- The paper presents a hierarchical spatiotemporal approach that improves anomaly detection by 25.7 points and boosts recall across varied anomaly types.
- It introduces a novel three-stage training regime—single-frame warmup, multi-frame SFT, and two-turn GRPO—that refines spatial grounding and temporal localization.
- Empirical evaluations indicate an overall accuracy of 81.7% with significant cross-domain gains, making CaC a pivotal tool for enhancing video synthesis quality.
CaC: Hierarchical Spatiotemporal Concentrating for Fine-Grained Video Reward Modeling
Motivation and Problem Statement
Contemporary generative video models have achieved substantial gains in global visual fidelity, yet their outputs frequently suffer from sparse, subtle anomalies—structural distortions, physical-law violations, temporal inconsistencies, and corrupted text renderings—especially in synthesizing complex dynamic scenes. These anomalies are spatiotemporally localized, often present in only a few frames or restricted to small regions, making them difficult to isolate and assess. Existing reward models primarily focus on coarse-grained metrics such as global visual quality or text-video alignment, which are inadequate in diagnosing these sparseness-induced bottlenecks. As generation quality rises, the relative importance of detecting these micro-anomalies increases.
CaC (Concentrate and Concentrate) proposes a hierarchical spatiotemporal pipeline to address this deficit, introducing an anomaly-sensitive reward model based on vision-language architectures, capable of robustly grounding and judging sparse defects via coarse-to-fine reasoning.
Dataset Construction for Anomaly Supervision
Recognizing the lack of datasets targeting spatiotemporally sparse anomalies in generated videos, the authors construct a large-scale, expert-annotated corpus with per-frame bounding boxes, temporal anomaly windows, categorical attribution, and saliency labels. The annotation protocol is rigorous, employing dedicated experts, structured taxonomy (object distortion, human distortion, motion anomaly, physical violation, character anomaly), and multi-round review for quality assurance.
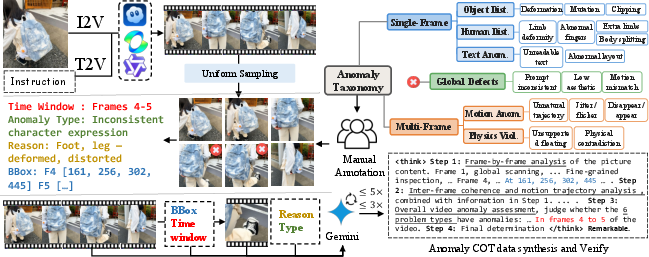
Figure 1: The processing pipeline for the CaC dataset, encompassing video generation, expert annotation of anomaly types, regions, and temporal spans.
The dataset enables high-fidelity Chain-of-Thought (CoT) synthesis. Human-provided temporal and spatial ground truth, when input to a vision-LLM (Gemini-2.5-Pro), results in structured reasoning chains that avoid hallucinated rationales and improve label quality for subtle anomalies.
Model Architecture and Training Paradigm
CaC introduces a three-stage progressive training regime to imbue vision-LLMs with anomaly localization capability:
- Single-frame Warmup: The model learns anomaly recognition and spatial grounding from individual frames, setting up structured mappings from local visual cues to spatiotemporal attributions.
- Multi-frame SFT: Extending to video-level, the model is jointly trained on full sequences (for temporal anchoring) and short clips (for fine spatial localization), facilitated by dense and sparse sampling regimes.
- Two-turn GRPO Fine-tuning: Group Relative Policy Optimization (GRPO) is applied in a hierarchical inferential design. The first turn scans the video temporally (4 fps) for anomalous windows, the second turn grounds spatial anomalies (8 fps) within these windows, producing structured CoT explanations and bounding box predictions.
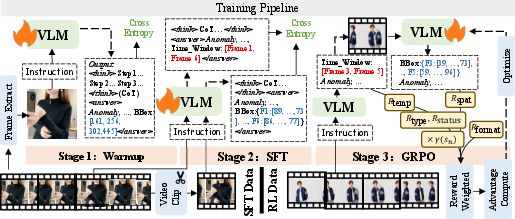
Figure 2: CaC Reward Model's coarse-to-fine three-stage training paradigm, synergistically progressing from spatial grounding to full video localization and reinforcement learning alignment.
