- The paper demonstrates that prompt-driven DSL generation using open-source LLMs yields both syntactically valid and semantically rich models without fine-tuning.
- The methodology employs structured prompts, iterative temperature reduction, and dual evaluation (automated parsing and expert review) to ensure DSL accuracy.
- The evaluation reveals that compact, instruction-tuned LLMs can achieve comparable grammar conformity and domain completeness to larger models for low-code applications.
Introduction
The paper "From Text to DSL: Evaluating Grammar-Based Model Generation Using Open LLMs" (2605.15865) systematically examines the DSL model generation capabilities of open-source LLMs, specifically focusing on syntactic validity, semantic completeness, and reference consistency. The study leverages few-shot prompting without model fine-tuning and extends prior work by not only generating UI models from natural language but also inferring and constructing data models, thereby increasing task complexity. The evaluation encompasses 39 LLMs ranging from 0.5B to 32B parameters, spanning multiple architectures, and emphasizes prompt engineering as the sole mechanism to guide model outputs.
Model-Based Approach and Evaluation Pipeline
The methodology is grounded in a modular pipeline which ingests a user's natural language application specification—e.g., “I want to create the website for an online ice cream parlour”—and sequentially generates the conceptual data model and UI model via LLM inference. Both grammar definition and domain semantics are embedded in structured prompts. All generated outputs are validated through automatic parsing (LARK framework) and human expert evaluation.
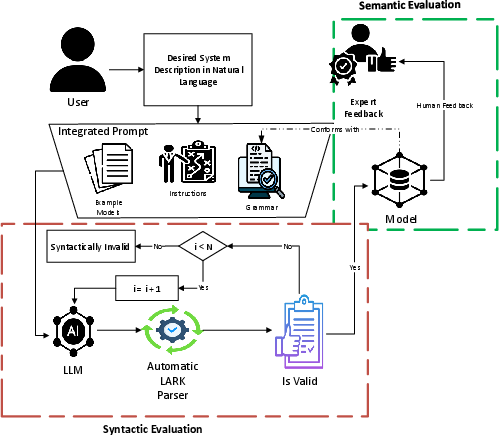
Figure 1: Pipeline overview illustrating prompt-driven DSL generation and multi-stage syntactic and semantic evaluation.
The process comprises:
- Concept extraction: LLMs are prompted to identify key entities, attributes, and relationships.
- DSL synthesis: Strict grammar conformance is enforced via prompt constraints (cardinality, enums, subset of, references, etc.).
- Syntax validation: Outputs are parsed for token-level errors and resolved via iterative retries with reduced temperature.
- Semantic review: Expert evaluation addresses domain correctness, covering advanced features such as ratings, promotions, and delivery tracking.
LLM Selection and Prompt Engineering
The study targets a heterogeneous sample of open LLMs: LLaMA, Qwen2, Phi, Gemma, GraniteMoE, StableLM, and others. Model variants include general-purpose, instruction-tuned, and code-centric flavors. The unified prompt template incorporates the DSL grammar, sample models, the inferred data model, and the user’s original specification. Strict directives are applied to enforce grammar conformity and encourage semantic expansion.
The reliance on prompt engineering, without fine-tuning or retraining, is central—addressing scalability and deployability constraints that hinder adoption of large closed models. The systematic retry loop on parsing failure, with progressive temperature reduction, ensures syntactic validity and leverages the stochastic nature of LLM outputs for robustness.
Human-Centered Semantic Evaluation
In addition to automatic parsing, DSL models are assessed by domain experts across four axes: Semantic Correctness, Concept Identification, Completeness, and Advanced Feature Coverage. Scores use a Likert scale (1-5), and the web-based interface standardizes participant input, demographic tracking, and criteria display.
