- The paper introduces a novel covariance-aware sampler that leverages first-order noise injection and Fourier domain decomposition to improve few-step diffusion model sampling.
- It employs structured covariance estimation via Tweedie’s formula and ConvDCT to correct variance underestimation and maintain sample diversity.
- Empirical results on pixel-space diffusion architectures demonstrate superior FID performance compared to second-order methods under matched computational budgets.
Covariance-Aware Sampling for Diffusion Models: A Technical Analysis
Introduction
The paper "Covariance-aware sampling for Diffusion Models" (2605.13910) investigates the persistent challenge of improving sample quality and diversity for diffusion models (DMs) when using a reduced number of sampling steps. Standard practice for DMs relies primarily on the conditional mean during reverse sampling, leading to performance degradation and sample collapse in low-step regimes. This work introduces a first-order, noise-injecting sampler that explicitly models the stepwise conditional covariance via Tweedie's formula, with a tractable implementation based on structured approximations in the Fourier domain. The method delivers strong empirical performance across pixel-space diffusion architectures, outperforming both established second-order ODE solvers (Heun, DPM-Solver++) and state-of-the-art first-order alternatives (aDDIM) under matched computational budgets.
The proposed method builds on the observation that the reverse conditional distribution p(xt−1∣xt) in diffusion processes is intractable but its moments—specifically mean and covariance—can be estimated analytically via Tweedie's formula. Previous work has focused on integrating second-order moments in the training objectives or via post-hoc diagonal approximations. Distinctly, this approach conducts direct, per-step estimation of the conditional covariance during sampling, thus correcting for the variance underestimation endemic to mean-only samplers in the few-step regime.
The posterior covariance is approximated as a block-diagonal structure in the frequency domain, where each block corresponds to a frequency component decomposed using either discrete cosine transform (DCT) or the newly introduced convolutional DCT (ConvDCT, which incorporates pixel neighborhoods). Covariance parameters for each frequency are efficiently estimated by employing Hutchinson's trace estimator using Jacobian-vector products (JVP), thereby requiring only one additional function evaluation per step.
This approach results in a first-order, non-deterministic sampler: each sampling step perturbs the predicted mean with structured noise whose covariance matches the estimated posterior covariance in the Fourier basis. This mechanism addresses both sample diversity and quality even when the number of sampling steps is significantly reduced.
Implementation and Design Considerations
A key implementation choice is the restriction of JVP-based covariance estimation to the guided prediction in classifier-free guidance scenarios, which minimizes the computational overhead (three function evaluations per step, compared to four for second-order methods). The algorithm is deployable as a drop-in replacement for standard DDIM samplers without alterations to the model or training pipeline.
Critical ablations are presented on (1) the block structure and averaging axes for covariance decomposition, and (2) the choice of frequency transform. A granular decomposition—distinct ci,t per spatial component/channel—provided optimal expressivity and performance. ConvDCT outperforms standard DCT specifically in low-NFE (function evaluation) regimes, reflecting the added expressivity from local frequency aggregation.
