X-Voice: Enabling Everyone to Speak 30 Languages via Zero-Shot Cross-Lingual Voice Cloning
Abstract: In this paper, we present X-Voice, a 0.4B multilingual zero-shot voice cloning model that clones arbitrary voices and enables everyone to speak 30 languages. X-Voice is trained on a 420K-hour multilingual corpus using the International Phonetic Alphabet (IPA) as a unified representation. To eliminate the reliance on prompt text without complex preprocessing like forced alignment, we design a two-stage training paradigm. In Stage 1, we establish X-Voice${\text{s1}}$ through standard conditional flow-matching training and use it to synthesize 10K hours of speaker-consistent segments as audio prompts. In Stage 2, we fine-tune on these audio pairs with prompt text masked to derive X-Voice${\text{s2}}$, which enables zero-shot voice cloning without requiring transcripts of audio prompts. Architecturally, we extend F5-TTS by implementing a dual-level injection of language identifiers and decoupling and scheduling of Classifier-Free Guidance to facilitate multilingual speech synthesis. Subjective and objective evaluation results demonstrate that X-Voice outperforms existing flow-matching based multilingual systems like LEMAS-TTS and achieves zero-shot cross-lingual cloning capabilities comparable to billion-scale models such as Qwen3-TTS. To facilitate research transparency and community advancement, we open-source all related resources.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces X-Voice, a computer system that can copy a person’s voice from a short audio clip and make that voice speak sentences in 30 different languages—even languages the person never spoke in the recording. The system aims to be fast, high‑quality, and usable without needing a typed transcript of the example audio.
What questions are the researchers trying to answer?
- Can we build a single, efficient system that can “clone” any person’s voice and make it speak in 30 languages?
- Can we do this without needing the text of the example voice clip (so people don’t have to provide a transcript)?
- How can we reduce “accent leakage,” where the accent from the original voice recording spills into a different target language?
- Can we make this work quickly and reliably, not just for popular languages but also for less common ones?
How does X-Voice work? (Explained simply)
Think of X-Voice as a “voice photocopier” plus a “language switcher.”
- “Voice cloning” means copying how someone sounds—their tone, pitch, and style—using a short audio clip.
- “Cross-lingual” means you can then make that voice speak in other languages.
- “Zero-shot” means the system doesn’t need extra training for each new person; it can clone a new voice on the spot.
To make this work well, the team combines a few ideas:
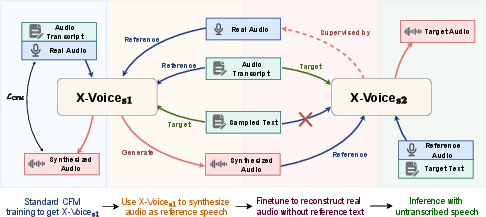
1) A two-stage training process
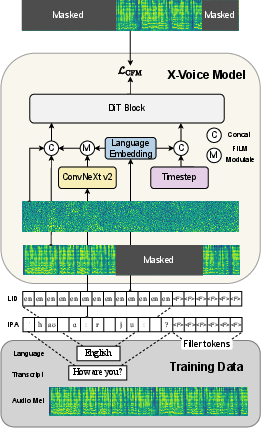
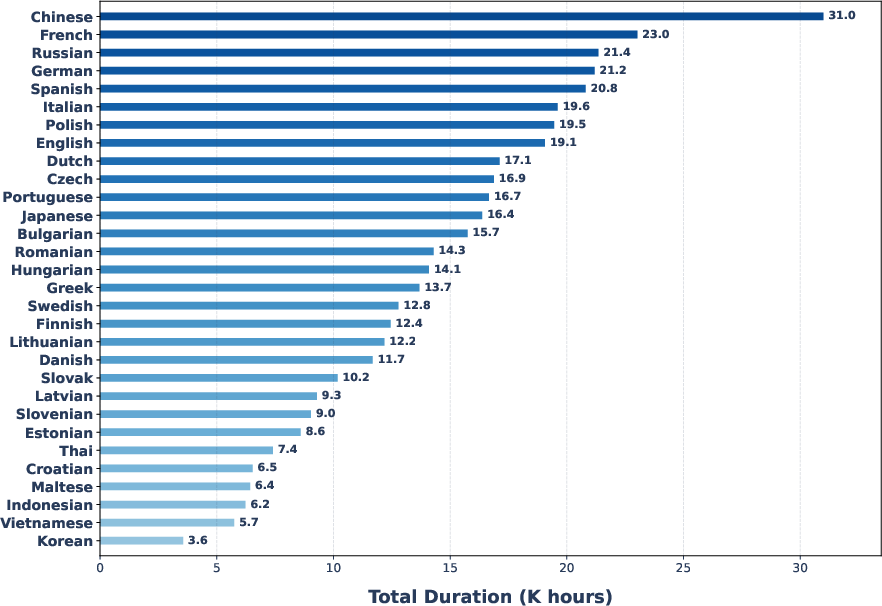
- Stage 1: Build a strong multilingual “base brain.” The model learns from a huge collection of speech (about 420,000 hours) across 30 languages. This helps it understand the sounds and rhythms of many languages and how voices vary.
