- The paper introduces a lightweight, dimensional memory system that structures agent memory into distinct fields for improved retrieval fidelity and efficient updates.
- It employs dimension-aware extraction and tri-path (lexical, semantic, and explicit) retrieval strategies, achieving 81.43% and 78.20% QA accuracy on key benchmarks.
- Its schema-driven design reduces token consumption by up to 75%, demonstrating that compact models can effectively learn structured memory representations.
DimMem: Dimensional Structuring for Efficient Long-Term Agent Memory
Introduction and Motivation
LLM agents increasingly serve as persistent, interactive assistants, necessitating robust long-term memory capabilities spanning personalization, temporal continuity, knowledge update, and multi-session tracking. Conventional memory systems for LLM agents typically balance a trade-off between high-fidelity raw context storage—which is costly in terms of storage and computational resources—and fact or summary-based approaches, which sacrifice representational richness necessary for precise and contextually aware recall. DimMem addresses this core challenge by introducing a lightweight, dimensional memory framework: each memory is encoded as an atomic, typed, self-contained unit, with explicit dimensions such as time, location, reason, purpose, and keywords. This schema not only augments retrieval fidelity and operational efficiency but also systematically exposes structure critical for nuanced reasoning and context-sensitive updates.
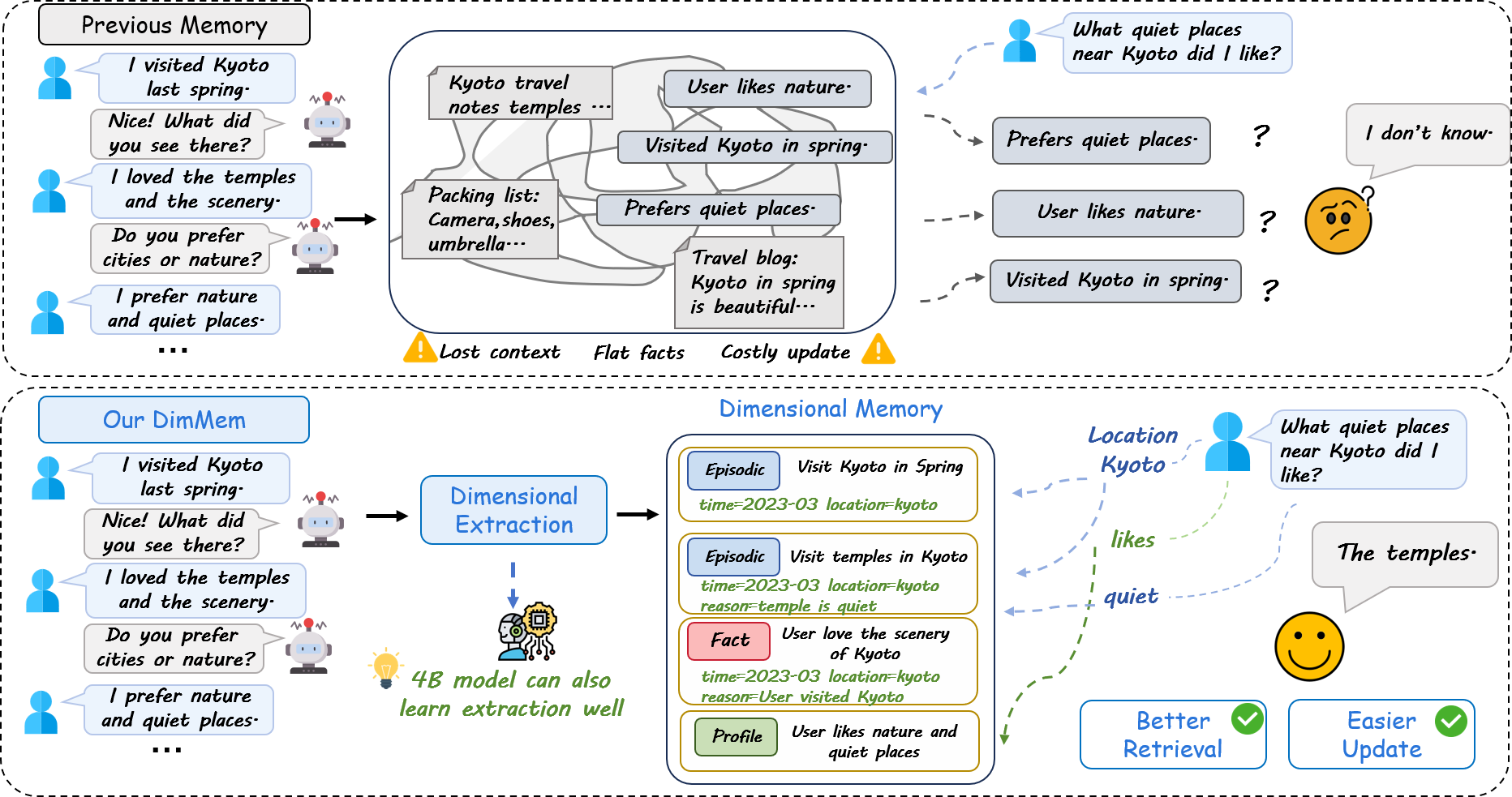
Figure 1: Prior memory systems entangle or flatten memory, hampering efficient update and retrieval; DimMem explicitly structures each unit along key operational dimensions.