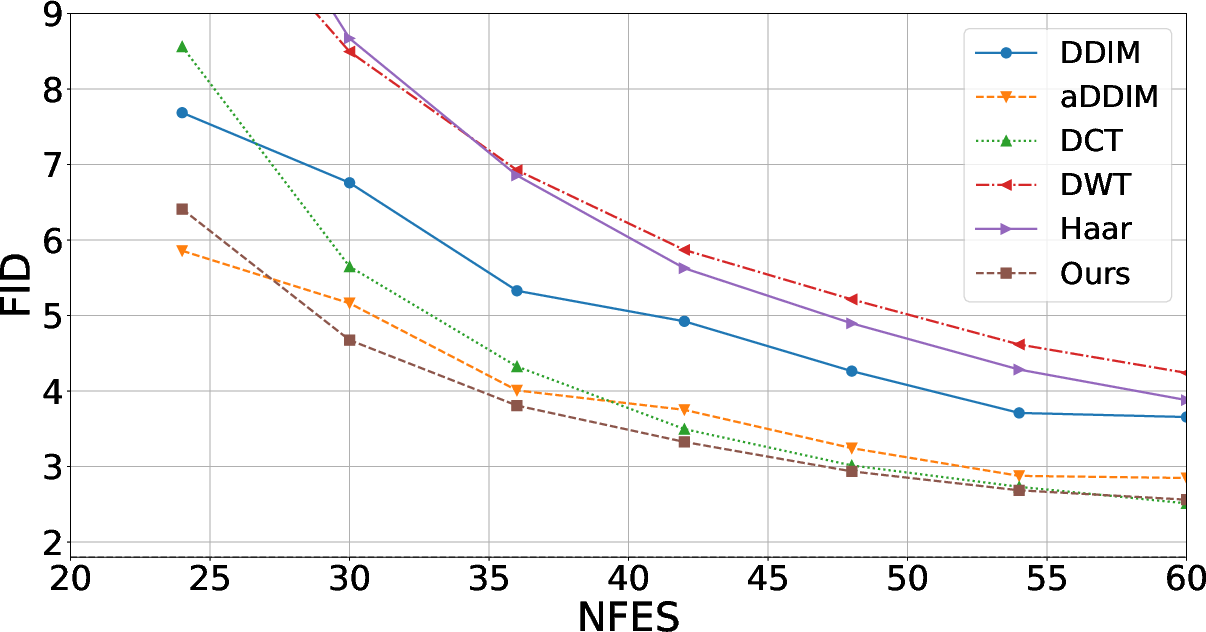
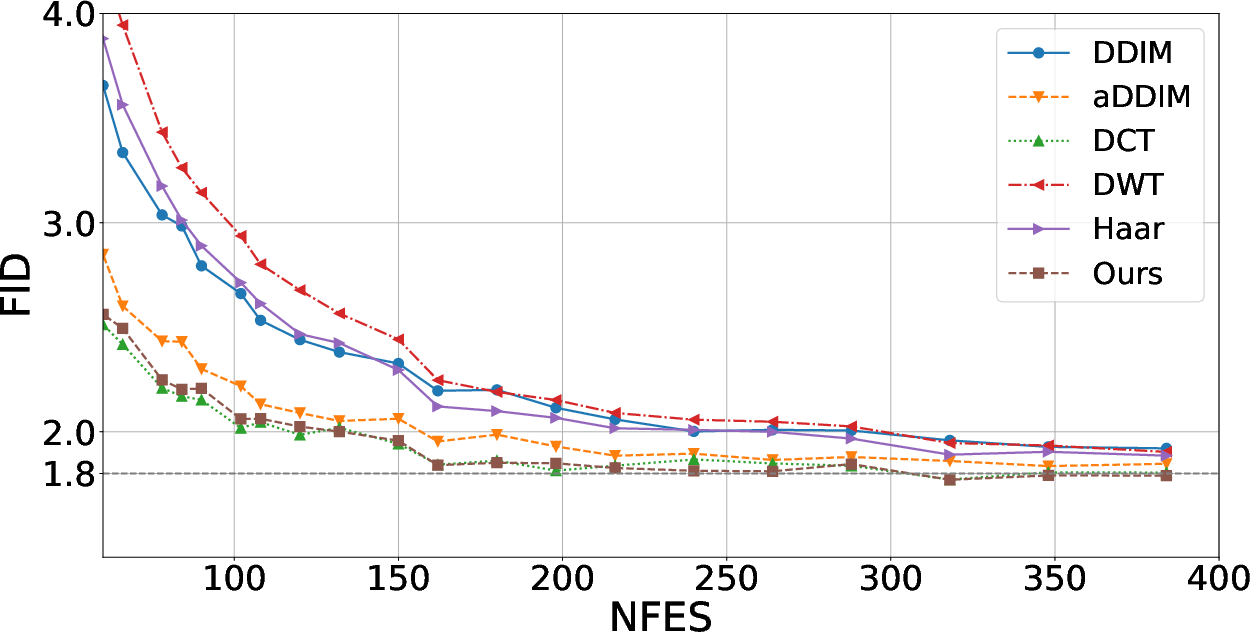
Figure 1: ConvDCT and DCT are the most effective frequency mappings for covariance approximation, with ConvDCT preferred for low function evaluations and both being equivalent for higher computational budgets.
