- The paper presents GEAR, a novel framework that leverages self-distillation for fine-grained credit assignment in reinforcement learning for LLM agents.
- It employs token-level reverse KL divergence and entropy-based segmentation to dynamically reweight advantages, achieving up to 20% accuracy gains on complex benchmarks.
- The framework enhances policy stability and sample efficiency in long-horizon tasks without relying on external reward models.
Granularity-Adaptive Credit Assignment for LLM Agents: The GEAR Framework
Motivation and Problem Setting
LLMs deployed as agents in complex reasoning and tool-use environments require reinforcement learning (RL) with fine-grained credit assignment for effective policy optimization. Traditional agentic RL methods such as Group Relative Policy Optimization (GRPO) assign outcome-level rewards, broadcasting identical trajectory-level advantages to all tokens or actions in a trajectory, disregarding the local heterogeneity of their contributions. In long-horizon tasks, this coarse credit propagation introduces credit diffusion, reinforcing suboptimal behaviors and penalizing beneficial actions, leading to noisy policy updates and slower convergence.
Fine-grained token- or step-level credit assignment methods exist, but practical application is complicated by the absence of reliable local reward signals and misalignment between arbitrary segmentation units and the behavioral structure of agentic trajectories. The GEAR (Granularity-adaptivE Advantage Reweighting) framework proposes a solution that leverages self-distillation to adaptively partition trajectories at behaviorally salient points and redistribute advantage accordingly, yielding more targeted and outcome-consistent policy gradients.
GEAR: Methodological Overview
GEAR reshapes trajectory-level advantage signals by modulating them with reference-guided, token- and segment-level weights derived from self-distillation. The pipeline consists of the following components:
1. Reference-Guided Divergence Estimation:
For each token in a trajectory, GEAR computes the reverse Kullback–Leibler (KL) divergence between the action probabilities of the on-policy student and a ground-truth-conditioned teacher policy. This reference policy is constructed by conditioning the model on the ground-truth data, yielding a behavioral deviation signal for each token.
2. Adaptive Trajectory Segmentation:
Empirical observations reveal that reverse KL divergence spikes sharply at tokens corresponding to semantic departures or transitions (e.g., discourse markers or reasoning shifts), detectable in practice (Figure 1).
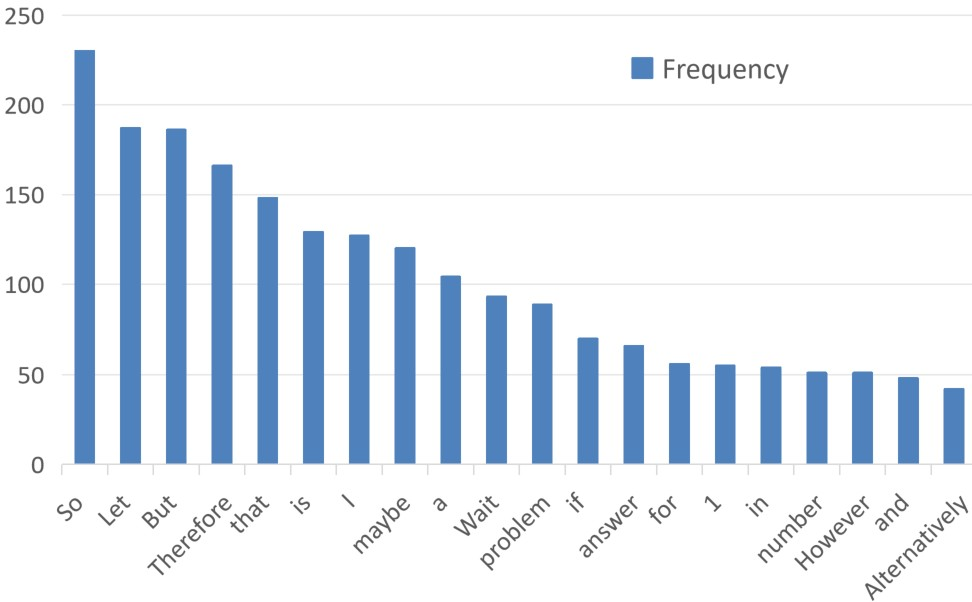
Figure 1: Frequency of top-20 tokens with normalized reverse-KL >0.1 in 100 sampled math trajectories.
Segment boundaries are anchored at these reverse KL spikes, while the extent of each segment is determined by subsequent increases in the token-level policy entropy, which reflects local uncertainty and potential shifts in semantic context (Figure 2).
