- The paper presents a modular agent that integrates executable statistical computation, symbolic KB matching, and iterative clarification to bolster clinical reasoning.
- It employs an IDF-weighted log-linear scoring system and TSA-generated trend predicates to ensure diagnostic transparency and robustness against temporal inconsistencies.
- Experimental results show improvements of up to 12 points on longitudinal benchmarks, highlighting enhanced safety, auditability, and performance in clinical decision support.
COTCAgent: Probabilistic Chain-of-Thought Completion for Longitudinal Clinical Consultation
Introduction and Motivation
The paper "COTCAgent: Preventive Consultation via Probabilistic Chain-of-Thought Completion" (2605.15016) introduces a hierarchical agent architecture targeting high-fidelity longitudinal clinical reasoning from irregular, label-sparse EHR data. Contemporary LLM-based systems for clinical decision support demonstrate limitations in numeric consistency, propensity for trend hallucination, and weak traceability from multimodal evidence through to diagnostic hypothesis formation. This work addresses the lack of fine-grained, programmatic statistics in current LLM pipelines and the difficulty of explicit, auditable inference over long-range temporal evidence.
System Architecture and Algorithms
COTCAgent adopts a modular stack that decouples statistical computation, symbolic feature matching, and NL-based completion:
1. Temporal-Statistics Adapter (TSA):
TSA maps NL clinical queries to analytic plans and generates executable code for trend extraction (e.g., mixed-effects models for continuous variables, Bayesian change-point routines for abrupt transitions). Typed statistical summaries (M:Q→Φ→Λ→C) guarantee that downstream symbolic layers operate on verifiable signal-level predicates, not heuristic free-text.
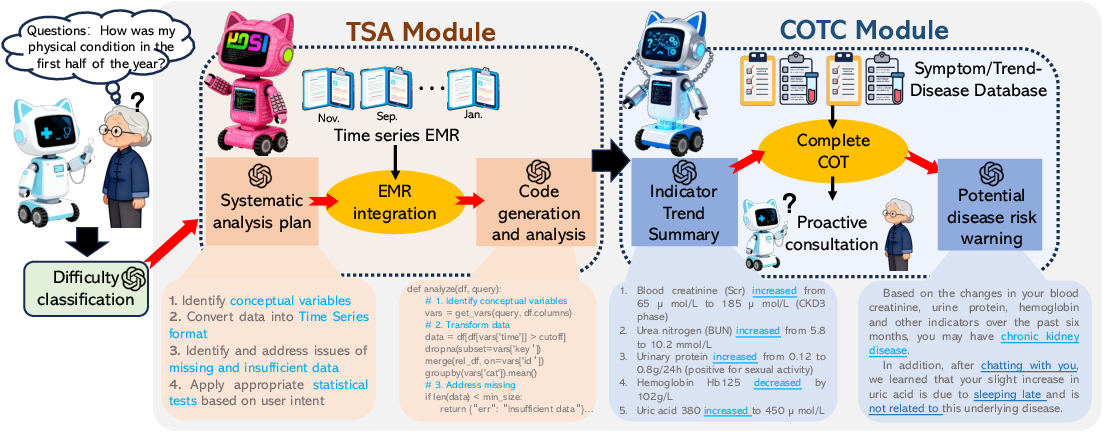
Figure 1: High-level architecture of COTCAgent showing TSA translation of raw longitudinal signals into predicates, which then drive KB scoring and targeted completion.
2. Chain-of-Thought Completion (COTC) Layer:
COTC matches extracted symptom and trend predicates against a curated Symptom–Trend–Disease knowledge base (KB) of 23k entities. Each disease is scored via an IDF-weighted log-linear aggregation (Gibbs energies), softmax-normalized among viable hypotheses. This process yields transparent, deterministic ranking distinct from probabilistic graphical models where global priors are absent.
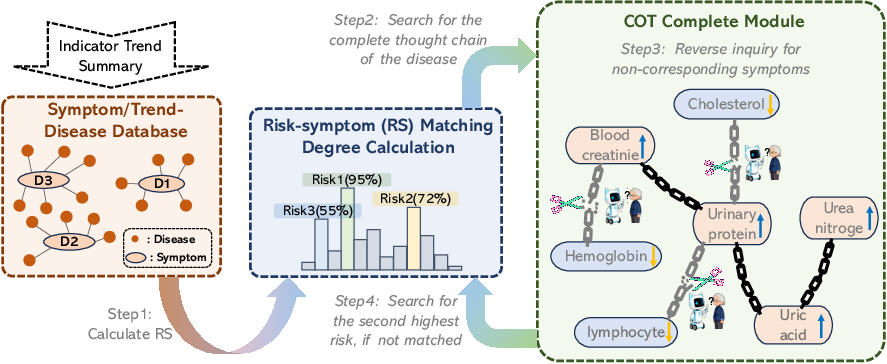
Figure 2: COTC module wiring—TSA summaries and structured cues are collated and scored via KB matching, which also enumerates missing evidential gaps.
3. Bounded Completion Module:
This logic generates one-turn, slot-filling clarification questions for ambiguous or underspecified gaps in the evidence, parses responses, and invokes an iterative re-scoring protocol. Stopping rules are rigorously defined in terms of the maximum softmax confidence, entropy, maximum rounds, or exhaustion of actionable gaps.
Explicit Failover and Provenance: All stochastic and NL-generative operations are isolated in well-defined modules. Statistical and KB failures are surfaced as explicit uncertainty signals, preventing the system from hallucinating metrics or inferences in low-confidence regimes.
