- The paper presents a novel algorithm that couples Euclidean and Wasserstein gradient flows to jointly optimize prompt and latent distributions in Bayesian inverse problems.
- It leverages latent consistency models to approximate prior scores, dramatically reducing neural function evaluations and computational cost.
- Empirical evaluations on deblurring and super-resolution tasks demonstrate state-of-the-art performance and robust convergence even with challenging prompt initializations.
Consistency-Regularised Gradient Flows for Fast and Accurate Bayesian Inverse Problems
Introduction and Context
The paper "Consistency Regularised Gradient Flows for Inverse Problems" (2605.07907) presents a novel algorithmic framework for image inverse problems leveraging latent consistency models (LCMs) as generative priors. The motivation originates from the increasing success of vision-language latent diffusion models (LDMs) in inverse problem solvers, yet noting substantial computational overhead and slow convergence with existing baselines. Core to current bottlenecks are the high number of neural function evaluations (NFEs) and the inefficiencies introduced by prompt and posterior sequential optimization—especially with methods like LATINO-PRO. The paper responds to these drawbacks with the introduction of a unified Euclidean-Wasserstein gradient flow, allowing simultaneous prompt optimization and posterior sampling in LCM-powered inverse imaging.
Formulation: Joint Posterior and Prompt Optimization via Wasserstein Gradient Flow
The authors formulate the inverse problem: given observation y=A(x0)+ϵ, with known forward operator A and Gaussian noise ϵ, and a generative prior pc(x0) on signals x0 parameterized by a text prompt embedding c. The data likelihood p(y∣x0) and the observation model are used to define the Bayesian posterior pc(x0∣y)∝p(y∣x0)pc(x0).
Distinctively, pc(x0) is induced by an LCM, operating in the latent space of a VAE. This prior is conditional on a learned prompt c, which is not directly known at inference and typically requires tuning. The paper departs from previous work that alternates between heuristic prompt search and posterior Gibbs sampling by proposing a coupled optimization of the joint parameter A0, where A1 is the prompt embedding and A2 is the distribution over the latent space.
The main objective functional is:
A3
This is minimized with respect to both the prompt and the latent posterior law, using the Euclidean geometry on the prompt parameters and the Wasserstein-2 geometry on the space of latent distributions.
Gradient Flow Dynamics and Algorithmic Realization
Standard gradient flows are generalized: the prompt A4 evolves under a Euclidean gradient, while the latent measure A5 evolves along the Wasserstein-2 gradient of A6. The time-continuous flow equations are discretized via a Lie-Trotter splitting, yielding a practical explicit-splitting update scheme where prompt and measure updates are sequential over each iteration.
Posterior transport is implemented using a Consistency Model A7, which implicitly approximates the PF-ODE solution and thereby the prior score, leveraging theoretical properties relating flow maps and denoising scores. The prior term in the gradient is efficiently approximated using a kernelized score-matching approach and empirical barycenter estimates over a finite particle set (see (Figure 1)).
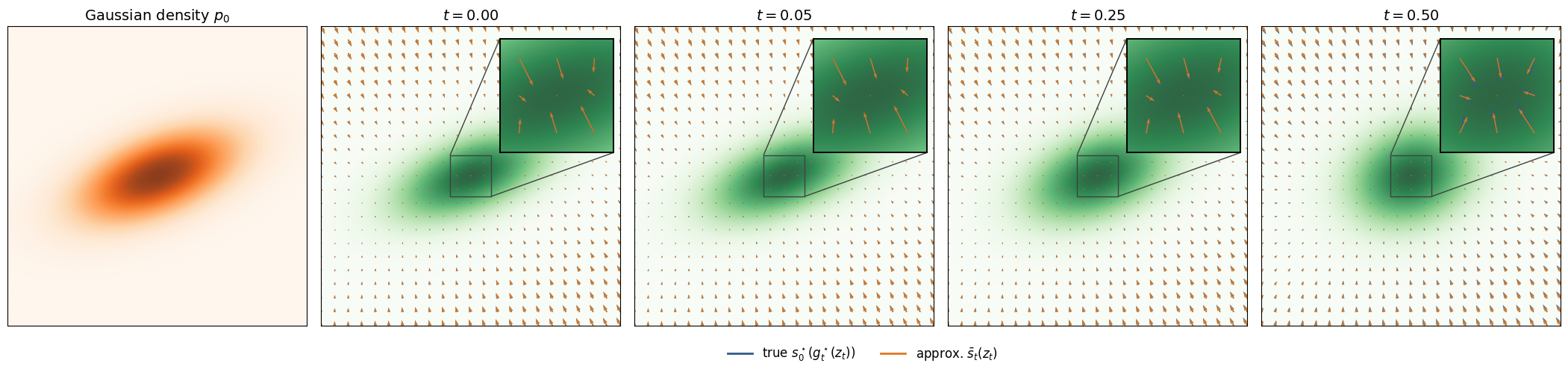
Figure 2: The kernelized CM-induced surrogate closely tracks the true prior score in the Gaussian latent regime for moderate diffusion times.
Prompt gradients are estimated via Monte Carlo over the denoising score-matching loss, with the LCM approximating the true prior score, validating use of the CM output for prompt adaptation. The likelihood gradient can be evaluated efficiently using the VAE encoder, circumventing the need for prohibitive decoder backpropagation.
Empirical Evaluation
Experiments are conducted on canonical high-resolution imaging problems (Gaussian deblurring, motion deblurring, A8 super-resolution) with pixel-level measurement noise (A9), using LCM-LoRA distilled from Stable Diffusion 1.5 as prior and tested on FFHQ-512 and ImageNet-512.
The method, Consistency-regularised Wasserstein Gradient Flow (CWGF), achieves state-of-the-art (SOTA) results with only 16 NFEs per sample, as evidenced in Table 1 and corresponding qualitative visualizations (see (Figure 3), (Figure 4), (Figure 5)):



Figure 6: Qualitative Gaussian deblurring results with CWGF on FFHQ-512, restoring fine details and textures at low computational cost.



