- The paper introduces a decoupled, data-centric methodology that bridges user intent and advertiser promise by explicitly modeling the 'Logical Bridge' in LLM responses.
- The paper demonstrates that Supervised Fine-Tuning and in-context learning substantially improve ad integration metrics, with 78.6% of LLM samples outperforming human baselines and achieving significant score gains (p<0.001).
- The paper provides a comprehensive dataset of ~59K samples and a robust calibration framework that eliminates halo effects, enabling transparent, joint optimization of user experience and commercial effectiveness.
NaiAD: A Data-Centric Foundation for LLM-Native Advertising
Introduction and Motivation
With the proliferation of generative AI assistants in consumer and enterprise applications, the integration of advertising into LLM outputs has become both commercially attractive and technically challenging. The central tension lies in balancing monetization objectives (maximizing platform and advertiser value) with user experience (ensuring conversational relevance and coherence). Existing LLM advertising pipelines predominantly employ “hard insertion” of ad content, which disrupts conversational flow and degrades utility for both stakeholders.
"NaiAD: Initiate Data-Driven Research for LLM Advertising" (2605.09918) introduces the NaiAD dataset and methodology as a systematic foundation for LLM-native advertising. This work posits that optimal ad embedding is a cognitive process rooted in modeling the latent “Logical Bridge” between user intent and commercial payload, and that practical progress requires a robust, unbiased, multi-dimensional dataset and calibrated evaluation metrics.
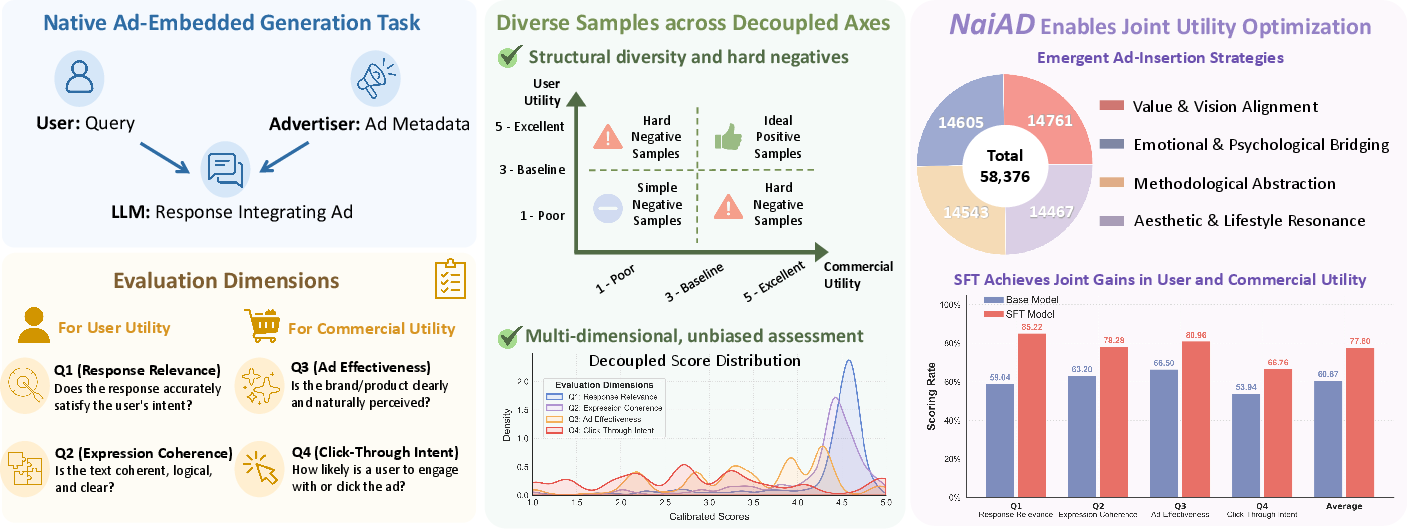
Figure 1: The NaiAD dataset conceptual framework—task definition, decoupled metrics, data generation, and main empirical findings.