Dimensional Memory Representation and System Architecture
DimMem operationalizes memory as structurally typed records. Each entry is annotated with an explicit memory type (fact, episodic, profile) and decoupled fields for time, location, reason, purpose, and typed keywords. Importantly, these fields are not just metadata—for DimMem they define the core operational interface that coordinates extraction, intent parsing, retrieval, update, and even selective context reconstruction.
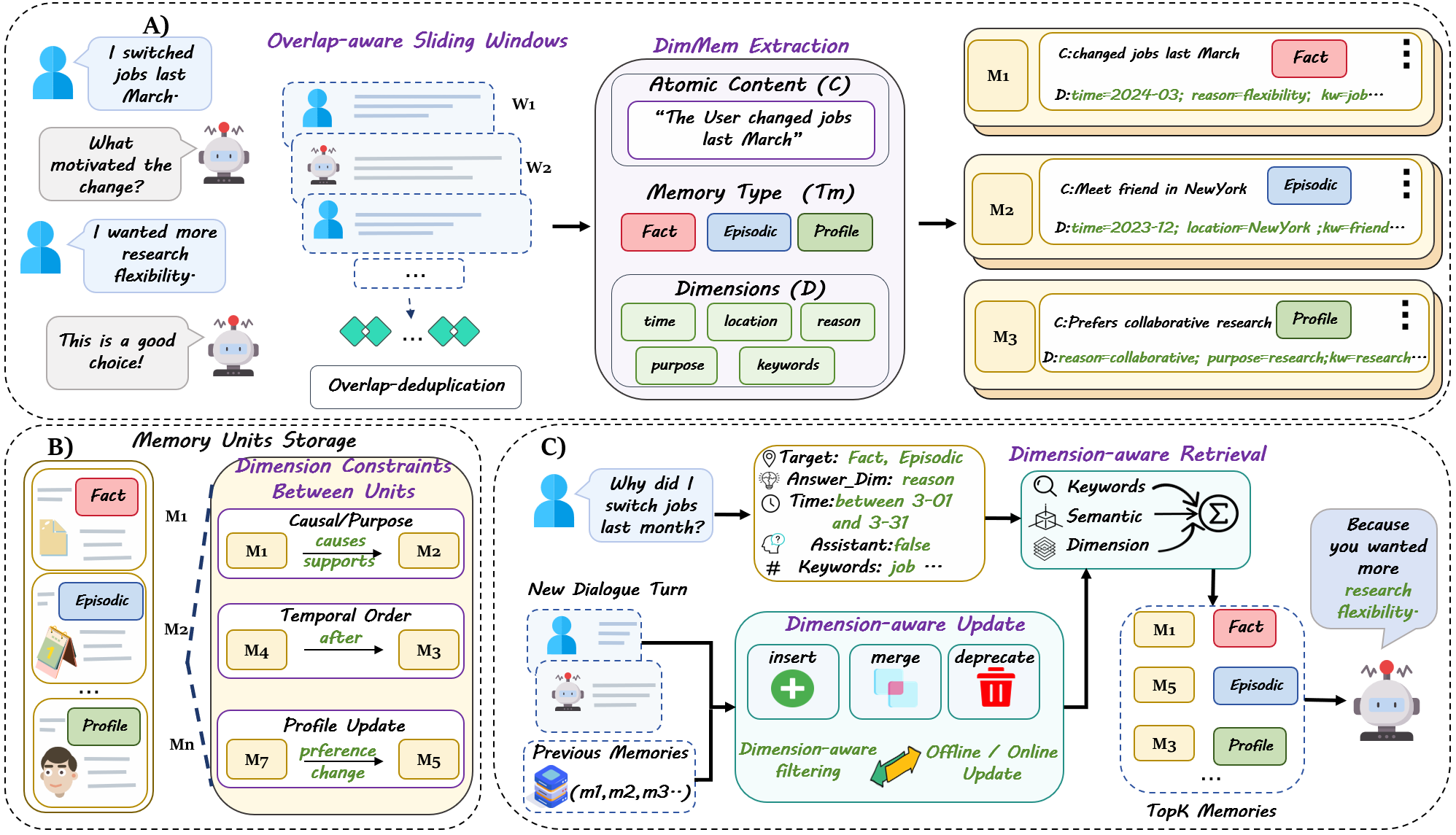
Figure 2: DimMem segments dialogue into atomic, structured units, supporting dimension-aware retrieval, cross-memory relations, and context-efficient update.
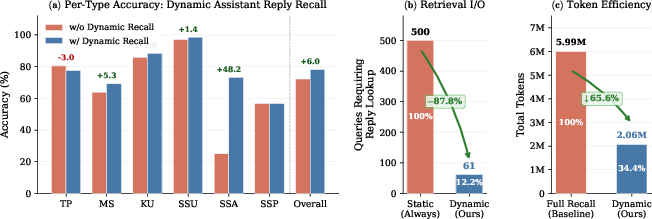
Dialogues are segmented via overlap-aware sliding windows, ensuring local coherence and robust boundary detection for atomic event extraction. Parsed queries are mapped to the same dimensional schema, enabling tri-path retrieval: (1) lexical, (2) dense semantic, and (3) explicit dimension-based matching. Memory update is similarly dimension-aware, filtering candidates for merging, superseding, or retention by leveraging type and keyword constraints prior to expensive embedding comparison and LLM-based consolidation. Critically, DimMem supports dynamic assistant recall, returning to the original assistant utterance only when a query specifically warrants it, which drastically reduces unnecessary context augmentation.
Dimension-Aware Extraction and Learning
