- The paper demonstrates that feedforward Transformers (BERT) rely on shortcut solutions that limit forward transfer in continual compositional tasks.
- It reveals that recurrent ALBERT develops algorithmic attention patterns, enabling more robust generalization and systematic reasoning over sequential tasks.
- Replay buffers and incremental data mixing are shown to mitigate catastrophic forgetting, although neither architecture fully integrates knowledge across experiences.
Introduction
This paper addresses the intersection of continual learning (CL) and compositional reasoning in Transformer neural network architectures, with a focus on how model architecture influences the ability to generalize and transfer knowledge across sequential tasks. Centering on the Learning Equality and Group Operations (LEGO) synthetic reasoning framework, the study examines the CL performance of two canonical Transformer variants: feedforward BERT and recurrent ALBERT. The principal contribution is a systematic investigation of whether these architectures leverage generalizable solutions or resort to shortcut solutions, and how this impacts continual learning and forward transfer across compositional subproblems.
The Continual LEGO Task Design
The LEGO task employs the D3 symmetry group to construct well-defined, theoretically grounded subproblems (flip-flop experiences) with recurring algebraic structure, thus enabling controlled probing of compositional reasoning (Figure 1).
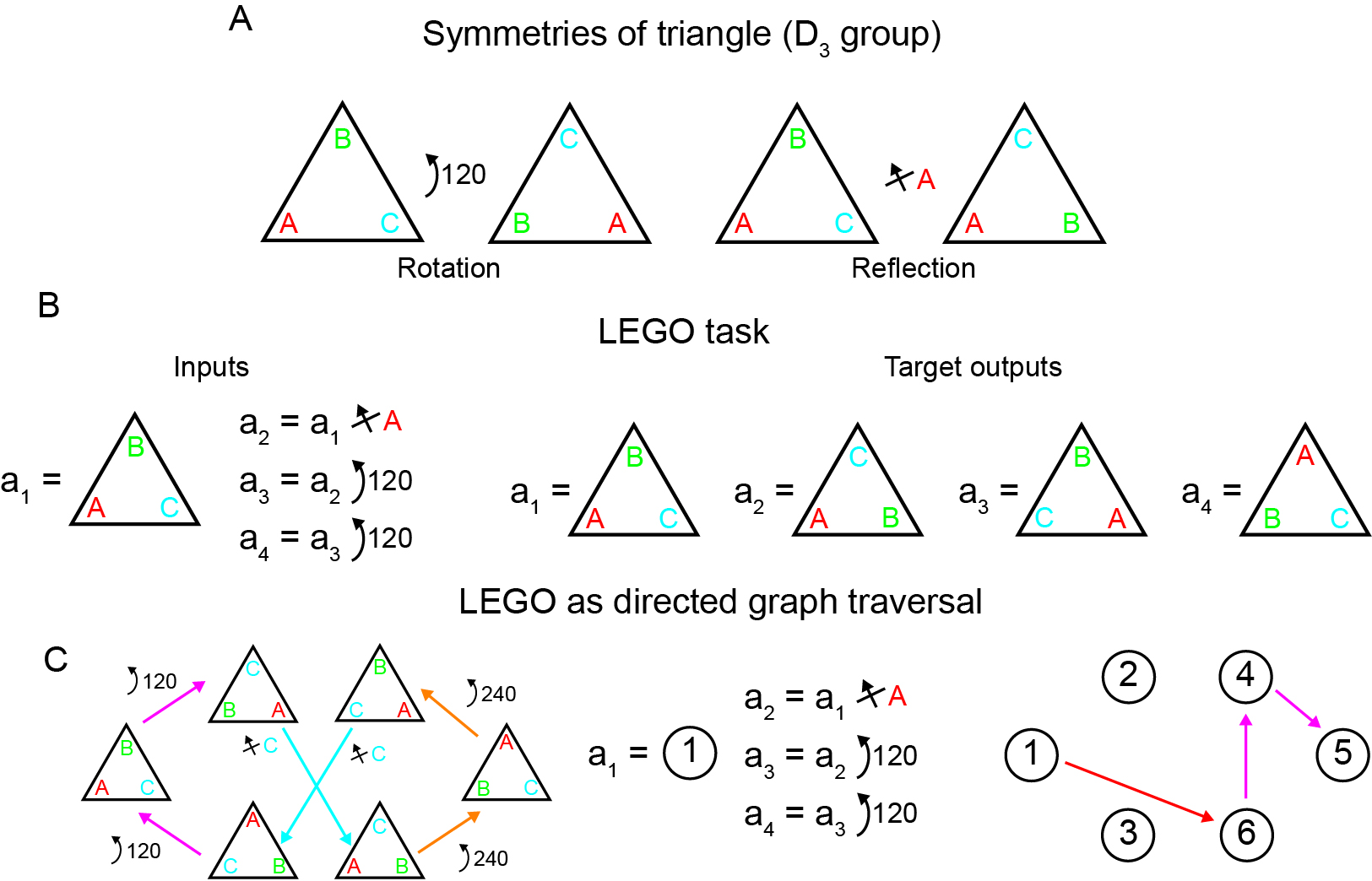
Figure 1: The structure of the D₃ LEGO task—illustrating its symmetries, task instantiation as group operations, and equivalence to directed graph traversal.