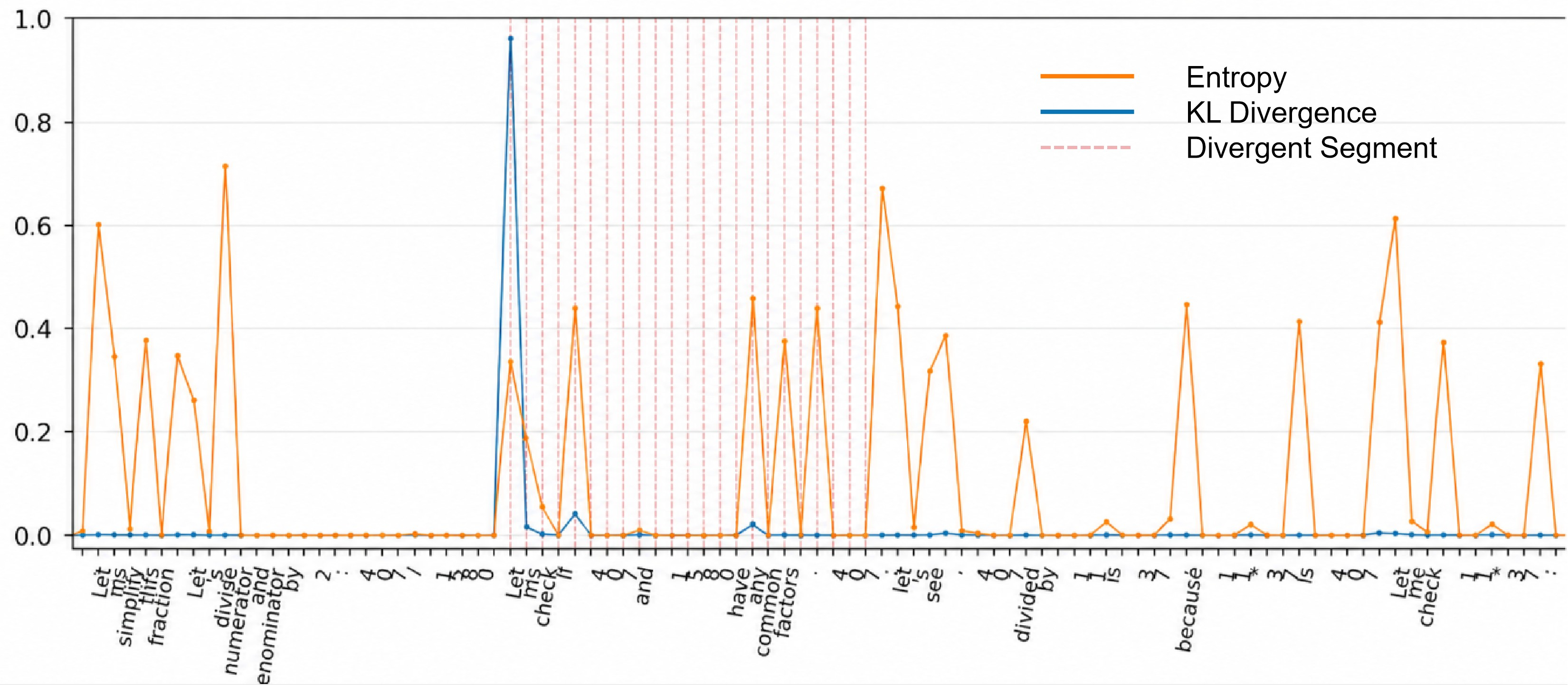
Figure 2: Token-level visualization results of normalized KL divergence and normalized entropy.
All tokens within a divergent segment inherit the credit weight of the segment onset token, propagating localized discrepancy signals. Tokens not in divergent segments retain their individual KL-based weight.
