- The paper introduces a geometric framework that uncovers invariant semantic zones in LLMs through subspace decomposition between semantic and nuisance directions.
- The methodology employs generalized eigenvalue analysis and projection energy computations to rigorously validate the separation of semantic-preserving and semantic-changing variations.
- The study demonstrates high model attribution accuracy (>92%) using invariant features, suggesting promising applications in model forensics and robustness evaluation.
Geometric Characterization of Semantic Invariance in LLMs
Introduction and Motivation
Understanding how LLMs achieve robustness to paraphrasing requires explicit characterization of their latent representation geometry. Prior empirical analyses have shown that deep transformer architectures encode semantic information in high-level activations, which remain stable across lexical and syntactic variation. Yet, the location, nature, and functional role of these invariant semantic representations have not been formalized or directly linked to layer-wise structure. The paper "Invariant Features in LLMs: Geometric Characterization and Model Attribution" (2605.06458) provides a rigorous geometric framework for studying semantic invariance in LLMs, positing that semantically equivalent inputs converge to compact regions in latent space and proposing subspace decomposition that separates semantic-preserving (nuisance) and semantic-changing (semantic) directions.
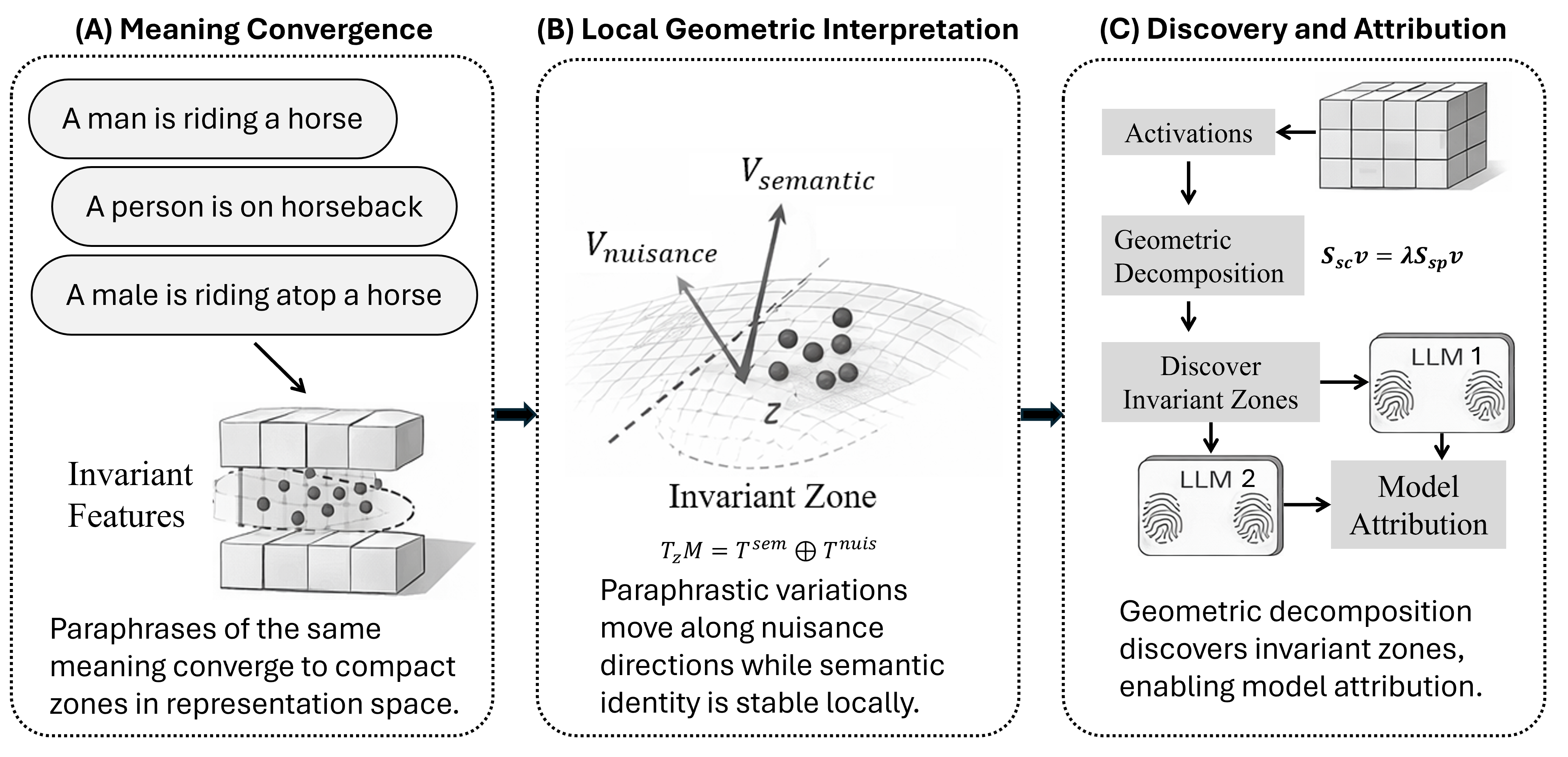
Figure 1: Emergence of invariant semantic regions in LLMs. (A) Paraphrases propagate through layers and tend to converge to compact zones. (B) Local geometric interpretation: nuisance vs semantic tangent directions. (C) Geometric decomposition detects invariant zones for model attribution.
