- The paper introduces a bi-level reinforcement learning framework that decouples agent skill evolution from the task LLM, enabling recurrent skill refinement.
- It employs a lightweight skill generator and group-relative policy optimization to iteratively improve rollout quality and skill reliability.
- Empirical results on GAIA and WebWalker benchmarks show significant accuracy gains and consistent performance improvements across multiple generations.
Skill-R1: Agent Skill Evolution via Reinforcement Learning
Skill-R1 addresses the recurrent optimization of agent skills in LLM-based agents, decoupling the improvement of procedural guidance ("skills") from the adaptation of the main LLM. Conventional approaches to agent skill evolution rely primarily on prompt engineering, static skill banks, or costly fine-tuning of task LLMs. These methods are limited by misaligned objectives, inefficiency, and lack of generalizability, especially in settings with proprietary or black-box models. Skill optimization should be treated as a bi-level, recurrent decision problem: skills must be revised to improve rollout quality under the current context, and each revision should leverage observed successes and failures for future improvement. Skill-R1 formalizes this as a bi-level group-relative policy optimization problem, aligning both intra-generation rollout performance and inter-generation skill improvement.
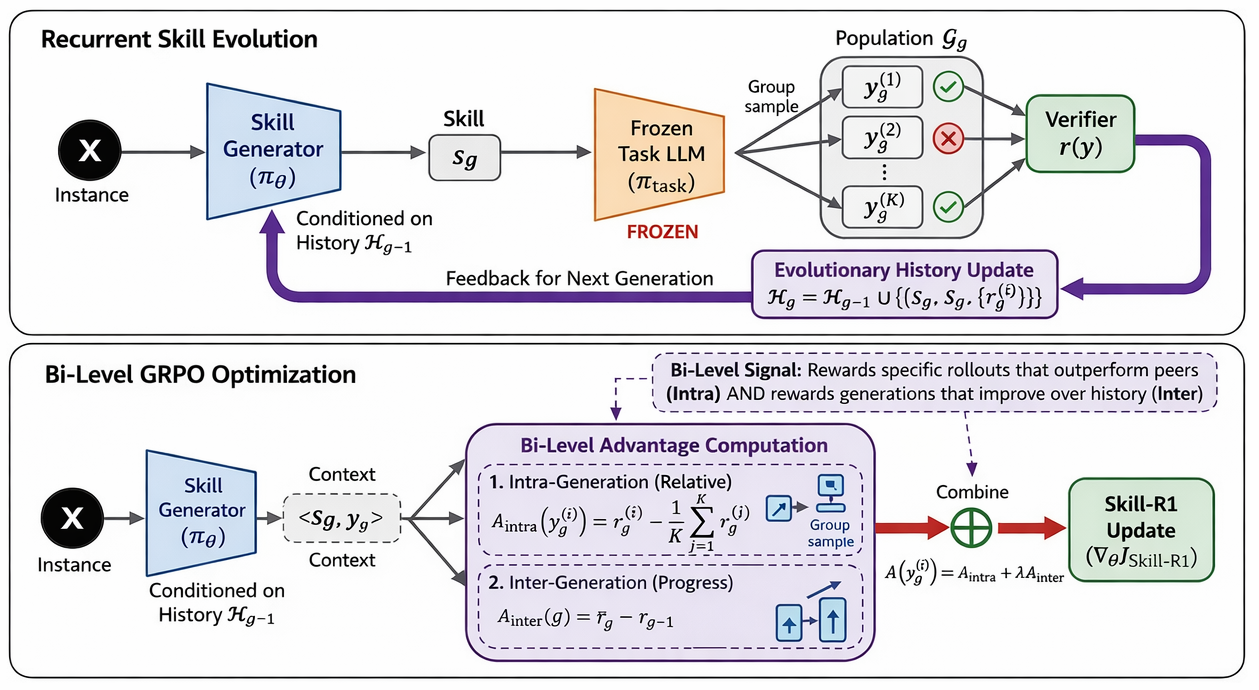
Figure 1: Skill-R1 overview, illustrating recurrent skill generation, rollout and verification, and bi-level GRPO optimization with task LLM frozen.