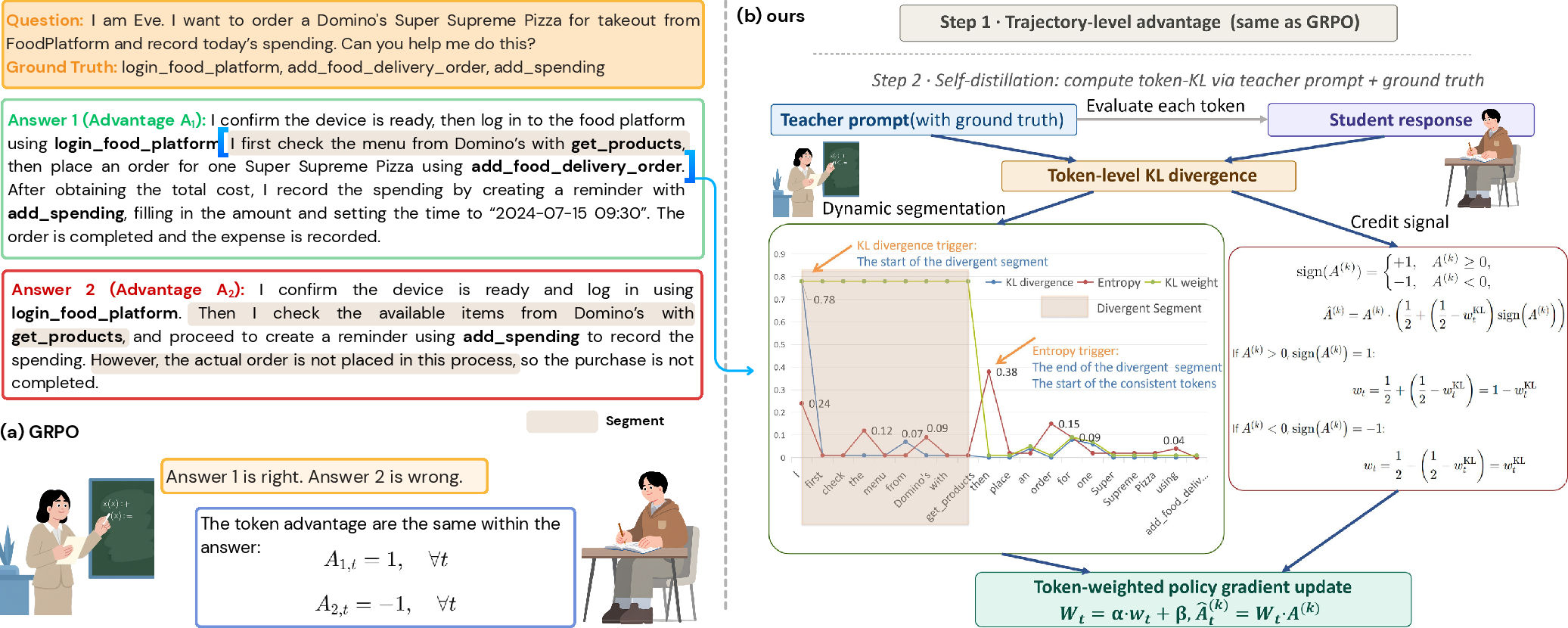
Figure 3: GEAR computes token-wise reverse KL divergence to detect segment onsets and uses entropy to determine segment extent, redistributing trajectory-level advantage adaptively.
3. Advantage-Aware Modulation:
The reweighted local credit signal is modulated by the sign of the original trajectory-level advantage: tokens with high divergence (relative to the teacher) are downweighted for successful trajectories and upweighted for unsuccessful ones. This outcome-aware asymmetry ensures that undesirable deviations are suppressed in positive outcomes and emphasized for correction in negative-outcome rollouts. The modulation preserves the low-variance property of GRPO, only introducing multiplicative weights without injecting high-variance step-level rewards.
Empirical Evaluation
GEAR is evaluated on eight benchmarks spanning mathematical reasoning (e.g., MATH, GSM8K, AIME24/25) and agentic tool-use tasks (e.g., ToolSandbox, BFCL, ACEBench), using Qwen3-4B and Qwen3-8B models. Comparative baselines include GRPO, feature-based multi-turn RL methods (ARPO, MT-GRPO), and token/turn-level self-distillation approaches.
