- The paper introduces a rigorous psychometric protocol using adapted WAIS-IV subtests to quantify generative AI model cognition via the AIQ Benchmark.
- It reveals significant disparities with models scoring at ceiling in verbal and working memory tasks while lagging in visual-perceptual reasoning.
- Longitudinal analysis shows rapid improvements in language-mediated tasks contrasted by consistent bottlenecks in non-verbal, spatial reasoning requiring architectural innovation.
Uneven Cognitive Development in Generative AI: An Analysis of the "Artificial Intelligence Quotient" Benchmark
Psychometric Framework for AI Cognition Assessment
This work introduces a rigorous psychometric protocol to quantify the evolving cognitive architecture of generative AI models, aligning evaluation paradigms with those established in human intelligence assessment. The methodology operates on two axes: adapting Wechsler Adult Intelligence Scale-Fourth Edition (WAIS-IV) subtests—considered the human gold standard in cognitive evaluation—and constructing the Artificial Intelligence Quotient (AIQ) Benchmark, a synthetic, incrementally challenging test suite that escapes ceiling/floor effects inherent to human-normed instruments.
The initial WAIS-IV adaptation enabled cross-domain comparison of leading LMMs (e.g., GPT-4o, Gemini 1.5-3.1, Claude 3.5 Sonnet/Opus) across Verbal Comprehension (VCI), Working Memory (WMI), and Perceptual Reasoning (PRI). Notably, all models exhibit a highly uneven cognitive profile, with performance distributions at ceiling in VCI and WMI (≥99\textsuperscript{th} percentile) and near floor in PRI (≤1\textsuperscript{st} percentile), with essentially no meaningful improvement in the latter except for Claude 3.5 Sonnet. This dichotomy exposes a systematic architectural bias toward language-mediated symbolic manipulation over visual-perceptual reasoning.
Architecture and Scaling of the AIQ Benchmark
In recognition of the inadequacy of human-normed tests for advanced AI, the AIQ Benchmark was designed to provide a scalable, model-normalized metric for cognitive development. Subtests span verbal, visual, and working memory domains, paralleling WAIS-IV structures while supporting algorithmic difficulty scaling (e.g., sequence lengths up to 1,600 for WM; see Figure 1), with all subtests validated via bootstrapped accuracy distributions and item response analysis to ensure the absence of ceiling/floor artifacts.
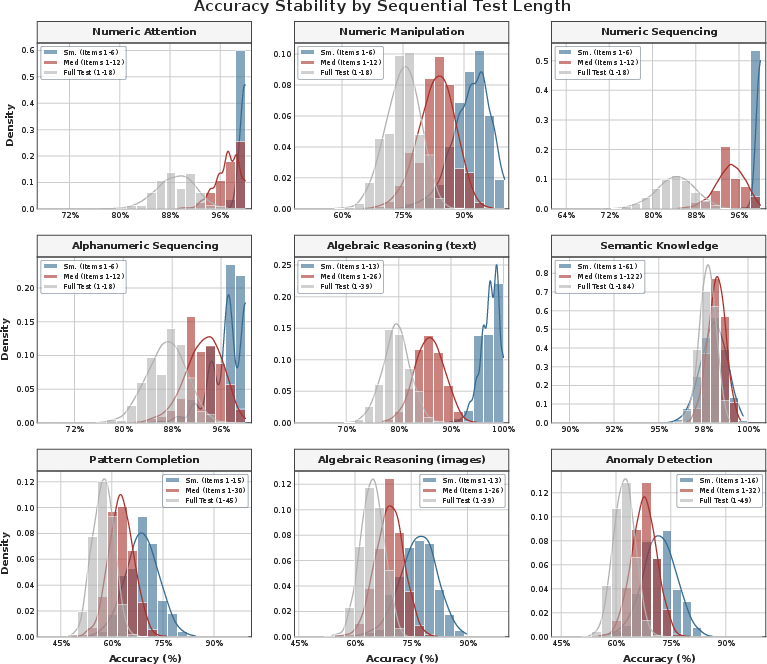
Figure 1: Impact of difficulty grading on bootstrapped accuracy distributions, demonstrating effective ceiling and variance scaling across AIQ subtests.