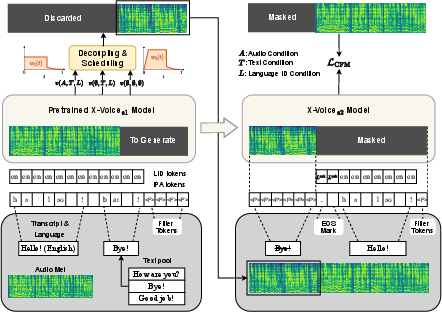
- Stage 2: Fine-tune so it no longer needs a transcript for the example audio. The team uses the Stage‑1 model to create pairs of “synthetic prompts” and real speech. Then they train the model to rely on the audio prompt itself (what the speaker sounds like) instead of needing the prompt’s text. This unlocks transcript‑free voice cloning: you can give just an audio sample of someone and the model can speak new text in another language in that voice.
Analogy: First teach a musician to play many styles (Stage 1). Then train them to copy someone’s voice by listening, even if they don’t see the sheet music (Stage 2).
2) A universal “sound alphabet”
- The system uses IPA (International Phonetic Alphabet) as a universal way to represent how words sound, across many languages. For Mandarin Chinese, they use Pinyin (a standard way to write Chinese sounds). For most other languages, they convert text to IPA. This gives the model a single, consistent way to read pronunciations, like giving it one master alphabet for all languages.
3) Keeping accents under control (so languages sound right)
- The model adds a “language tag” in two places:
- In the timing of how it generates speech (time-level)
- In the text sounds it reads (text-level)
- This “dual-level language injection” helps the model produce clear, correct pronunciations in the target language and reduces leftover accent from the speaker’s original language.
Analogy: It’s like setting your GPS language both on the screen and the voice directions, so everything stays consistent.
4) Balancing text accuracy and voice similarity
- During speech generation, there are two “knobs”:
- One knob helps the model follow the text exactly (so words are pronounced correctly).
- The other knob helps it keep the speaker’s unique voice and style.
- X-Voice “decouples” these knobs and schedules them over time. Early on, it leans more on the voice to anchor the sound; then it gradually increases the text guidance. This helps the speech be both understandable and natural, without sounding robotic or losing the speaker’s identity.
5) Fast generation
- The model uses a “non‑autoregressive” method (think: generating many parts in parallel rather than one step at a time). That makes it faster than many systems that speak “token by token.”
What did they find?
- Strong multilingual performance: X-Voice works across 30 languages and often beats other open models (like LEMAS-TTS) in how accurately it pronounces words (lower Word Error Rate).
- Competitive with bigger models: Even though X-Voice is smaller than some giant systems (like Qwen3-TTS), it performs similarly on several languages and tasks.
- Faster than many popular systems: Because it generates speech in parallel, it runs faster, making it more practical for real-time use.
- Better accent control: The dual-level language tagging reduces “accent leakage,” so English spoken by a cloned voice doesn’t sound, for example, unintentionally Russian or Japanese.
- Works without prompt transcripts: After the second training stage, X-Voice can clone a voice using just an audio snippet—no typed text is needed for that example. Tests show intelligibility often stays the same or even improves slightly, though speaker similarity can drop a bit because the model leans toward more standard pronunciations.