Skill-R1 Framework
The Skill-R1 framework separates task execution (performed by a frozen task LLM) from skill improvement (conducted by a lightweight, learnable skill generator). At each generation, the skill generator proposes a new skill conditioned on the task context and the historical trajectory of rollouts and rewards. The task LLM executes rollouts based on this skill, and a verifier scores each outcome. The resulting success/failure signals are appended to an instance-specific evolutionary history, which informs subsequent skill revisions.
This cyclical, multi-generation process supports directional skill evolution. Each skill revision is empirically evaluated through rollout populations, making the system amenable to recurrent reinforcement learning (RL) optimization, rather than one-shot heuristic refinement.
The bi-level credit assignment mechanism is central: intra-generation advantages compare rollout quality within the same skill (relative to group mean), while inter-generation advantages reward skill revisions that induce improvements between generations (relative to previous population mean reward). The sum—a bi-level advantage—serves as the RL signal to optimize the skill generator via group-relative policy optimization (GRPO). Only the skill generator is updated; the task LLM remains fixed, enabling compatibility with both open- and closed-source models.
Theoretical Contribution
Skill-R1 generalizes RL for agentic LLMs by introducing bi-level GRPO credit assignment, optimizing both rollout selection and skill revision. This objective ensures that skill evolution is directional: each update is incentivized to improve agent behavior in a lasting, compositional manner. The clipped GRPO surrogate further stabilizes optimization via importance-weighted policy updates and KL anchoring to a reference distribution.
Empirical Results
Experiments demonstrate consistent and substantial improvements over both no-skill baseline and standard GRPO policy optimization across multiple benchmarks: GAIA (multi-modal reasoning over heterogeneous sources), and WebWalker (multi-hop web navigation and cross-page reasoning). The Skill-R1 setup achieves accuracy gains ranging from +4% to +12% over vanilla GRPO, particularly for complex, multi-step tasks.
GAIA benchmark: Skill-R1 (GRPO) reaches 41.8% overall accuracy, outperforming vanilla GRPO (29.7%) and no-skill baseline (6.1%). Gains are most pronounced in Level 3 tasks (38.5% vs 15.4% for GRPO), which demand compositional reasoning.
WebWalker benchmark: Skill-R1 (GRPO) achieves 26.0% accuracy, surpassing vanilla GRPO (22.0%), with strongest improvements in medium and multi-source settings.