Dataset Construction and Structural Decoupling
NaiAD comprises 58,999 ad-embedded LLM responses paired with user queries, spanning 58,376 LLM-generated samples and 623 human-transcribed YouTube sponsorship segments. Crucially, data generation is guided by a decoupled pipeline engineered to overcome dimensional collinearity—LLMs’ tendency to produce outputs that are uniformly strong (or weak) across all evaluation axes due to RLHF and alignment optimization.
The construction pipeline operates in three phases:
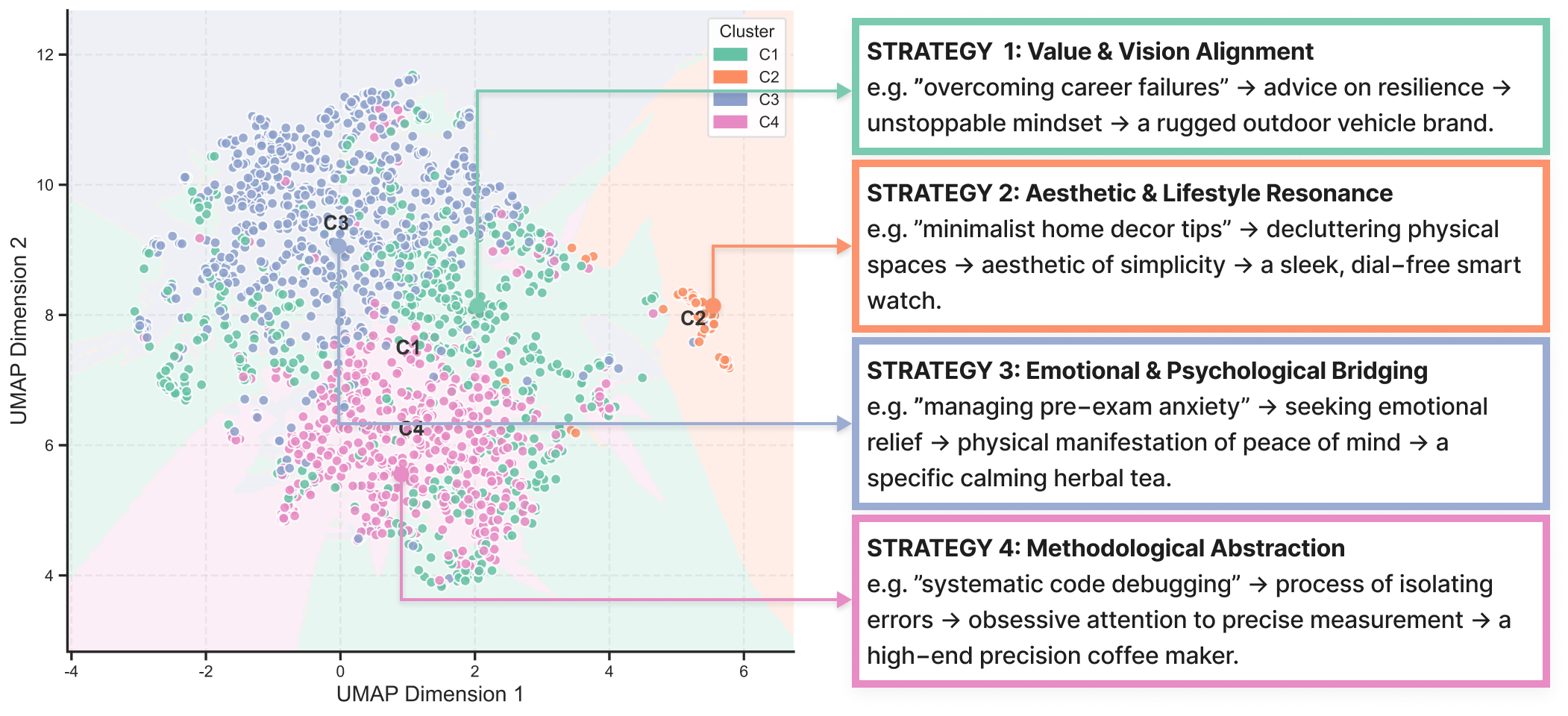
- Elicitation of Cognitive Strategies: LLMs are prompted to explicitly articulate the reasoning path—the "Logical Bridge"—that connects a given user query to an advertiser’s value proposition. PCA and K-Means clustering performed on Sentence-BERT embeddings of these bridges robustly reveal four principal cognitive strategies for ad integration, optimized by the Silhouette Score at K=4.