For verbal reasoning, even low-frequency (highly uncommon) vocabulary items failed to elicit significant variance—accuracy remained ∼99% for top models. However, the algebraic reasoning subtest (text-based), designed as an isomorphic counterpart to the visual algebraic task, allowed isolation of architectural effects.
The AIQ visual subtests employed high-complexity pattern completion (extending Raven/Gf constructs), visual algebraic reasoning (scaled up to four relations, using both integer and fractional relationships), and anomaly detection in photorealistic images, engineered to target non-symbolic compositional and organizational reasoning (see Figures 5–8).
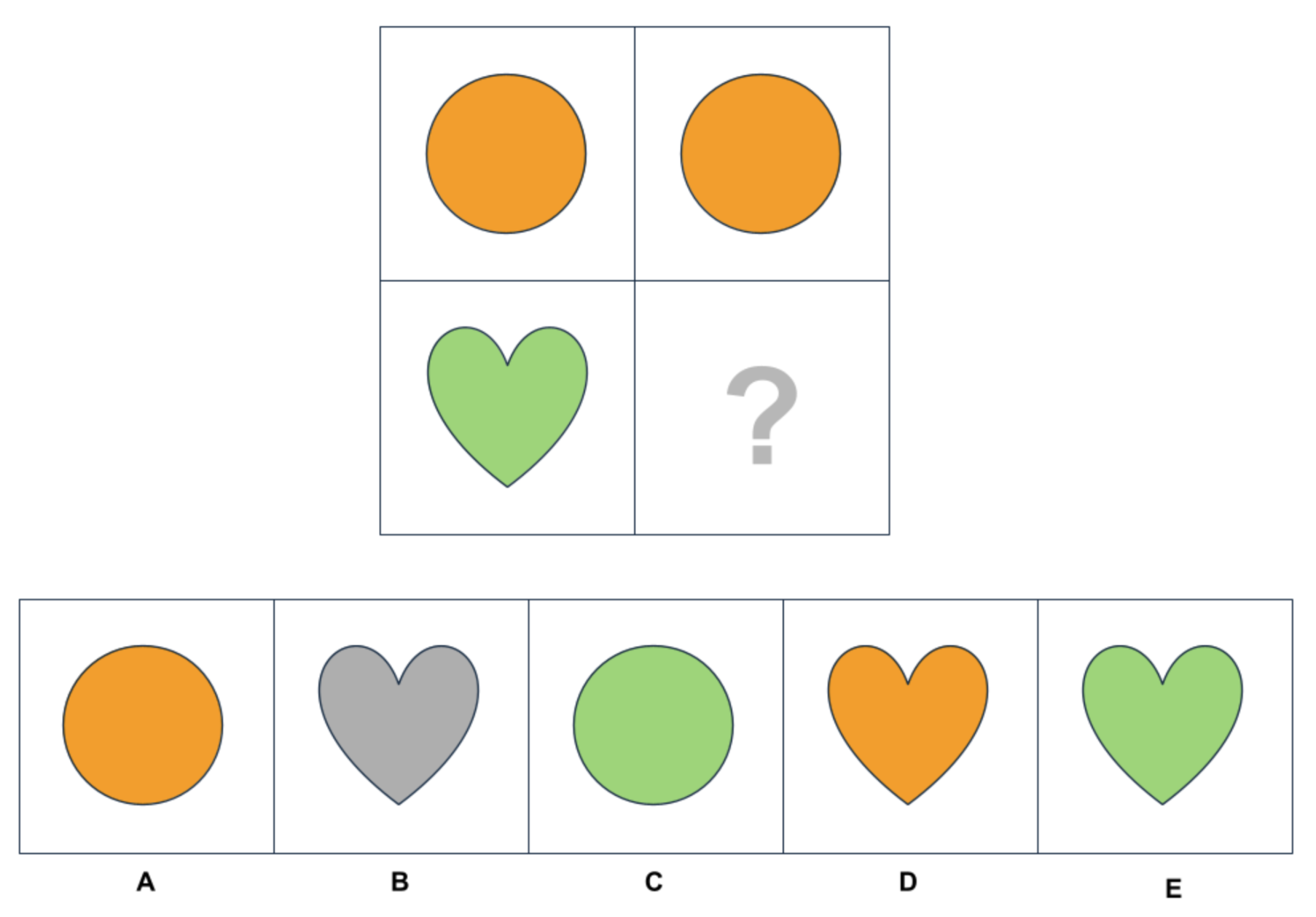
Figure 2: Example of an AIQ Pattern Completion (matrix reasoning, easy) item.