The authors advance a formal geometric hypothesis: LLM representations map input sentences onto a manifold M⊂Rd in latent space, with local tangent-space decomposition yielding distinct semantic and nuisance directions. Paraphrasing induces variation primarily along nuisance subspaces, while semantic displacement occurs in orthogonal directions. This view is operationalized by constructing empirical covariance matrices for paraphrastic (SP) and semantic-changing (SC) perturbations and solving a regularized generalized eigenvalue problem:
Sscv=λ(Ssp+ϵI)v
The top-k eigenvectors for largest λ then define invariant semantic directions, and projection onto this basis yields the invariant latent feature zinv.
Emergence and Localization of Invariant Zones
Layer-wise analysis reveals that invariant semantic structure concentrates in specific depth regions. Generalized eigenvalue profiles show monotonically increasing invariant signal strength with depth, peaking in mid-to-late transformer layers. The invariant dimension exhibits a stable and ordered hierarchy, where the semantic abstraction is not uniformly distributed but localized in "invariant zones." This supports theoretical predictions regarding gradual abstraction in transformer architectures and aligns with prior studies of hierarchical linguistic encoding.
Tangent-Direction Validation and Subspace Causality
Direct geometric validation is performed via projection energy computations: semantic displacement vectors between group centroids are nearly orthogonal to the nuisance subspace, demonstrating that semantic-changing variation is excluded from nuisance directions (projection energy Enuis≈0.01–$0.02$ across models).
