- The paper introduces LMO-IGT, a novel method that leverages implicit gradient transport to accelerate convergence without extra gradient evaluations.
- It establishes a unified RSF-based framework bridging unconstrained and constrained optimization via normalized and sign-based momentum updates.
- Empirical evaluations on ResNet-18/CIFAR-10 show that Muon-IGT outperforms standard LMO and variance-reduced methods in both accuracy and computational efficiency.
Accelerating LMO-Based Optimization via Implicit Gradient Transport
This paper addresses the optimization of large-scale, stochastic, and potentially nonconvex objectives as encountered in deep learning. The focus is on LMO-based (Linear Minimization Oracle) algorithms—especially those typified by Lion and Muon—that have gained recent empirical traction due to their ability to normalize gradient momentum and exploit structured update geometries. Despite progress, accelerated convergence typically necessitates variance reduction, which doubles gradient evaluation cost per iteration and is thus computationally burdensome. Moreover, theoretical analyses for unconstrained (Euclidean) and constrained (Frank–Wolfe-type) formulations are fragmented, impeding a unified understanding.
The key questions posed are:
- Can LMO-based optimizers achieve acceleration beyond the O(ϵ−4) stochastic rate without the full cost of variance reduction?
- Can one design and analyze these methods in a unified framework applicable to both unconstrained and constrained settings?
Unified Framework and Regularized Support Function
The authors present a unified framework for stochastic LMO-based optimization, parameterizing methods using a generic LMO update class that encapsulates normalized SGD, sign-based momentum, and matrix-structured updates. They introduce the Regularized Support Function (RSF) as a stationarity measure bridging the dual norm (for unconstrained problems) and the Frank–Wolfe gap (for constrained optimization), enabling direct comparison across algorithmic and geometric variants.
Given a convex set C and regularization λ≥0, the RSF is defined as:
ΨC,λ(w):=v∈Csup⟨−∇F(w),v−λw⟩.
This interpolates between the support function hC(−∇F(w)) (unconstrained) and λ times the Frank–Wolfe gap GP(w) (constrained with P=λ−1C).
LMO-IGT: Implicit Gradient Transport for LMO-Based Methods
The principal algorithmic contribution is the LMO-IGT method, which adapts implicit gradient transport (IGT) to the LMO-based paradigm. The classical IGT technique mitigates momentum lag in normalized SGD by transporting gradients to a lookahead point, aligning the momentum buffer with the actual optimization trajectory. The novel insight here is that this mechanism generalizes to arbitrary LMO directions induced by C, e.g., for sign-based Lion, matrix-based Muon, or others.
IGT is implemented by updating momenta using gradients at an extrapolated point xt, which is a convex combination of the prior iterate(s) and the current LMO direction parameterized according to the momentum schedule. This preserves single stochastic gradient evaluation per iteration.
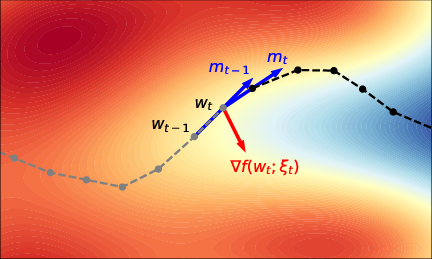
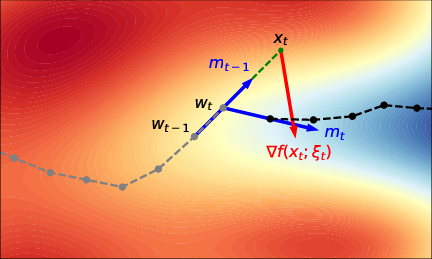
Figure 1: Stochastic momentum (left) and IGT (right); IGT aligns the momentum buffer to the optimization trajectory via extrapolated point evaluation.
Theoretical Results: Unified Stochastic Rates
Detailed non-asymptotic convergence rates under the RSF are established for three algorithmic classes—plain stochastic LMO, variance-reduced LMO (LMO-VR), and the new LMO-IGT:
- Stochastic LMO achieves an C0 iteration complexity, i.e., to reach expected RSF C1, C2 gradient oracle accesses suffice.
- LMO-VR leverages STORM-like corrections, reducing complexity to C3, at the price of doubling the gradient cost per iteration.
- LMO-IGT attains C4 complexity, matching much of the benefit of VR without extra gradient evaluations. This acceleration is enabled by exploiting second-order smoothness via gradient evaluation at transported points.
These results are obtained under standard C5-smoothness, bounded variance, and when appropriate, C6-Lipschitz Hessian assumptions. The analysis is precise, with exact dependencies on momentum parameters and learning rates. Importantly, all are cast in terms of the RSF, allowing direct cross-geometry comparison.
