- The paper identifies an optimizer mismatch where Adam’s elementwise regularization and Muon’s matrix-level bias create distinct weight geometries.
- It demonstrates through theoretical and empirical analyses that LoRA fine-tuning effectively bridges the gap by constraining update magnitudes.
- The study reveals that low-rank adaptation not only preserves pretrained structures but also reduces catastrophic forgetting across domains.
Muon Fine-Tuning for Adam-Pretrained Models: Uncovering Optimizer Mismatch and Mitigation via LoRA
Introduction
The paper "Can Muon Fine-tune Adam-Pretrained Models?" (2605.10468) provides a rigorous analysis of the optimizer mismatch problem that emerges when switching between Muon and Adam for pretraining and fine-tuning large neural networks. Muon, a matrix-level optimizer that recent LLM pretraining research has shown to be more computationally and memory efficient than Adam, is increasingly used for pretraining at large scales. However, most open-source LLMs are pretrained with Adam, and naively swapping to Muon for fine-tuning degrades downstream performance. The paper formalizes, empirically quantifies, and theoretically analyzes this mismatch, and proposes that parameter-efficient fine-tuning with LoRA can systematically mitigate the adverse effects.
Theoretical Analysis and Mechanisms of Mismatch
The optimizer mismatch stems from fundamental differences in the implicit regularization (implicit bias) induced by Adam and Muon. Adam employs elementwise adaptive learning rates through second-moment tracking, implicitly biasing toward minimum max-norm solutions. In contrast, Muon operates on weight matrices, applying matrix-level normalization (Newton-Schulz orthogonalization), and biases toward solutions with minimum spectral norm.
This distinction is formalized using a toy linear regression setting, showing that SignGD/Adam converges to the minimum max-norm solution while Muon finds the minimum spectral-norm solution (Theorems 1, 2). When transferring between weights pretrained under different optimizers, these geometric disparities become structural: Adam and Muon produce weight matrices with distinct singular value spectra and stable rank distributions, as verified numerically.
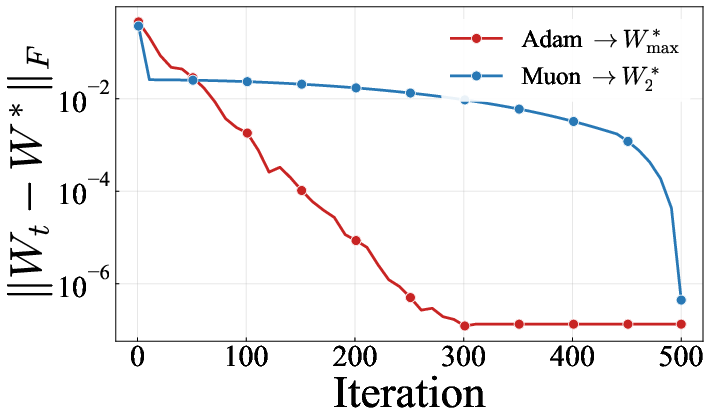
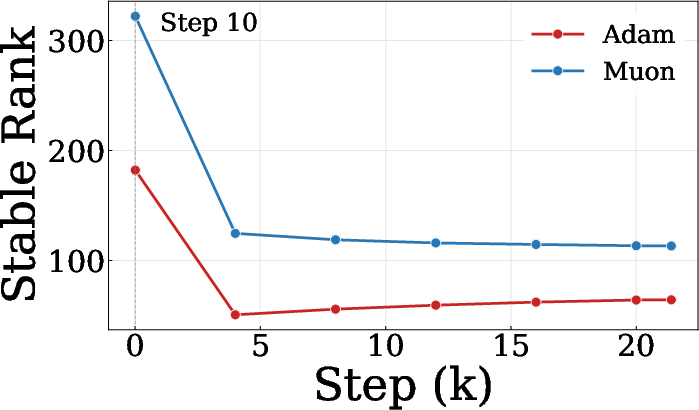
Figure 1: Left: Adam converges to the minimum max-norm solution; Muon to the min spectral-norm solution. Right: Muon-trained attention weights show higher stable rank.
The mismatch manifests empirically as sensitivity during fine-tuning: using a mismatched optimizer significantly increases downstream loss and narrows the viable learning rate (LR) region, with evidence that larger updates exacerbate the disruption of pretrained structure. Learning rate sweeps reveal a pronounced upward and leftward shift in loss curves under mismatch, while matched optimizer trajectories remain stable.