The averaging scheme used for the covariance parameters (channels alone rather than full spatial or global averaging) was crucial: excessive averaging diluted the structural accuracy of the conditional covariance estimate, as summarized in the following experiment.
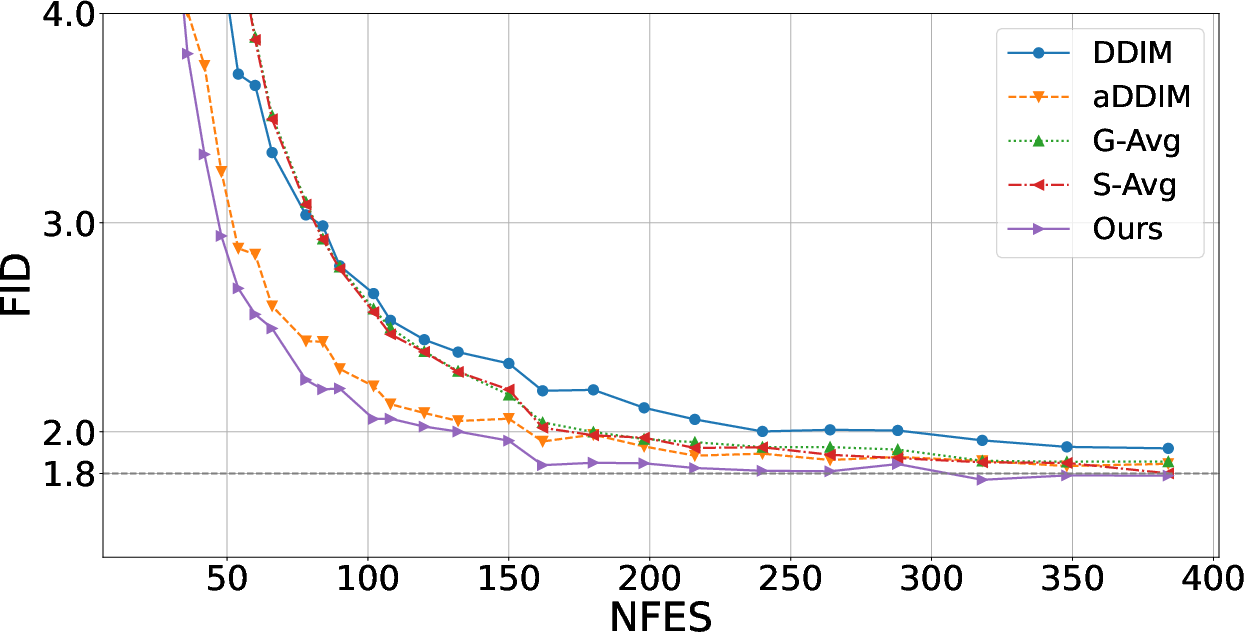
Figure 2: Averaging only across channel axis yields optimal performance for covariance estimates, highlighting the necessity for spatial granularity.
Empirical Results
Pixel-Space Diffusion Models
Benchmarked on challenging datasets and competitive architectures (e.g., SiD2 on ImageNet-512, UViT on ImageNet-128, and CIFAR-10), the covariance-aware sampler consistently outperformed both Heun and DPM-Solver++ as well as contemporary alternatives (aDDIM, DDIM) at fixed NFE. Sample quality was measured via FID (Fréchet Inception Distance) at 50k samples, and superiority extended across both conditional and unconditional sampling settings.