Figure 3: Example of an AIQ Pattern Completion (matrix reasoning, hard) item.
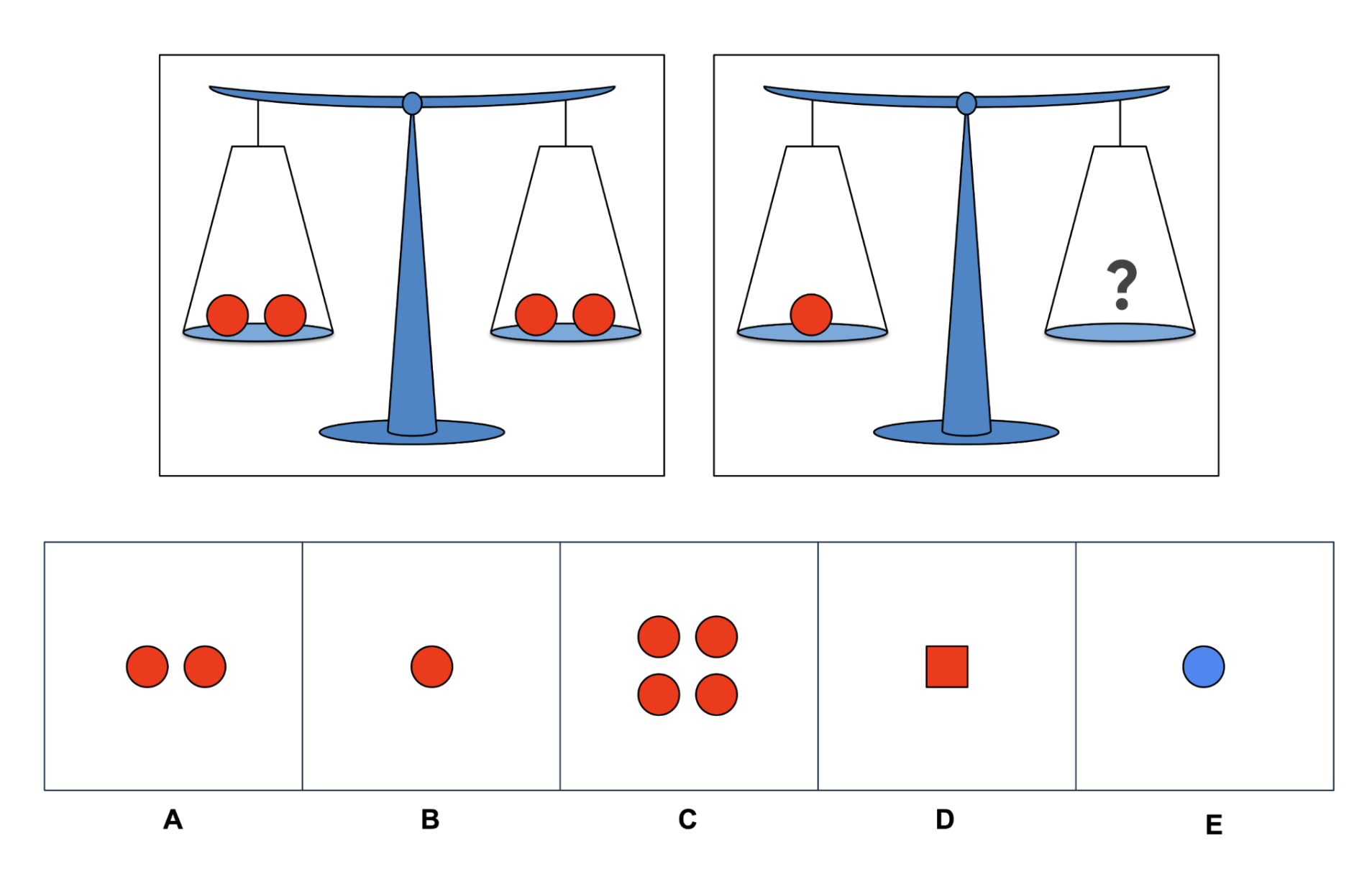
Figure 4: Example of an AIQ Algebraic Reasoning (image, easy) item.