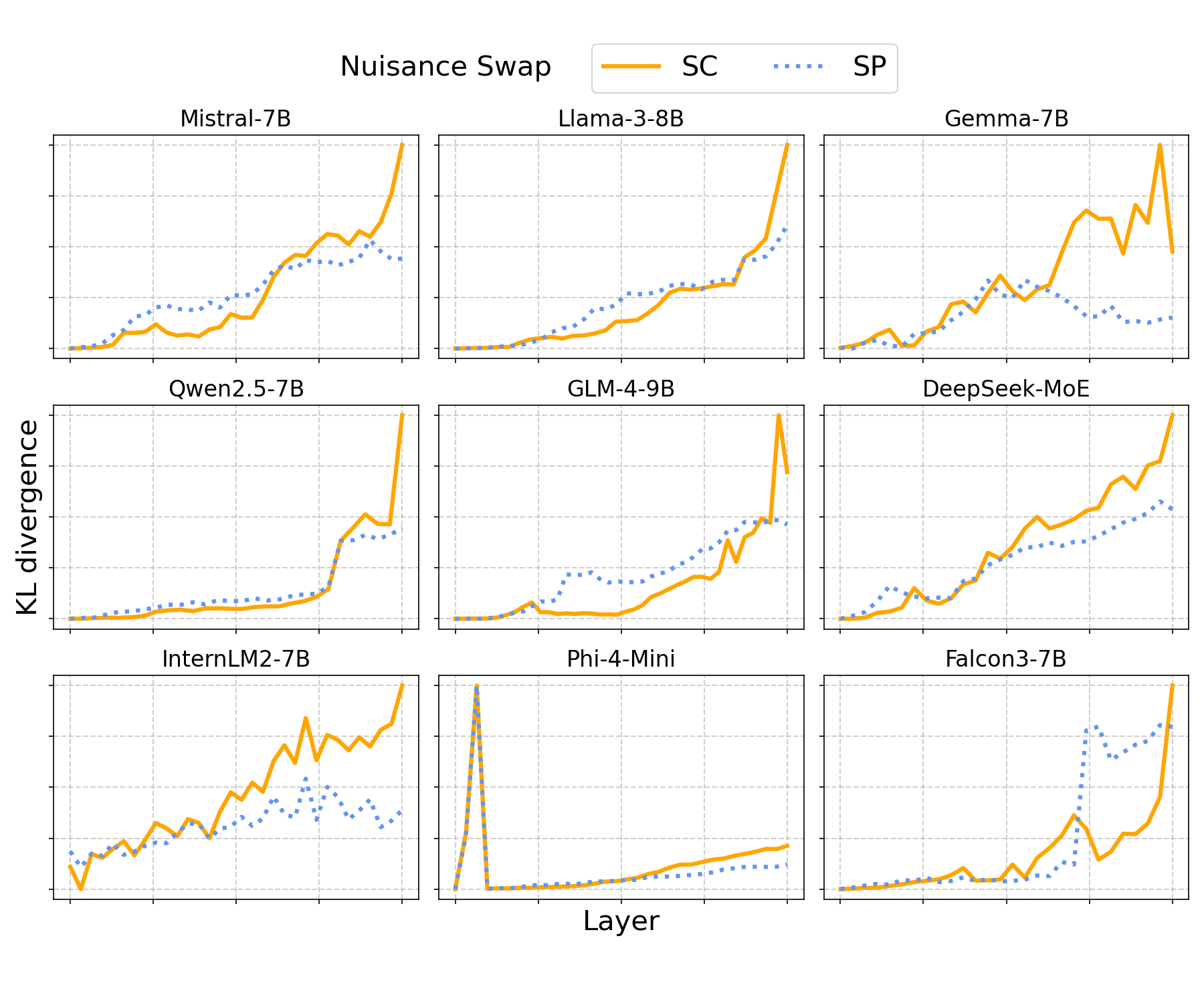
Figure 2: Per-layer KL divergence for nuisance component swaps across models, showing comparable curves for SC and SP donors and absence of semantic selectivity in the nuisance subspace.
Causal intervention experiments confirm the functional distinction: swapping invariant components between SP paraphrases produces negligible output change (KL divergence near zero), while swapping with SC or between-group donors yields large KL divergences, indicating semantic sensitivity. In contrast, nuisance swaps show weak, non-selective effects, further reinforcing the dominant semantic role of the invariant subspace.
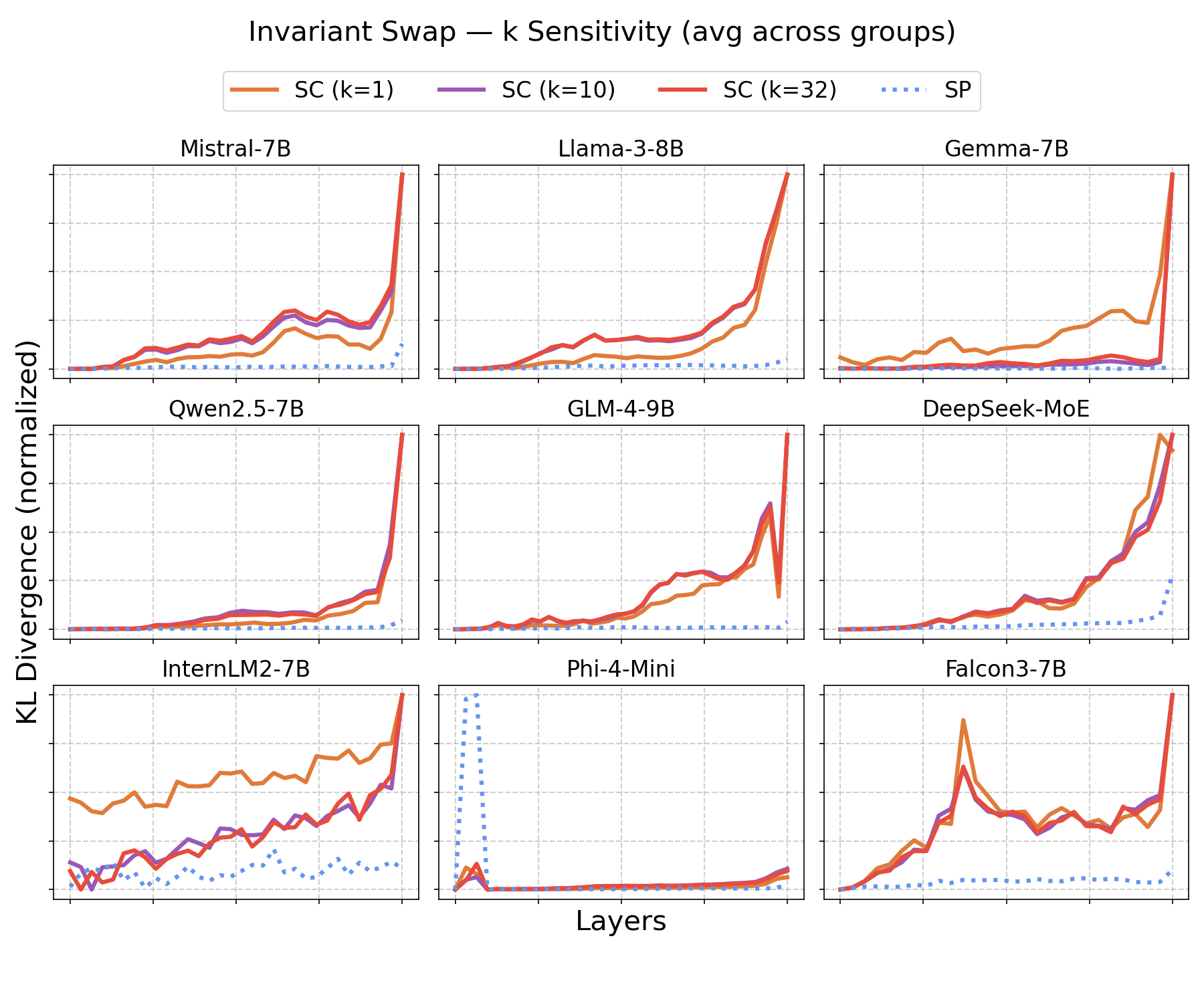
