounced generalization barriers on industrial-scale problem instances, especially those requiring integration of external tools and real-time feedback.
Solution Validation Frameworks
Robust solution validation is essential to compensate for potential logical inconsistencies and constraint omissions inherent to LLM-generated models and algorithms.
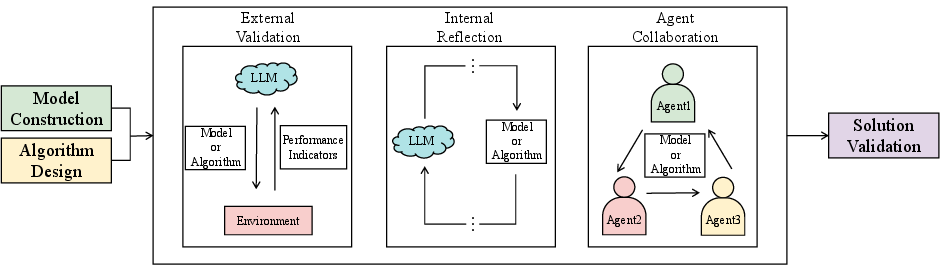
Figure 8: Illustration of three solution validation frameworks: external validation, internal reflection, and agent collaboration.
Three primary paradigms are identified:
- External validation: Integration with optimization solvers or RL-based feedback for automated error tracing and correction.
- Internal reflection: Enabling LLMs to perform iterative reasoning, debugging, and self-correction, as operationalized in multi-turn or agentic platforms.
- Agent collaboration: Dedicated agent roles for cross-verification, leveraging redundancy and modularity for higher validation assurance.
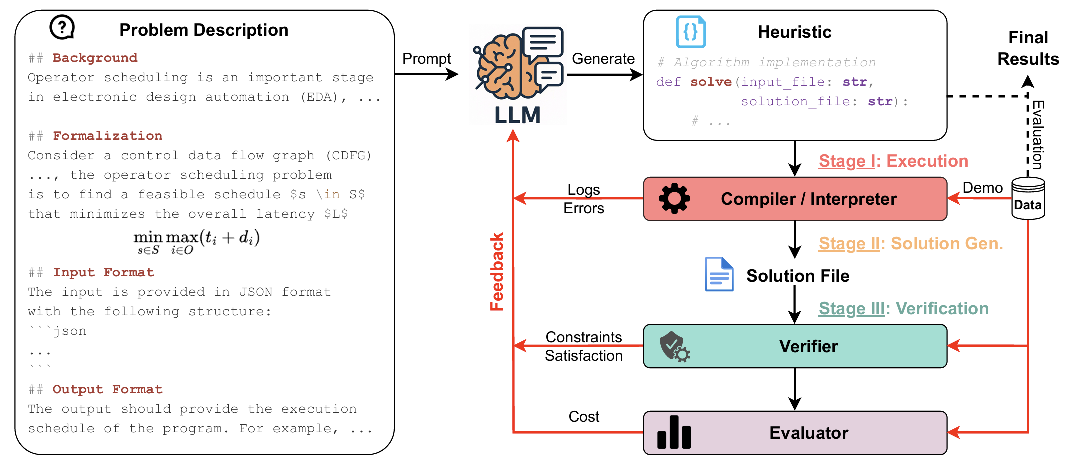
Figure 9: Workflow of HeuriGym, an agentic evaluation platform coupling LLM code generation, execution, and feedback-driven iteration.
Collectively, these frameworks mitigate automation risks inherent in LLM4OR and offer pathways for scalable, trustworthy deployment.
Application Scenarios
LLM4OR methodologies have been validated across a spectrum of domains:
Figure 10: Scenario application across scheduling, transportation, robotics, biochemistry, networks, and finance.
Key domains include:
- Scheduling: Resource allocation and sequencing (e.g., supply chain, cloud computing) via OptiGuide and other agentic pipelines.
- Transportation: End-to-end decision support, spanning TSP/VRP, with integrated map data and symbolic planning.
- Robotics: Multi-agent planning and human-in-the-loop preference incorporation.
- Biochemistry: Biomolecule and enzyme design via combined LLM-genetic algorithm frameworks.
- Networks and Finance: Resource allocation, portfolio optimization, and risk assessment under uncertainty with LLM-driven scenario modeling.
LLM4OR demonstrates superior performance on synthetic and academic datasets, but performance diminishes significantly with increasing problem complexity and real-world data heterogeneity.
Datasets and Benchmarking
The survey aggregates a comprehensive taxonomy of benchmark datasets, spanning from natural language-to-mathematics mapping to cross-domain combinatorial optimization.
The depth and diversity of datasets, with a gradual shift from textbook-derived examples to industrial-scale, multi-modal, and real-world scenarios, is identified as a determining factor in method evaluation and progress tracking.
Challenges and Future Directions
The survey underscores several persistent bottlenecks and research opportunities:
- Framework Exploration: Existing LLM4OR frameworks underperform (<50% accuracy) on complex industrial-scale datasets, necessitating the development of domain-specific and scalable architectures.
- Dataset Construction: Lack of standardized, realistic benchmarks inhibits cross-comparative evaluation and generalizability assessment.
- Data Protection: Ensuring data confidentiality, especially for cloud-based LLM deployments in sensitive domains.
- Result Explainability: Interpretability for expert validation and feedback remains limited, despite recent progress in explainable OR.
- Multimodal LLMs: Integration of image, table, and other structured modalities for holistic problem representation is nascent but essential for broader applicability.
Conclusion
The survey offers an authoritative, structured account of LLM4OR, consolidating methodological, empirical, and application-oriented advances. While LLMs have induced transformative advances in OR, critical technical challenges remain in scaling, generalization, validation, and explainability, especially under real-world constraints and requirements. Future work will likely converge on integrating multimodal data processing, developing privacy-compliant frameworks, unifying benchmarks, and advancing explainable AI mechanisms to unlock the potential of LLM4OR in industrial practice and scientific discovery.