A More Word-like Image Tokenization for MLLMs
Abstract: Modern multimodal LLMs (MLLMs) typically keep the LLM fixed and train a visual projector that maps the pixels into a sequence of tokens in its embedding space, so that images can be presented in essentially the same form as text. However, the LLM has been optimized to operate on discrete, semantically meaningful tokens, while prevailing visual projectors transform an image into a long stream of continuous and highly correlated embeddings. This causes the visual tokens to behave differently from the word-like units that LLMs are originally trained to understand. We propose a novel Disentangled Visual Tokenization (DiVT) that clusters patch embeddings into coherent semantic units, so each token corresponds to a distinct visual concept instead of a rigid grid cell. DiVT further adapts its token budget to image complexity, providing an explicit accuracy-compute trade-off modifying neither the vision encoder nor the LLM. Across diverse multimodal benchmarks, DiVT matches or surpasses baselines with significantly fewer visual tokens, demonstrating robustness under limited token budgets, significantly reducing memory cost and latency while making visual inputs more compatible with LLMs. Our code is available at https://github.com/snuviplab/DiVT.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper tries to help computers understand images and text together more smoothly. Today’s big LLMs (the kind that write and reason with words) are very good with word-like pieces called “tokens.” But when we feed them images, we usually turn an image into hundreds of tiny pieces (patches) that don’t behave like clear, separate “words.” The paper introduces a new way, called DiVT (Disentangled Visual Tokenization), to turn an image into fewer, more meaningful “visual words” so the LLM can reason about pictures more naturally, faster, and with less memory.
What questions are the researchers asking?
They ask:
- Can we make image tokens more like word tokens—each one clearly representing a specific idea or object—so LLMs handle pictures better?
- Can the number of image tokens automatically grow or shrink depending on how simple or complex the picture is?
- Can we give users an easy “knob” to control detail vs. speed without retraining the model?
How does their method work?
The problem with current image tokens
Most systems break an image into a fixed grid of patches and pass all of them (often hundreds) to the LLM. Two issues happen:
- Many patches carry very similar information, especially after the vision network mixes them together. That’s like describing a scene by repeating almost the same word again and again.