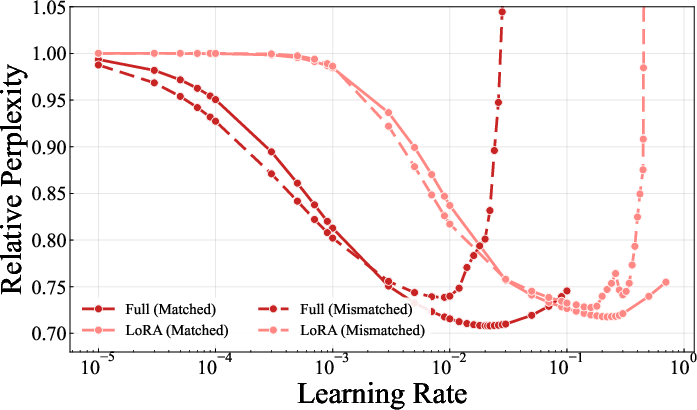
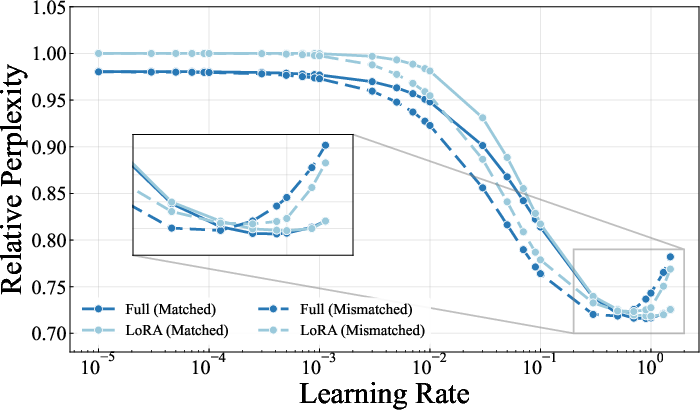
Figure 2: Adam fine-tuning; learning curves shift under mismatch, with optimal LR decreasing and best perplexity degrading.
LoRA as a Mitigation Strategy
The authors hypothesize that constraining update strength can suppress the detrimental effects of optimizer mismatch. LoRA fine-tuning, by virtue of freezing the pretrained weights and updating only a low-rank adapter, satisfies this criterion. Theoretically, under a LoRA-style constraint, the effect of mismatch inflates with rank but vanishes in the rank-1 limit.
Empirically, across both language and vision domains, LoRA not only narrows the Adam–Muon performance gap but, in many regimes, allows Muon to match or modestly outperform Adam. The extent of mitigation is evident in relative perplexity curves, where the full fine-tuning gap shrinks dramatically under LoRA, irrespective of the pretraining optimizer. Results are consistent across diverse architectures and modalities.
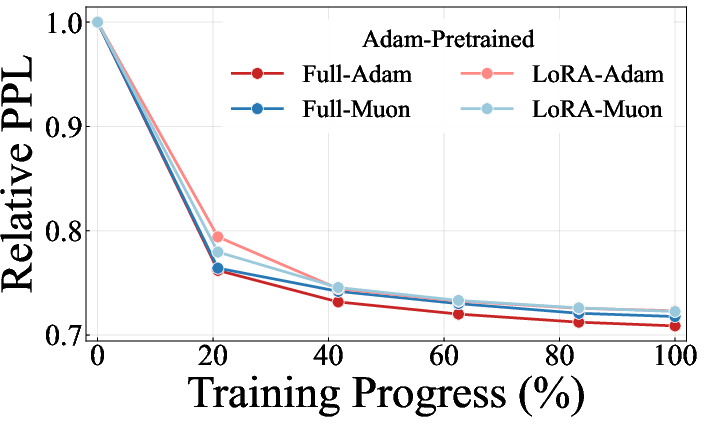
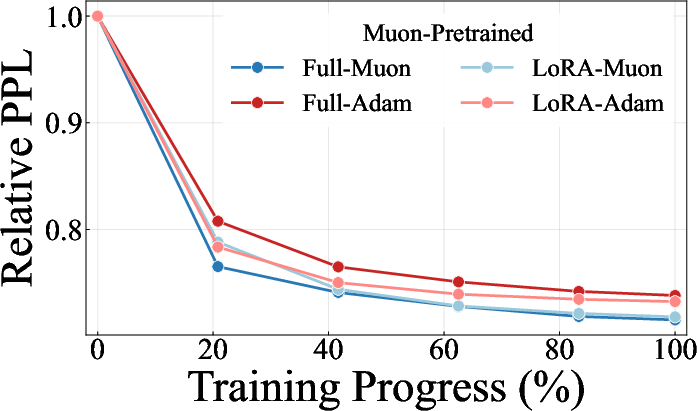
Figure 3: LoRA mitigates optimizer mismatch in fine-tuning perplexity trajectories for both Adam- and Muon-pretrained NanoChat models.
Experimental Results Across Domains
A comprehensive sweep of tasks is conducted: natural language understanding (GLUE with T5-Base), generation (math, code, commonsense QA with Llama 2–7B), and vision (image classification with CLIP ViT-B/32). In all settings, full fine-tuning with a mismatched optimizer yields consistent degradation relative to the matched case (about 0.3–5% mean drop, more pronounced for some tasks). However, LoRA—especially at moderate ranks—yields nearly identical, and sometimes slightly superior, performance for Muon versus Adam.
