- The paper introduces LatentRAG, shifting multi-step reasoning and retrieval into the latent space to drastically cut inference latency by about 90%.
- The method employs a trainable projection and KL-based retrieval alignment to achieve answer accuracy within 5% of traditional agentic RAG methods.
- Optional latent decoding restores interpretability of intermediate reasoning with moderate overhead, making multi-hop QA practical for real-time applications.
LatentRAG: Latent Reasoning and Retrieval for Efficient Agentic RAG
Motivation and Background
Retrieval-augmented generation (RAG) models augment LLMs with external information retrieval to support open-domain question answering (QA) and related tasks. While single-step RAG is latency efficient, it fails to address multi-hop or compositional queries that necessitate iterative reasoning and retrieval. Agentic RAG methods, where LLMs alternate between generating thoughts, formulating subqueries, and invoking retrieval, address task complexity but suffer prohibitive latency due to sequential token-by-token generation of natural language intermediates.
LatentRAG introduces a paradigm shift by relocating both the reasoning and retrieval components of agentic RAG into the LLM's latent (continuous) space. The framework replaces intermediate natural language thoughts and subqueries with directly generated latent tokens, supports dense retrieval via these latent representations, and optionally enables transparent decoding of latents into natural language. This approach aims to combine agentic RAG's reasoning capability with the efficiency of single-step RAG.
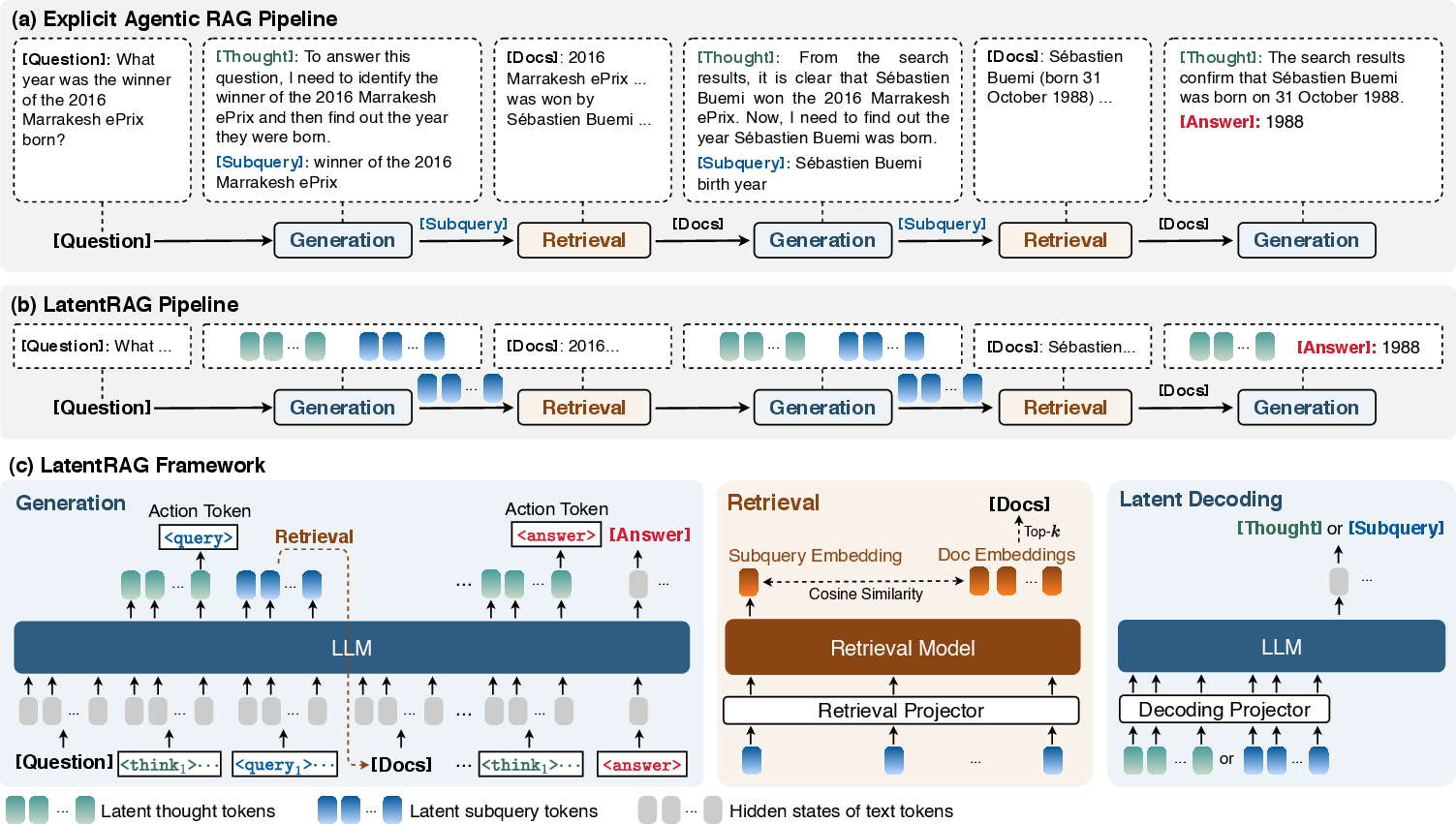
Figure 1: Top: Standard agentic RAG alternates language generation and retrieval; Center: LatentRAG emits latent thought/subquery tokens and retrieves directly in latent space; Bottom: The three modular components of LatentRAG.