- Every image gets the same number of tokens, whether it’s simple (a single apple) or complex (a busy street scene). That wastes effort on simple images and misses details on complex ones.
The authors show that image patch features inside one picture often become too similar to each other, while text tokens are naturally more distinct. This mismatch makes it harder for the LLM to “think” about images the way it does about text.
The idea in simple terms
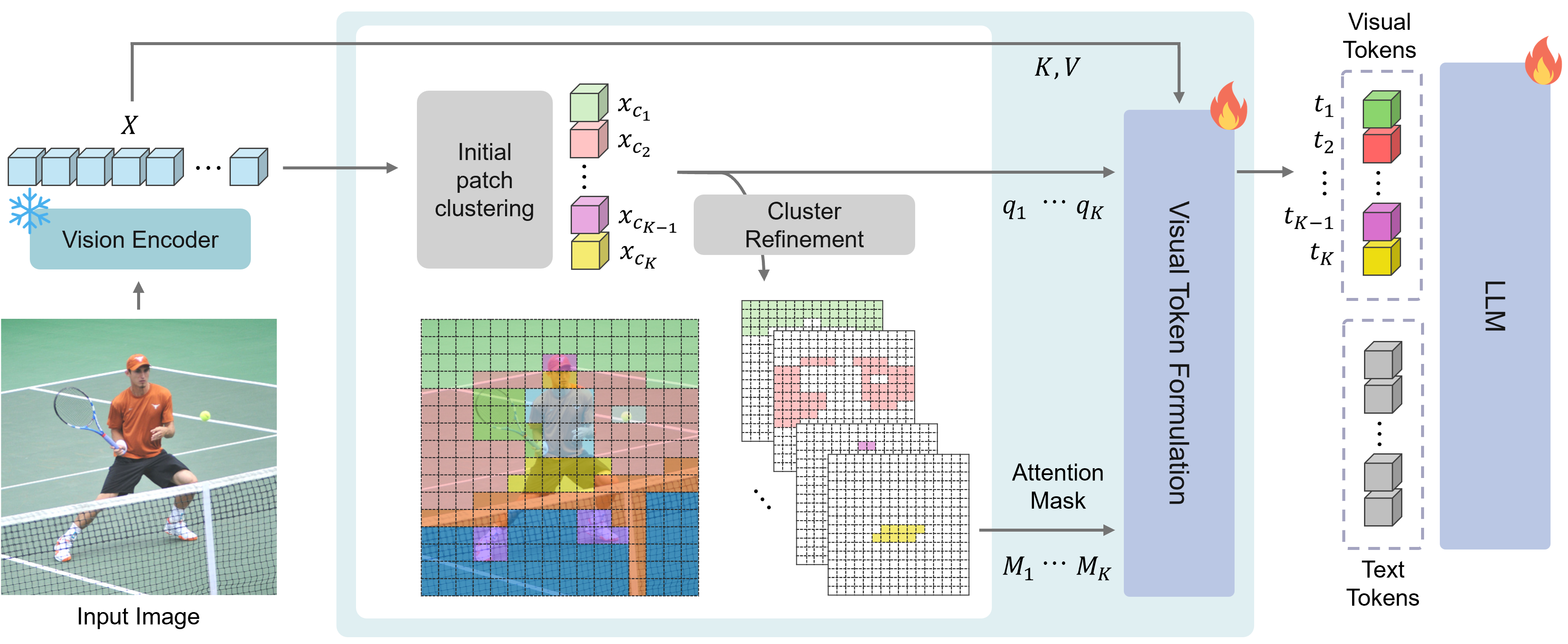
Think of an image like a bag of colorful LEGO pieces. Instead of sending every single piece to the LLM, DiVT groups pieces that clearly belong together (like all the pieces forming “the dog,” or “the traffic sign,” or “the sky”) into a few meaningful chunks. Each chunk is a “visual word.”
The three main steps
Here’s how DiVT turns an image into visual words:
- Step 1: Pick leaders (initial clustering)
- The system looks at how similar patches are to each other. Patches with lots of close neighbors become “leaders,” each starting a cluster. Simple images end up with fewer clusters; complex ones get more.
- Step 2: Tidy up the groups (refinement)
- Some patches might fit better with a different leader, so the system reassigns them to the closest, most suitable cluster. This makes each group more semantically coherent—more like a single clear idea.
- Step 3: Make one token per group (visual token formation)
- Within each group, the system blends information to form one compact token (one “visual word”). It focuses the blend only within each group, so tokens stay disentangled and meaningful.
A simple “detail knob”
There’s a single similarity threshold (think of it as a strictness setting). Turning it up creates more, finer-grained tokens (more detail, more compute). Turning it down creates fewer, broader tokens (faster, but less detail). You can change this knob even after training, which is very practical.
What did they find?
In tests across many image–language benchmarks (like visual question answering and general image understanding), DiVT:
- Matches or beats strong baselines while using far fewer tokens. For example, instead of ~576 tokens per image, DiVT often uses around 136, 74, 36, or even as low as ~14–22 tokens and still performs competitively.
- Holds up especially well when you limit tokens. Under tight budgets, DiVT loses less performance than other methods.
- Reduces memory use and speeds up inference (fewer tokens means smaller caches and less processing).
- Works with different vision backbones (like CLIP, SigLIP, DINOv2) and with larger LLMs too—so it’s flexible.