- Good for less common languages: On many lower‑resource European languages, X‑Voice gets especially strong scores in listening tests, which is a big deal since those languages often have less data.
Why does this matter?
- Easier for users: You can clone a voice and make it speak 30 languages without having to write out what the person said in the example audio. That’s simpler and more practical, especially for spontaneous recordings.
- Faster, more scalable speech tools: The speed and multilingual support make it useful for dubbing videos, language learning, accessibility tools (like screen readers), and global apps.
- Helps research and fairness: The team releases their large training set and a carefully built test set for 30 languages. This helps other researchers compare systems fairly and build better multilingual voice tech.
- Ethical considerations: Voice cloning is powerful, so it should be used responsibly—with the speaker’s consent and protections against misuse. The research’s open approach can also support building safeguards.
In short: X-Voice is like a smart, fast voice “photocopier” that can speak many languages, doesn’t need a typed transcript of your example audio, and keeps accents under control. It’s a step toward making high‑quality, multilingual voice technology accessible to everyone.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper advances multilingual zero-shot TTS, but several gaps and open questions remain for future work:
- Transcript-free cloning relies on synthetic prompts generated by the model itself in Stage 2, leaving robustness to real, noisy, or far-field human prompts untested; evaluate across SNRs, reverberation, channel bandwidths, and prompt accents.
- No analysis of minimal and optimal prompt duration for reliable voice cloning; quantify similarity/intelligibility as a function of prompt length and content.
- Dependence on language-specific G2P/IPA pipelines (eSpeak-NG, PyOpenJTalk, g2pK, PyThaiNLP) is unexamined; measure per-language G2P error rates and their impact on WER/IMOS, and compare to grapheme- or byte-based inputs.
- Mandarin is represented with Pinyin (not IPA); the trade-offs (e.g., tone modeling fidelity, cross-lingual alignment) versus IPA with tone diacritics are not evaluated.
- Dual-level LID injection assumes correct, single-language LID; robustness to incorrect/misaligned LID, dialectal variation, and per-token LID for code-switching is untested.
- Code-switching within utterances is not evaluated; extend the conditioning to token-level LID and assess mixed-lingual synthesis quality.
- Accent leakage is discussed qualitatively and via WER, but no explicit accent/purity metric is provided; develop and report metrics (e.g., accent classifiers, phoneme error rates) to quantify accent transfer and phonetic deviations.
- CFG decoupling and Asymmetric Warmup hyperparameters are not systematically ablated; explore schedules, warmup/decay lengths, and language-dependent settings and report quality–speed–stability trade-offs.
- Speaking Rate Predictor is introduced with minimal detail and no accuracy evaluation; quantify prediction error per language and ablate its effect on intelligibility and rhythm.
- Speaker similarity lags behind larger AR models in many languages; analyze root causes (architecture, data balance, CFG choices, embedding biases) and test alternatives (e.g., improved speaker conditioning, adversarial disentanglement).
- Evaluation relies on ASR (Whisper/Paraformer) and speaker-embedding models (WavLM) that may be biased toward high-resource languages; include human transcriptions and language-calibrated ASR to avoid measurement bias, especially for low-resource languages (e.g., Maltese).
- Objective prosody metrics (e.g., F0 RMSE, duration/rhythm errors, energy contours) are absent; complement IMOS/SMOS with prosody-focused measures.
- Generalization beyond the 30 languages (notably few/no African, South Asian, or indigenous languages) is unknown; assess typologically diverse languages (clicks, complex tones, long consonant clusters).
- Data balance, demographics, and recording conditions are not reported; analyze per-language hours, gender/age/region distributions, and study fairness and performance disparities across demographic subgroups.
- Dataset licensing and consent are not detailed; clarify legal status and usage rights for the 420K-hour corpus and benchmark, especially for commercial deployment.
- Robustness to text normalization edge cases (numbers, dates, currencies, acronyms, mixed scripts) is not stress-tested; evaluate normalization failures and cross-lingual homograph handling.
- Long-form synthesis (>30 s) and paragraph-level prosodic coherence are not evaluated; test stability over minutes-long content and consistency across sentences.
- Expressive/emotional style control and explicit controllability (e.g., emotion, global pitch/pace, speaking style) are not supported beyond CFG; investigate control tokens or style embeddings.