- Dimensionally Decoupled Generation: Each synthetic sample is constructed by randomly assigning a strategy and enforcing targeted, decoupled scores across four axes: two for user utility (Relevance, Coherence) and two for commercial utility (Ad Effectiveness, Click-Through Intent). Hard negatives are synthesized by requiring minimum score differentials and enforcing challenging template constraints. LLMs are forced to output both the plan (bridge) and the final response, ensuring transparency and data traceability.
- Variance-Calibrated Score Annotation: Unbiased evaluation at dataset scale is achieved with the Variance-Calibrated Prediction-Powered Inference (VC-PPI) procedure. A human-annotated anchor set is used to fit dimension-specific calibration models—polynomial regression for user utility and decision trees for commercial utility—restoring inter-sample variance and neutralizing LLM judge biases.
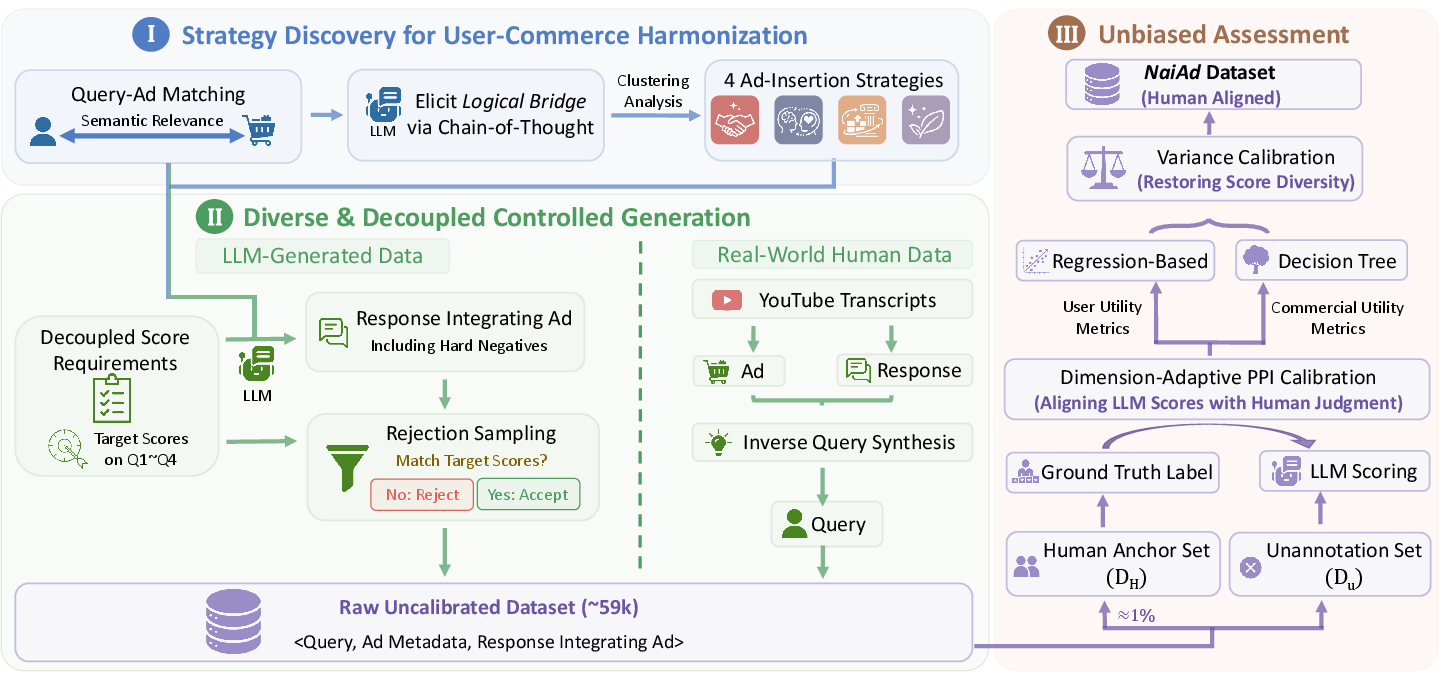
Figure 2: Overview of construction and calibration pipeline: cognitive strategy discovery, decoupled sample generation, and statistical calibration of scores.
