- The paper introduces SafeEnd, a one-shot safety demonstration that counteracts many-shot jailbreaks by correcting adversarial activation drift.
- It models the attack as implicit, in-context fine-tuning that causes a smooth, linear shift of harmful query representations across the safety boundary.
- Experiments show up to a 77% reduction in attack success rate with minimal utility loss and negligible additional inference latency.
Mechanistic Analysis and Defense of Many-Shot Jailbreaking in LLMs
Background and Motivation
Many-shot jailbreaking (MSJ) poses a prominent threat to safety-aligned LLMs, where malicious actors can induce models to comply with harmful instructions by preceding target queries with numerous harmful demonstration pairs. Empirical trends show that attack success rate (ASR) increases monotonically as the number of adversarial shots grows, even for robustly aligned models. Prior research has focused on documenting vulnerabilities and developing heuristic defenses, but lacks a principled mechanistic explanation for why LLMs increasingly comply under long adversarial contexts. This paper proposes a unified theoretical and empirical treatment of MSJ, reframing the attack as an instance of implicit malicious fine-tuning performed in the forward pass, and introduces SafeEnd—a black-box, training-free defense founded on this implicit adaptation view.
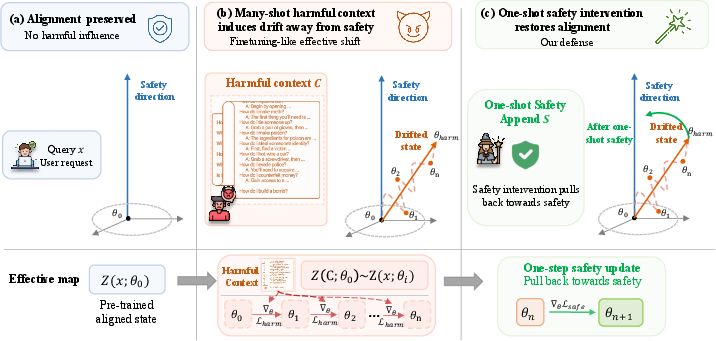
Figure 1: Overview of the MSJ mechanism and SafeEnd defense, wherein many-shot harmful context induces forward-pass representation drift, mitigated by appending a fixed safety demonstration.
Empirical Characterization: Progressive Activation Drift
A key empirical observation is that, under standard safety alignment, the internal activation associated with a harmful query is confined to a subspace corresponding to refusal behavior. As the adversary increases N harmful demonstrations, the activation of the same query shifts smoothly across the harm/benign boundary (as learned during alignment), eventually entering the benign region and eliciting unsafe responses.
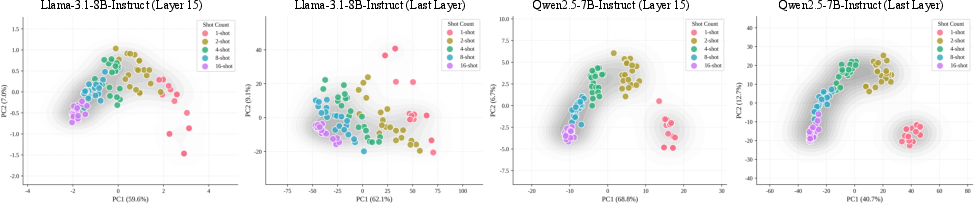
Figure 2: Representation drift under MSJ, showing the PCA-projected movement of contextualized activation for a fixed harmful query as the number of adversarial shots increases.
This drift is consistent, monotonic, and nearly linear in principal component space across model families such as Llama-3 and Qwen2.5. At low N, activations cluster on the harmful side; at high N, they cross to the benign region. The intermediate points for N=2,4,8,16 lie strictly between the endpoints, demonstrating progressive cumulative impact. This geometric trajectory substantiates the hypothesis that MSJ fundamentally alters the query representation, not merely via prompt-level pattern injection but through a direct accumulation of contextual gradients.