- Out-of-domain prompts (whispered speech, singing, laughter, pathological speech) are untested; measure cloning performance and failure modes under atypical vocal conditions.
- The Stage-2 SFT uses model-generated audio prompts, which may induce self-reinforcement/data-feedback loops; compare against SFT with real human prompts and quantify any distribution-shift or overfitting effects.
- No analysis of catastrophic forgetting from SFT on synthetic prompts; report pre/post-SFT performance across languages and prompt types.
- Incremental language addition is not addressed; propose and evaluate adapter/LoRA-style methods for adding new languages with limited data, including OOV phoneme handling.
- Sensitivity to target LID mis-specification and to mismatched prompt–target language pairs beyond tested pairs is not systematically assessed; broaden cross-lingual pair coverage and include adversarial LID settings.
- Alignment learning without forced alignment is assumed but not analyzed; investigate learned alignment quality (e.g., cross-attention plausibility) and failure cases.
- Speed/quality trade-offs are only reported for 16-NFE Euler on an RTX 4090; provide latency breakdowns, NFE–quality curves, memory footprints, and CPU/mobile performance.
- Energy/computational footprint and training compute (GPU-hours, carbon) are not reported; document resource requirements and explore parameter/NFE scaling laws.
- Comparison to transcript-free baselines that use explicit speaker encoders is missing; implement matched baselines and quantify trade-offs in similarity, intelligibility, and compute.
- Per-language correlation between training hours and performance is not provided; analyze data-efficiency and identify diminishing returns to guide future curation.
- Phonetic suprasegmental modeling (length marks, aspiration, tones) is motivated but not ablated; quantify their contribution, especially for tonal languages (e.g., tone error rates in Vietnamese/Thai/Chinese).
- Handling of OOV words/names and rare phoneme sequences is not studied; evaluate robustness on rare names, loanwords, and neologisms per language.
- Speaker privacy and misuse risks (voice cloning safeguards, watermarking, consent verification) are not discussed; outline and test abuse mitigation mechanisms.
- Potential training/eval contamination across public datasets and baselines is not examined; ensure and report de-duplication across corpora to guarantee fair comparisons.
- Mixed prompt conditions (very short prompts, mismatched genders/ages, prosody conflicts) are not explored; systematically test prompt–target mismatch scenarios and their effects.
Practical Applications
Immediate Applications
Below are concrete applications that can be deployed now, leveraging X-Voice’s transcript-free, zero-shot cross-lingual cloning, unified IPA representation, dual-level language conditioning, decoupled/scheduled CFG, and open-source datasets/benchmarks.
- Media localization and dubbing (media/entertainment) — Rapidly dub videos, films, and series into 30 languages while preserving a creator’s or actor’s timbre, without needing reference transcripts for the prompt audio. Products/workflows: “Batch Dubbing Studio” that ingests target scripts, applies dual-level LID to reduce accent leakage, and exposes CFG knobs for quality/similarity trade-offs; automated QC using ASR WER + ECAPA/WavLM speaker-sim checks; integration into Adobe Premiere/DaVinci via an X-Voice SDK/API. Assumptions/Dependencies: Rights and explicit consent for voice cloning; target-language scripts; high-quality vocoder in the pipeline; sufficient GPU; g2p/IPA quality for the chosen language.
- Creator economy: multilingual podcasting and video (media/creator platforms) — One-take multilingual releases in the host’s voice; generate 30-language versions of episodes/shorts from a short voice prompt and typed scripts. Tools: hosting-platform plug‑ins, speaking-rate matching via the provided rate predictor, and per-language CFG presets to balance intelligibility vs. timbre. Assumptions/Dependencies: Clean prompt audio; platform moderation and consent capture; per-language text editing.
- Customer support IVR/chatbots (software, telecom, finance, retail) — Low-latency NAR synthesis for consistent brand voices across locales (same “agent” voice worldwide), including dynamic content. Tools: “VoiceKit” microservice exposing LID and CFG controls; A/B profiles per locale to suppress accent leakage; autoscaling for call volumes. Assumptions/Dependencies: Telephone-band vocoder and noise-robust output; regulatory compliance and disclosure; guardrails to prevent misuse.