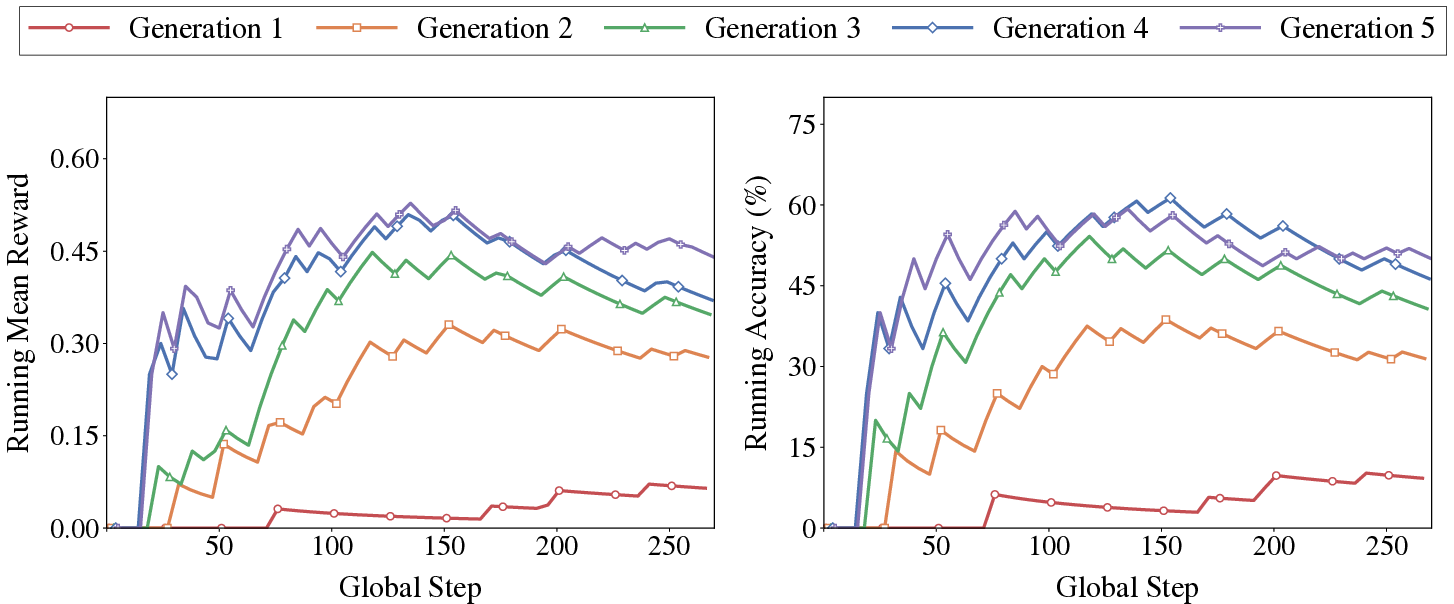
Figure 2: Accuracy and reward curves across 5 generations, showing monotonic progression and performance stabilization.
Skill-R1 exhibits monotonic improvements in both reward and accuracy across generations, with the most significant gains realized in early rounds (Generations 1–3). Later generations stabilize and refine skill reliability, boosting consistency within each task.
Qualitative skill evolution analysis confirms that trained skill editors (GRPO) retain core executable structure, introduce targeted safeguards, and avoid overfitting to incidental, task-specific context—as opposed to inference-only editors, which degrade skill compositionality.
Practical and Theoretical Implications
Skill-R1 provides a scalable approach to skill evolution for LLM agents, especially in environments where task LLM adaptation is infeasible. By maintaining model-agnostic compatibility via a frozen task LLM, Skill-R1 enables deployment across both proprietary and open-source platforms, lowering computational cost and adaptation latency. The recurrent bi-level optimization framework ensures directional improvement and compositional generalization, supporting complex reasoning, tool use, and robust execution. Theoretical advances in bi-level and group-relative RL objectives may inform broader learning paradigms for agent orchestration, memory skill refinement, and continual self-improvement.
Future Directions
Skill evolution via bi-level optimization opens several avenues:
- Multi-instance and ecosystem-scale skill evolution: Leveraging population-level skill libraries and sharing evolutionary histories beyond single tasks.
- Continual learning and longitudinal evaluation: Integrating Skill-R1 with lifelong memory architectures and agent self-reflection frameworks.
- Black-box adaptation and cross-modal skill conditioning: Extending Skill-R1 to multimodal or federated scenarios, further minimizing reliance on task model gradients.
- Efficient reward acquisition: Enhancing reward modeling via weakly-supervised or reward-conditioned GRPO variants.
Conclusion
Skill-R1 advances agent skill evolution by decoupling procedural optimization from core LLM adaptation, employing a bi-level reinforcement objective that rewards both strong rollouts and effective skill revision. Empirical results establish its superiority on complex agentic tasks, with pronounced gains in compositional reasoning, reliability, and adaptation efficiency. The skill-centric optimization paradigm substantially expands the practical and theoretical toolkit for agentic LLM research, offering an avenue for scalable, efficient, and directional agent improvement in diverse environments.

