- The paper demonstrates that while autoregressive byte models eventually reach efficiency parity with BPE models, masked diffusion models maintain a significant compute penalty.
- It employs compute-matched Transformer evaluations across a wide scale (48M to 1.2B parameters) using Bits-per-Byte to rigorously assess performance differences.
- The study identifies context fragility and lack of emergent segmentation in byte-level diffusion as key limitations, suggesting the need for innovative architectural adaptations.
The Efficiency Gap in Byte-Level Language Modeling: A Detailed Examination
Introduction and Motivation
Language modeling has conventionally relied on autoregressive (AR) generation combined with subword tokenization methods such as BPE. The intersection of byte-level modeling and order-agnostic objectives—specifically, masked diffusion models (MDM)—eliminates these structural priors in the pursuit of modality universality and generation flexibility. However, the extent to which this removal increases computational demands and alters scaling behavior has remained underexplored. "The Efficiency Gap in Byte Modeling" (2605.12928) delivers a rigorous scaling analysis, systematically quantifying the performance-over-compute tradeoff in AR and MDM settings under both BPE and byte tokenization constraints, and identifies fundamental limitations rooted in context fragility for byte-level diffusion.
Experimental Design and Methodology
The investigation is grounded in a compute-matched evaluation of multiple Transformer-based architectures, spanning 48M to 1.2B non-embedding parameters, trained on the Slimpajama-627B corpus. For normalized comparison across representational granularities, Bits-per-Byte (BPB) is adopted as the primary metric. Training regimes are meticulously matched on total FLOPs, compensating for the quadratic attention cost induced by increased input sequence lengths in byte-level models.
Key distinctions are made between:
- Autoregressive (AR) models: Strict causal, left-to-right factorization, leveraging BPE or raw bytes.
- Masked Diffusion Models (MDM): Order-agnostic, bidirectional denoising using random masking, applied at both BPE and byte granularities.
Scaling Analysis and Core Numerical Results
A central empirical finding is the objective-dependent scaling overhead of byte-level modeling. AR byte models, despite an initial efficiency penalty relative to AR BPE models, asymptotically approach parity as the compute budget increases. In contrast, byte-level MDMs sustain a persistent and numerically significant performance gap vis-à-vis BPE-based MDMs, even under substantial scale increases. This divergent behavior is visualized in isoFLOPs curves:
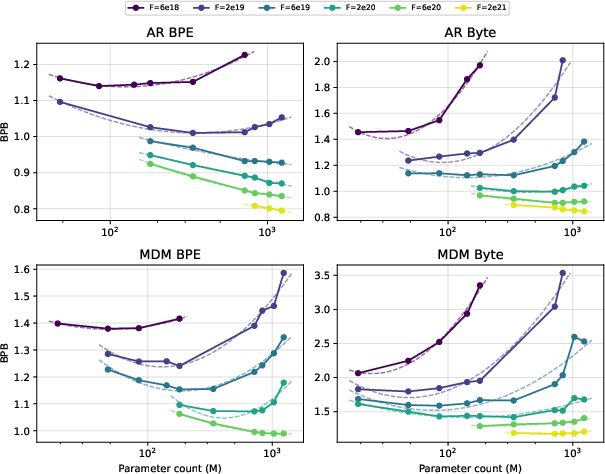
Figure 1: IsoFLOPs curves comparing AR (top) and MDM (bottom) with BPE (left) and byte (right) tokenization, benchmarking BPB across model and compute scales.
Training curve analysis confirms that AR byte models’ efficiency offsets diminish rapidly with scale, while MDM byte models remain compute-inefficient (Figure 2). Notably, AR byte and BPE models converge on the efficiency frontier in high-compute regimes; the MDM byte-vs-BPE gap, by contrast, persists across increasing data and compute.