- Accessibility and assistive communication (healthcare, daily life) — Personalized voices for people with speech impairments; multilingual reading aids that read any text in the user’s own timbre; minimal prompt audio suffices. Products: “Personal Voice Wizard” to capture consent and a short sample; browser/e‑reader TTS plug‑ins with language auto‑switch via LID. Assumptions/Dependencies: Ethical consent management; private/on-device or HIPAA/GDPR‑compliant hosting; high-quality prompt capture.
- Language learning content generation (education) — Produce exercises, dialogs, and graded‑speed audio in target languages; keep the same instructor voice across languages. Tools: curriculum generators that use IPA tokens; CFG presets for clarity; speaking-rate predictor for level-appropriate pacing. Assumptions/Dependencies: Accurate IPA/g2p for the curriculum’s languages; expert review of pedagogical content; proper labeling of synthetic audio.
- In‑game and interactive media TTS (gaming/software) — NPCs and characters speak multiple languages with a consistent voice; low-latency NAR suits interactive scenes. Tools: Unity/Unreal/Wwise plug‑ins wrapping X‑Voice; per‑scene CFG profiles; batch asset generation for localization. Assumptions/Dependencies: Real‑time or near‑real‑time vocoder; memory footprint constraints; IP clearance for any cloned voices.
- Robotics and smart devices (robotics/IoT) — Multilingual responses in a single device voice for global deployments; fast NAR inference minimizes latency. Products: cloud API for constrained devices or an optimized edge build; “locale profiles” using dual-level LID for accent purity. Assumptions/Dependencies: Network reliability or edge optimization; device compute budgets; multilingual text inputs from NLU layer.
- Corporate communications at scale (enterprise/comms) — Executive announcements delivered in 30 languages in the executive’s voice. Workflow: consented voice capture; script translation pipeline; batch synthesis with speech‑sim audits. Assumptions/Dependencies: Legal approval; translation QA; brand safety processes.
- Synthetic data generation for ASR/SLU and speaker tech (industry/academia) — Create multilingual, speaker-consistent corpora to stress‑test ASR/SLU, improve language coverage, and evaluate anti‑spoofing. Tools: dataset generator driven by LID, speaking rates, and accent‑leakage probes; built‑in QC via DNSMOS, VAD, and WER SIM‑o metrics. Assumptions/Dependencies: Domain gap vs. natural speech; careful licensing/disclosure; anti‑spoofing safeguards.
- Benchmarking and reproducible evaluation (academia, policy) — Adopt the released 30‑language test set, text normalization frontend, and evaluation scripts as a baseline for multilingual TTS procurement and research. Tools: continuous benchmarking harness with WER, SIM‑o, IMOS/SMOS; shared leaderboards. Assumptions/Dependencies: Community uptake; consistent ASR backends (e.g., Whisper, Paraformer) for cross‑lab comparability.
- Contact center agent simulation and training (enterprise/HR) — Scenario audio in many languages with consistent “trainer” voices; evaluate agent ASR and comprehension pipelines. Tools: synthetic scenario bank with difficulty tiers (speaking rate, style). Assumptions/Dependencies: Clear disclosure of synthetic content; calibration against human-recorded baselines.
- Travel and personal communication aids (daily life) — Personal messages or announcements rendered in a traveler’s own voice across supported languages. Products: mobile apps to import short prompt audio and type messages for local playback. Assumptions/Dependencies: Consent; device/cloud compute; accurate scripts or translations.
- Security red‑team testing for voice authentication (finance/security) — Generate controlled spoofs to test and harden voice biometrics. Workflow: produce cross‑lingual, speaker-similar samples and evaluate ASV thresholds. Assumptions/Dependencies: Strict ethical governance; offline, non‑production testing; adherence to anti‑abuse policies.
Long-Term Applications
These require further research, scaling, or engineering (e.g., on‑device deployment, end‑to‑end speech pipelines, broader language coverage, safety tooling).
- Real‑time speech‑to‑speech translation preserving speaker identity (software, telecom, education, public safety) — Combine streaming ASR + MT + X‑Voice or move toward direct speech‑to‑speech with voice preservation. Products: live translator headsets; broadcast caption+voice translation suites. Assumptions/Dependencies: Low‑latency streaming stack; high MT accuracy for all target languages; robust diarization and turn‑taking; edge cases for code‑switching.