Figure 5: Example of an AIQ Algebraic Reasoning (image, hard) item.
Longitudinal assessment using the AIQ across six Gemini and multiple OpenAI model versions revealed substantial, yet distinctly asymmetric, gains attributable to model scaling and architectural updates. Generalized linear mixed-effects modeling (GLMM) formalized these improvements, quantifying near-exponential gain in odds of correct response across generations, independent of test and item heterogeneity (see Figure 6).
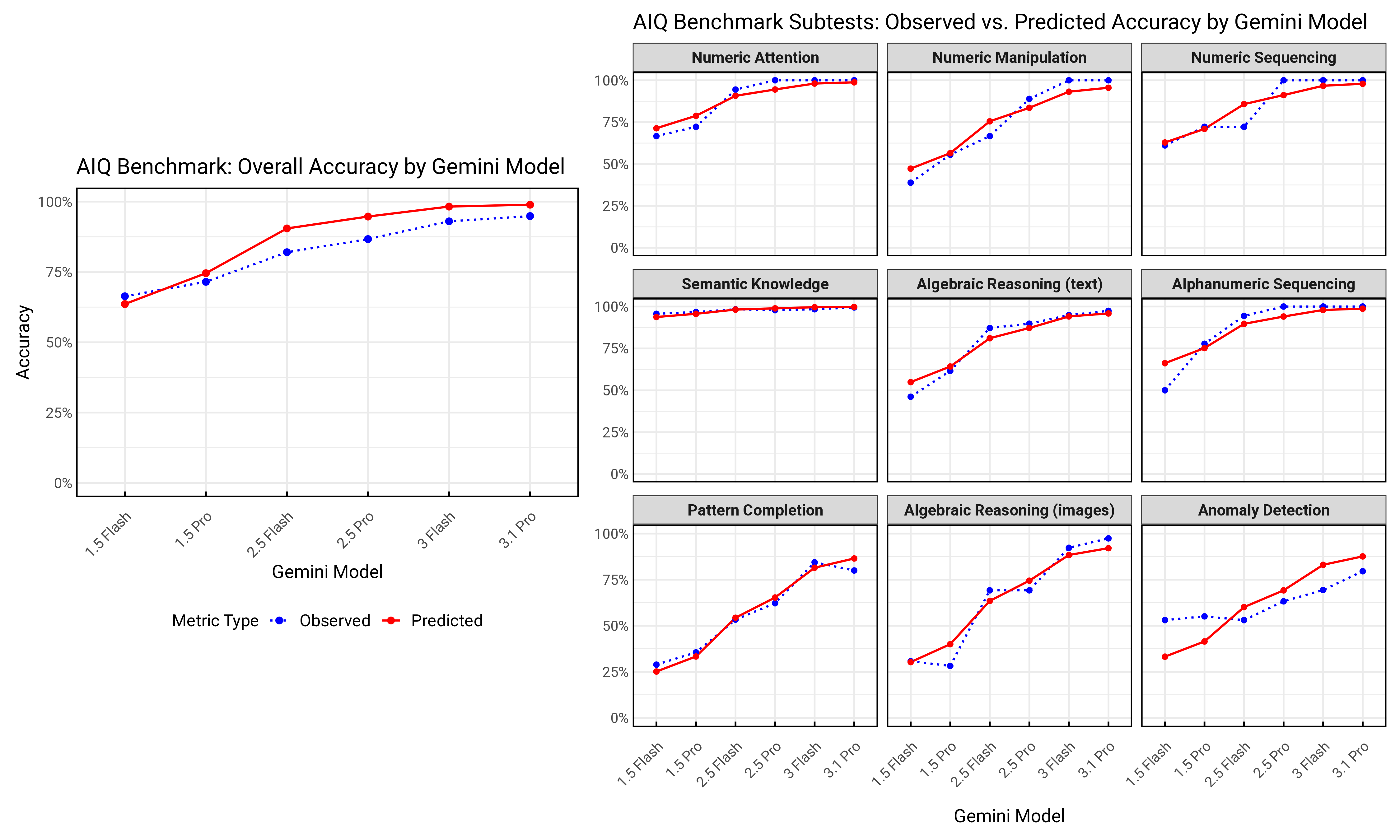
Figure 6: GLMM results for observed vs.\ predicted AIQ performance by model version and subtest, revealing cross-domain accuracy trajectories.