The continual LEGO adaptation introduces three sequential experiences, each a subtask with nearly isomorphic algebraic structure, reflecting realistic requirements for continual adaptation and transfer while minimizing confounds from distributional shift.
Main Results: Architectural Inductive Bias and Emergent Computations
Sequential training on the continual LEGO tasks reveals a stark architectural divergence. Both BERT and ALBERT achieve perfect in-distribution accuracy on the first flip-flop experience. However, only ALBERT displays strong generalization to longer sequences and robust forward transfer to subsequent experiences, with BERT languishing at chance for compositional generalization and showing inconsistent sample efficiency across seeds and model sizes (Figure 2).
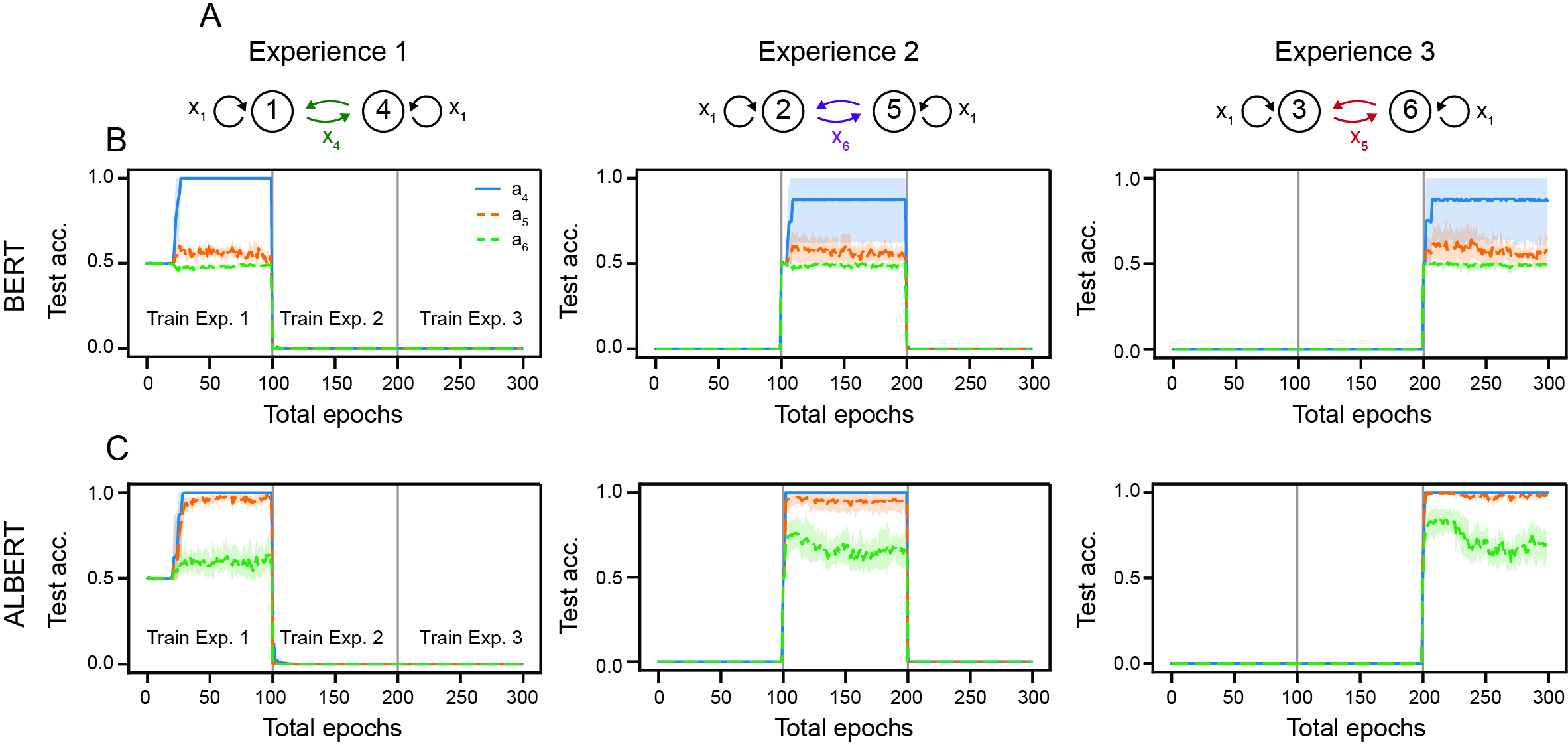
Figure 2: BERT and ALBERT performance on the continual LEGO task across three flip-flop experiences, highlighting forward transfer and catastrophic forgetting.