Empirical Evaluation
Experiments on ResNet-18 / CIFAR-10 (as well as more extensive setups in the appendix) compare AdamW, NIGT, Lion, Muon, their VR variants, and IGT-enabled versions. Hyperparameter grids are carefully searched for each method to ensure fair comparison.
Muon-IGT consistently yields the highest test accuracy and lowest test loss, outperforming both NIGT (Euclidean IGT) and Muon (operator-norm LMO) baselines. Notably, VR variants (e.g., Muon-VR, Lion-VR) sometimes fail to beat plain IGT or stochastic LMO, despite their better asymptotic rates, due to wall-clock time and additional computation. This suggests the advantage of LMO-IGT is not solely theoretical but represents a computationally efficient acceleration mechanism in practice.
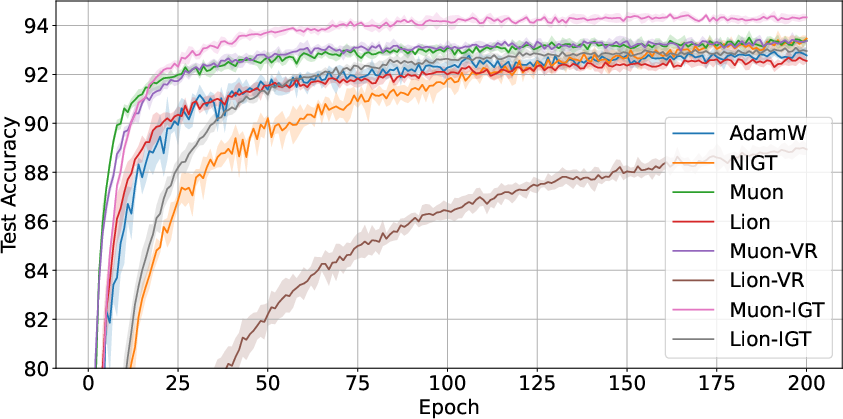
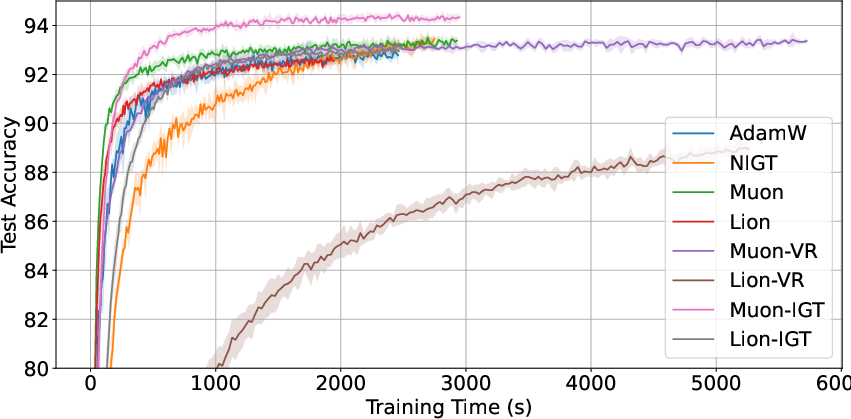
Figure 2: Test accuracy over epochs for AdamW, NIGT, Lion, Muon, and IGT/VR variants on CIFAR-10.
Implications and Future Directions
This work clarifies the relationship between normalized, sign-based, and matrix-aware LMO optimizers and their acceleration regimes. The RSF framework eliminates analytical inconsistencies between gradient-norm and FW-gap stationarity, making direct comparison theoretically sound. The main implication is that implicit gradient transport provides a pragmatic path to accelerate LMO-based methods without incurring the costly overheads of variance reduction, often central in modern large-scale model training.
Potential future directions include:
- Extending the unified RSF-based analysis to biased or approximate LMOs.
- Generalizing the approach to non-stochastic (deterministic) settings, or establishing high-probability convergence guarantees.
- Translating the method to even more structured parameter spaces, such as those emerging in very deep models or models with adaptive network architecture.
- Further empirical study of the limits of IGT acceleration in the presence of data heterogeneity (e.g., in federated learning) or severe nonconvexity.
Conclusion
The paper delivers a comprehensive theoretical and empirical study of low-overhead acceleration for LMO-based optimizers. By introducing implicit gradient transport to this family, a new tradeoff frontier is opened: practitioners gain a method that nearly matches variance reduction’s improved convergence rates but with the computational efficiency of single-gradient-per-iteration optimizers. The unified theory, operationalized via the regularized support function, offers a broad analytical lens for future development and benchmarking of optimization algorithms in deep learning.