Strong empirical results are reported:
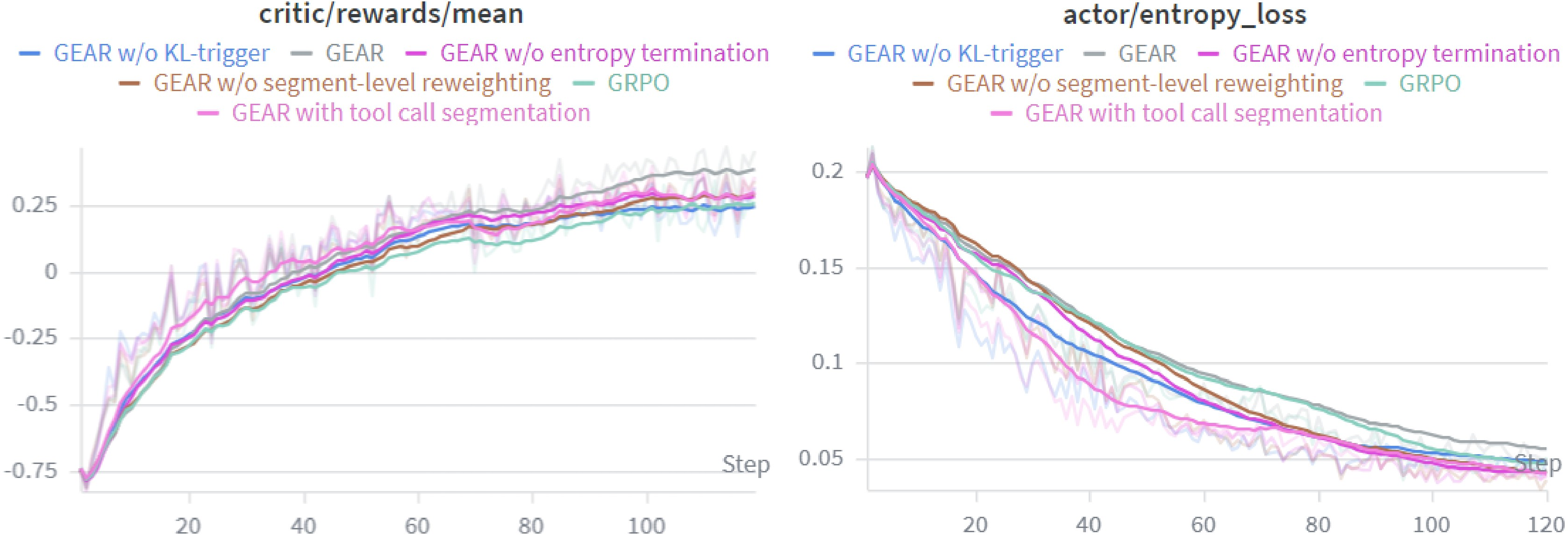
Ablation studies reinforce that both segment-level propagation and the dynamic segmentation strategy (combining reverse KL triggering and entropy-based termination) are essential for achieving stable, fine-grained credit propagation. Using standard units (e.g., turns, tool invocations) or neglecting either segmentation cue results in degraded performance and less accurate credit localization.
Theoretical and Practical Implications
GEAR’s integration of self-distillation divergence and dynamic adaptive segmentation addresses key limitations of fixed-unit credit assignment and step-level reward dependence in RL for LLM agents. By using only ground-truth-conditioned self-reference and intrinsic uncertainty without external reward models or manual annotation, GEAR is applicable to a broad class of RL settings with outcome-only supervision. The approach reduces overfitting to in-domain trajectories and fosters transferability, as evidenced by robust cross-domain results.
Practically, this improves policy reliability, stability, and sample efficiency for LLM-based agents operating in multi-step, compositional environments. Theoretically, it foregrounds the value of leveraging intrinsic model signals for behavioral diagnostics and control, suggesting a broader research agenda around reference-guided, structure-adaptive RL for language agents.
Future Directions
GEAR’s design presumes availability of reliable ground-truth trajectories for constructing the teacher policy. Extension to open-ended environments (where ground truth is ambiguous or multiple valid behaviors exist) could employ proxy signals (e.g., ensemble verification, preference modeling) for reference construction. Broader application to multimodal agentic settings and scaling to more expressive trajectory structures are additional avenues.
Further, integrating GEAR’s adaptive advantage propagation with hierarchical or search-augmented policy architectures, and evaluating its interaction with more sophisticated exploration/exploitation schedules, would offer valuable insights.
Conclusion
GEAR introduces a principled, granularity-adaptive advantage reweighting procedure, leveraging reverse KL divergence and entropy-based segmentation anchored in self-distillation, to advance fine-grained credit assignment in RL for LLM agents. Empirical results validate that GEAR consistently outperforms both outcome-level and token/turn-level baselines, achieving strong improvements especially in long-horizon, challenging settings. The framework reduces the reliance on external/local reward models, facilitating scalable, robust RL fine-tuning for agentic LLM systems and motivating new directions in model-driven trajectory analysis and credit assignment (2605.11853).