A hyperparameter sweep further elucidates these architectural differences (Figure 3): ALBERT networks demonstrate monotonic improvement in generalization and forward transfer as model depth grows, whereas BERT's capacity does not correlate cleanly with performance, and catastrophic forgetting is ubiquitous in both architectures.
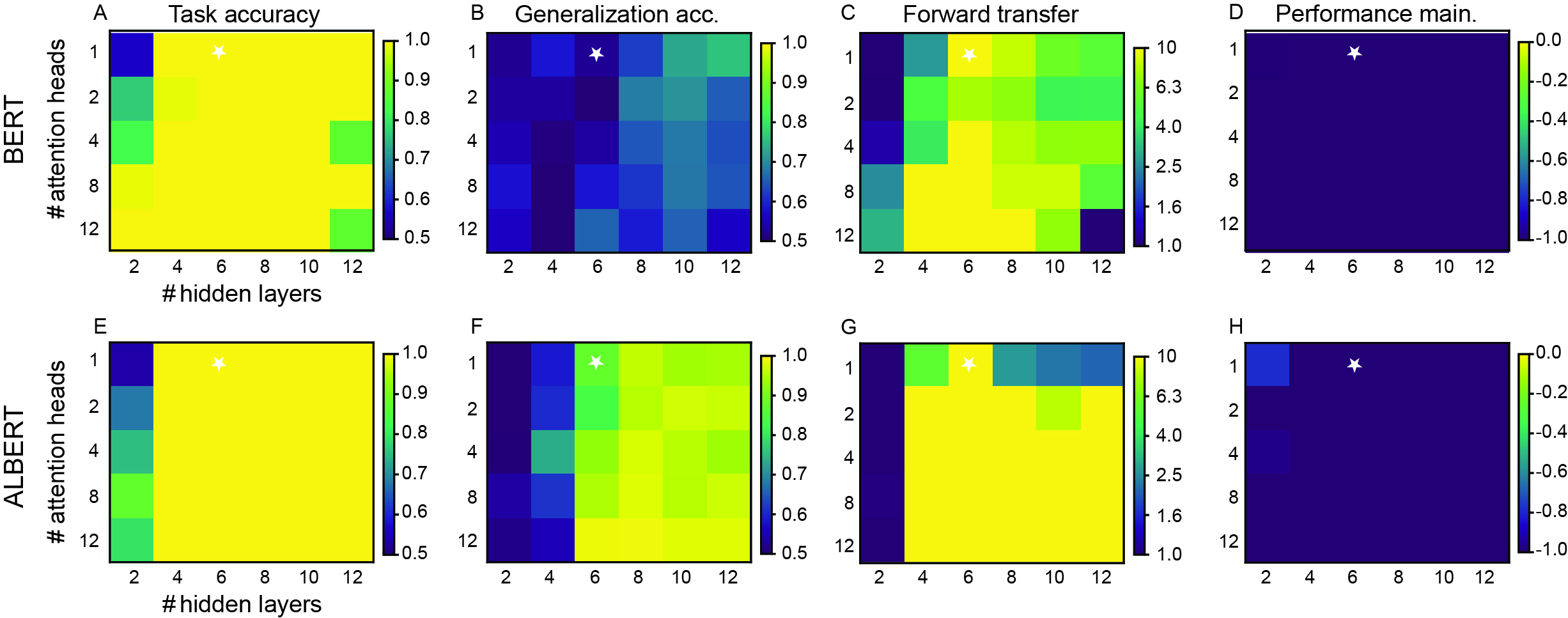
Figure 3: Relationship between Transformer depth/width and continual LEGO performance metrics—task accuracy, generalization, forward transfer, and performance retention—for BERT and ALBERT.
Analysis of attention patterns in minimal architectures (single-head, six-layer variants) demonstrates qualitative distinctions in learned computation (Figure 4). ALBERT develops attention regimes resembling algorithmic For loops, attending systematically to preceding clauses, thereby supporting reusable, compositional computation. In contrast, BERT converges on shortcut solutions, wherein later layers fixate attention on a single token from the initial clause, bypassing the algebraic structure of the problem and thereby failing to generalize beyond the training regime.
