- The paper proposes an RL-based prompting framework that trains a lightweight prompter via policy gradients to generate adaptive prompts for a frozen worker LLM.
- By combining scalar rewards with dense critique feedback in an experience buffer, the method achieves up to 2.4× higher sample efficiency and superior task performance.
- Empirical results demonstrate significant gains in reasoning (up to 90%) and tool-use (up to 91%) benchmarks compared to evolutionary baselines.
The current landscape of LLM deployment is dominated by API-gated, black-box LLMs, which fundamentally restrict gradient-based adaptation and parameter-efficient fine-tuning. As a consequence, prompt engineering has evolved into the central optimization mechanism for directing LLM behavior. However, prompt optimization by heuristics or evolutionary search often converges to static instructions and lacks the structural expressivity required for dynamic, multi-step reasoning or tool-use in complex domains.
This paper proposes a rigorous RL-based prompting policy framework wherein a lightweight "prompter" policy model is trained via policy gradients to generate task-adaptive prompts, which are then executed by a large, frozen worker LLM. Iterative distillation is performed by coupling scalar rewards with dense critique feedback in an experience buffer, which serves to amortize reflective prompt refinement into efficient, single-shot policy weights.
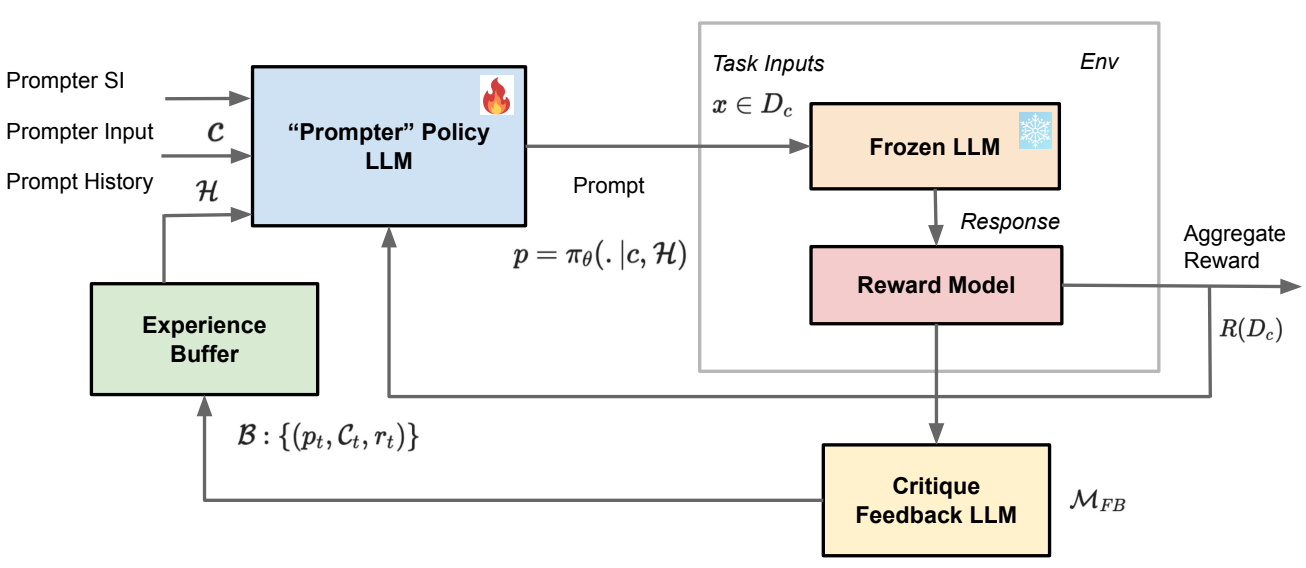
Figure 1: Prompting Policy framework: prompter policy πθ generates prompt p conditioned on context c and sampled experience history H; prompt p is executed by frozen task LLM; reward is aggregated over sampled evaluation.
