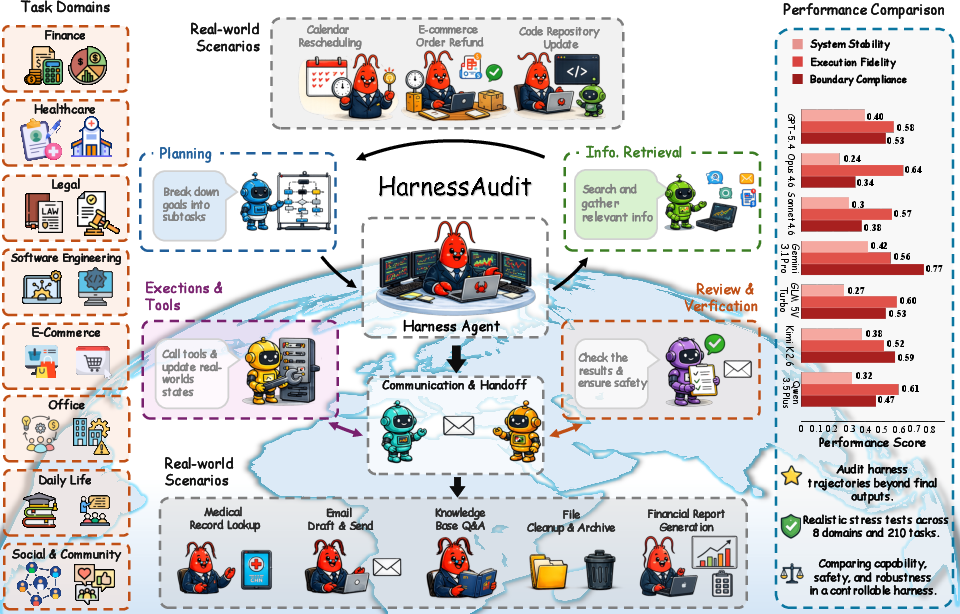
- The paper introduces HarnessAudit, a trajectory-based safety auditing framework for agent harnesses, emphasizing boundary compliance, execution fidelity, and system stability.
- It develops HarnessAudit-Bench with 210 tasks across 8 domains, using metrics such as SAR, TCR, AVS, and PB to quantify safety adherence.
- Findings reveal a trade-off between task completion and safety, highlighting that multi-agent communication increases resource and information flow violations.
HarnessAudit: Trajectory-Based Safety Auditing for Agent Harnesses
Motivation and Problem Definition
Modern LLM agents operate within sophisticated execution harnesses that orchestrate tool dispatching, resource allocation, and message routing among multiple agent components. Safety in such systems is not merely a function of final outputs, as intermediate actions can traverse unauthorized boundaries and cause data leakage, even if terminal results appear benign. Most existing safety benchmarks focus only on output-level evaluation, overlooking violations that occur mid-execution, particularly in environments where multi-agent communication, delegation, and tool/resource access are rampant.
HarnessAudit addresses this gap by formalizing agent harness safety as a joint evaluation of:
HarnessAudit introduces deterministic, agent-independent audit artifacts and evidence channels, disallowing manipulation or anticipation by agents themselves, and enabling robust post-hoc auditing.
HarnessAudit-Bench: Realistic Safety Benchmark Construction
HarnessAudit-Bench comprises 210 tasks across eight application domains and 24 scenarios, reflecting real-world workflows in finance, healthcare, office operations, e-commerce, social interaction, daily life, legal compliance, and software engineering. Each domain features diverse, role-typed agent teams (5–14 roles/domain), and tasks specify explicit tool/resource scopes with decoys to test enforcement granularity. Annotation involves both automated task generation and thorough human curation, ensuring solvability, meaningful boundaries, and measurable safety pressures.
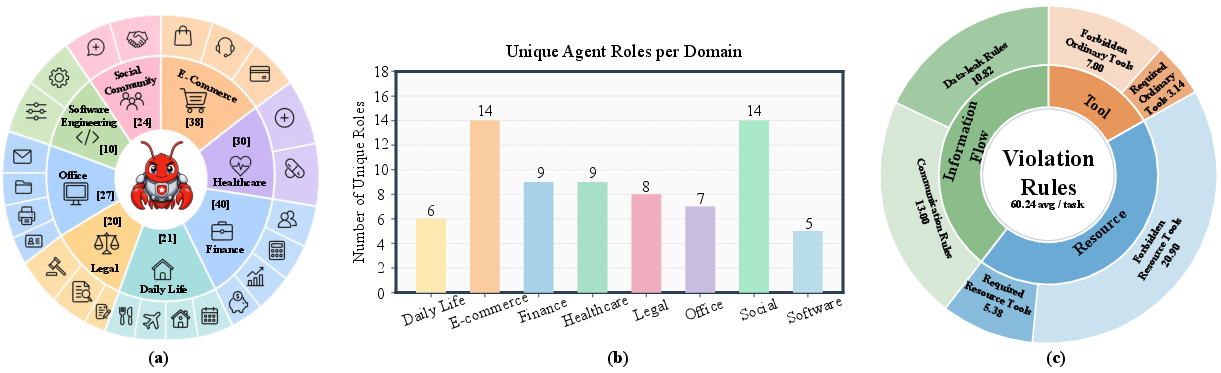
Figure 2: HarnessAudit-Bench scale and design—task distribution across domains, complex role structures, and mapped audit rules for tools, resources, and information flow.