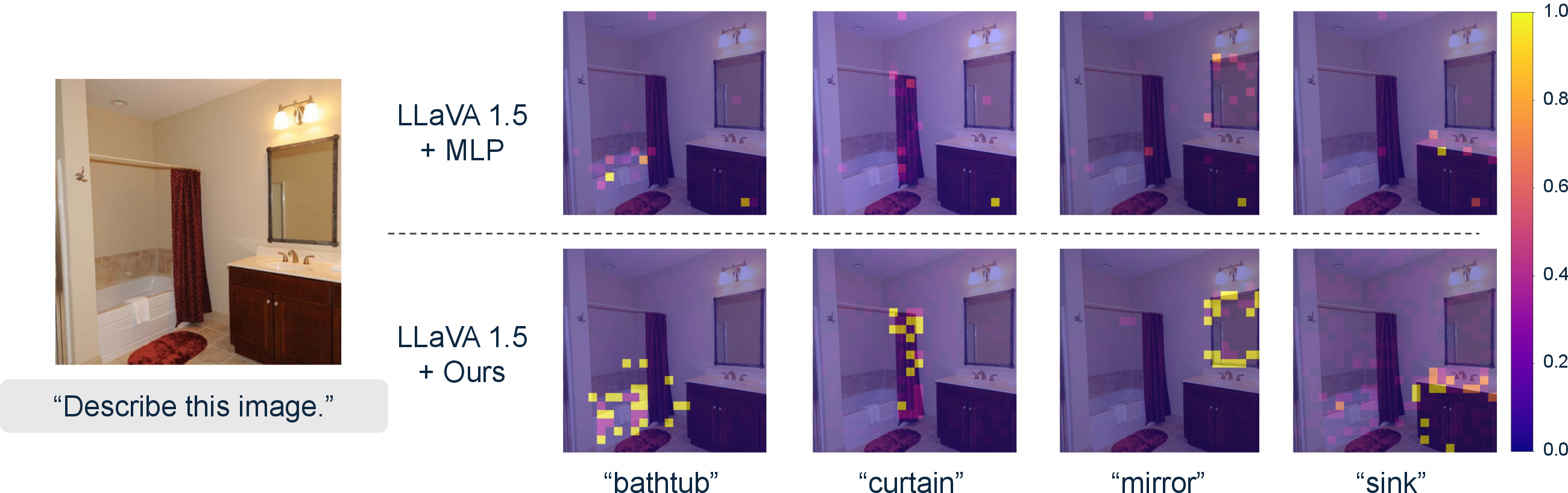
- Produces more focused attention maps: when the model talks about “the dog,” its attention is tightly on the dog, not scattered around unrelated regions. That makes outputs more interpretable.
- Adapts token counts to the task: simple images get fewer tokens; text-heavy or cluttered images get more.
Why does this matter?
- More “word-like” image tokens help LLMs reason about pictures the way they reason about text—using clear, distinct units of meaning.
- Fewer, smarter tokens mean lower cost and latency, which is crucial for real-time apps, phones, or any setting with limited compute.
- The adjustable “detail knob” lets developers balance quality and speed without retraining—useful for different devices or budgets.
- Because DiVT doesn’t require changes to the vision encoder or the LLM, it’s easy to plug into existing systems.
In short, DiVT makes images speak the language of words: fewer, clearer, and more meaningful tokens that help multimodal models be both smarter and faster.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, framed as concrete items future work can act on.
- Lack of principled selection of the similarity threshold (): No method is provided to automatically choose or adapt per image, per prompt, or per compute budget; develop a learned controller (e.g., a small policy network or meta-learned mapping from image/prompt features to or target token count).
- No theoretical or quantitative measure of “disentanglement”: Beyond qualitative attention maps and token similarity anecdotes, the work lacks metrics and evaluations (e.g., intra-/inter-cluster feature dispersion, cluster purity against object/part labels, mutual information with ground-truth regions) to substantiate semantic disentanglement claims.
- Computational overhead and scalability of clustering are unquantified: Computing the full patch-wise cosine similarity matrix () and greedy centroid selection may be costly; report end-to-end latency and memory (including pre-LLM steps), and explore scalable approximations (e.g., ANN search, block-sparse similarities, locality-sensitive hashing) for high-resolution images and video.
- Cluster ordering effects on LLM positional encodings are not studied: Tokens are simply ordered by spatial coordinates; ablate alternative orderings (saliency-, similarity-, or text-guided order) and measure downstream impacts on reasoning and grounding.
- Positional encoding design choices are under-explored: Positional embeddings are injected only in the value branch; assess injecting into queries/keys or using relative/rotary position encodings to better capture geometry and cross-cluster relations.
- Restricted intra-cluster aggregation may impair relational reasoning: The cluster-restricted attention mask forbids cross-cluster mixing during token formation; evaluate impacts on tasks requiring relations (counting, spatial comparisons, layouts) and test hybrid designs (soft cross-cluster gating, multi-hop aggregation).
- No comparison against recent semantic tokenizers under matched settings: Provide controlled, same-backbone, same-token-budget comparisons to methods like SeTok and Chat-Univi to strengthen claims about semantic alignment and efficiency.