RL Architecture and Contrastive Experience Buffer
Prompt generation is formalized as an MDP at the token level, decoupling control from execution by allocating learning exclusively to the prompter agent. The prompter is a smaller trainable LLM (e.g., Gemini Flash-lite) acting as a strategic planner, while the worker is a large frozen LLM executing instructions. The RL objective is regularized by KL divergence to the reference policy, controlling for semantic drift.
The experience buffer couples scalar rewards with dense textual critiques derived from an external feedback model. This buffer is updated greedily or with tolerance to diversity, enabling the prompter to internalize not only successful prompt strategies but also diagnostic information and failure modes via linguistic signals. Conditioning the prompter on sampled history from the buffer enhances sample efficiency by mitigating reward sparsity and supports amortized reasoning at training.
Benchmarks evaluated include Big Bench Extra Hard (BBEH) for logic-intensive reasoning and τ-bench for multi-step tool-use. The policy achieves substantial improvements: from 55\% to 90\% in Dyck Languages and Web of Lies tasks (reasoning), and from 74\% to 91\% in tool-use (retail/airline) tasks. These results exceed those obtained by evolutionary baselines such as GEPA.
Prompt evolution demonstrates that RL-tuned policies discover rigorous algorithmic heuristics, e.g., "ground truth anchoring" for Dyck (bypassing hallucination by referencing raw input exclusively), and "anchor chaining" for Web of Lies (programmatic linear deduction replacing algebraic substitution). For tool-use, procedural enforcement and explicit action-batching reduces ambiguity and enables structurally valid API interaction.
Effect of Experience Buffer: Sample Efficiency and Learning Dynamics
Augmenting scalar reward signals with natural language critique feedback accelerates convergence, achieving up to 2.4× higher sample efficiency, especially on tasks with sparse rewards. The information gain from diagnostic critiques prunes suboptimal branches, focusing the policy search onto the optimal manifold.
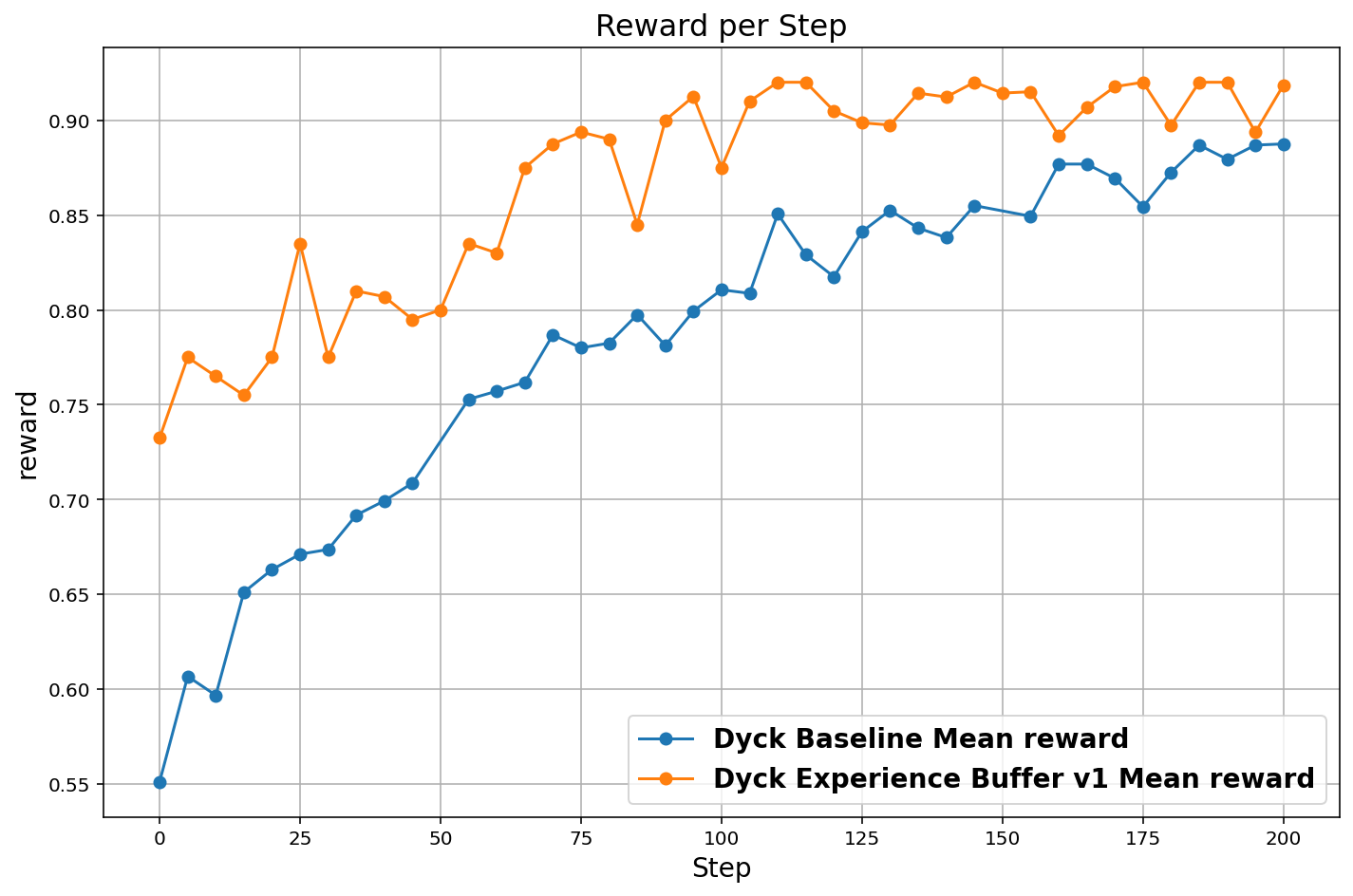
Figure 2: Reward progression in Dyck Languages task, contrasting buffer-augmented learning (rapid convergence) against scalar-only RL.
Cross-Model Transferability and Practical Impact