Systematic LoRA rank studies reveal that at low and moderate ranks (e.g., 2–32), LoRA-Muon matches or outperforms LoRA-Adam. As rank is increased, the update trajectory becomes increasingly similar to full fine-tuning, and the mismatch-related degradation re-emerges. This indicates a rank-dependent transition between regimes where LoRA's update constraint is protective versus not (especially pronounced in domains with strong optimizer-specific structural artifacts, such as mathematical reasoning).
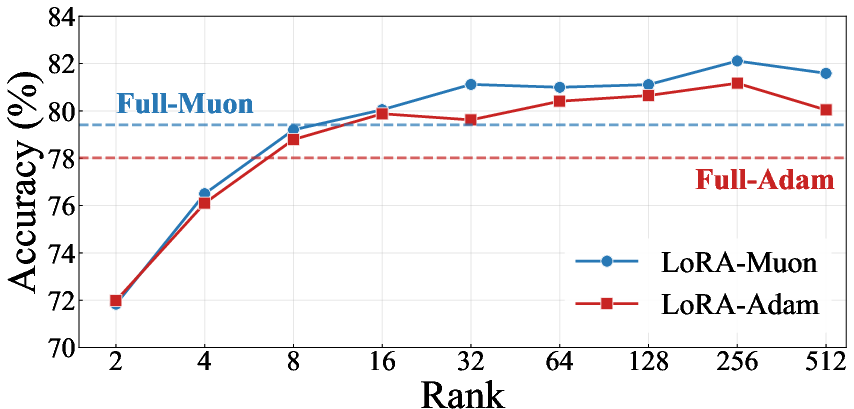
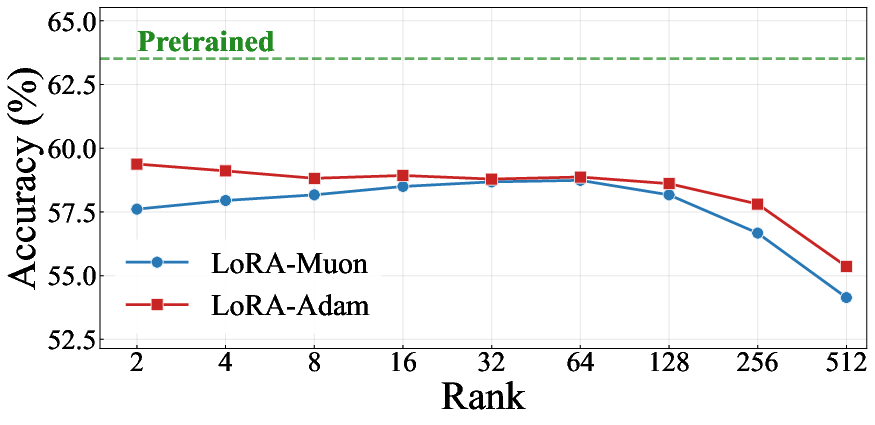
Figure 4: Left: On StanfordCars, LoRA-Muon outperforms LoRA-Adam for most ranks; Right: For Llama 2-7B on MetaMath, mismatch-induced catastrophic forgetting is attenuated at lower ranks.
Catastrophic Forgetting and Structural Effects
The optimizer mismatch induces not only a drop in target-task performance but also amplifies catastrophic forgetting: the loss of pretrained knowledge on unrelated benchmarks (e.g., commonsense reasoning after math fine-tuning). Full-Muon fine-tuning from Adam-pretrained LLMs incurs more forgetting and moves further from the pretrained weights in parameter space, both in L2 and cosine distance. LoRA consistently reduces this forgetting, with LoRA-Muon underperforming only for high ranks where it increasingly emulates full matrix updates.