Emergent Cognitive Strategies and Latent Structures
Mechanistic analysis of bridge embeddings reveals four non-overlapping semantic clusters in latent space, corresponding to:
This structure is not anecdotal; it emerges universally as the optimal approach for harmonizing user and advertiser value objectives across the dataset.
Robust Evaluations and Calibration: Eliminating the Halo Effect
The VC-PPI score calibration pipeline is empirically validated to decisively break the “Halo Effect”—spurious inter-metric correlations induced by aligned LLM evaluators. For example, PPI calibration reduces the cross-domain correlation between user relevance and commercial click-through from ρ=0.39 to $0.00$, restoring metric independence and aligning with human ground-truth judgment.
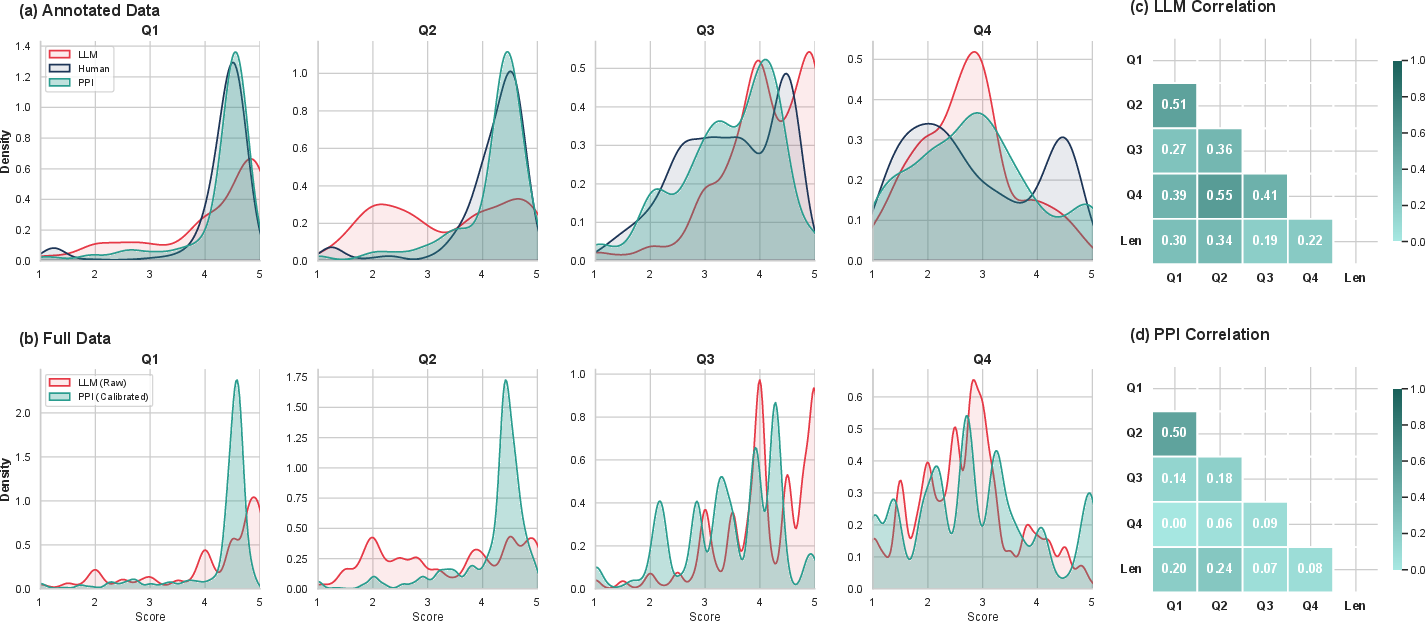
Figure 4: (a, b) Score distribution correction for user utility; (c, d) Heatmaps evidencing decoupling of evaluation dimensions post-calibration.