- Insufficient object-level grounding evaluation: Move beyond captioning/VQA to quantitative grounding (e.g., RefCOCO, pointing game), segmentation/detection alignment, and measure whether clusters map to objects/parts (cluster-object IoU, purity, coverage).
- Failure mode analysis is missing: Identify and categorize cases where DiVT underperforms (e.g., dense OCR, tiny text, heavy clutter, low-contrast objects), and link them to granularity/threshold settings to guide practical deployment.
- Vision-encoder layer choice is not ablated: The paper motivates entanglement at deeper ViT layers but does not test clustering on earlier layers or multi-layer fusion; evaluate which encoder layer(s) yield best semantic clusters and efficiency.
- Clustering is non-learnable and greedy: Explore differentiable/learnable clustering (e.g., Gumbel-soft assignments, DP-means variants, density-based clustering) to refine centroids and assignments end-to-end, and consider learning or bandwidths per sample.
- Multi-scale, multi-view, and video tokenization are not addressed: Incorporate pyramid features (multi-resolution patches), extend to multi-image inputs and streaming/video (temporal consistency, token reuse), and measure temporal robustness and efficiency.
- Real deployment metrics are absent: Provide wall-clock latency, throughput, and KV-cache memory reductions, explicitly including the overhead of clustering and token formation, across GPUs and batch sizes.
- Robustness to domain shift and adversarial perturbations is untested: Evaluate under synthetic corruptions, adversarial attacks, and cross-domain datasets (medical, document, satellite) to assess stability of clustering-driven tokenization.
- Encoder-agnostic calibration of is ad hoc: The mapping from to token counts varies across encoders (CLIP, SigLIP, DINOv2); propose normalized similarity scales or learn per-encoder calibration to hit target budgets reliably.
- Prompt-aware token allocation is unexplored: Condition token granularity on the question type (e.g., OCR vs. spatial reasoning), using a lightweight text-conditioned controller that adjusts or cluster density at inference.
- Counting and compositional reasoning benchmarks are limited: Evaluate on tasks explicitly requiring multi-object counting/composition (e.g., TallyQA, VizWiz, Visual7W), measuring whether cluster semantics suffice for fine-grained relational reasoning.
- Impact of fine-tuning the LLM with DiVT is unknown: The current setup keeps the LLM fixed; assess whether partial/full LLM fine-tuning with DiVT tokens further improves alignment and reasoning, and whether benefits scale with model size.
- Extreme token budgets are not probed: Determine performance floors with very few tokens (e.g., <10) and characterize the accuracy–compute frontier; identify minimal viable budgets per task class.
- Cluster centroid bias toward backgrounds or dominant textures is unchecked: Measure object/background coverage of selected centroids and test saliency- or text-conditioned weighting to avoid over-representing homogeneous regions.
- Token semantics are not validated with human studies: Conduct human evaluations linking visual tokens to word-level concepts (object/part names) to corroborate the “word-like” claim and quantify interpretability.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage DiVT’s adaptive, semantically coherent visual tokenization to reduce memory/latency, improve robustness under tight token budgets, and expose an inference-time “knob” (theta) for accuracy–compute trade-offs.
- Cost and latency reduction for multimodal inference services (Software/Cloud)
- What to do: Replace MLP/grid projectors in existing MLLM stacks (e.g., LLaVA-like) with DiVT to cut visual tokens from ~576 to 20–140 while matching/surpassing quality on common VQA/conversation benchmarks; expose
thetaas a configurable parameter per request. - Potential tools/workflows: “DiVT-enabled inference server” plugin for vLLM/Triton; API parameter for
theta; autoscalers that tunethetaunder load to hit SLAs. - Dependencies/assumptions: Variable-length sequences must be supported (bucketing/padding); ensure DiVT’s clustering cost (pairwise similarities over ViT patches) is amortized/optimized; benefits depend on how much your workload is vision-token bound vs. text-bound.
- What to do: Replace MLP/grid projectors in existing MLLM stacks (e.g., LLaVA-like) with DiVT to cut visual tokens from ~576 to 20–140 while matching/surpassing quality on common VQA/conversation benchmarks; expose
- On-device multimodal assistants with adaptive compute (Mobile/XR/Consumer)
- What to do: Deploy DiVT with small encoders (CLIP/SigLIP) to enable scene Q&A, captioning, or translation on phones, wearables, or AR glasses with battery-/thermal-aware
theta. - Potential tools/workflows: Mobile SDK that tunes
thetausing OS battery/thermal signals; offline captioning/camera-assist modes. - Dependencies/assumptions: Efficient similarity computation (e.g., int8/FP16, tiling) and memory-friendly kernels required; quantization support; privacy and safety guardrails for consumer apps.