Knowledge Base Construction and Matching
The knowledge base comprises 9,948 diseases, 8,673 symptoms, and 4,835 trends, constructed via LLM-augmented tuple proposal (with strict PHI scrubbing and clinician adjudication) from public medical resources and guidelines. All edges are versioned and reviewed, with 10% disease/edge holdout for validation and leakage prevention.
IDF Weighting: Diagnostic strength mirrors information retrieval: symptoms or trends that appear in fewer diseases are upweighted in the scoring function; common signals (e.g., fever) are penalized, increasing specificity. No calibration on actual prevalence or generative likelihoods is invoked, prioritizing auditable, explainable logic over maximum discriminative power.
Scoring and Completion: Disease hypotheses are scored as
Ri=sj∑(logwjIDF+logϕ(sj,di))+missing sj∑log(1−γwjIDF)
and normalized for ranking. Knowledge gaps (missing symptoms/trends) are prioritized via mass-weighted expected information gain. Completion questions close these gaps, updating evidence and rescoring.
Experimental Results
Benchmarks and Comparative Analysis
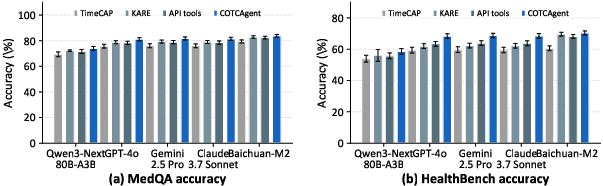
COTCAgent achieves strong performance on multiple longitudinal and conversational reasoning benchmarks, including MedQA, HealthBench, Time-MMD, and DiSCQ. Empirical evaluation is carefully constructed, with identical prompt/cap protocols across all agent backbones and ablations.
Ablation studies reveal that:
- TSA-autogenerated statistical predicates contribute incrementally to accuracy, mainly by strengthening temporal consistency and reducing hallucinated trends.
- The COTC tier and its IDF-weighted softmax produce significant gains by compressing evidence in the KB and efficiently staging high-value slot-filling questions.
- Full COTCAgent (TSA + COTC + bounded completion) delivers cumulative improvements up to 12 points over backbone-only variants.
Round-by-round attribution demonstrates that the majority of interactive consulting gain (∼70%) accrues from the first targeted clarification, substantiating the impact of the gap-to-question prioritization logic.
Qualitative Assessment and Representation Probes

Figure 4: Qualitative demonstration contrasting structured diagnostic reasoning (COTCAgent) and direct single-pass generation (frontier API readers) on identical prompts—COTCAgent yields fine-grained, evidence-traceable chains of logic.
Representation probing (coherence, temporal smoothness, semantic margins) validates that the architectural separation in COTCAgent leads to higher temporal fidelity and more distinct disease clustering at the embedding level, affecting both first-order reasoning and downstream interpretability.
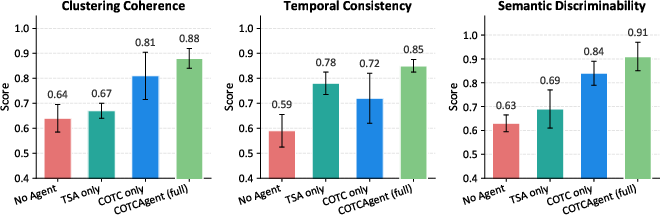
Figure 5: Representation probes—COTCAgent achieves higher coherence and semantic separation due to its modular, constraint-enforced architecture.
Knowledge Base Multiplicity and Robustness
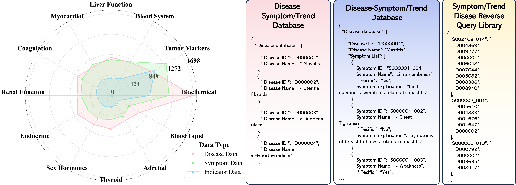
Figure 6: Radar plot summarizing entity multiplicity in the symptom–trend–disease KB, showing wide and diverse coverage critical for robust differential diagnosis.
KB edge ablations confirm that reduced edge coverage causes predictable, smooth degradation in performance but the system remains robust under moderate KB sparsity.
Discussion and Implications
COTCAgent demonstrates that programmatic, symbolically-grounded reasoning layers—bridging LLM planning, executable statistics, and interpretable symbolic matching—significantly improve the safety, auditability, and performance of clinical decision support agents in temporal, low-label environments. The transparency of diagnostic trajectories (from trend code to evidence contracts and explicit question-answering) enables post-hoc auditing and algorithmic fairness checks not tractable in end-to-end generative stacks. The formalism is extensible to other high-stakes domains where explainability and traceable evidence chains are prerequisites for deployment.
The framework's dependence on hand-curated, large-scale KBs is both a strength (for governance) and a limitation (for flexibility and coverage). Absent true population priors or real-time evidence integration, the system favors precision and interpretability rather than maximizing recall in under-curated clinical ontologies. Empirical improvements—while clear in retrospective and synthetic setups—require operational validation against real-world, prospectively collected EHR and in the presence of rare disease variants or adversarial noise.
Conclusion
COTCAgent establishes a reproducible, evidence-driven pipeline for probabilistic chain-of-thought completion in longitudinal clinical consultation. Its primary contributions are the explicit formalization of modular, verifiable reasoning layers, strong empirical gains on longitudinal EHR benchmarks, and a complete, public reference architecture for future expansions. Future directions include prevalence-aware reasoning, integration with richer temporal knowledge graphs, real-time latency optimization, and interventional studies in prospective clinical workflows.