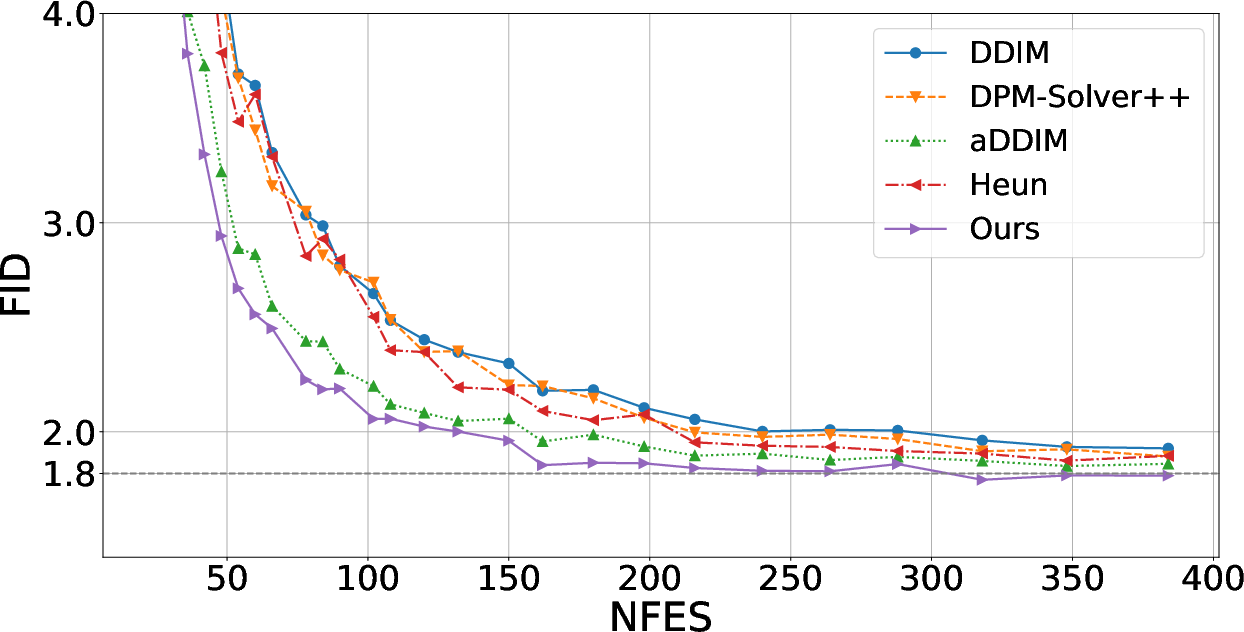
Figure 3: The covariance-aware sampler shows superior FID convergence compared to second-order samplers and aDDIM for a matched computation budget on ImageNet-512.
Results on UViT (ImageNet-128) further corroborate the efficacy, where aDDIM and DDIM perform comparably but lag behind second-order samplers—both of which are surpassed by the new covariance-based approach.
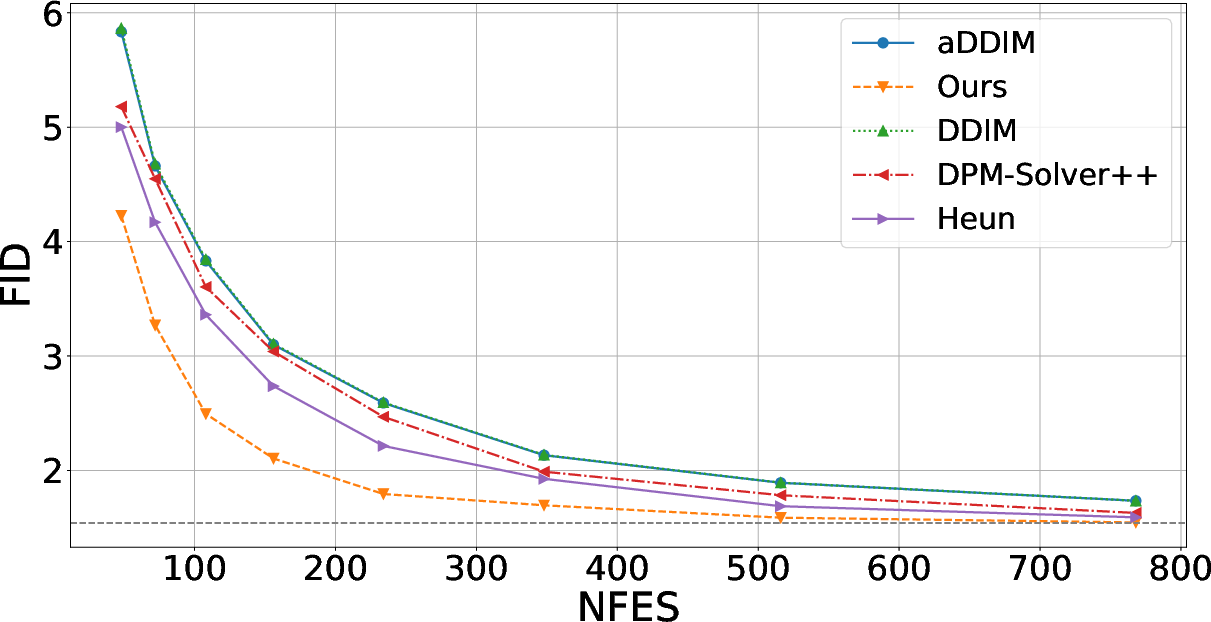