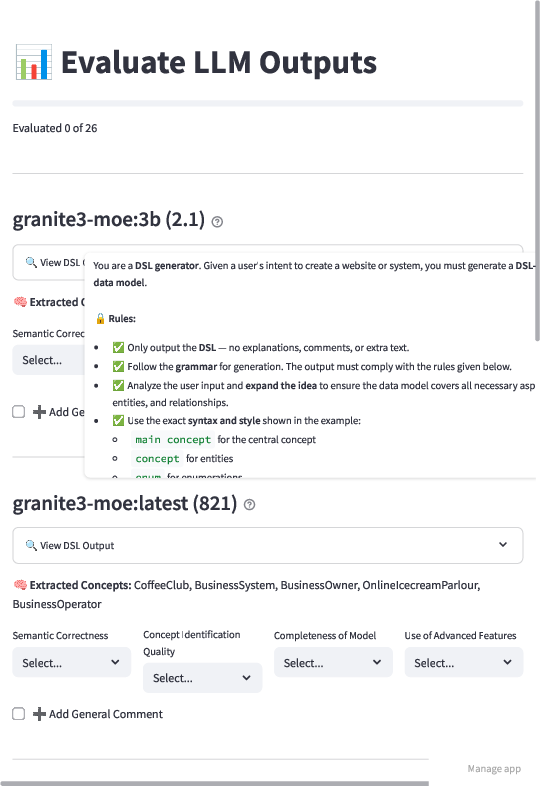
Figure 2: Interactive expert evaluation platform capturing experiment selection, demographic input, and detailed model review with syntactic and semantic highlight.
This two-pronged approach—structural and semantic—enables fine-grained discrimination between models that merely satisfy grammar and those that generate domain-complete, semantically rich outputs.
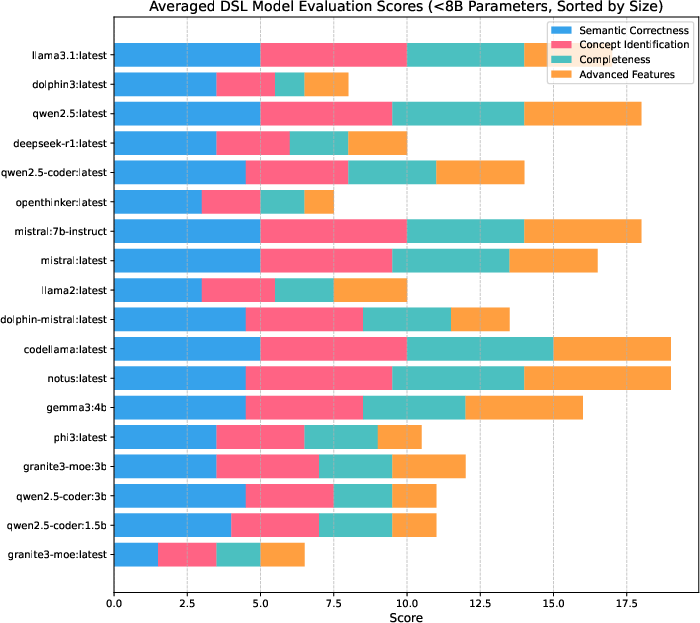
Out of 39 evaluated LLMs, 26 produced at least one syntactically valid DSL within retry constraints. Among these, notable compact models (e.g., gemma3:12b, mistral:7b-instruct) achieved semantic scores comparable to larger models (e.g., phi4:latest). Top-performing models consistently incorporated advanced semantics, including enums and constrained relationships.
Strong numerical results include:
These findings directly address RQ1 (small/mid-size LLM DSL generation capability vs large models) and RQ2 (efficacy of prompt engineering without fine-tuning).
Implications and Future Directions
The demonstrated viability of prompt-driven DSL generation using small and mid-sized open-source LLMs has substantial implications for MDE and low-code/nocode platforms:
- Cost and deployment efficiency: Models with modest compute footprints can produce grammar-conformant, semantically rich outputs, enabling private, edge, or enterprise-controlled deployments over proprietary SaaS LLMs.
- Model-driven application synthesis: Reliable structural inference and inter-model reference resolution by LLMs supports automation and democratization of software modeling, reducing manual overhead.
- Prompt-centric workflows: Structured prompts and retry-based syntactic validation provide practical pathways to harness LLM capabilities for DSL tasks, circumventing training data sparsity and fine-tuning obstacles.
Further research trajectories include fine-tuning compact LLMs for DSL-specific tasks, multi-turn interactive refinement workflows, and tighter integration of automated verification/repair tools for correctness and semantic alignment.
Conclusion
The systematic evaluation establishes that compact, open-source LLMs, properly guided by grammar-aware prompt engineering, can reliably synthesize DSL-conformant models directly from text inputs. Instruction-tuned models yield consistently superior outputs, and prompt design significantly mitigates dependencies on model scale. The results substantiate the practical feasibility of deploying lightweight LLMs for grammar-based modeling in low-code and MDE platforms, suggesting fertile ground for future investigation into prompt optimization, refinement pipelines, and domain-specialized LLM customization.