Notably, Gemini 3.1 Pro achieved over 50× increased odds of correct response versus its 1.5 Flash predecessor (β=3.95, OR=51.92, p≪.001). However, the improvement was not uniform: verbal AIQ subtests universally approached ceiling after 2.5 Pro, whereas visual-perceptual subtests, most notably anomaly detection and high-complexity matrix reasoning, lagged substantially in both trajectory and absolute performance (see Figure 7).
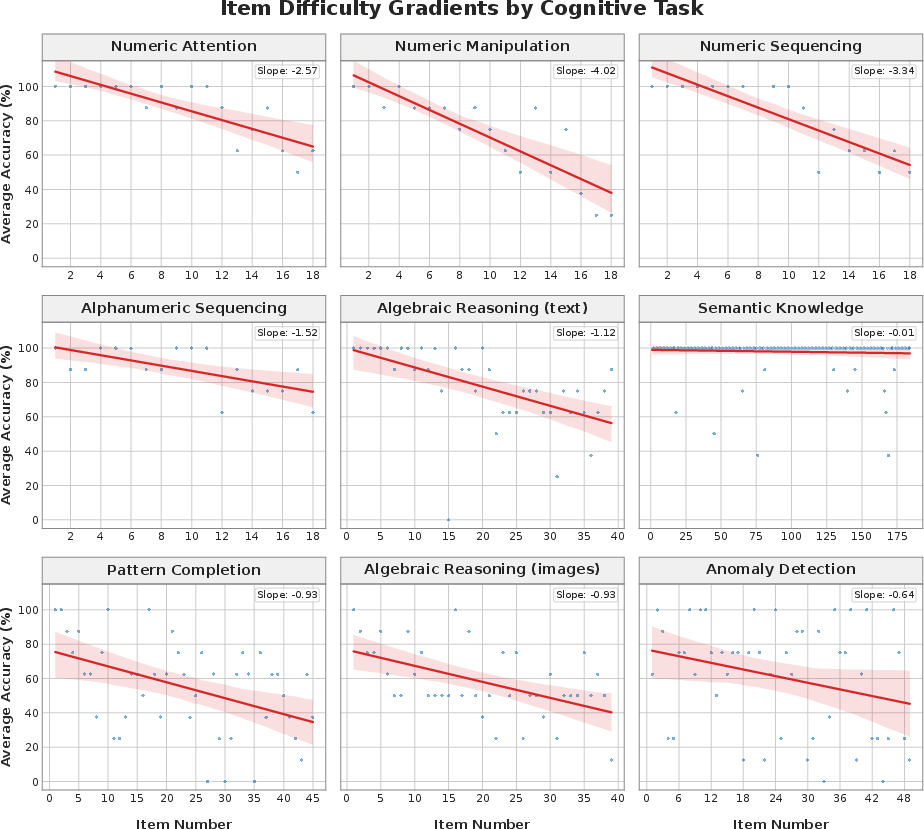
Figure 7: Slope and variance of accuracy as a function of test item difficulty, demonstrating steeper gain in verbal and memory domains than visual reasoning.
Direct verbal/visual modality comparison using isomorphic algebraic tasks revealed a sharp dissociation: models rapidly learned abstract quantitative relations in text but not in analogous image-based format, signaling an inductive bias in favor of linguistic symbolic processing pipelines over genuinely compositional, modality-independent reasoning.
Cross-family evaluation with OpenAI models yielded congruent trends: peri-ceiling scores for verbal/WM, substantially lower and slower improvements for perceptual constructs (see Figure 8).