Comparative Experiments: LLM vs. Human and SFT Impact
Pareto Optimality and Maximal Integration
NaiAD’s structurally diverse generation pipeline yields LLM-generated ad embeddings that are Pareto-dominant relative to human YouTube sponsorships in commercial utility metrics, while maintaining near-parity in user utility. For Click-Through Intent, 78.6% of LLM samples exceed the mean of human baselines, demonstrating the pipeline’s ability to optimize previously conflicting objectives.
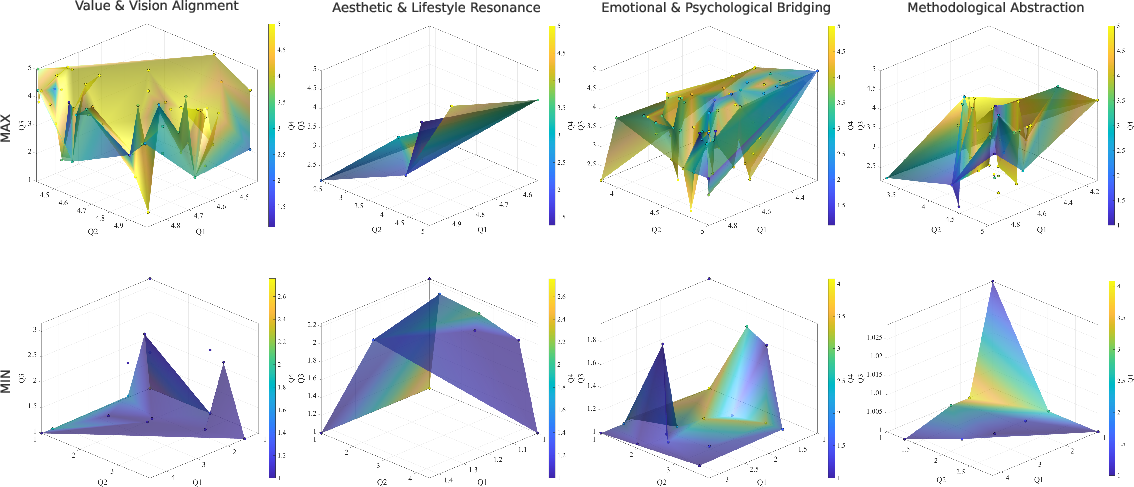
Figure 5: 4D Pareto frontier distribution for the four logical bridge strategies, illustrating broad exploratory and optimality space.
Fine-Tuning and Breakthrough in Joint Optimization
Supervised Fine-Tuning (SFT) on the NaiAD dataset results in simultaneous, statistically significant gains across all four utility axes. Notably, no trade-off is needed—joint optimization of user and commercial objectives is empirically feasible. The mean score gains for SFT models are highly significant (p<0.001; e.g., +26.18% on relevance, +14.46% on effectiveness).
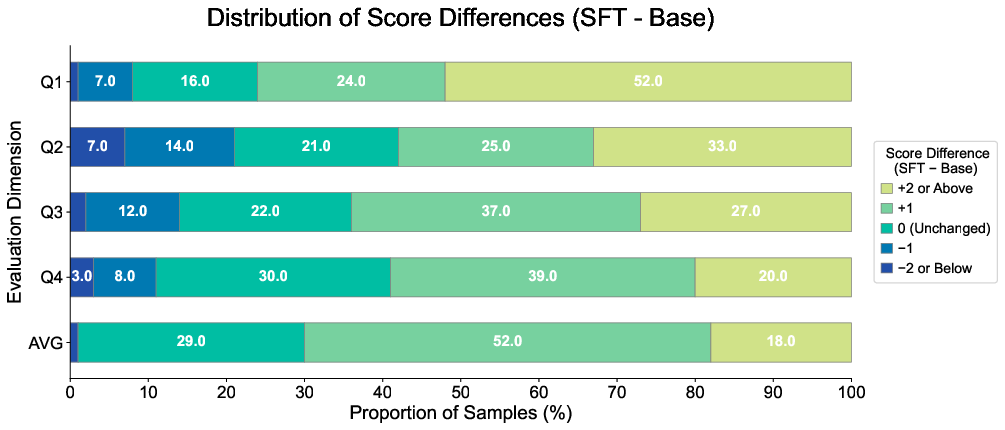
Figure 6: Distribution of per-sample score shifts for SFT vs. baseline, confirming systematic gain across dimensions.