DimMem separates the extractor (responsible for generating structured records from raw interactions) from the QA system, demonstrating that dimensional extraction is not contingent on large proprietary LLMs. The pipeline leverages SFT with compact models (notably, Qwen3-4B via LoRA fine-tuning) trained on schema-consistent, teacher-generated (GPT-5.4) supervision derived from both LoCoMo-10 and LongMemEval-S. This explicit schema learning proves sufficient for high-quality, efficient extraction without reliance on massive underlying models, matching or surpassing prior lightweight systems in both accuracy and efficiency.
Empirical Results
DimMem is evaluated against state-of-the-art lightweight and retrieval-augmented memory systems on the LoCoMo-10 and LongMemEval-S benchmarks, reflecting generative long-term conversational memory and assistant-side recall, respectively. DimMem achieves 81.43% and 78.20% overall QA accuracy on LoCoMo-10 and LongMemEval-S, outperforming all baselines (including LightMem and SimpleMem) while reducing per-query token consumption by 24% in the LoCoMo setting and substantially decreasing candidate pairs for memory update.
Key numerical results and behavior include:
Operational Efficiency and Memory Update
DimMem’s structural design also provides substantial gains in update efficiency. By using type and keyword overlap as a candidate filter, embedding-based operations for update are reduced by over 75% on LongMemEval and nearly 60% on LoCoMo, with no reduction in merge discovery—indicating dimension fields not only speed up update, but also enhance consolidation quality.