Figure 4: On ImageNet-128, the covariance-aware sampler demonstrates clear advantage over both first- and second-order competitive baselines with respect to FID for a fixed NFE.
On unconditional CIFAR-10, while second-order samplers and the covariance-aware approach require double the function evaluations per step relative to (a)DDIM, the proposed approach rapidly overtakes all other samplers as the computational budget is increased (especially in the moderate-to-high NFE regime).
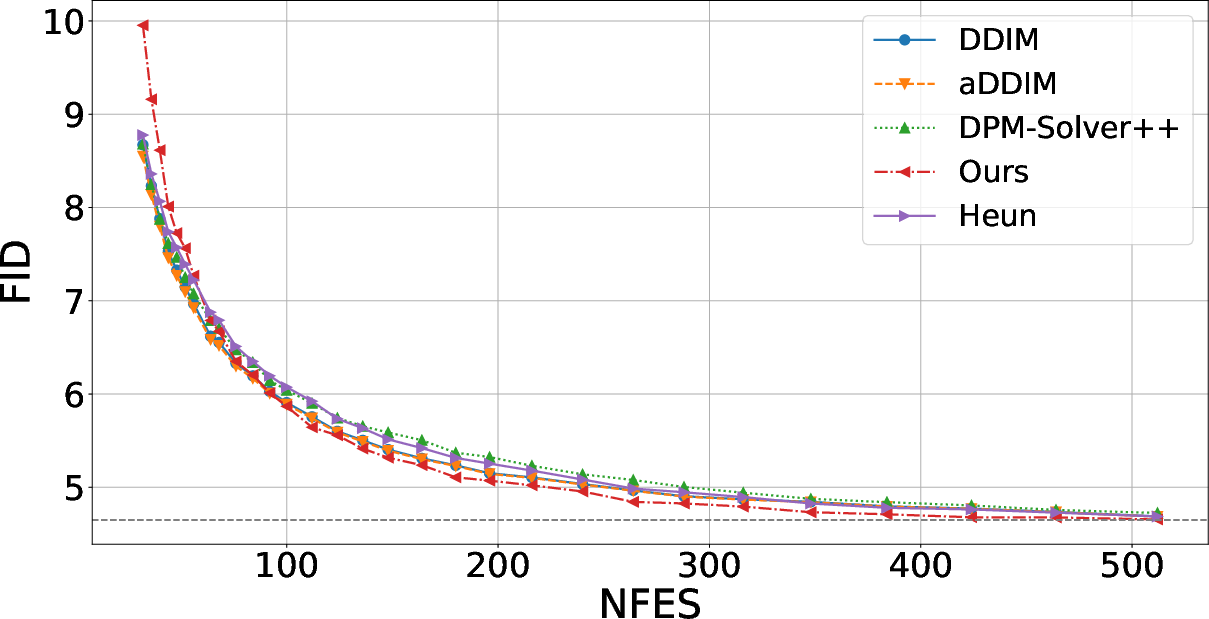
