- The paper introduces NBPL to quantify posterior uncertainty over policy assignments using a Dirichlet process prior.
- It demonstrates efficient Bayesian computation via the Bayesian bootstrap, achieving minimax-optimal regret contraction.
- Empirical results show adaptive tree-based policies outperform linear rules in experiments like JTPA and bednet subsidies.
Nonparametric Bayesian Policy Learning: An Expert Overview
Introduction and Context
"Nonparametric Bayesian Policy Learning" (2605.17068) introduces a framework, NBPL, for statistical treatment choice that explicitly quantifies posterior uncertainty over policy assignments and welfare in program evaluation. The decision-maker (DM) is tasked with maximizing expected social welfare by allocating treatments (interventions) to heterogeneous units, leveraging observable covariates. Departing from conventional plug-in and empirical welfare maximization (EWM) approaches, this framework employs a nonparametric Dirichlet process (DP) prior over a reduced-form distribution that captures all welfare-relevant information. NBPL thus enables uncertainty-aware inference for optimal treatment rules, welfare, and model comparisons across policy classes.
The DM targets maximal welfare by assigning individuals to treatment or control based on covariates X, with potential outcomes (Y(1),Y(0)). The action space is a class of policies G, each G∈G corresponding to a subset of the covariate space receiving treatment. The welfare objective is normalized against the status quo:
W(P0;G)=EP0[(Y(1)−Y(0))I{X∈G}].
This welfare is fully determined by a reduced-form distribution P0 over ((Y,T,X)), under standard identification (external validity, unconfoundedness, finite moment, and known propensity score). The sole inferential challenge is thus posterior uncertainty about P0.
The NBPL Framework
NBPL’s core innovation is to treat P0 as a random probability measure endowed with a Dirichlet process prior, DP(α), for flexible nonparametric modeling. Posterior inference for (Y(1),Y(0))0 induces posteriors over the set of optimal policies (Y(1),Y(0))1 and optimal welfare (Y(1),Y(0))2. This approach enables comprehensive inference for:
- Optimal Welfare: Bayesian posterior median and credible intervals.
- Optimal Policy Set Membership: Posterior probability that a policy is optimal or satisfies constraints.
- Model Comparison: Posterior probabilities for which policy class (e.g., linear vs. tree) achieves superior welfare.
All such statements are with respect to a well-defined posterior, promoting formal uncertainty quantification absent in frequentist plug-in or EWM methods.
Computational Implementation
Efficient Bayesian computation is achieved via the Bayesian bootstrap (Rubin's Bayesian bootstrap), leveraging the conjugacy and discrete sampling properties of the DP. For each posterior sample:
- Draw normalized Exponential(1) weights.
- Reweight the observed data accordingly.
- Solve the (possibly constrained) empirical welfare maximization problem for the chosen policy class, using standard algorithms.
This facilitates direct, scalable computation, with the posterior draws supporting estimation of any functionals of interest.
Theoretical Guarantees
NBPL is validated by two core theoretical results:
1. Posterior Regret Contraction
Let (Y(1),Y(0))3 be a finite VC-dimension class. Then, as (Y(1),Y(0))4, the posterior for welfare regret,
(Y(1),Y(0))5
contracts at the minimax-optimal EWM rate:
(Y(1),Y(0))6
where (Y(1),Y(0))7 is the VC dimension. Incorporating posterior uncertainty does not slow the learning rate relative to frequentist empirical welfare maximization (2605.17068).
2. Consistent Model Comparison
Posterior probabilities for the correct welfare ranking between policy classes are pointwise consistent: as (Y(1),Y(0))8,
- If classes are strictly separated (in welfare), the posterior probability of correctly identifying the superior class converges to one.
- If not, the posterior concentrates on arbitrarily small differences.
This yields a rigorous Bayesian decision-theoretic rationale for model selection across non-nested policy classes, an area where frequentist methods (in policy learning) are underdeveloped.