- On‑device, privacy‑preserving voice cloning (mobile/IoT) — Distilled/quantized 0.4B‑class NAR TTS for phones, cars, and home devices. Tools: 8‑bit or lower precision, KV‑cache‑like optimizations for DiT, faster ODE solvers, lightweight vocoders. Assumptions/Dependencies: Hardware acceleration (NPU/DSP); memory/power budgets; acceptable quality at reduced model size.
- Expansion to low‑resource and unwritten languages (global development, education, cultural preservation) — Scale the IPA-centric pipeline with specialized g2p and community‑sourced audio; use transcript‑free SFT to reduce annotation needs. Products: localized voice libraries for underserved languages. Assumptions/Dependencies: Ethical data sourcing and community consent; improved tokenization for languages where eSpeak‑NG underperforms; careful evaluation with native speakers.
- Fine‑grained accent and style control (media, education) — Turn dual‑level LID and decoupled CFG into intuitive “accent/style sliders,” disentangling timbre, prosody, and linguistic features. Products: creative GUIs for localization studios and educators. Assumptions/Dependencies: Additional supervision or control tokens; interpretable mappings between GUI controls and acoustic outcomes; user studies.
- Long‑form and expressive narration (audiobooks, training content) — Stable multi‑hour synthesis with consistent prosody, section‑aware pacing, and character switching. Tools: long‑form alignment workflows, segment stitching, prosody planners. Assumptions/Dependencies: Better long‑context handling (memory/attention strategies); expressive style modeling; robust error recovery for long runs.
- Multimodal avatars with lip‑sync and emotion (software, robotics, healthcare) — Drive photorealistic or stylized avatars across languages while preserving speaker identity and emotional nuance. Tools: TTS + lip‑sync (e.g., face animation models) + emotion control layers. Assumptions/Dependencies: High‑quality phoneme‑viseme alignment; emotion/style labels; compute for real‑time operation.
- Secure provenance and anti‑deepfake tooling (policy, finance, media platforms) — Embed robust audio watermarks at the vocoder stage; provide public detectors; couple with consent registries. Products: “Clone Registry” APIs; enterprise policy kits for acceptable use. Assumptions/Dependencies: Watermark robustness vs. common transforms; standards adoption; minimal perceptual impact; regulator and platform buy‑in.
- Public safety and emergency multilingual PA systems (government, transportation) — One consistent voice for alerts across languages; local CFG presets for clarity in noisy environments. Tools: certified TTS appliances with offline failover. Assumptions/Dependencies: Reliability certifications; loudspeaker/vocoder optimization; tested scripts with domain experts.
- Conversational commerce and personalized ads (marketing, retail) — Hyper‑personalized messages in a user’s preferred language and a consented brand voice. Tools: campaign schedulers with LID routing and frequency caps. Assumptions/Dependencies: Explicit user consent; platform enforcement of anti‑abuse and disclosure; privacy regulation compliance.
- Standardized multilingual TTS scorecards for procurement (policy/standards) — Use the open test set and scripts to create certification scorecards (WER, SIM, IMOS/SMOS) for public tenders and audits. Tools: compliance evaluation suites; periodic re‑testing workflows. Assumptions/Dependencies: Stakeholder alignment on metrics; periodic dataset refresh; handling of ASR bias across languages.
- Cross‑modal research on flow‑matching vs. AR at scale (academia) — Study sample quality/latency tradeoffs, accent leakage suppression via dual‑level LID, and transcript‑free SFT generalization. Products: teaching labs, reproducible baselines, and student projects. Assumptions/Dependencies: Compute/storage for 420K‑hour‑scale training; consistent evaluation harnesses; community maintenance of datasets.
- Healthcare communication and telemedicine (healthcare) — Patient‑specific, multilingual instructions in their own voice to improve adherence; caregiver updates across languages. Tools: clinical content templates; safety‑tuned CFG presets. Assumptions/Dependencies: Medical safety review; culturally appropriate translations; stringent privacy and consent workflows.
Notes on feasibility across applications
- Technical dependencies: high‑quality vocoder; clean prompt audio; stable IPA/g2p for each language; GPU or optimized edge inference; integration of LID and CFG schedules for accent control; text normalization front‑end.