Method Overview
LatentRAG operates in three stages per reasoning iteration:
- Latent Generation: The LLM ingests the current question, history, and a sequence of dedicated “thought” and “subquery” tokens. Their final-layer hidden states are extracted as latent thought and subquery tokens.
- Latent Retrieval: A trainable projection module adapts latent subquery tokens into the retrieval model’s input space. The projected latent tokens are passed to a dense retriever, executing document retrieval directly in the latent space.
- Latent Decoding (Optional): For interpretability, another set of projector modules enables decoding latent tokens back into explicit natural language thoughts and subqueries, facilitating human inspection.
All latent tokens are produced in a single LLM forward pass, eliminating autoregressive generation for intermediate outputs—an efficiency critical to overall system speedup.
Training Objective
LatentRAG is trained with a combined loss covering three objectives:
- Generation Loss: Cross-entropy over the action token indicating whether to continue retrieving or to answer; also over final answer tokens.
- Retrieval Alignment Loss: Kullback–Leibler (KL) divergence between the document retrieval distribution induced by reference (natural language) subqueries and that induced by latent subqueries. This aligns the retrieval behaviors of latent and explicit queries, compensating for the low availability of labeled subquery-document pairs in agentic RAG.
- Decoding Loss: Cross-entropy loss over reconstructing natural language thoughts and subqueries from the decoded latent tokens, enhancing both transparency and the semantic utility of the learned latent space.
Experimental Results
LatentRAG is evaluated across seven QA datasets covering both general and multihop queries. The comparison includes direct inference, single-step RAG, and a spectrum of explicit agentic RAG baselines (Search-R1, AutoRefine, DeepRAG, etc.).
Key empirical findings:
- Latency: LatentRAG achieves ~90% reduction in inference latency relative to competitive agentic methods (e.g., Search-R1, AutoRefine), virtually matching the efficiency of single-step RAG.
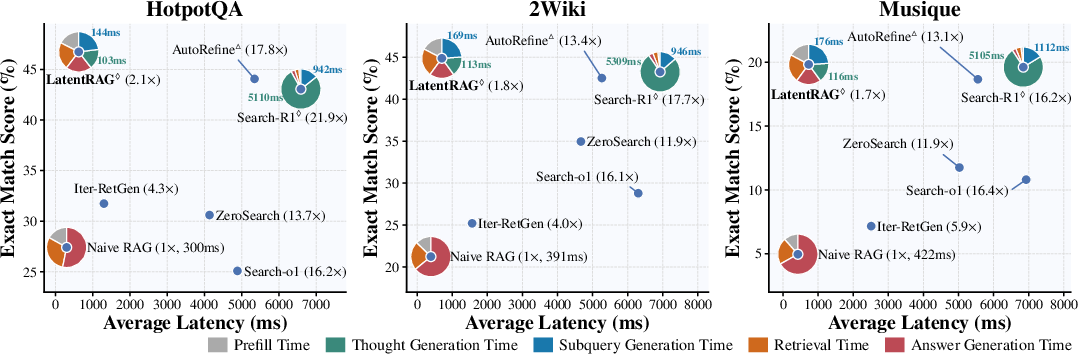
Figure 2: LatentRAG matches agentic RAG performance while reducing per-question latency to the level of naive single-step RAG; latency is dominated by intermediate thought/subquery generation in explicit methods and is nearly eliminated by LatentRAG.
- Accuracy: Across diverse retrieval models and task datasets, LatentRAG reaches answer accuracies within 5% of agentic RAG baselines, sometimes slightly exceeding them.
- Transparency: When latent decoding is applied, interpretability of intermediate reasoning steps is restored, with only a moderate increase in latency. The parallelizable nature of latent decoding maintains a substantial time advantage.