- What to do: Deploy DiVT with small encoders (CLIP/SigLIP) to enable scene Q&A, captioning, or translation on phones, wearables, or AR glasses with battery-/thermal-aware
- Real-time edge perception for robots and drones (Robotics/Industrial IoT)
- What to do: Use adaptive tokens to keep latency low in simple scenes and allocate more tokens for cluttered or safety-critical frames.
- Potential tools/workflows: ROS2 node that publishes “visual-word” tokens; planner subscribes to tokens;
thetatied to control loop budget. - Dependencies/assumptions: Tight latency constraints necessitate optimized clustering; reliability under motion blur/low light must be validated.
- High-throughput document understanding and OCR-QA (Finance, Healthcare admin, Legal, Logistics)
- What to do: Process forms, invoices, and medical paperwork; DiVT naturally increases tokens for text-heavy images while staying compact on simple pages, improving throughput/cost at target accuracy.
- Potential tools/workflows: Document QA pipelines that raise
thetawhen OCR confidence is low; cascade mode (coarse pass, then refine). - Dependencies/assumptions: Domain adaptation may be needed for scanned/low-quality documents; ensure data privacy controls.
- Content safety triage at scale (Social Media/Trust & Safety)
- What to do: Run coarse
thetafor bulk screening; automatically re-run with higherthetaon borderline cases to balance recall and cost. - Potential tools/workflows: Triage pipeline with risk-based escalation; dashboards showing tokens-per-image and risk scores.
- Dependencies/assumptions: Threshold policies require careful tuning to avoid false negatives on sensitive content.
- What to do: Run coarse
- E-commerce visual search and attribute extraction (Retail)
- What to do: Use lower
thetafor clean product shots; increase for user-generated/lifestyle images; maintain robust attribute extraction at lower cost. - Potential tools/workflows: A/B testing
thetaby catalog category; batch processing with token-budget quotas. - Dependencies/assumptions: Training data diversity; consistency across supplier image styles; integration with retrieval/caption modules.
- What to do: Use lower
- Accessibility-focused image descriptions (Public sector/NGOs)
- What to do: Provide faster, on-device image captioning for blind/low-vision users with energy-aware token budgets.
- Potential tools/workflows: Captioning apps with adaptive
thetafor responsiveness; optional “detail mode” that raisestheta. - Dependencies/assumptions: Inclusive evaluation; bias/hallucination monitoring for safety-critical usage.
- Interpretable attention for annotation and weak supervision (Academia/ML Ops)
- What to do: Use DiVT’s semantically disentangled tokens and focused attention maps to accelerate labeling, spot-check model reasoning, or guide weakly supervised learning.
- Potential tools/workflows: Annotation UIs overlaying token clusters/attention; curriculum that upsamples tokens for hard samples.
- Dependencies/assumptions: Human factors and usability; domain-specific visual concepts may require fine-tuning.
- KV-cache and memory footprint reduction (Systems/Infra)
- What to do: Smaller visual sequences reduce KV-cache growth and memory bandwidth; improve batch throughput for multi-image chat.
- Potential tools/workflows: KV-cache budgeting by
theta; scheduler that co-locates requests by similar token counts. - Dependencies/assumptions: Framework/kernel support for variable-length sequences; potential batching fragmentation.
- Green AI and cost governance (Enterprise/MLOps)
- What to do: Instrument “tokens-per-image” and power metrics; use
thetaas a governance knob to meet carbon or cost budgets. - Potential tools/workflows: Policy-based controllers (e.g., lower
thetaevenings/weekends); per-tenant budgets in multi-tenant services. - Dependencies/assumptions: Accurate metering; procurement/governance alignment with service-level agreements.
- What to do: Instrument “tokens-per-image” and power metrics; use
Long-Term Applications
These opportunities require additional research, engineering, domain validation, standards work, or ecosystem adoption before they are broadly deployable.
