- The paper introduces a Bayes-assisted method that constructs anytime-valid confidence sequences for bounded means with rigorous frequentist guarantees.
- It leverages Bayesian predictive distributions to optimize test martingale log-growth, achieving asymptotic log-optimality under Wasserstein consistency.
- Empirical results show reduced sequence widths and improved sample complexity in sequential tasks, even under misspecified or diffuse priors.
Asymptotically Log-Optimal Bayes-Assisted Confidence Sequences for Bounded Means
Introduction and Theoretical Framework
The paper introduces a Bayes-assisted methodology for constructing confidence sequences (CSs) for the mean of bounded i.i.d. random variables, with rigorous, time-uniform frequentist guarantees. The proposed class of Bayes-assisted CSs leverages working Bayesian predictive distributions to guide the sequential construction of test martingale factors, producing tighter CSs in the presence of informative priors, while preserving coverage even under misspecification.
The central innovation is a separation between validity and efficiency: the anytime-validity of the CS is maintained by constructing test martingales using only the bounded-mean martingale property, with the prior or working model used solely for log-growth optimization of the betting coefficient. Theoretical results include time-uniform, nonasymptotic coverage for arbitrary working predictives, and asymptotic log-optimality relative to an oracle with knowledge of the data-generating law, contingent on Wasserstein consistency of the predictive sequence.
Methodology
Test Martingales and Confidence Sequence Construction
For each candidate mean μ, the procedure constructs a nonnegative test martingale whose one-step factors take the form 1+λi(Xi−μ) for selected λi within a range ensuring global nonnegativity. The anytime-valid CS at time n for a desired coverage level 1−α is assembled by test inversion: the CS retains all μ such that the cumulative martingale does not exceed 1/α up to that time.
A salient feature is that the sequence of coefficients λi is chosen by maximizing the expected log-growth under a working predictive distribution. Formally, at each time point and for each μ, λi solves
1+λi(Xi−μ)0
where 1+λi(Xi−μ)1 is any 1+λi(Xi−μ)2-measurable predictive, potentially informed by prior distributions.
Predictive Models
The paper presents several instantiations for 1+λi(Xi−μ)3:
- Parametric Beta Predictive: The Bayesian predictive under a Beta likelihood, which is efficient for well-specified models but not robust to distributional misspecification.
- Mixture Dirichlet Process (MDP) Predictive: A robustification that interpolates between the parametric Bayesian predictive and the empirical distribution, controlled by a weight parameter 1+λi(Xi−μ)4, ensuring predictive consistency and asymptotic optimality regardless of prior accuracy.
- Bayesian Empirical Likelihoods (BETEL/RETEL): Nonparametric constructions that place priors directly on the mean parameter of interest, bypassing full distributional specification, and guarantee optimal log-growth under minimal assumptions.
All constructions guarantee validity via Ville's inequality, regardless of the informativeness or correctness of the working predictive.
Theoretical Results
Nonasymptotic Coverage: The methodology yields CSs with exact time-uniform coverage with respect to the true mean for any choice of working predictives, including situations where the prior and likelihood are completely misspecified.
Asymptotic Log-Optimality: If the predictive sequence 1+λi(Xi−μ)5 converges to the latent data-generating law in Wasserstein-1 metric, the per-sample expected log-evidence of the test martingale matches that of the theoretically optimal oracle betting strategy.
Efficiency Loss Quantification: Finite-sample regret with respect to oracle log-evidence is shown to scale linearly with the mean Wasserstein-1 error of the predictive distribution sequence.
Empirical Results
Synthetic Experiments
A diverse set of synthetic distributions, including mixtures, non-Beta, and Bernoulli laws, probe the robustness and efficiency of Bayes-assisted CSs. Under informative priors, Bayes-assisted strategies (MDP, BETEL, RETEL) achieve a considerably reduced oracle-normalized CS width relative to empirical or uninformed baselines, with Bayes-assisted MDP performing optimally at small sample sizes and BETEL/RETEL catching up with further data. Misspecified or diffuse priors increase CS width but do not compromise coverage, empirically validating the theoretical results.
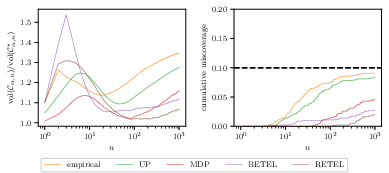
Figure 1: The MDP and empirical-likelihood-based Bayes-assisted CSs achieve near-oracle normalized width and maintain valid cumulative miscoverage 1+λi(Xi−μ)6 across repetitions in the synthetic beta-mixture experiment.
Sequential LLM Evaluation (Best-Arm Identification)
For sequential best-arm identification among LLMs using Spearman rank correlation as a bounded reward, Bayes-assisted CSs (particularly BETEL and RETEL) often reduce the average number of model queries required for 1+λi(Xi−μ)7-optimal identification compared to empirical and universal portfolio baselines. This reflects direct improvements in sample complexity by integrating prior knowledge via predictive-guided betting.
Prediction-Powered Inference (PPI)
Applications to PPI demonstrate that informative priors for the residual mean can drastically reduce CS widths, and thus, the number of labels required to reach a given inferential threshold. The Bayes-assisted CSs remain robust to predictive adequacy, and their performance gracefully interpolates between (potentially) powerful but assumption-reliant Bayesian methods and fully agnostic, minimax-valid approaches.
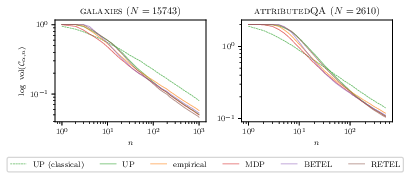
Figure 2: Bayes-assisted CSs are substantially narrower than classical labeled-only CSs and competitive across PPI tasks in mean estimation for labeled galaxies and attributedQA residuals.
Discussion, Limitations, and Future Directions
The presented methodology enacts a modular separation between inferential validity and efficiency, enabling the integration of robust, prior-informed prediction mechanisms without sacrificing frequentist guarantees. Theoretical results rigorously characterize the efficiency–validity trade-off and confirm practical gains in sample efficiency and CS tightness. Limitations include computational overhead due to grid-based test inversion, potential non-interval-valued CSs, and the critical dependence of realized efficiency on the informativeness of the working predictive.
Further research directions include (1) computational advances for exact or approximate CS computation, (2) interval-valued summarization schemes for multi-interval CSs, (3) adaptively learned hyperpriors or data-driven model selection for robust predictive specification, and (4) extension to general functionals or dependence structures.
Conclusion
The Bayes-assisted framework for test-martingale-based CSs achieves asymptotic log-optimality with nonasymptotic, time-uniform coverage for bounded mean estimation under minimal distributional assumptions. By leveraging informative priors or auxiliary predictives, these CSs can attain substantial efficiency gains in both classical and cutting-edge sequential tasks, even as they maintain robust coverage in the presence of model misspecification. The general approach provides a principled avenue to incorporate side information and prior expertise within the rigorous apparatus of anytime-valid sequential inference (2605.07964).