Figure 3: Per-layer KL divergence for invariant component swaps—SC curves increase consistently with depth, SP curves remain near zero, confirming selective semantic encoding in the invariant subspace.
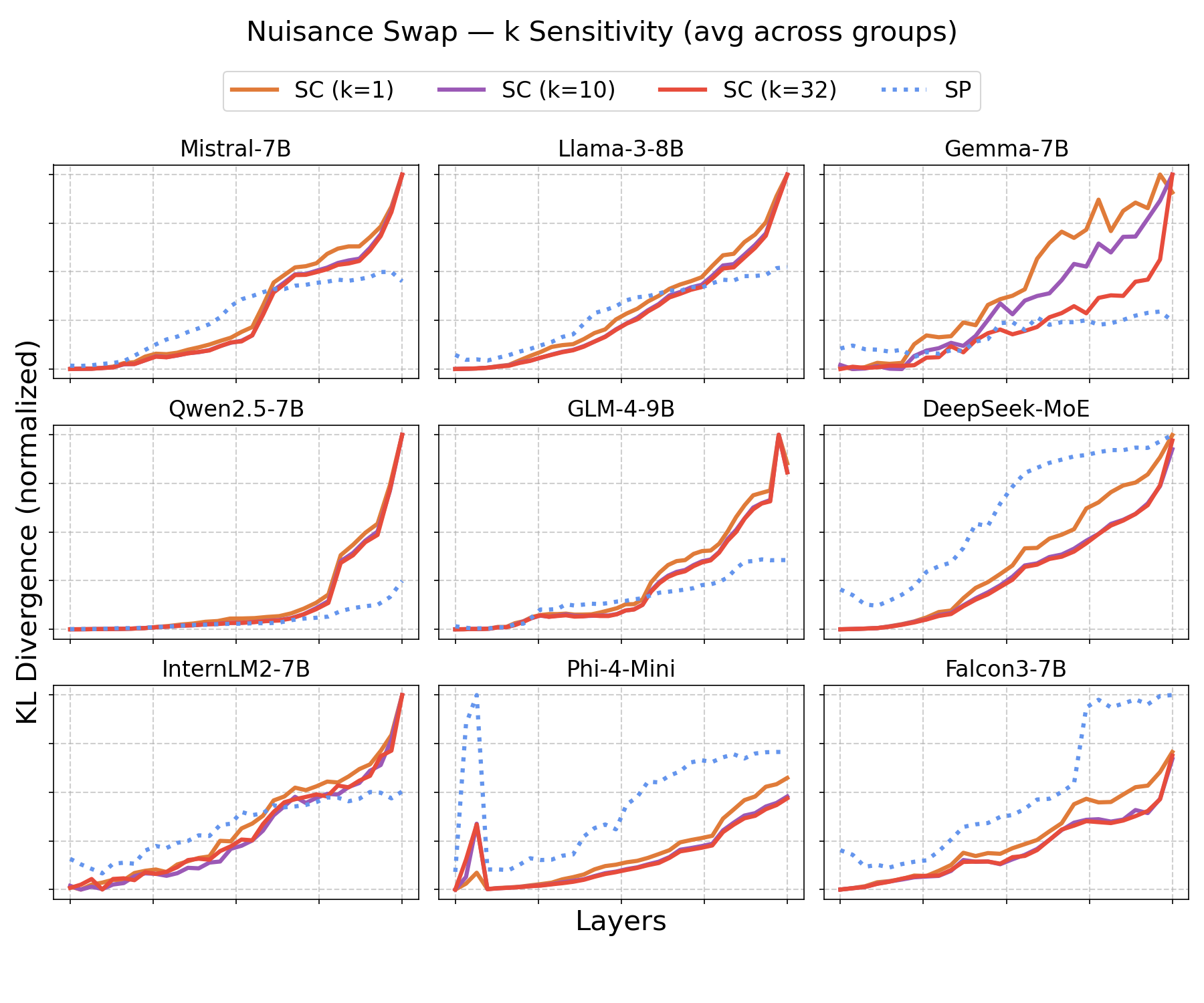
Figure 4: Per-layer KL divergence for nuisance component swaps—SC and SP curves overlap, confirming absence of semantic selectivity in the nuisance subspace.
Geometry and Model Attribution
The invariant subspace is shown to encode model-specific organization, enabling zero-shot attribution via invariant zone signatures. Attribution accuracy remains high (typically >92%) even for adapted (fine-tuned or distilled) variants, with only modest performance degradation after adaptation. This indicates that invariant geometry persists irrespective of task or parameterization changes, supporting the view that semantic invariance is a persistent latent property.