Figure 7: Motion deblurring reconstructions obtained by CWGF demonstrate superior preservation of global and local structures relative to previous LCM-based solvers.



Figure 1: Super-resolution (ϵ0) task: CWGF generates visually accurate, semantically-meaningful high-frequency content in a fraction of the steps used by competitors.
CWGF is especially notable for robust convergence and high sample quality under adversarial prompt initialization (e.g., ImageNet prompt: "a photo of a cat"), outperforming all iterative competitors on most quantitative metrics (FID, PSNR, LPIPS). The method is insensitive to moderate hyperparameter variations and shows negligible performance degradation in unfavorable prompt conditions (see Table 2).
The method is also tested under limited-data or ambiguous inverse scenarios (MNIST box inpainting), demonstrating improved output diversity via explicit particle interactions. When ϵ1 parallel particles are sampled with explicit repulsive interaction in low-dimensional latent space, the generated posterior exhibits substantially greater solution diversity – crucial in stochastic and multimodal contexts.

Figure 9: Effect of repulsive particle interaction on posterior sample diversity in MNIST inpainting—the CWGF joint evolution (ϵ2) achieves higher diversity than independent runs.
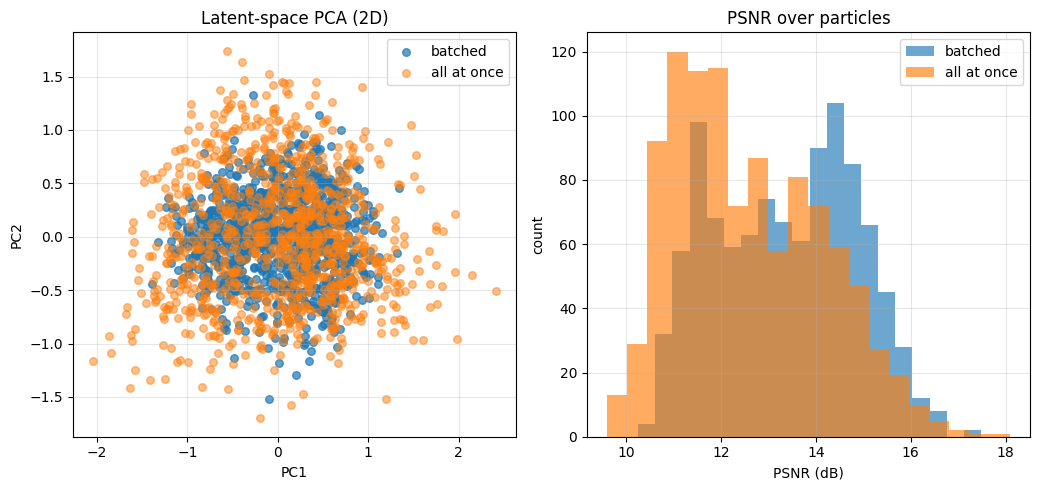
Figure 8: Latent PCA and PSNR distribution of posterior samples reinforce the diversity benefits of particle-based Wasserstein flow in low-dimensional settings.
Theoretical Implications and Limits
Theoretically, the combined Euclidean-Wasserstein gradient flow admits unique minimizers under mild log-concavity and regularity conditions, with exponential convergence to the empirical Bayes solution. The framework formally unifies MMLE-based prompt optimization and posterior sampling, obviating the need for nested Langevin or Gibbs schemes and eliminating the requirement for decoder backpropagation.
The split-step and kernelized score approximations are justified via analysis in Gaussian latent space, with error bounds demonstrating that LCM-derived scores serve as accurate surrogates near the canonical Gaussian regime of VAE-trained LDMs. This enables scalable and numerically stable latent transport, leveraging theoretical advances in Wasserstein gradient flows.
Practical Implications and Future Directions
CWGF advances practical inverse solvers by enabling: (1) low-NFE SOTA inference for a variety of image restoration problems, (2) invariant sample quality under poor prompt initializations, and (3) posterior exploration and sample diversity in lower-dimensional latent settings via explicit interaction.
These results demonstrate that coupling gradient flows in parameter and measure spaces is a highly effective strategy for Bayesian imaging problems under strong generative priors, likely impacting new developments in computational photography, medical imaging, and more generally any inverse problem leveraging deep generative models. Extension to more expressive few-step models, alternative non-Euclidean prompt geometries, and broader classes of inverse problems (such as non-linear or highly ill-posed) are anticipated directions. From a theoretical perspective, further work on the geometry of the prompt space and richer forms of interaction in the Wasserstein flows could improve diversity and uncertainty calibration.
Conclusion
The approach outlined in "Consistency Regularised Gradient Flows for Inverse Problems" (2605.07907) synthesizes prompt-conditional generative modeling and Bayesian inference, leveraging recent progress in consistency models and measure-theoretic optimization. The proposed CWGF algorithm achieves strong empirical performance on challenging imaging tasks at a fraction of the computational cost of competitor methods and sets a technical foundation for principled, scalable joint inference in LDMs with prompt conditioning.