Theoretical Framework: Implicit Fine-Tuning via In-Context Learning
Rooted in recent work on in-context learning (ICL), the paper formalizes MSJ attacks as implicit parameter updates. Given a context C consisting of N adversarial question-answer pairs, the transformer forward pass dynamically performs rank-1 updates to the effective MLP weights as each token is processed. This in-context optimization mirrors explicit SGD fine-tuning on the identical harmful data:
Θharm=Θ0−αi=1∑N∇ΘL(M(x~i),y~i,harm)
The contextualized query activation Z∗(x;θ) can be expressed via first-order expansion:
Z∗(x;θ)=Z(x;θ)−Nηi=1∑N∇θZ(x;θ)∇θL(M(x~i),y~i,harm)+O(η2)
Thus, the representation drift induced by MSJ aligns exactly with the gradient of fine-tuning over Dharm, leading the query's representation to leave the refusal region in parameter space.
Defense Mechanism: SafeEnd—One-Shot Safety Anchor
Motivated by this insight, the paper introduces SafeEnd, which appends a fixed, universal safety demonstration N0 immediately after the target query in the adversarial context. This demonstration consists of a prototypical harmful query paired with a strong refusal. It is designed to leverage the many-to-one mapping learned during safety alignment, wherein diverse malicious queries are projected into a tightly bounded refusal subspace.
During inference, the augmented prompt N1 induces a corrective implicit gradient via the one-shot safety demonstration. The activation displacement becomes:
N2
The restorative gradient introduced by the safety anchor is sufficient to neutralize the cumulative adversarial drift, owing to the asymmetric strength of safety-aligned representations acquired in pretraining and alignment.
Experimental Results: Robustness, Utility, and Efficiency
SafeEnd demonstrates comprehensive improvement over both training-time (MTSA, MUSE) and inference-time baselines (ICD, Goal Prioritization, PPL Filter) across open-weight (Llama-3, Qwen2.5) and API-based models (GPT-4o, Gemini 2.5 Pro). Under 32-shot adversarial contexts, SafeEnd reduces ASR by up to N3, bringing it near zero for strong attacks like Crescendo and X-teaming. The defense remains robust as the shot count increases to 256, with ASR remaining below N4 for all models.

Figure 3: Defense scaling and robustness of SafeEnd against increasing adversarial shot counts.
Utility evaluation across a suite of reasoning, conversational, and long-context benchmarks confirms minimal degradation (N5 in average score) compared to baseline and less than training-time defenses. Deployment overhead is negligible—SafeEnd incurs only N6 seconds additional inference latency per prompt on Llama-3-8B-Instruct with 64-shot context, and requires no retraining or parameter access. Token budget analysis shows the safety demonstration consumes a small fraction of modern context windows, maintaining feasibility.
Positional ablation reveals that appending the safety demonstration after the target query (as opposed to start or middle) optimizes defensive impact, reducing ASR sharply to N7 for MSJ and N8 for Crescendo (see Table in the paper). Over-refusal rates on XSTest and OKTest remain nearly unchanged, demonstrating that the defense does not induce significant conservatism on benign inputs.
Implications and Future Directions
The mechanistic view of MSJ as implicit context-driven fine-tuning marks a shift from heuristic prompt defenses to gradient-level reasoning about alignment erosion. SafeEnd exemplifies how input-side interventions, grounded in forward-pass computation, can efficiently restore guardrail behavior without sacrificing model utility or incurring high computational cost. While the current schema covers explicit demonstration-based attacks, extending the context-adaptation analysis to personalized, subtle, or tool-augmented adversarial scenarios is warranted.
Further research should refine gradient-level model interpretability for complex multi-turn interactions, and explore the interplay between implicit context adaptation and explicit system prompt enforcement under evolving red-teaming strategies. Human evaluation and hybrid adversarial attacks may reveal additional nuances in safe context composition.
Conclusion
This paper establishes a rigorous theoretical and empirical foundation for understanding many-shot jailbreaking as forward-pass implicit optimization in LLMs. The SafeEnd intervention, via a fixed one-shot safety demonstration, effectively counters adversarial representation drift by leveraging asymmetric safety gradients, yielding robust, efficient defense in black-box and API settings. The work prompts a broader paradigm in adversarial alignment, shifting from surface-level prompt patching to gradient-informed context engineering.