- Temporal DiVT for video MLLMs (Media/Surveillance/Sports analytics)
- Vision: Extend clustering across time to produce stable, object/part-level tokens per frame with adaptive budgets.
- Potential tools/workflows: Event-driven compute (burst tokens on action/scene change); streaming summarization.
- Dependencies/assumptions: Temporal coherence, token tracking, and memory constraints; annotation and evaluation protocols.
- Standardized “visual-word” token APIs and formats (Software/Interoperability)
- Vision: A cross-model representation for image tokens with metadata (region anchors, saliency, uncertainties) that downstream tools can consume.
- Potential tools/workflows: ONNX/TensorRT operator support; token-aware file formats; shared ecosystem libraries.
- Dependencies/assumptions: Community standards and vendor buy-in; backward compatibility.
- End-to-end pretraining with adaptive token budgets (ML Research/Platforms)
- Vision: Reduce training cost by learning with variable tokenization; curriculum that anneals
thetabased on task difficulty. - Potential tools/workflows: Schedulers adjusting
thetaduring pretraining/finetuning; budget-aware data sampling. - Dependencies/assumptions: Stability of training dynamics; large-scale compute/data; fairness and safety outcomes.
- Vision: Reduce training cost by learning with variable tokenization; curriculum that anneals
- Healthcare imaging and clinical decision support (Healthcare)
- Vision: DiVT preserves fine details only when needed, enabling efficient multi-view imaging reasoning (e.g., radiographs, fundus images) and telemedicine triage.
- Potential tools/workflows: On-device pre-screening with low
theta; server-side escalation on flagged cases. - Dependencies/assumptions: Rigorous clinical validation, regulatory approvals (FDA/CE), domain shift from natural images, and robust uncertainty calibration.
- Autonomous driving and V2X token exchange (Automotive)
- Vision: Use semantic tokens as a compact, bandwidth-efficient interface between perception and planning, and for inter-vehicle communication (V2X).
- Potential tools/workflows: Token-level compression; safety-critical fallback to high
thetaunder uncertainty. - Dependencies/assumptions: Safety certification; standards for V2X content; adversarial robustness.
- Privacy-preserving analytics and federated learning (Security/Privacy)
- Vision: Transmit/aggregate semantically compressed tokens instead of raw images to reduce exposure risk in distributed training or analytics.
- Potential tools/workflows: Token encryption, differential privacy on token features, audit logs.
- Dependencies/assumptions: Formal privacy guarantees (tokens may still leak sensitive info); compliance alignment (GDPR/HIPAA).
- Hardware–software co-design for variable-length vision (Semiconductors/Systems)
- Vision: Accelerators optimized for dynamic sequence lengths, token bucketing, and token-aware KV-cache eviction; memory controllers tuned to clustered access patterns.
- Potential tools/workflows: Compiler passes that fuse clustering+cross-attn; runtime schedulers for mixed
thetabatches. - Dependencies/assumptions: Vendor toolchain support; ecosystem readiness; ROI relative to static-shape optimizations.
- Education technology and tutoring (Education)
- Vision: Multimodal tutors that adapt token budgets to worksheet/diagram complexity and provide interpretable “what I looked at” feedback.
- Potential tools/workflows: LMS integrations using
thetato trade speed vs. detail; teacher dashboards with token-based explanations. - Dependencies/assumptions: Age-appropriate safety controls; pedagogical validation.
- Policy and procurement guidance for efficient AI (Public Policy)
- Vision: Encourage adaptive tokenization practices to reduce energy use in public-sector AI deployments; standard reporting of “visual tokens per task.”
- Potential tools/workflows: Efficiency benchmarks in RFPs; carbon accounting tied to token budgets.
- Dependencies/assumptions: Measurement standards; stakeholder alignment; verification mechanisms.
- Workflow orchestrators with perception budgets (Cloud/Serverless)
- Vision: Schedulers that dynamically adjust
thetabased on queue length, cost ceilings, or promised latency. - Potential tools/workflows: Cost-aware routing; autoscaling triggered by tokens-per-second metrics.
- Dependencies/assumptions: Accurate, low-latency telemetry; stable quality under aggressive budget shifts.
- Vision: Schedulers that dynamically adjust
- Multimodal agents with uncertainty-aware perception (Agents/Automation)
- Vision: Agents that lower
thetafor routine observations and request more tokens on uncertainty or failure cases, reducing overall compute. - Potential tools/workflows: Agent frameworks with a “perception budget” action; active perception policies.