Empirical Illustration and Numerical Results
NBPL's practical relevance is demonstrated with two benchmark experiments:
Job Training Partnership Act (JTPA) Experiment
NBPL is compared to EWM using linear and depth-2 tree policy classes. Key findings:
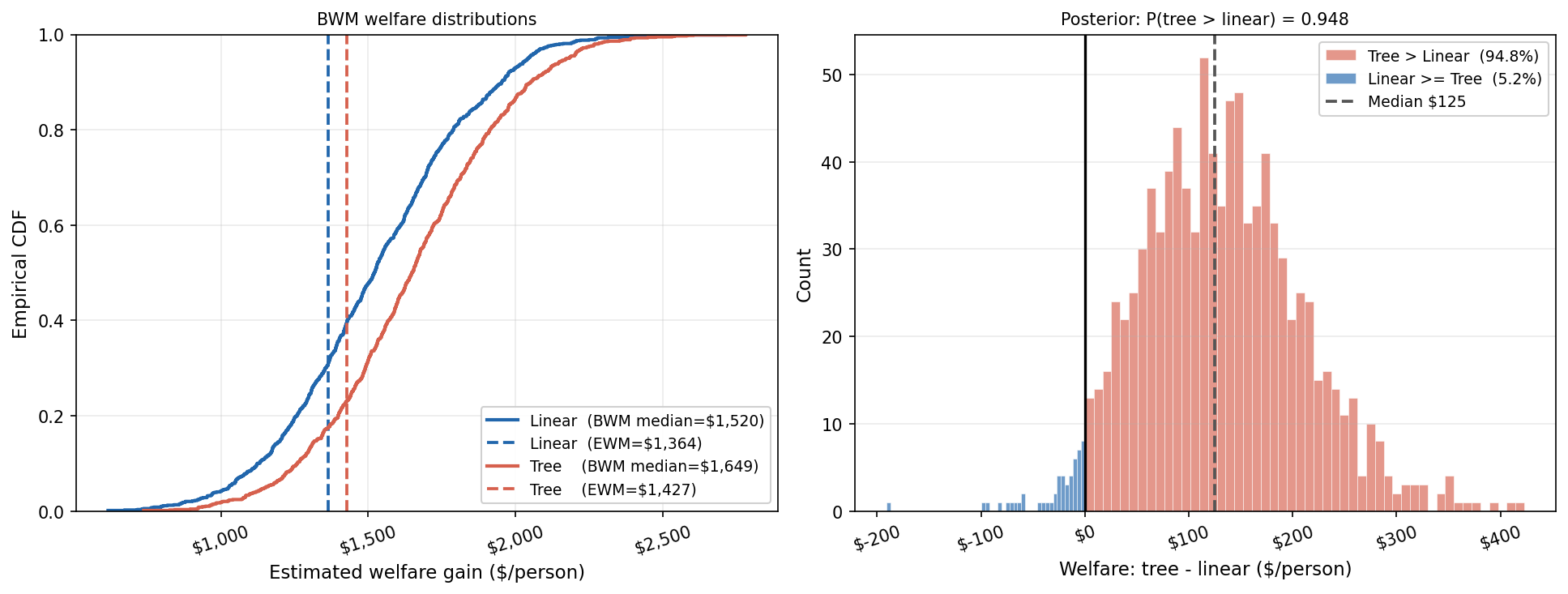
Figure 1: Posterior CDFs of optimal welfare under linear and tree-based policies for the JTPA experiment, indicating first-order stochastic dominance and sharper NBPL credible intervals.
- Posterior welfare distributions for trees dominate those for linear rules; the posterior probability that trees outperform linear rules is 94.8%.
- NBPL credible intervals are notably tighter than EWM’s bootstrap confidence intervals, with EWM estimates often lying below the NBPL posterior median.