Model responses are evaluated with a reward aggregation function incorporating format compliance, status accuracy, temporal and spatial IoU, attribution IoU, and anomaly saliency adjustment.
Coarse-to-Fine Inference and Structured Reward Interface
The two-turn inference protocol efficiently concentrates compute: global scan to anchor a temporal window, dense localized spatial reasoning to confirm anomalies and attribute fine-grained bounding boxes. This mechanism outperforms monolithic frame sampling approaches by focusing on regions most likely to contain defects.
CaC also exposes a structured-to-scalar interface, mapping the final judgment's vocabulary probabilities (normal/abnormal) to a scalar reward suitable for downstream RL optimization.
Empirical Evaluation and Numerical Results
CaC is benchmarked against general VLMs (Gemini, GPT-4o, Qwen3-VL), specialized reward models (UnifiedReward, VR-Thinker), and detection-based baselines (Skyra, VideoVeritas) on CaC-Bench-Main and CaC-Bench-Hard suites, featuring challenging splits by anomaly duration and spatial extent.
CaC achieves 81.7% overall accuracy, representing a 25.7-point improvement over the strongest baseline. Its advantage is accentuated on sparse anomaly splits—recall improvements of 38%, 16%, 36%, and 14% across difficulty groups—displaying sensitivity across all five anomaly categories.
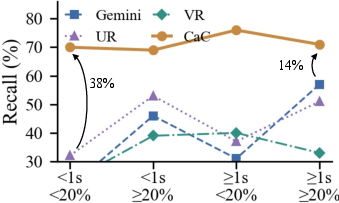
Figure 3: Quantitative comparison on CaC-Bench-Hard; CaC's recall is robust across temporal and spatial splits, outperforming competing models in anomalous-only evaluation.
Additional external validation on the Skyra-ViF-CoT-4K subset confirms 19.9-point gains over the best baseline, indicating cross-domain generalization. Temporal and spatial IoU metrics demonstrate marked improvements in localization quality.
Impact on Video Generation and Alignment
As a reward model integrated into downstream video generation frameworks (e.g., Flow-GRPO, Best-of-N sampling), CaC yields actionable optimization feedback. Combining UnifiedReward (general preference) with CaC (anomaly specialist) in alignment paradigms produces the following effects:
Ablation Studies and Diagnostic Value
Systematic ablations confirm the necessity of each training stage. Removing the single-frame warmup, multi-frame SFT, or two-turn GRPO stages results in significant accuracy drops (12%, 16%, 14%, respectively). The inference strategy, particularly temporal IoU rewards, is critical for robust window localization.
Per-category recall and qualitative visualizations underscore CaC's comprehensive coverage and interpretability in anomaly attribution, supporting its deployment as a modular evaluation signal in multimodal generative systems.

Figure 5: CaC two-turn reasoning visualizations: temporal scan followed by spatial grounding yields interpretable, robust chain-of-thought analyses targeting subtle phenomena.
Conclusion
CaC establishes a new paradigm for video reward modeling via hierarchical spatiotemporal concentrating. The methodological combination of dataset construction, progressive training, coarse-to-fine inference, and multi-dimensional reward supervision enables high-performance anomaly detection and localization. Empirical results validate its superiority over incumbent models, both in sparse-anomaly sensitivity and generative model alignment effectiveness.
Practically, CaC facilitates both finer anomaly control in video synthesis and more interpretable reward signal engineering, foreshadowing a landscape where specialized evaluators address distinct qualitative dimensions. Theoretically, the paper introduces a framework for localized RL guiding of generative models using spatiotemporal evidence, paving the way toward more modular, tightly-coupled reward architectures. Future research directions include scaling to longer videos, fully automated annotation pipelines, and integrating direct feedback into generator denoising trajectories for causally grounded anomaly suppression.