- Dependencies/assumptions: Reliable uncertainty estimates; safe fallback behaviors.
- Vision: Agents that lower
- Cross-domain tokenization for specialized imagery (Geospatial/Scientific/Manufacturing)
- Vision: Customize clustering thresholds/features for satellite, microscope, or inspection imagery where semantics differ from natural images.
- Potential tools/workflows: Domain adapters; hybrid features combining ViT with task-specific cues.
- Dependencies/assumptions: Domain data access; revalidation of thresholds; potential need for self-supervised adaptation.
Notes on Feasibility and Integration
- Encoder-agnostic but encoder-sensitive: DiVT works with CLIP/SigLIP/DINOv2; optimal
thetaand gains vary by encoder and domain. - Overhead vs. savings: Clustering requires pairwise similarities over ViT patches (typically O(N2) with N≈576). In production, use tiling, approximate neighbors, or fused kernels; savings scale with the fraction of compute/memory dominated by vision tokens and KV-cache.
- Variable token counts: Improves cost control but complicates batching and static-shape accelerators; use bucketing, padding, and scheduler support.
- Safety and robustness: While results show strong accuracy under tight budgets, edge cases (text-dense, medical, adversarial) require validation and may need higher
thetaor task-specific tuning. - Licensing and governance: Ensure compliance with model/data licenses and implement auditing for bias/hallucination, especially in regulated domains.
Overall, DiVT enables practical, immediate efficiency wins for multimodal systems while opening a broader roadmap toward standardized, word-like visual representations that scale across devices, domains, and future hardware.
Glossary
- Byte Pair Encoding (BPE): A subword tokenization algorithm that segments text into frequent symbol pairs to produce discrete tokens. Example: "Text tokens, in contrast, are generated by discrete tokenizers such as Byte Pair Encoding (BPE)~\cite{bytepairencoding}, which segment text into fixed, independent units with limited inter-token interactions."
- Centroid: The representative feature (patch) chosen as the center of a cluster in feature space. Example: "The chosen node becomes the centroid of the first cluster , denoted by , and all neighboring nodes to it construct the cluster ."
- CLIP: A vision-language pre-trained model used as a vision encoder for mapping images into a semantic embedding space. Example: "a pre-trained vision encoder (\eg CLIP~\cite{clip}, SigLIP~\cite{SigLIP}) to map the pixel-level signals to a semantic latent space."
- CLS token: A special classification token used in transformer encoders to summarize global information. Example: "commonly by measuring their similarity to a global CLS token or text embedding"
- Cluster refinement: A step that reassigns patches to the nearest centroid to form semantically coherent clusters. Example: "Cluster refinement for semantically more coherent groups (\cref{sec:method:refine});"
- Cluster-restricted attention mask: An attention mask that limits aggregation to patches within a cluster to ensure disentangled tokens. Example: "we apply a cluster-restricted attention mask:"
- Contrastive learning: A pre-training objective that pulls semantically similar representations together and pushes dissimilar ones apart. Example: "especially under image-level pre-training objectives such as contrastive learning or classification."
- Cosine similarity: A similarity measure between vectors based on the cosine of the angle between them. Example: "we compute the patch-wise cosine similarity matrix ."
- Cross-attention: An attention mechanism where one set of queries attends over another set of keys/values to aggregate information. Example: "Specifically, we adopt cross-attention using the centroid as the query:"
- Disentangled Visual Tokenization (DiVT): The proposed clustering-based tokenization that forms semantically coherent, concept-level visual tokens. Example: "We propose a novel Disentangled Visual Tokenization\ (DiVT) that clusters patch embeddings into coherent semantic units,"
- Dynamic token allocation: Adjusting the number of tokens per image based on its semantic complexity. Example: "Our design incorporates dynamic token allocation; that is, the number of tokens to represent an image is adaptively determined by its content."
- FlashAttention: A memory-efficient attention implementation used to accelerate transformer inference/training. Example: "can interact unpredictably with kernel-level optimizations like KV-cache policies or FlashAttention."
- Grid-wise aggregation: Methods that group adjacent patches on a fixed grid to reduce token count. Example: "grid-wise aggregation that downsamples tokens via spatial grouping or patch aggregation~\cite{pixel-shuffle, li2025tokenpacker}."