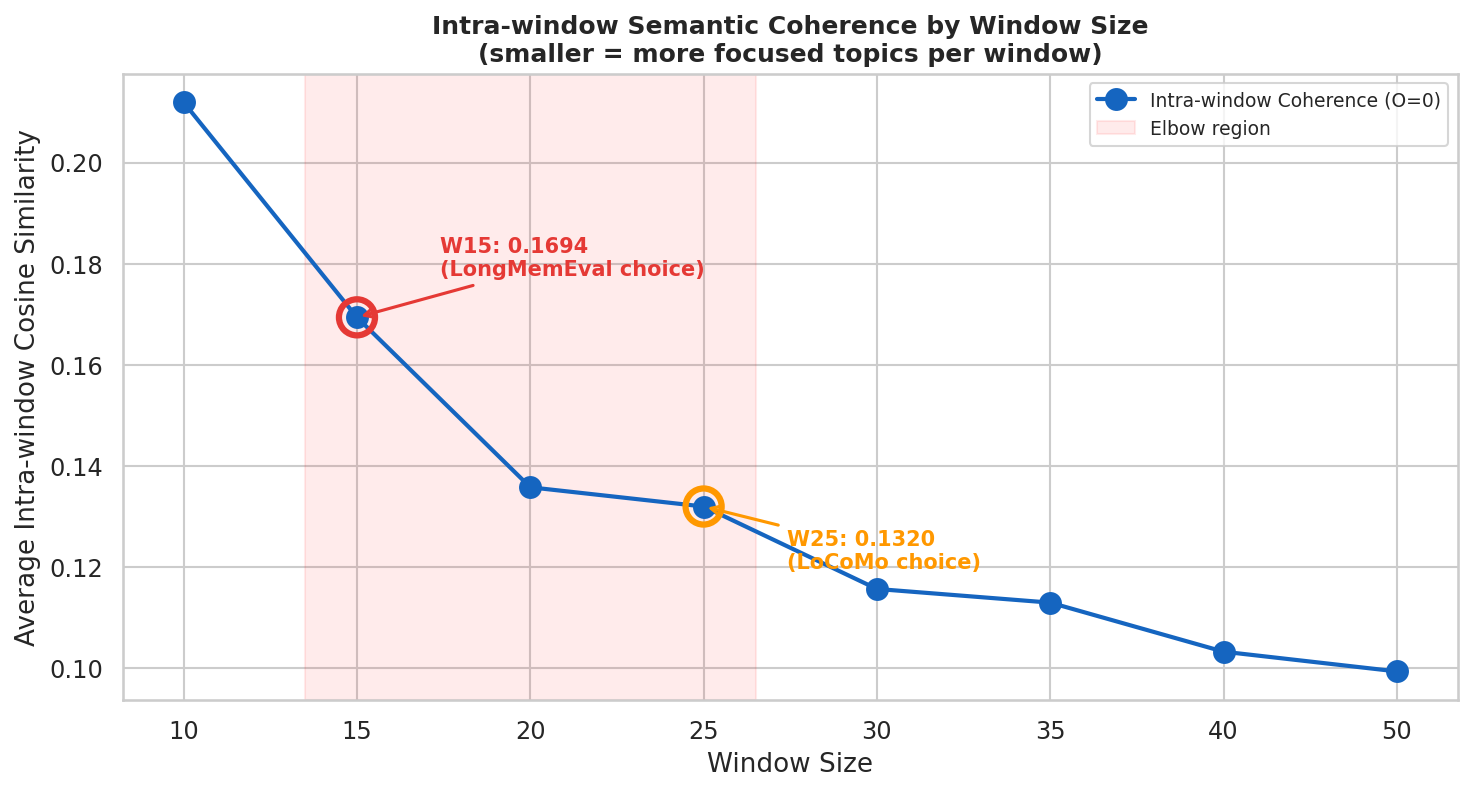
Figure 4: Intra-window semantic coherence drops as window size increases; DimMem selects small, high-coherence windows for optimal balance between extraction context and segment size.