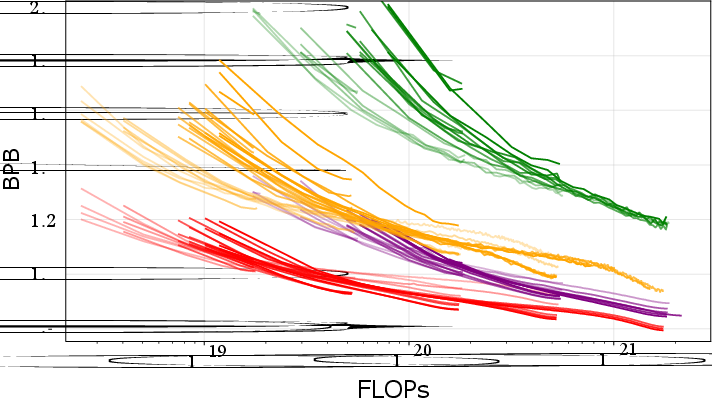
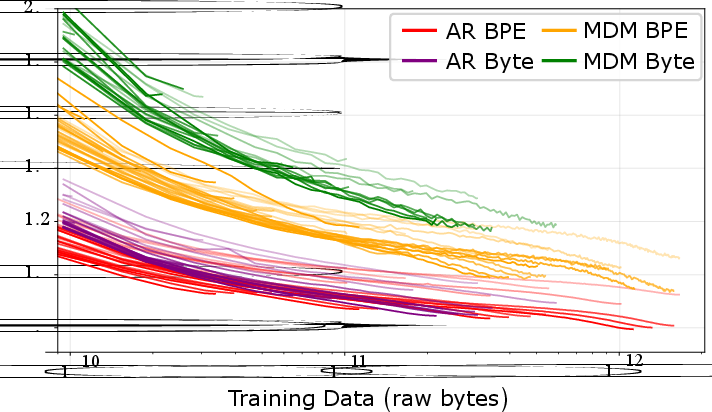
Figure 2: Training curves for BPB vs total FLOPs and data volume show that AR bytes approach BPE but MDM bytes lag consistently.
Explicit quantification shows:
- For AR, the compute gap between byte and BPE models at BPB=1.0 is approximately 7.9×, shrinking to 2.3× at BPB=0.8.
- For MDM, this penalty is markedly worse: at BPB=1.2, the compute gap is approximately 34×, and projections suggest 20.5× at BPB=1.0.
- Extrapolation indicates AR byte and BPE models reach parity near F≈1.3×1022 FLOPs, while MDM byte models may require F≈4.2×1026 FLOPs for similar parity.
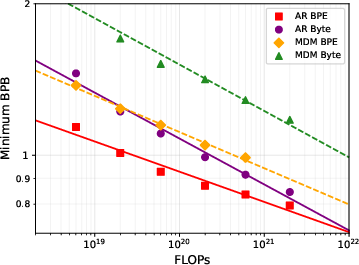
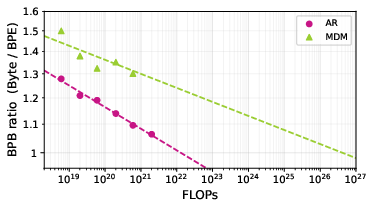
Figure 3: Extrapolated isoFLOPs minima and BPB ratios display that byte-to-BPE efficiency gaps decay more rapidly for AR than MDM.
Emergence of Segmentation and Predictive Efficiency
A core mechanism allowing AR byte models to close the efficiency gap is the emergence of implicit segmentation aligned with subword structures. By analyzing scalar predictive entropy of AR byte models, it is demonstrated that the model’s uncertainty peaks precisely at BPE token boundaries, achieving an ROC AUC of 0.829 for predicting BPE start boundaries. This emergent property illustrates that AR objectives enable models to reconstruct, via statistical dependencies, the salient boundaries that subword tokenization would otherwise enforce directly.