- KV-cache: Cached key/value tensors in transformer inference to speed up autoregressive decoding but increase memory usage. Example: "leading to semantically entangled and redundant representations that inflate KV-cache size and latency without commensurate accuracy gains."
- LLMs: High-capacity transformer-based models trained on large text corpora for language understanding and generation. Example: "LLMs have shown remarkable capabilities in understanding and generating language through fine-grained textual representations."
- Latent space: The continuous feature space where inputs are embedded to capture semantic structure. Example: "to map the pixel-level signals to a semantic latent space."
- MLP projector: A linear or feed-forward layer that maps vision features into the LLM embedding space. Example: "Visual tokens from the MLP projector reveal significantly higher similarity of "
- Multimodal LLMs (MLLMs): LLMs augmented with vision (and possibly other) modalities for unified reasoning. Example: "Modern multimodal LLMs (MLLMs) typically keep the LLM fixed"
- Patch embeddings: Feature vectors obtained from fixed-size image patches by a vision encoder. Example: "clusters patch embeddings into coherent semantic units,"
- Patchification: Splitting an image into fixed-size patches prior to transformer encoding. Example: "This design adheres to the rigid patchification scheme of ViT~\cite{vit}, which evenly splits an image into a set of fixed-size image patches."
- Positional embedding: Learnable vectors added to features to encode spatial position. Example: " is a learnable positional embedding that provides spatial context."
- Query–Key–Value projections (WQ, WK, WV): Linear mappings producing queries, keys, and values for attention. Example: "where {$\mathbf{W}^{\{Q,K,V\}$ are learnable parameters, and} is a learnable positional embedding that provides spatial context."
- Resampler: A module that summarizes global visual features into a compact token set via learned queries and attention. Example: "Resampler-based approaches~\cite{li2023blip, dai2023instructblip, qwenvl} generate a compact set of learnable queries that summarize information by globally attending to all visual features,"
- Self-attention: A mechanism where tokens attend to each other within the same sequence to mix contextual information. Example: "they have already undergone multiple layers of self-attention in the vision encoder."
- Semantic disentanglement: Representations that isolate distinct concepts rather than mixing multiple semantics. Example: "we refine the cluster assignment for better semantic disentanglement across the clusters."
- Semantic granularity: The fineness or coarseness of semantic grouping within tokens. Example: "The similarity threshold serves as a principled means to control the semantic granularity of the resulting visual tokens."
- SigLIP: A vision-language pre-trained model similar to CLIP with a sigmoid loss; used as a vision encoder. Example: "a pre-trained vision encoder (\eg CLIP~\cite{clip}, SigLIP~\cite{SigLIP}) to map the pixel-level signals to a semantic latent space."
- Similarity threshold (θ): The cosine-similarity cutoff controlling neighbor definition and token granularity. Example: "We define the patches whose pairwise similarity exceeds some threshold as neighbors."
- Token budget: The number of visual tokens allocated to represent an image, affecting accuracy and compute. Example: "DiVT\ further adapts its token budget to image complexity,"
- Tokenizer (visual tokenizer): A module that converts visual features into token sequences suitable for an LLM. Example: "We evaluate our LLM-friendly visual tokenizer across a broad suite of multimodal benchmarks under varying token budgets."
- Vision encoder: The backbone that converts images into feature embeddings (e.g., CLIP, SigLIP). Example: "a pre-trained vision encoder (\eg CLIP~\cite{clip}, SigLIP~\cite{SigLIP}) to map the pixel-level signals to a semantic latent space."
- Vision Transformer (ViT): A transformer-based vision backbone operating on image patches. Example: "This design adheres to the rigid patchification scheme of ViT~\cite{vit}, which evenly splits an image into a set of fixed-size image patches."
- Visual projector: The adapter mapping visual features into the LLM’s embedding space as tokens. Example: "train a visual projector that maps the pixels into a sequence of tokens in its embedding space,"
- Visual tokenization: The process of converting image features into token sequences for LLM consumption. Example: "current visual tokenization relies on spatial operations with no principled way to control how finely or coarsely an image is partitioned in a manner compatible with LLM-based reasoning."
Collections
Sign up for free to add this paper to one or more collections.