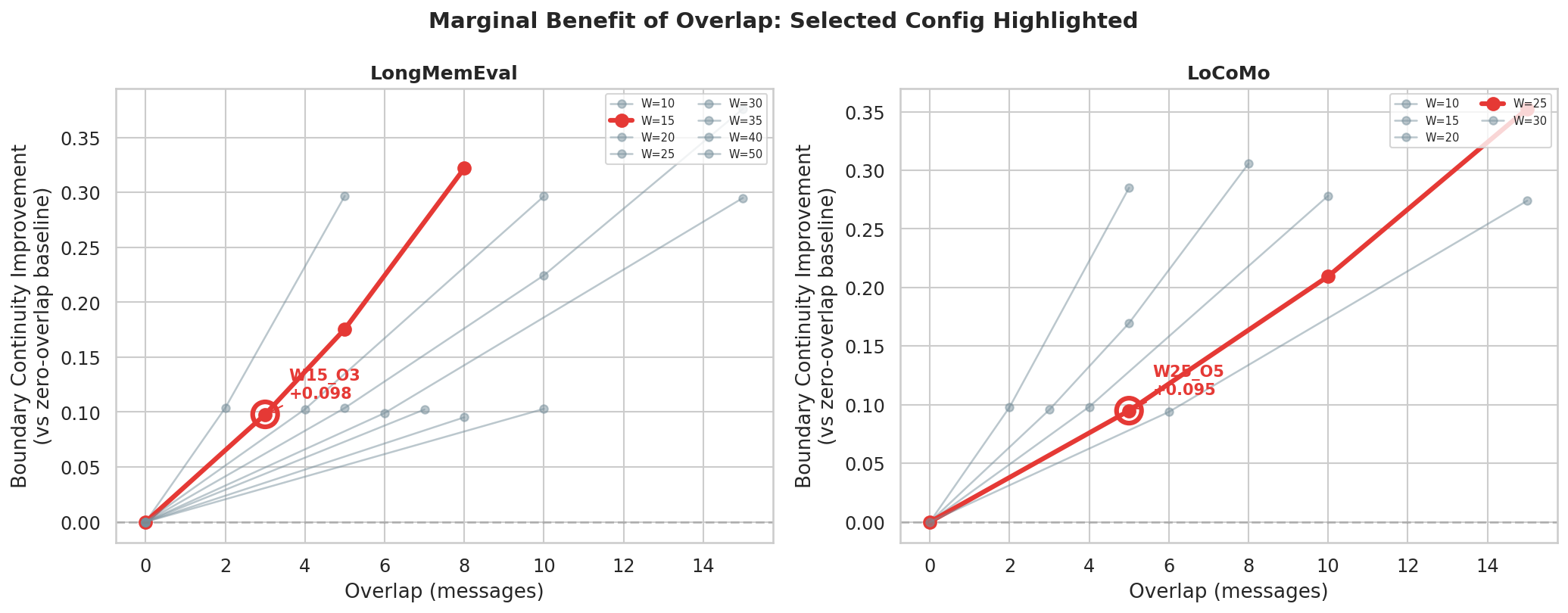
Figure 5: Both LongMemEval and LoCoMo select a 20% overlap ratio—yielding efficient, contextually continuous extraction while keeping cost low.
Theoretical and Practical Implications
DimMem’s results substantiate several major claims:
- Explicit dimensional structuring is a strong inductive bias for the design of agent memory systems, supporting both efficient, high-quality recall and robust scaling to session- and knowledge-dependent queries.
- Structured extraction capabilities are learnable by compact models, diminishing dependence on expensive, proprietary LLMs for memory construction.
- Schema-driven memory design disambiguates control and reasoning from surface representation, enabling system developers to extend or specialize fields based on application context.
Practically, these advances will facilitate persistent, resource-efficient agent deployments in long-running conversational and multi-session environments, with direct applicability to personal assistants, multi-modal agents, enterprise chatbots, and interactive simulation environments. The explicit schema opens avenues for adaptation to multimodal memory (e.g., grounding images, documents, or code), privacy-preserving retrieval/updates, and robust consolidation in lifelong learning scenarios. On the theoretical side, DimMem aligns closely with cognitive accounts of episodic, semantic, and personal semantic memory, inviting future work in integrating richer cognitive structures or graph-based overlays as a thin extension on top of the atomic schema.
Conclusion
DimMem introduces a unified dimensional memory framework for LLM agents, advancing both theoretical structuring and practical efficiency in long-term conversational memory. Through atomic, typed, and multi-dimensional representation, DimMem demonstrably surpasses prior lightweight memory systems on complex QA and recall benchmarks, achieves compelling efficiency in extraction and update, and enables schema-driven memory learning in compact models. The implications span both scalable agent deployment and future research in structured, compositional agent memory design.