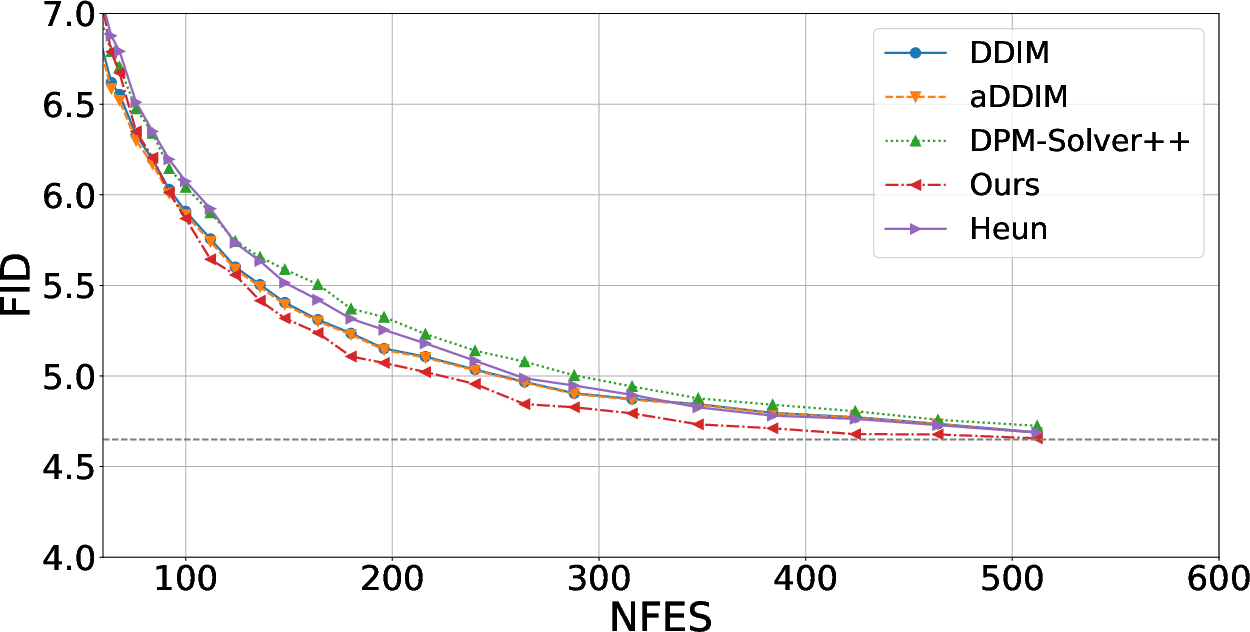
Figure 5: For CIFAR-10, the covariance-aware sampler surpasses aDDIM and DDIM as NFE increases, even though the comparison is penalized by step-count.
Failure Modes and Limitations
The method’s efficacy is currently constrained to pixel-space diffusion models. When applied to latent diffusion models (LDMs), such as Stable Diffusion, adding structured noise in latent space generally led to degraded sample quality—DDIM's deterministic process remained superior.