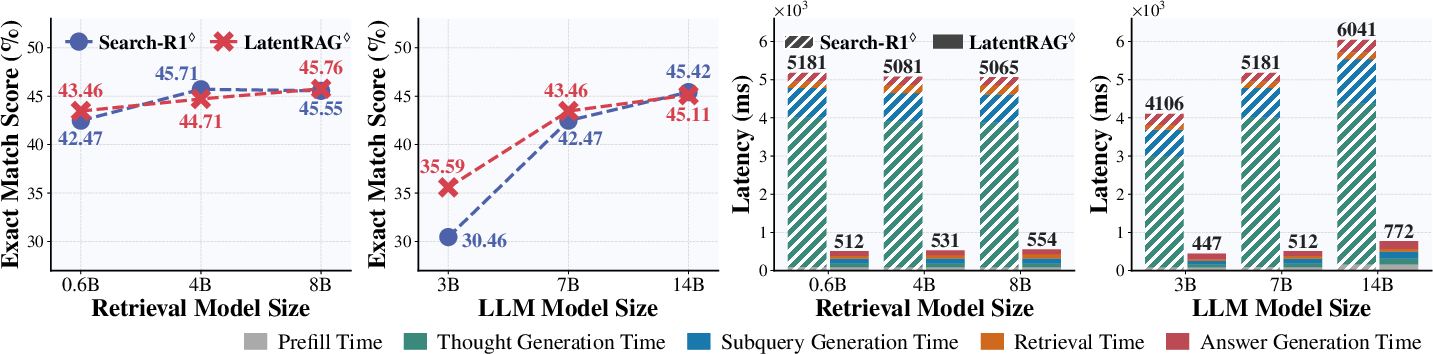
Figure 3: Performance and latency for different LLM and retriever backend sizes; LatentRAG consistently achieves strong performance at a fraction of the baseline latency.
- Embedding Model Robustness: Accuracy drops are observed when using retrieval models with severely anisotropic embedding spaces (e.g., e5-base-v2), limiting LLM adaptation to such retrievers.
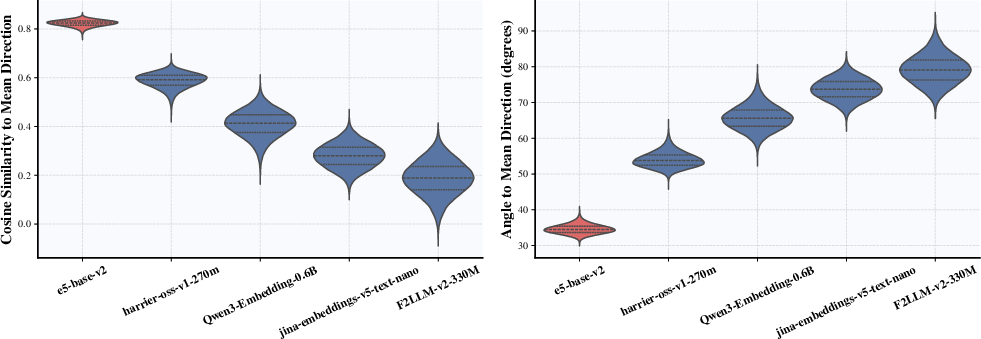
Figure 4: Violin plots show embedding anisotropy across retrievers; e5-base-v2 exhibits narrow cone collapse, impacting LatentRAG's alignment and retrieval efficacy.
Ablations and Analysis
Ablation studies highlight the importance of design choices:
- Replacing the KL-based retrieval alignment loss with cosine or InfoNCE losses degrades performance, verifying the necessity of full-distribution alignment under data scarcity.
- Omitting the latent decoding objective or the pretrained retrieval model both result in clear performance drops, underscoring the necessity for semantic latents and robust inductive biases.
- Performance improves with the quality of agentic trajectories used for SFT, and model capacity scaling experiments confirm that both larger LLMs and more powerful retrievers can be leveraged in LatentRAG without incurring significant additional latency.
Practical and Theoretical Implications
LatentRAG enables practical deployment of agentic QA systems in scenarios requiring iterative multi-hop reasoning without prohibitive latency—an obstacle for production-scale usage in, e.g., legal, medical, technical, and real-time contexts. It further raises the prospect of rethinking search architectures: if agents can natively “think” and “search” in embedding space, future information retrieval infrastructure may become more agent-oriented instead of human-text-oriented.
On the theoretical front, the framework motivates further exploration of what kinds of knowledge and reasoning procedures can be encoded, manipulated, and attributed within LLM latent spaces, especially for tasks requiring compositionality. The optional latent-to-language decoding offers new tools for interpretability and debugging of inner-model reasoning steps.
Conclusion
LatentRAG demonstrates that agentic RAG can be realized almost entirely in the continuous latent space, achieving near parity in answer accuracy with explicit multi-step methods while offering an order-of-magnitude reduction in system latency. The approach’s modular design, effective latent-space alignment, and optional transparent decoding suggest a versatile template for future agent-oriented reasoning architectures. Extensions may include reinforcement learning-based optimization, direct latent-to-latent retrieval infrastructure, and further research into the alignment and interpretability of LLM-internal representations.

Figure 5: LogitLens visualizations indicate that latent tokens produced by LatentRAG encode semantically meaningful and conceptually coherent information at each reasoning step.

Figure 6: Additional LogitLens analysis confirms the alignment of latent tokens with evolving reasoning subgoals across multihop tasks.