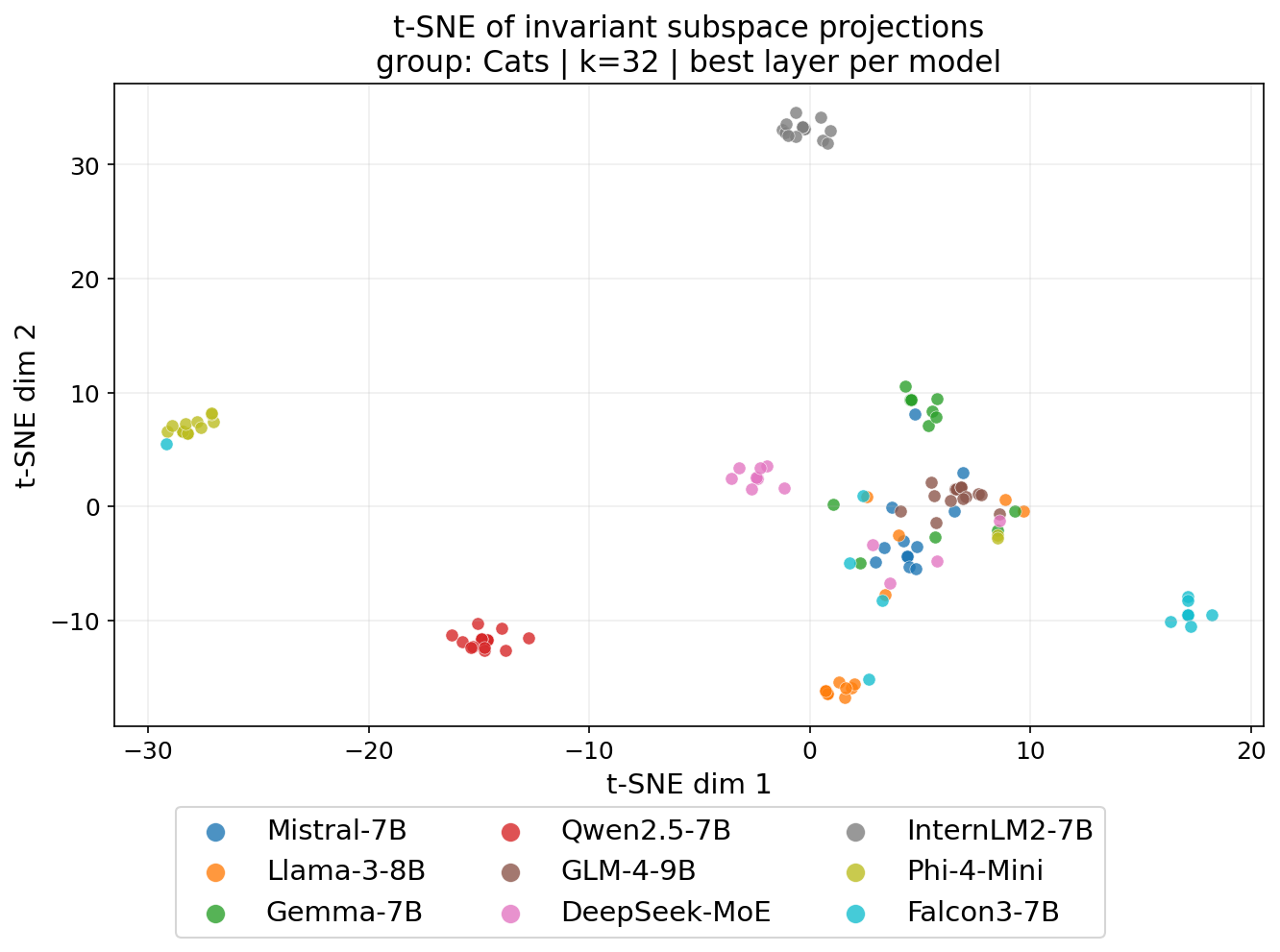
Figure 5: t-SNE visualization of invariant subspace projections for different models on one concept group. Each point is colored by model identity, showing model separability.
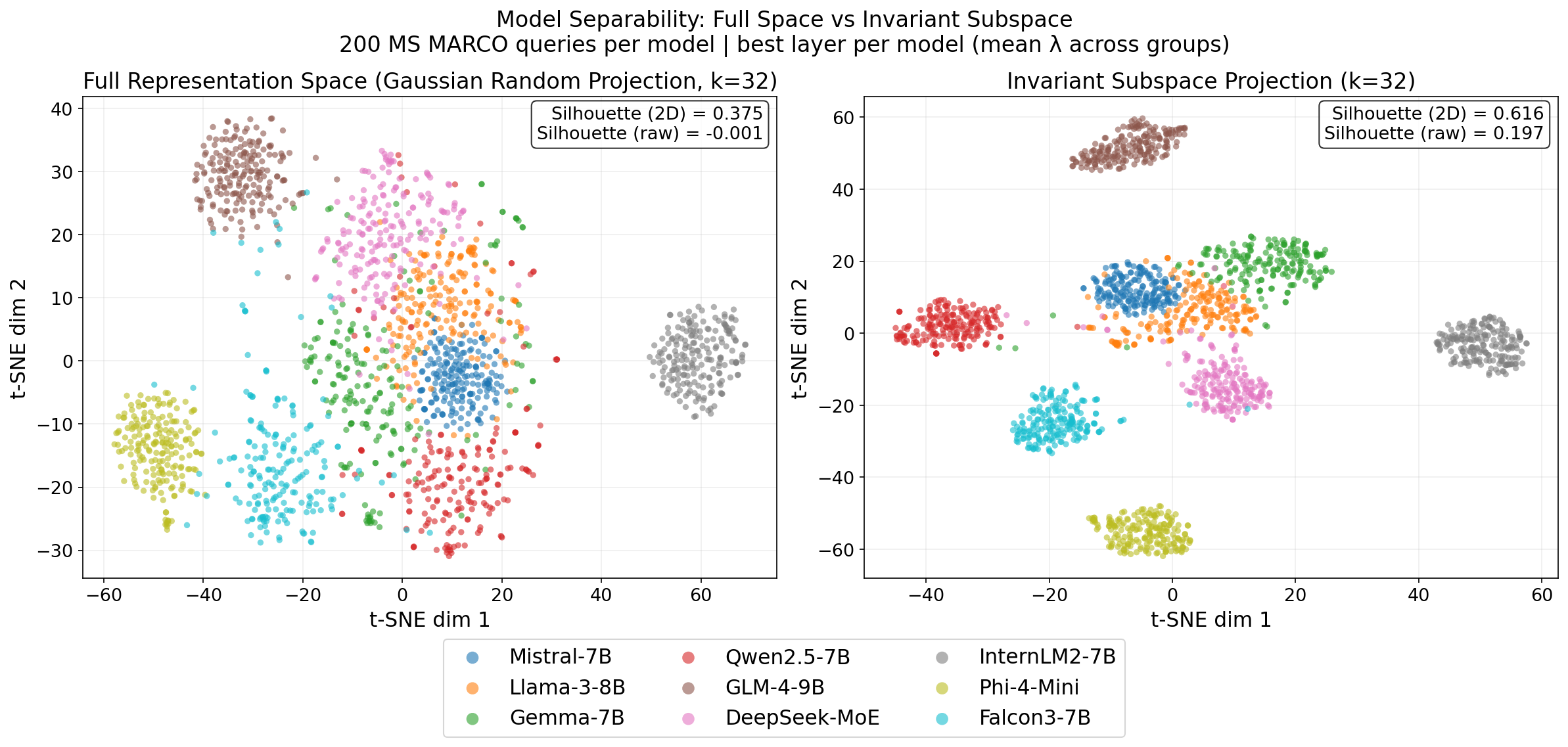
Figure 6: Side-by-side t-SNE comparison of model separability for MS MARCO queries—left: Gaussian random projection, right: invariant subspace projection with higher silhouette scores.
Limitations and Diagnostic Analysis
While the invariant zone demonstrates strong semantic selectivity and model discriminability, nuisance subspace decomposition is not perfectly orthogonal: residual semantic information persists in nuisance directions, as shown by KL divergence for nuisance swaps and overlapping SP/SC curves. The data-driven decomposition provides a dominant-direction separation rather than a pure disentanglement. This limitation is inherent to finite-sample estimates and the nonlinear structure of manifold representations.
Implications and Future Directions
The geometric characterization of semantic invariance has both theoretical and practical implications. Theoretically, it supports the manifold hypothesis for language representations and offers a principled explanation for paraphrase robustness, complementing layer-wise linguistic abstraction studies. Practically, invariant subspace signatures can be used for forensic analysis, robustness evaluation, and provenance tracking, supporting intellectual property and model accountability in generative NLP systems.
Future directions include improving disentanglement of nuisance variation, scaling the framework to larger and more diverse corpora, and investigating transferability and adaptation effects across broader model families. There is also scope for integrating the geometric approach with functional and behavioral similarity analyses, as well as further studying the dual-use implications for model fingerprinting and adversarial robustness.
Conclusion
This work establishes a rigorous geometric framework for semantic invariance in LLMs, implementing a contrastive subspace discovery method and validating it empirically and causally across diverse models. Semantic-preserving and semantic-changing variations are robustly separated, revealing structured, localized invariant zones that govern semantic abstraction and support accurate model attribution. The invariant subspace provides a stable encoding of semantic identity, while nuisance directions remain non-selective, indicating the dominant role of geometric organization in LLM internal representations.