- Legal/ethical dependencies: explicit consent for cloning; disclosure policies; watermarking/detection to deter misuse; compliant data handling (GDPR/HIPAA/CCPA).
- Performance caveats: slight SIM gap vs. some AR baselines; accent leakage can still occur in difficult settings; certain languages may need better g2p than eSpeak‑NG; long‑form stability and emotion control require further work.
- Operational dependencies: translation quality for target languages; platform moderation and safety; autoscaling and monitoring for IVR/real‑time systems.
Glossary
- AdamW optimizer: An optimization algorithm that decouples weight decay from the gradient update to improve generalization. "and employ the AdamW optimizer~\citep{adamw} for optimization."
- Asymmetric Warmup (A-Warmup): A scheduling strategy that warms up linguistic guidance while keeping acoustic guidance strong at the start of sampling. "we propose Asymmetric Warmup (A-Warmup) for CFG strength"
- Autoregressive (AR): A modeling paradigm that generates outputs sequentially where each step depends on previous outputs. "either predicting discrete acoustic tokens in a fully autoregressive (AR) architecture"
- bfloat16 mixed precision: A reduced-precision floating-point format used to speed up training while maintaining numerical stability. "and bfloat16 mixed precision."
- Classifier-Free Guidance (CFG): A sampling technique that improves conditional generation by interpolating between conditional and unconditional predictions. "Classifier-Free~Guidance~\citep{cfg} is used to enhance the fidelity and conditioning of the generated speech."
- Coarse-to-fine hybrid frameworks: Two-stage models that first generate high-level semantics and then refine acoustics non-autoregressively. "employing coarse-to-fine hybrid frameworks that bridge AR semantic modeling with non-autoregressive (NAR) acoustic refinement"
- Cross-lingual synthesis: Generating speech in a target language conditioned on references from a different source language. "to enable cross-lingual synthesis."
- Decoupled Classifier-Free Guidance (DCFG): A variant of CFG that separately guides linguistic and acoustic components during sampling. "introduce Decoupled Classifier-Free Guidance (DCFG)"
- Diffusion Transformer (DiT): A transformer architecture adapted for diffusion/flow-matching generative modeling. "a Flow Matching model using Diffusion Transformer (DiT)~\citep{dit} architecture"
- DNSMOS: A non-intrusive model for estimating perceived speech quality/noise suppression quality. "We utilize DNSMOS~\citep{dnsmos} to assign an acoustic quality score"
- ECAPA-TDNN: A state-of-the-art speaker embedding network for speaker verification tasks. "we employ the ECAPA-TDNN\footnote{\url{https://huggingface.co/speechbrain/spkrec-ecapa-voxceleb/tree/main}~\citep{ecapa} model"
- Euler ODE solver: A numerical integrator for ordinary differential equations used to traverse the generative flow. "We use the Euler ODE solver with 16 NFE steps"
- Feature-wise Linear Modulation (FiLM): A conditioning method that scales and shifts features based on auxiliary inputs. "We instead apply the Feature-wise Linear Modulation (FiLM)~\citep{film} to text embeddings:"
- Flow Matching: A generative modeling approach that learns a vector field to transform noise into data along a continuous path. "X-Voice is built upon F5-TTS~\citep{f5tts}, a Flow Matching model"
- Forced alignment: A preprocessing technique aligning audio to its transcript at the frame/phoneme level. "without complex preprocessing like forced alignment"
- Graphemes: Written characters used as input units, as opposed to phonetic units like phonemes. "or graphemes~\citep{grapheme} as input"
- International Phonetic Alphabet (IPA): A standardized phonetic notation system covering sounds across languages. "using the International Phonetic Alphabet (IPA) as a unified representation."
- Intelligibility Mean Opinion Score (IMOS): A subjective metric rating how understandable synthesized speech is. "we introduce Intelligibility Mean Opinion Score (IMOS) and Similarity Mean Opinion Score (SMOS)"
- Intra-lingual: Pertaining to tasks within the same language (as opposed to cross-lingual). "negligible performance differences for intra-lingual and cross-lingual voice cloning"
- Language ID (LID): A discrete identifier specifying the language of an input for conditioning. "injects Language ID (LID) at textual level to guide pronunciation."