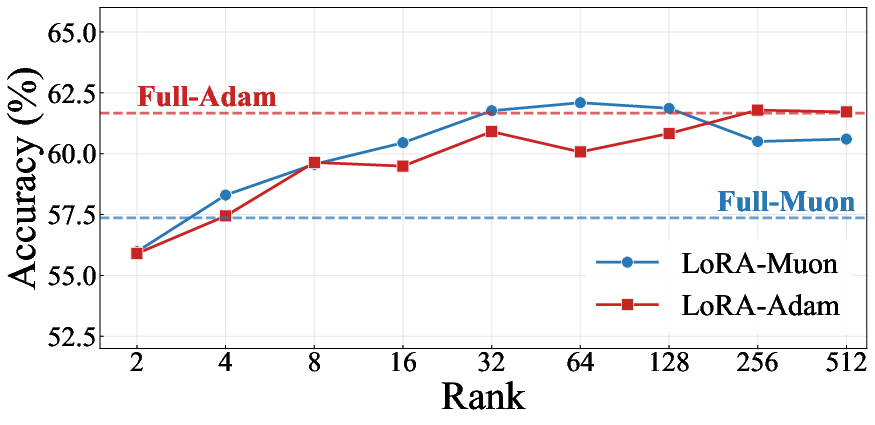
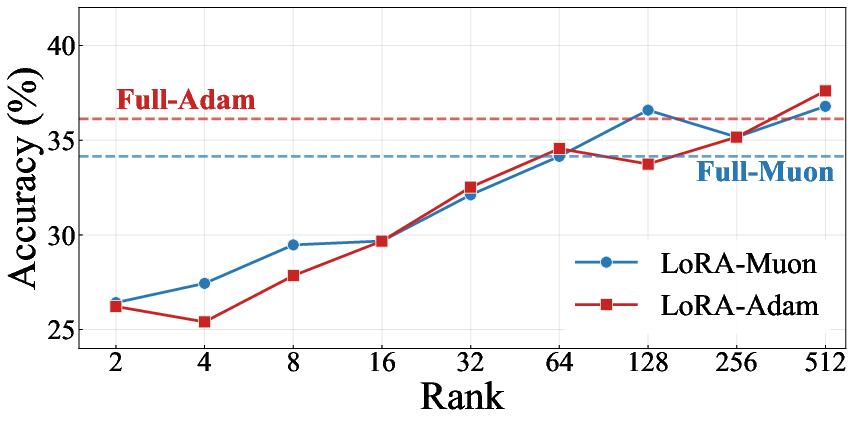
Figure 5: After fine-tuning for math (MetaMath), LoRA retains more GSM8K performance, mitigating forgetting relative to full fine-tuning.
Spectral Dynamics and Additive Effects
The study provides spectral diagnostics of both base weights and the LoRA adapters throughout training. Muon consistently induces higher stable rank and entropy in adapter matrices, reproducing its spectral-norm bias at the level of updates on frozen weights. This suggests LoRA's mitigating effect is tied to its role as an adapter, where Muon's native update geometry can operate without conflict with the legacy structure of the base parameters.
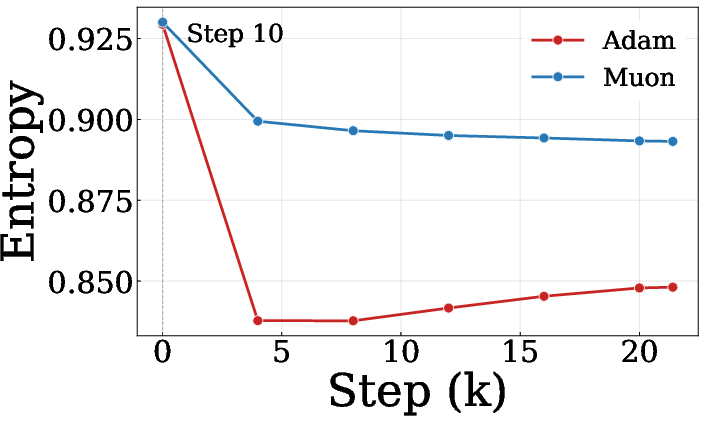
Figure 6: Muon-trained QKV projection weights maintain higher stable rank and entropy during NanoChat pretraining.
Limitations and Further Implications
While the findings underpin LoRA's utility in addressing optimizer mismatch, certain LoRA variants (e.g., rsLoRA, PiSSA, LoRA-One) do not consistently yield further gains when combined with Muon, likely because they aim to emulate full fine-tuning or amplify update magnitude, which exacerbates mismatch. The full fine-tuning gap persists for certain harder tasks or for very expressive LoRA adapters, implying a structural rather than merely algorithmic barrier.
The practical upshot is clear: for Adam-pretrained models, LoRA allows Muon to be used without loss of downstream quality and with substantial memory reduction (50% less optimizer state). For settings prioritizing large-scale distributed efficiency or where only LoRA-based adaptation is needed, Muon is now immediately usable as a drop-in replacement for Adam.
Conclusion
This paper provides a thorough treatment of the optimizer mismatch problem between Adam and Muon, rooted in their fundamentally distinct implicit biases and structural artifacts. The work demonstrates—both theoretically and empirically—that constraining updates via LoRA is effective at mitigating the mismatch, thus unlocking Muon's resource efficiency for prevalent Adam-pretrained models without degradation in downstream fine-tuning.
Future research directions include a formal characterization of the interplay between pretrained weight geometry and downstream adaptation, the principled design of Muon-specific LoRA variants, and a comprehensive exploration of alternative constrained-update schemes (beyond LoRA) to further generalize the mitigation of optimizer-induced structural conflicts.