Bednet Subsidy Experiment
The targeted assignment of subsidies is studied under unconstrained and 70% capacity-constrained scenarios:
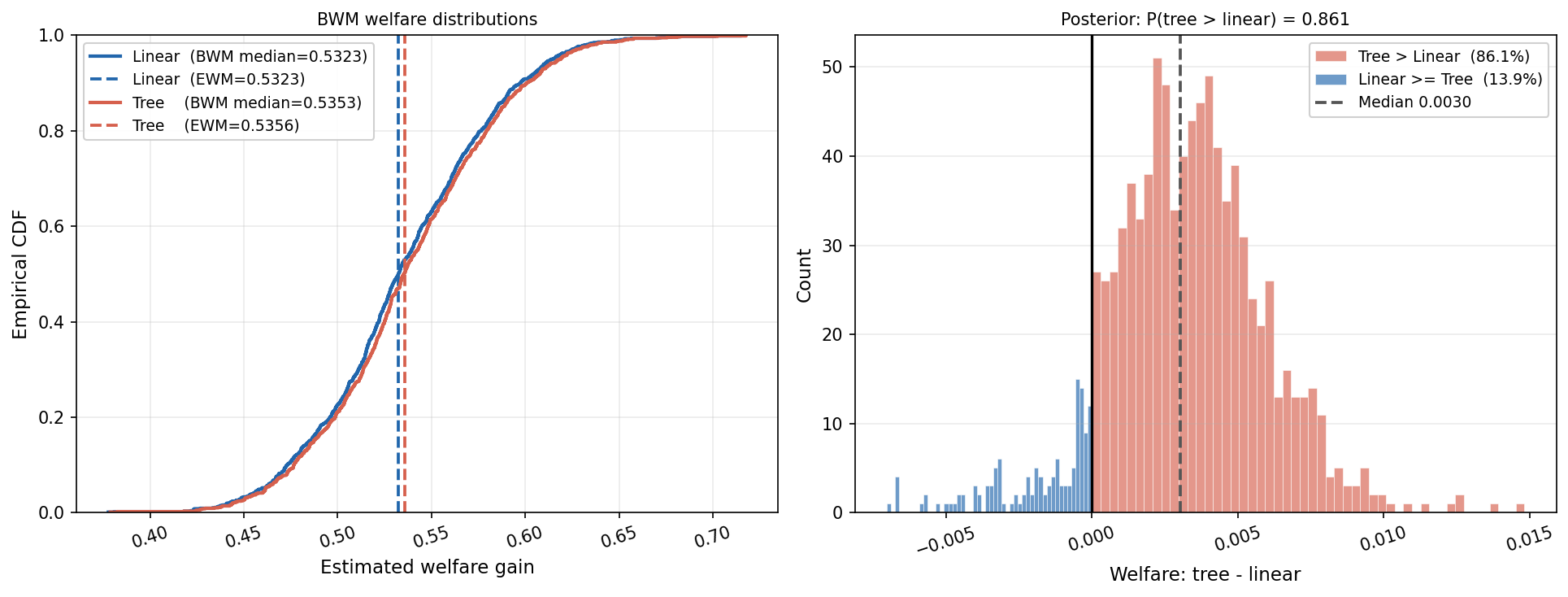
Figure 2: Posterior welfare distributions for linear vs. tree policies without capacity constraint in the bednet experiment. Tree-based policies marginally outperform linear rules.
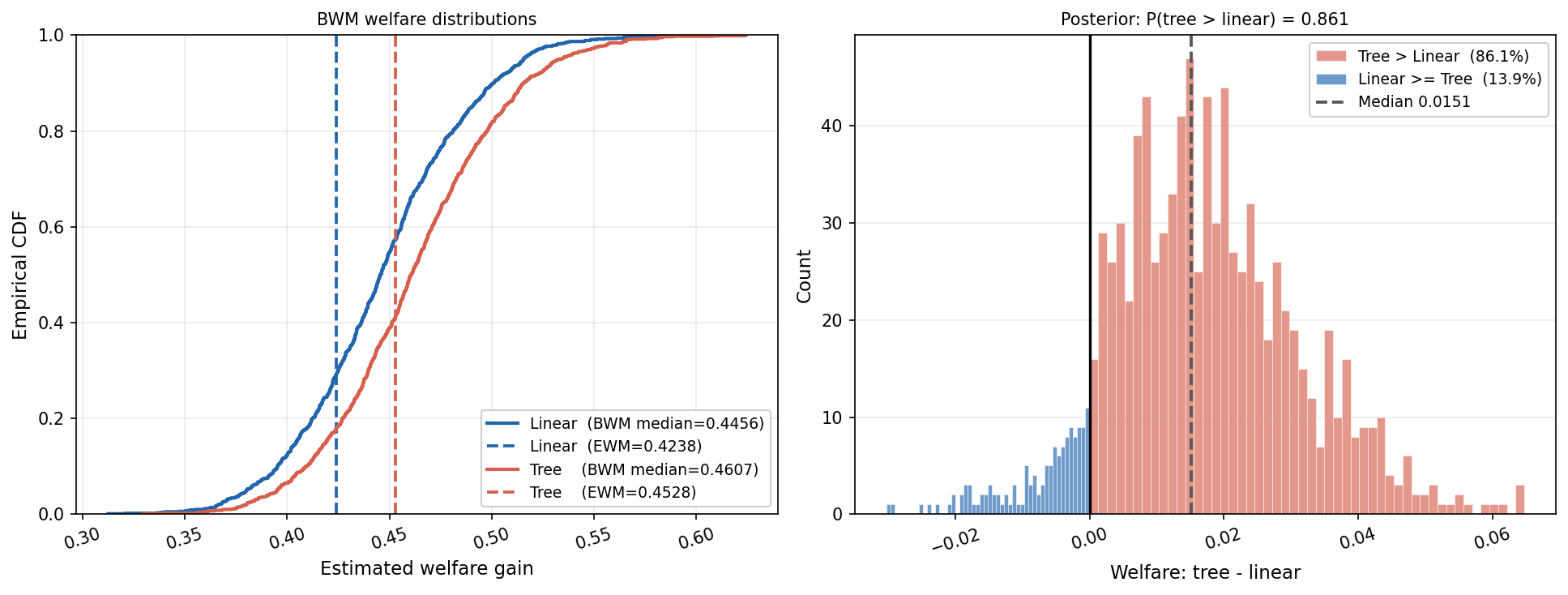
Figure 3: With a 70% capacity constraint, tree-based policies more clearly dominate linear rules, with greater welfare differences but moderate overall probabilities.
- Capacity constraints amplify the welfare advantage of adaptive (tree-based) policies.
- Model comparison probabilities climb but remain moderate (approx. 86%), underscoring the value of formal uncertainty quantification.
Relationships to Prior Literature
- Empirical Welfare Maximization: NBPL subsumes EWM as the Bayes rule minimizing posterior mean regret under a Bayesian bootstrap prior, but EWM averages-then-optimizes, whereas NBPL infers the distribution of the optimal rule.
- Uncertainty-Aware Treatment Choice: NBPL generalizes prior Bayesian decision-theoretic analysis for limited-information settings [chamberlain2011bayesian], handling partially identified rules, continuous distributions, and constrained classes.
- Nonparametric Bayesian Inference: By employing the Dirichlet process, NBPL enjoys large support and conjugacy, supporting analogues of nonparametric frequentist theory in the Bayesian regime [ghosal2017fundamentals].
Implications and Future Directions
NBPL provides a unified, uncertainty-aware Bayesian framework for treatment assignment, welfare evaluation, and policy class selection. Its strong numerical properties—minimax posterior regret and consistent model comparison—are supported by tractable computation and offer tighter uncertainty quantification than prevailing frequentist benchmarks.
Practical implications include:
- Transparency: Posterior statements about both welfare and policy set membership support evidence-based transparent policy recommendations.
- Flexibility: The DP prior can be augmented via external knowledge, generative models, or alternate welfare criteria with minimal modification.
- Parallelizability: Bootstrapped computation enables large-scale adoption in empirical policy analytics.
Theoretical implications extend to posterior contraction, decision-theoretic interpretations of classical estimators, and nonparametric uncertainty quantification.
Future directions involve:
- Unknown propensity scores: Extending identification and robustification in observational or quasi-experimental settings.
- Ambiguity and partial identification: Integrating ambiguity-averse decision-making and partial identification into Bayesian policy learning, to reflect both statistical and model-based uncertainty.
- Complex policy classes: Scaling methods to high-dimensional, dynamic, or networked treatment assignments, subject to computational and statistical guarantees.
Conclusion
NBPL constitutes a rigorous, computationally efficient, and theory-grounded Bayesian solution to policy learning, supplementing and extending the frequentist paradigm. By capturing the full spectrum of uncertainty in both optimal welfare and policy choice, the framework advances methodological standards for individualized treatment assignment and program evaluation. Its implications are broad, with promising avenues for integration with robust statistics, modern machine learning, and real-world decision analysis.