- LLMs: Very large neural models trained on extensive text corpora that can be leveraged for speech generation. "With the rise of LLMs"
- Mel-spectrogram: A time–frequency representation of audio on the mel scale used as a target in TTS. "Let be the Mel-spectrogram"
- Multi-Layer Perceptron (MLP): A feedforward neural network used here to fuse time and language embeddings. "This fused vector passes through a Multi-Layer Perceptron (MLP) with SiLU activation:"
- Non-autoregressive (NAR): A modeling paradigm that predicts all outputs in parallel, enabling faster inference. "non-autoregressive (NAR) acoustic refinement"
- Number of Function Evaluations (NFE) steps: The count of model evaluations during numerical integration in sampling. "with 16 NFE steps"
- ODE solver: A numerical method to integrate ordinary differential equations during generative sampling. "using an ODE solver to integrate the predicted vector field"
- Optimal Transport Condition Flow Matching (CFM): A training objective for flow matching that leverages optimal transport for conditioning. "F5-TTS adopts DiT with Optimal Transport Condition Flow Matching (CFM)~\citep{flowmatching}."
- Paraformer: A non-autoregressive ASR model used for objective evaluation (Chinese). "We use Paraformer~\citep{paraformer} for Chinese"
- Phonemes: Basic units of sound used as phonetic input representation in TTS. "phonemes remain the most widely adopted representation"
- Pinyin: Romanized phonetic transcription system for Mandarin Chinese. "We represent Mandarin Chinese via Pinyin"
- Prosodic: Relating to rhythm, stress, and intonation patterns in speech. "the scale and diversity of the dataset enable models to learn both fine-grained phonetic details and higher-level prosodic patterns."
- Real-time factor (RTF): A measure of synthesis speed relative to real time (lower is faster). "The RTF values are measured on an NVIDIA RTX 4090 GPU"
- SiLU activation: The Sigmoid Linear Unit activation function used in MLPs. "with SiLU activation:"
- Silero VAD: A voice activity detection tool used for trimming non-speech segments. "we utilize Silero~VAD\footnote{\url{https://github.com/snakers4/silero-vad} to detect speech boundaries"
- Speaker encoder: A model that extracts speaker identity embeddings from audio. "employing speaker encoders to extract identity independently of text"
- Speaking Rate Predictor: A model to estimate or control speech rate for duration prediction. "for Speaking Rate Predictor."
- Supervised fine-tuning (SFT): Additional training using labeled data to adapt or improve a pretrained model. "We adopt a supervised fine-tuning (SFT) strategy"
- Sway sampling coefficient: A parameter controlling sample trajectory perturbation during inference. "and sway sampling coefficient -1.0."
- Similarity Mean Opinion Score (SMOS): A subjective rating of perceived speaker similarity to a reference. "we introduce Intelligibility Mean Opinion Score (IMOS) and Similarity Mean Opinion Score (SMOS)"
- Speaker Similarity (SIM-o): An objective metric (cosine similarity of embeddings) measuring speaker similarity. "We report Word Error Rate (WER) and Speaker Similarity (SIM-o) as objective metrics."
- Text-guided speech-infilling: A task where missing speech segments are generated conditioned on text and context. "trained on the text-guided speech-infilling task."
- Vector field: The learned field that guides integration from noise to data in flow matching. "integrate the predicted vector field"
- WavLM-Large: A pretrained speech model used for extracting speaker embeddings. "extracted using a pre-trained WavLM-Large model~\citep{wavlm}"
- Whisper-large-v3: An ASR model used for transcribing generated speech in evaluation. "and Whisper-large-v3~\citep{whisper} for other languages"
- Word Error Rate (WER): A standard ASR-based metric for intelligibility measuring substitutions, insertions, and deletions. "We report Word Error Rate (WER)"
- Zero-initialization: Initializing parameters to zero to avoid disrupting pretrained representations early in training. "We zero-initialize all LID injection layers"
- Zero-shot voice cloning: Cloning a target speaker’s voice from a short prompt without speaker-specific training. "Zero-shot voice cloning has revolutionized text-to-speech (TTS) synthesis"
Collections
Sign up for free to add this paper to one or more collections.