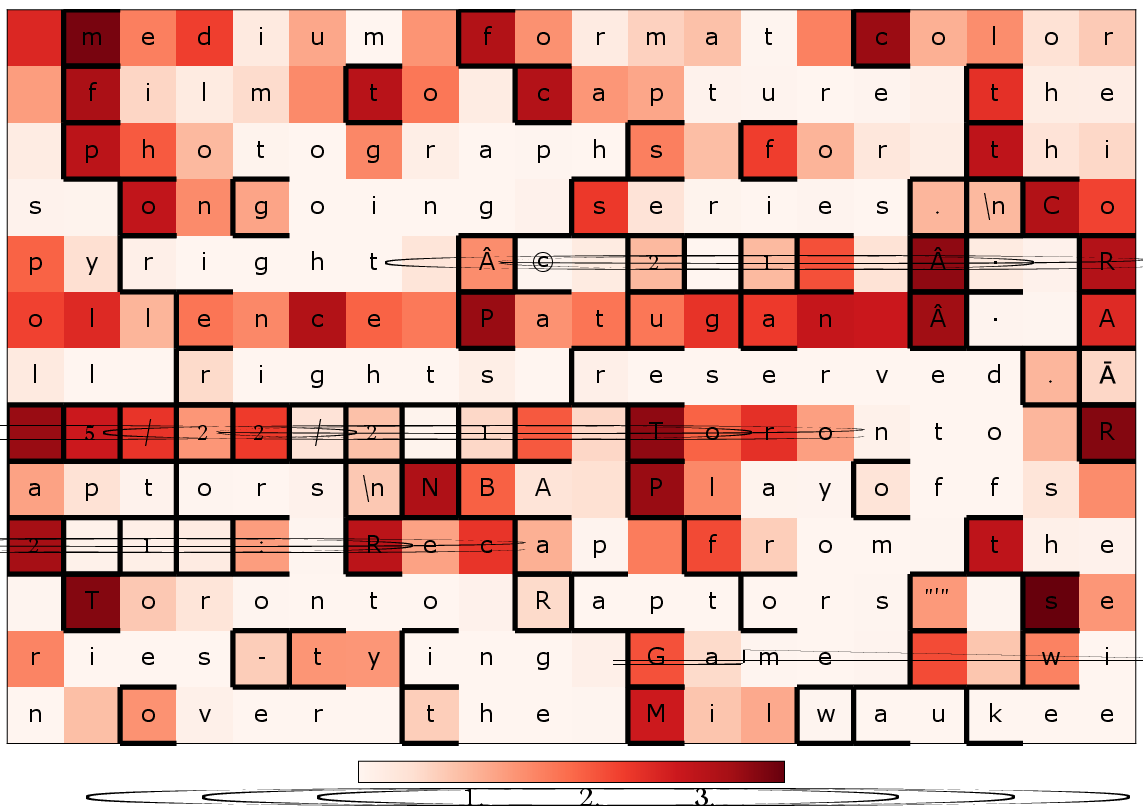
Figure 4: Predictive entropy of AR byte models peaks at BPE token boundaries, evidencing internal reconstruction of subword structures.
Fundamental Context Fragility in Byte-Level Diffusion
Detailed permutation experiments highlight a unique fragility of byte representations under order corruption—characteristic of MDM objectives. Randomizing global or local order of bytes significantly reduces statistical regularity (as measured by compression algorithms), and more importantly, impairs model learning far beyond what is seen for BPE sequences. Preserving global causal context (even with local noise) proves much more robust for byte models than preserving local blocks but destroying global order, further underscoring the inductive bias provided by AR objectives.
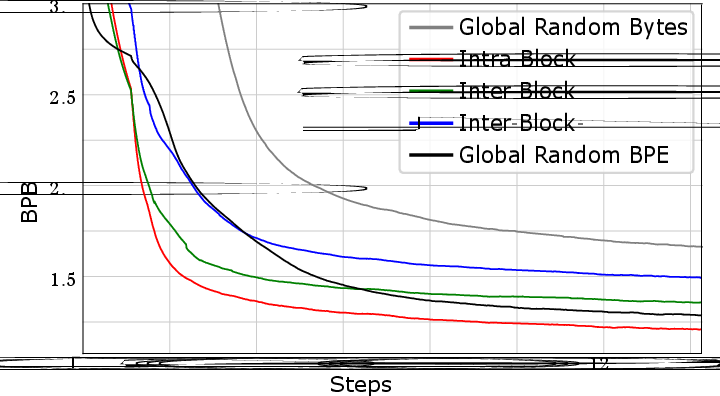
Figure 5: Strategies for corruption and their impact on compressibility demonstrate byte sequences' heightened sensitivity to context.
Byte vs. BPE Under Fixed Context
Even when normalizing for context length—matching attention quadratic scaling—byte models (especially those trained with MDM) remain markedly less sample- and compute-efficient than BPE models. This emphasizes that the efficiency deficit is not reducible to context length alone, but emerges from the increased representational complexity and loss of semantic density at the byte level.