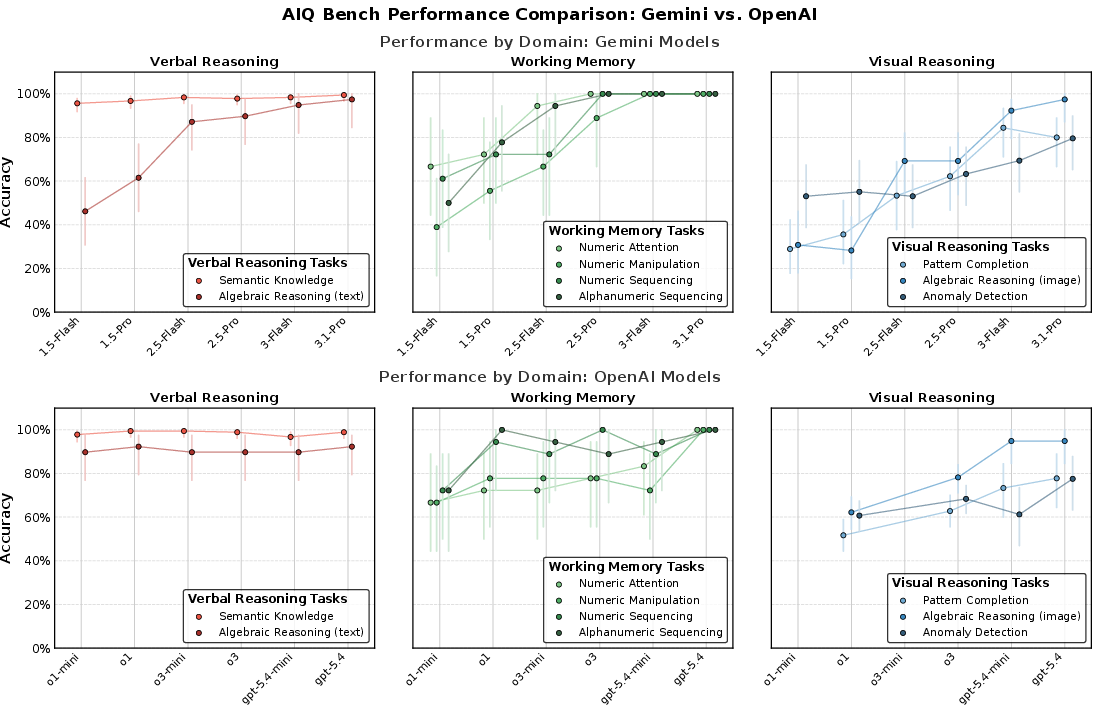
Figure 8: Gemini and OpenAI performance trends on AIQ subtests across model versions, highlighting uneven cognitive evolution and persistent modality gaps.
Implications for Model Architecture and Cognitive Benchmarking
This profound and stable architecture-induced dissociation calls into question the sufficiency of scaling and optimization-centric AGI development. Specifically, the results underscore that existing architectures—even with increased scale—do not support balanced or human-like general intelligence, instead drifting toward highly specialized, language-centric reasoning. The observed bottleneck in visual-perceptual and organizational reasoning implicates the absence of mechanisms for explicit compositionality, grounded world modeling, and the integration of spatial/common-sense priors—potentially analogous to deficits observed in systems lacking hippocampal-style cognitive map construction [whittington2022how].
Practically, this suggests that further performance improvements in non-verbal cognitive domains may require fundamental advances in pretraining corpora, data curation, and, most critically, architectural innovations targeting grounded compositional and spatial reasoning.
Additionally, as current test batteries approach ceiling in high-performing models, the need for dynamically re-normed and fully synthetic benchmarks such as AIQ becomes evident to enable continued progress tracking and to differentiate emergent cognitive capacities.
Conclusion
The presented findings constitute robust evidence that generative model cognition is advancing in a strongly uneven fashion: rapid scaling in symbolic (verbal, WM) domains, but persistent and substantial limitations in visual-perceptual and organizational reasoning. This unevenness is not merely one of training data or optimization depth, but of architecture—a limited transfer and integration of cognitive faculties across modalities. Addressing these architectural bottlenecks will be critical for progress toward domain-general intelligence.
Future research must prioritize grounded, neurobiologically inspired evaluation targets and the development of architectures with explicit compositional and world-modeling capabilities. The AIQ Benchmark provides a scalable, adaptable platform for detecting genuine advances in synthetic cognition, but benchmarking innovation must persist alongside model advances to ensure meaningful, theoretically aligned progress assessment.
Citation: "Uneven Evolution of Cognition Across Generations of Generative AI Models" (2605.06815).