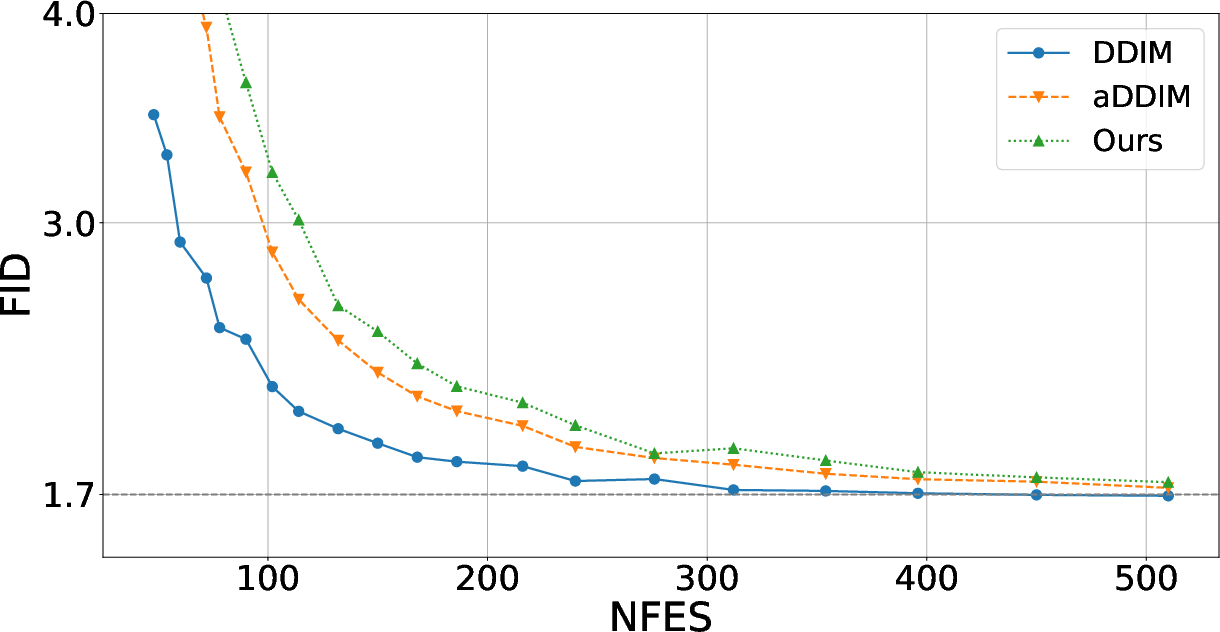
Figure 6: For Stable Diffusion, deterministic DDIM sampling outperforms methods (including covariance-aware) that add noise during generation, indicating LDMs’ sensitivity to latent noise injection.
This failure is hypothesized to arise from autoencoder sensitivities, and the authors appropriately restrict their claims to pixel-space DMs.
Relation to Prior Work
Unlike modified training procedures required by high-order score matching [Meng et al. 2021], post-hoc covariance prediction [Ou et al. 2025], or alternative block-diagonal/covariance correction methods prevalent in inverse problems [Peng et al. 2024; Boys et al. 2024], this approach is purely a sampling-time intervention, with no training changes or architectural modifications. The paper also systematically evaluates alternative frequency and block structures for covariance estimation, offering empirical evidence that local frequency covariances and fine-grained averaging yield the highest fidelity.
Practical and Theoretical Implications
The introduction of tractable, structured posterior covariance estimation refines the expressive power of first-order samplers, raising the performance bar in few-step generation—a critical practical requirement for real-time inference and interactive applications.
The findings reinforce the theoretical importance of accurate conditional moment modeling, particularly when sample diversity is challenged by large step sizes. The Fourier-domain decomposition exploits the stationarity and local structure of natural images, and the approach is likely extensible to other signal types where frequency-domain structure retains semantic coherence.
Given that the method does not improve or can even degrade performance in LDMs, future work is needed to adapt covariance structure estimation and noise augmentation for latent spaces, possibly by tailoring the frequency basis to autoencoder-specific priors or by capping/learning noise injection in an adaptive manner.
Conclusion
This work presents a computationally efficient, structured approach to covariance-aware sampling in diffusion models, offering empirical performance advantages over leading first- and second-order samplers within pixel-space image generation. By explicitly estimating and exploiting the conditional covariance via frequency-domain decomposition and trace estimation, the proposed method injects meaningful diversity and maintains sample quality under aggressive step reduction. Its efficacy, deployability, and independence from training modifications make it a significant technical advancement in practical diffusion model sampling. Extension to latent diffusion models remains an open problem and a promising avenue for continued research.