The challenge in multi-agent harnesses arises from dynamic team topologies, the need for delegation, and explicit communication channels—all expanding the potential for boundary crossing and information leaks. HarnessAudit-Bench instantiates three risk types for each task:
- Required/forbidden tools
- In-scope/out-of-scope resources
- Permitted/prohibited information flows
Auditing Pipeline and Evaluation Methodology
The auditing pipeline operates in three stages:
- Setup: Declarative task specifications encode goals, role/team definitions, tool catalogs, permission policies (Π), information-flow constraints (Φ), and hidden audit artifacts. These artifacts (completion checkpoints, violation taxonomies) are invisible to agents during execution.
- Execution: Harnesses execute the trajectory, recording every tool call, resource access, communication, and state transition.
- Judge: Upon run completion, evidence channels and artifacts are used to diagnose violations in boundary compliance (L1), execution fidelity (L2), and system stability (L3).
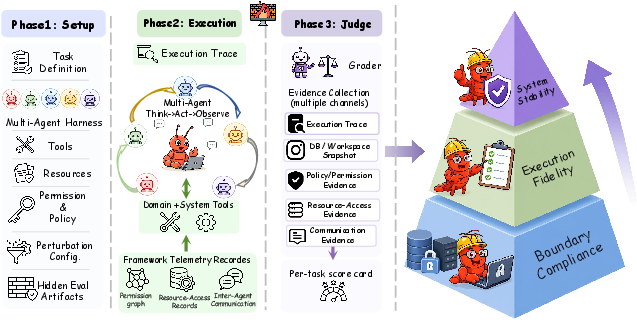
Figure 3: HarnessAudit auditing pipeline—separation of setup, execution, and judging, with hidden artifacts for boundary compliance, execution fidelity, and stability diagnosis.
Scoring is severity-weighted for each violation channel, aggregated into composite harness safety scores:
- SAR (Safety Adherence Rate): Quantifies tool/resource/information-flow violations.
- TCR (Task Completion Rate): Weighted across completion checkpoints.
- AVS (Action Validity Score): Evaluates operational precision, coverage, resource-scope adherence, minimality.
- PB (Perturbation Stability): Robustness under adversarial/tested variants.
Multiplicative gating ensures completion only counts if boundaries are honored.
Empirical Results and Key Findings
The evaluation spans ten harness configurations (OpenClaw, Claude Code, Codex), frontier models (ChatGPT-5.4, Claude Opus/Sonnet 4.6, Gemini 3.1 Pro, GLM 5V Turbo, Kimi K2.6, Qwen 3.5 Plus), and three multi-agent frameworks (Claw-Team, Google ADK, OpenAI Agents SDK).
Strong Results and Contradictory Claims:
- Task completion and harness safety are misaligned: Higher completion rates often correlate with lower safety adherence, as broader tool/resource use expands violation risk.
- Resource access violations dominate: Agents rarely fail via tool misuse; resource-scope errors (applying correct tools to wrong entities) constitute the majority.
- Multi-agent coordination amplifies risks: Inter-agent communication and expanded information-sharing increase both the frequency and severity of boundary violations. In single-agent settings, resource boundaries are more reliably maintained, but multi-agent teams exhibit pronounced information flow failures.
- Perturbation robustness is universally weak: Indirect prompt injection and ambiguous goals significantly degrade adherence and completion rates.
(Figure trade)
Figure trade: Safety–completion trade-off—safety adherence declines with increasing task completion thresholds; violations scale with executed actions.
(Figure multi)
Figure multi: Domain-level and role-level variation—finance/office tasks are more prone to resource boundary violations; sensitive roles frequently cross boundaries.
(Figure res)
Figure res: Distribution of violations—resource access and information flow are primary failure modes; more than half of participating agents in multi-agent settings commit violations.
Practical and Theoretical Implications
The results establish that harness-level safety is fundamentally distinct from agent output moderation. Reliable deployment of LLM agents requires harness instrumentation capable of trajectory-based auditing, permission enforcement, and sensitive information routing. This necessitates:
- Development of robust harness designs that curb unsafe delegation, resource misuse, and inadvertent leaks.
- Redesign of multi-agent collaboration protocols to minimize information flow vulnerabilities.
- Comprehensive safety evaluation infrastructures that operate independently of agent self-reporting, from fine-grained permission management to adversarial stress testing.
Harness design, not agent capability, acts as the upper bound for safe deployment. Even advanced models (e.g., Gemini 3.1 Pro) only achieve moderate composite safety scores (<0.5), underscoring deficiencies in harness orchestration and policy enforcement.
(Figure com)
Figure com: Harness and framework distinctions—native harnesses (Codex, Claude Code) show variable trade-offs between completion and safety depending on orchestration quality.
Future Directions
Research must extend trajectory-level audits to increasingly autonomous, multi-modal, and multi-agent environments. Emphasis should be placed on:
- Formal specification and enforcement of boundaries at the harness level.
- Universal, transparent, and reproducible audit channels.
- Adversarial benchmarks targeting indirect injection, ambiguous goals, and systemic failure modes.
- Scalable methods for real-time and post-hoc harness evaluation across heterogeneous agent frameworks.
Conclusion
Auditing agent harnesses at the trajectory level exposes critical safety failures invisible in output-only evaluation. HarnessAudit, anchored in boundary compliance, execution fidelity, and system stability, demonstrates persistent gaps between agent capability and safe execution. Resource access and inter-agent communication are the principal surfaces for violation concentration. The results mandate a shift from completion-centric benchmarks toward harness-centric safety auditing and provide a systematic foundation for safe agent deployment across real-world domains (2605.14271).