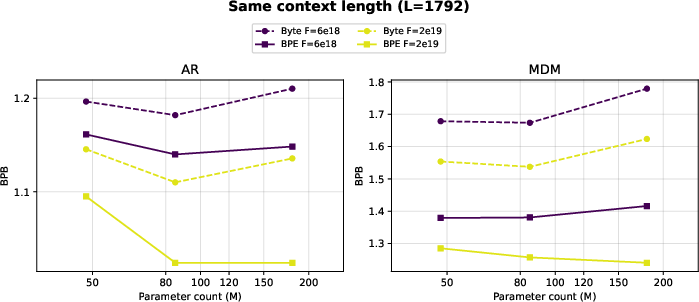
Figure 6: At the same context length and compute, byte models (dashed) systematically underperform BPE counterparts (solid).
Span Masking and Vocabulary Analysis
Attempting to counteract context fragility, the authors experiment with span-based masking aligned to BPE token boundaries. Contrary to expectations, larger spans monotonically degrade MDM performance, revealing that simple restoration of local context, absent AR's global structure, is insufficient to offset the byte-level information loss.
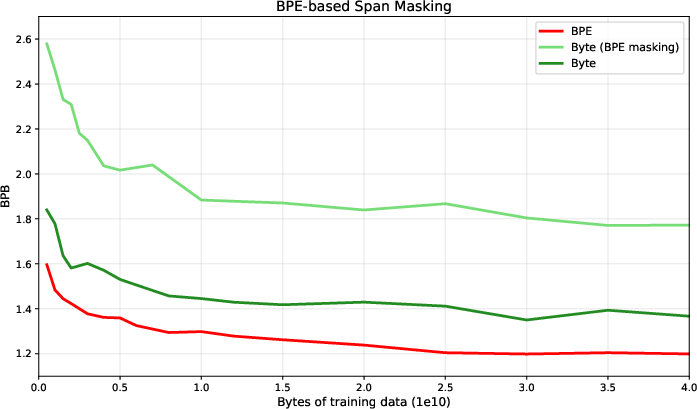
Figure 7: Span masking with larger contiguous blocks consistently reduces MDM efficiency, counter to intuition about context restoration.
Scaling analysis with larger token vocabularies (GPT-2, Llama-3) confirms that larger vocabularies do confer greater compression, but the byte-vs-BPE penalty persists across vocabularies, especially for MDM.
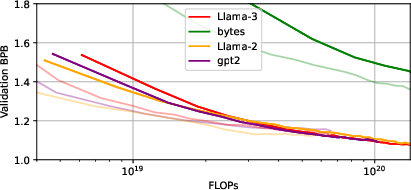
Figure 8: IsoFLOPs curves for different vocabulary sizes show the persistent compression and efficiency advantage for larger BPE vocabularies.
Implications, Limitations, and Future Prospects
This study establishes the contradictory claim that removing structural priors—via byte-level modeling and MDM—does not yield uniform scaling trajectories. In fact, it incurs substantial, objective-dependent efficiency penalties not attributable to context length alone. The identification of context fragility as a limiting factor for byte-level MDMs suggests that modality-agnostic or fully end-to-end models must introduce alternative structural biases or architectural adaptations if they are to match the learning efficiency of models using compressed token representations and/or causal ordering.
Practically, this has direct implications for large-scale multipurpose model design: byte-level MDMs are not compute-competitive with established AR or BPE-based models under realistic compute budgets, and naïvely substituting architectures may have severe performance consequences. Theoretically, the mechanistic evidence for the necessity of stable causal contexts and emergent segmentation points toward a fundamental incompatibility between highly local representations and order-agnostic generation, unless mitigated by stronger architectural inductive biases.
Future work may explore the introduction of learned grouping, hierarchical patching, or hybrid generative objectives to reclaim context integrity and semantic density without relying on hand-crafted tokenizations, as well as refinements to the masking or diffusion process that can explicitly favor learnable boundaries.
Conclusion
"The Efficiency Gap in Byte Modeling" provides an exhaustive, compute-controlled scaling study, dissecting the relative merits and current limitations of byte-level language modeling under both AR and MDM objectives. Strong numerical evidence demonstrates an enduring compute penalty for byte-level MDM, contrasted with diminishing penalties for byte-level AR. This penalty is mechanistically attributed to context fragility, providing clear direction for future architectural innovations in modality-agnostic generative modeling.