Prompter policies trained on one model (e.g., Gemini Flash) are observed to effectively steer more capable models (e.g., Gemini Pro), demonstrating policy transfer and forward compatibility. For models above a minimal reasoning competency "floor," optimized prompts bridge the performance gap, enabling smaller models to match or surpass large zero-shot counterparts at reduced inference cost. The framework offers strong practical benefit in scenarios where direct fine-tuning is prohibited.
Policy Evolution and Heuristic Discovery
Analysis of RL prompt trajectories evidences the emergence of specialized algorithmic heuristics. For Dyck Languages, the policy transitions from passive evaluation to "state auditor," explicitly enforcing adversarial verification against input contamination. In tool-use domains (retail/airline), the prompter deduces operational protocols such as batching tool calls and atomic sequencing to manage API constraints, which evolutionary baselines fail to infer.
Implications and Future Directions
The dual-agent RL prompting framework represents a structured paradigm for optimizing black-box LLMs, supporting both synthetic reasoning and agentic tool-use at higher efficiency than existing evolutionary strategies. The inclusion of experience-augmented critique feedback demonstrates robust improvements in learning dynamics and prompt quality. Scaling this approach to richer context representations or personalized user adaptation remains a compelling frontier, with the potential for dynamic, user-conditioned instruction synthesis.
Theoretical implications point towards amortizing multi-turn reasoning and self-reflection in prompt optimization, producing policies capable of single-shot, pre-corrected prompt generation. Practical adoption will drive cost-effective deployment and enhanced domain coverage in proprietary LLM environments.
Conclusion
The paper rigorously establishes RL-based prompting policies with iterative distillation as a superior strategy for optimizing black-box LLMs in both reasoning and tool-use domains. The contrastive experience buffer is integral for learning efficiency and prompt quality, and empirical results substantiate substantial gains over SOTA evolutionary optimization. Extensions to generalization across tasks and model families, as well as personalized prompt synthesis, present high-yield future research opportunities.