Controllable Generation via In-Context Learning
NaiAD contains a sufficient density of multi-objective hard negatives and reference samples as to support precise, decoupled controllable generation through in-context learning (ICL). Ten-shot ICL enables LLMs to accurately target fine-grained, discordant response profiles (e.g., suppressing commercial utility, amplifying user coherence), outperforming zero-shot baselines by 8–16% in target accuracy.
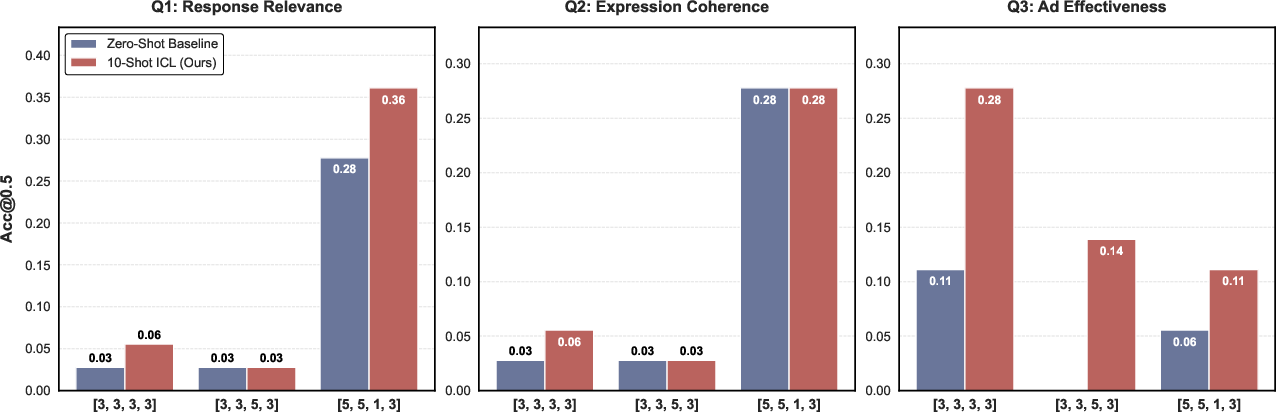
Figure 7: [email protected] for controllable generation of diverse decoupled scoring profiles, confirming the efficacy of in-context references.
Practical and Theoretical Implications
The NaiAD methodology concretely challenges the notion that there is a necessary trade-off between user satisfaction and commercial intent in LLM advertising. Through cognitive decomposition and unbiased evaluation, it establishes that synthetic generative models can, with proper data and supervision:
- Achieve simultaneous optimization of user and advertiser utility;
- Make integration decisions that are transparent, explainable, and anchored in explicit reasoning;
- Provide a solid foundation for dynamic, persona-adaptive, and compliance-constrained monetization frameworks.
In practical terms, this opens the path for programmatic control over ad integration intensity (e.g., utility-weighted bidding and user-persona targeting), and enables rigorous compliance with regulatory requirements on transparency and bias.
Limitations and Future Directions
Despite the substantial contributions, NaiAD is bounded by domain-specific source data, the scale of its human-labeled calibration set, and the potential for factual hallucinations in generated ads. Extension to multi-turn, multimodal, and cross-cultural advertising, as well as automated hallucination control, are identified as promising future research areas.
Conclusion
"NaiAD: Initiate Data-Driven Research for LLM Advertising" (2605.09918) establishes a comprehensive, data-centric framework and open dataset for studying and optimizing LLM-native advertising. Its multi-dimensional, structurally decoupled methodology, rigorous evaluation pipeline, and mechanistic insights into the integration process redefine the empirical basis for generative AI monetization. NaiAD provides indispensable infrastructure for research and industry efforts in building LLM systems that balance commercial objectives with user-centric design, and demonstrates that the apparent conflict between user experience and monetization is not fundamental, but a function of suboptimal strategies and inadequate benchmarking.