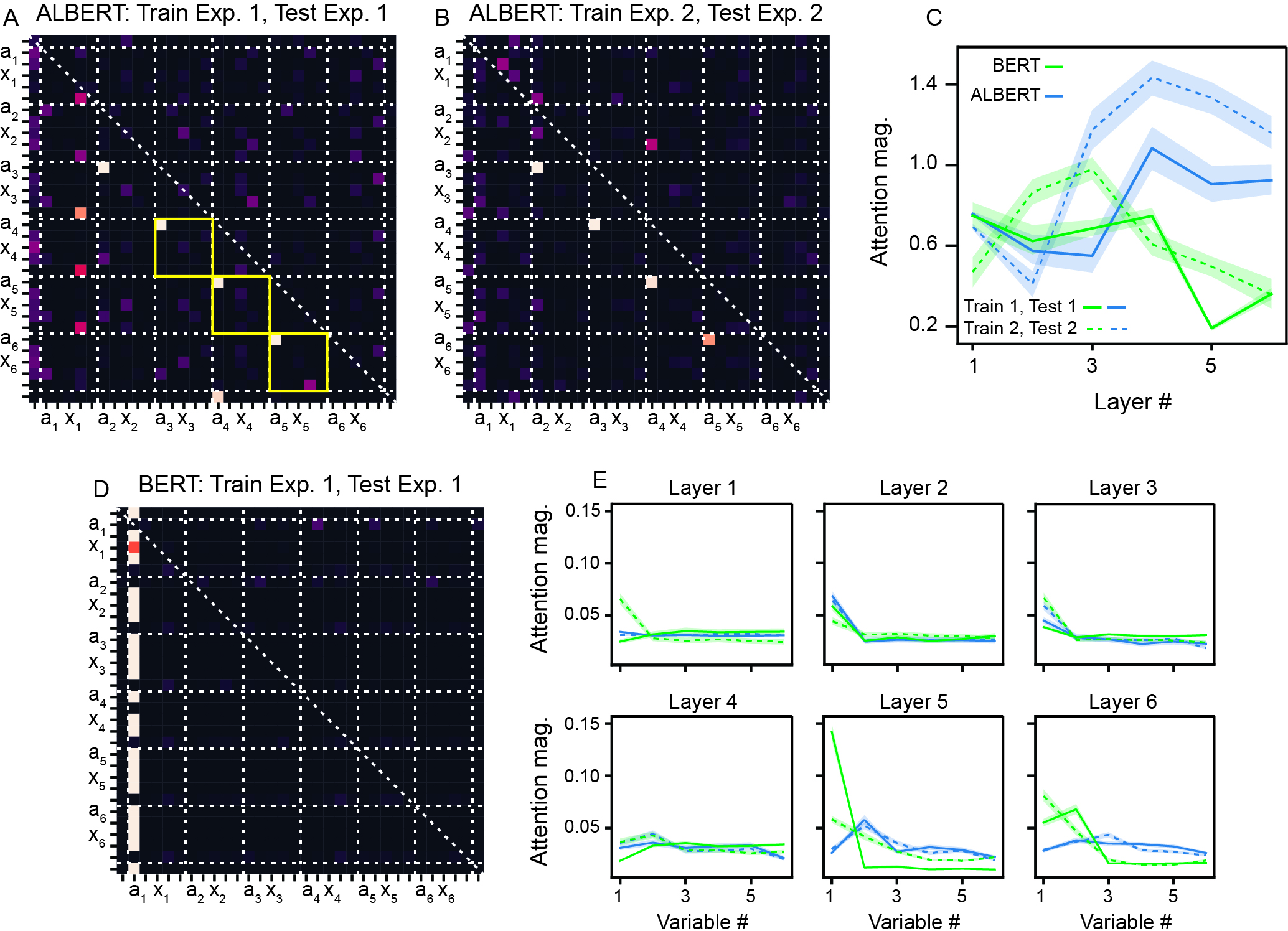
Figure 4: Attention pattern analyses for minimal ALBERT and BERT, demonstrating algorithmic For loop-like solutions in ALBERT versus shortcut solutions in BERT.
Catastrophic Forgetting and the Limits of Replay
Both architectures suffer from catastrophic forgetting, losing nearly all prior experience performance when learning new subtasks. Replay buffers, a canonical CL intervention, mitigate this effect, restoring performance on previous experiences without degrading forward transfer in both architectures when implemented with modest memory fractions (Figure 5). Replay stabilizes learned attention patterns, as measured via attention similarity metrics pre- and post-replay.
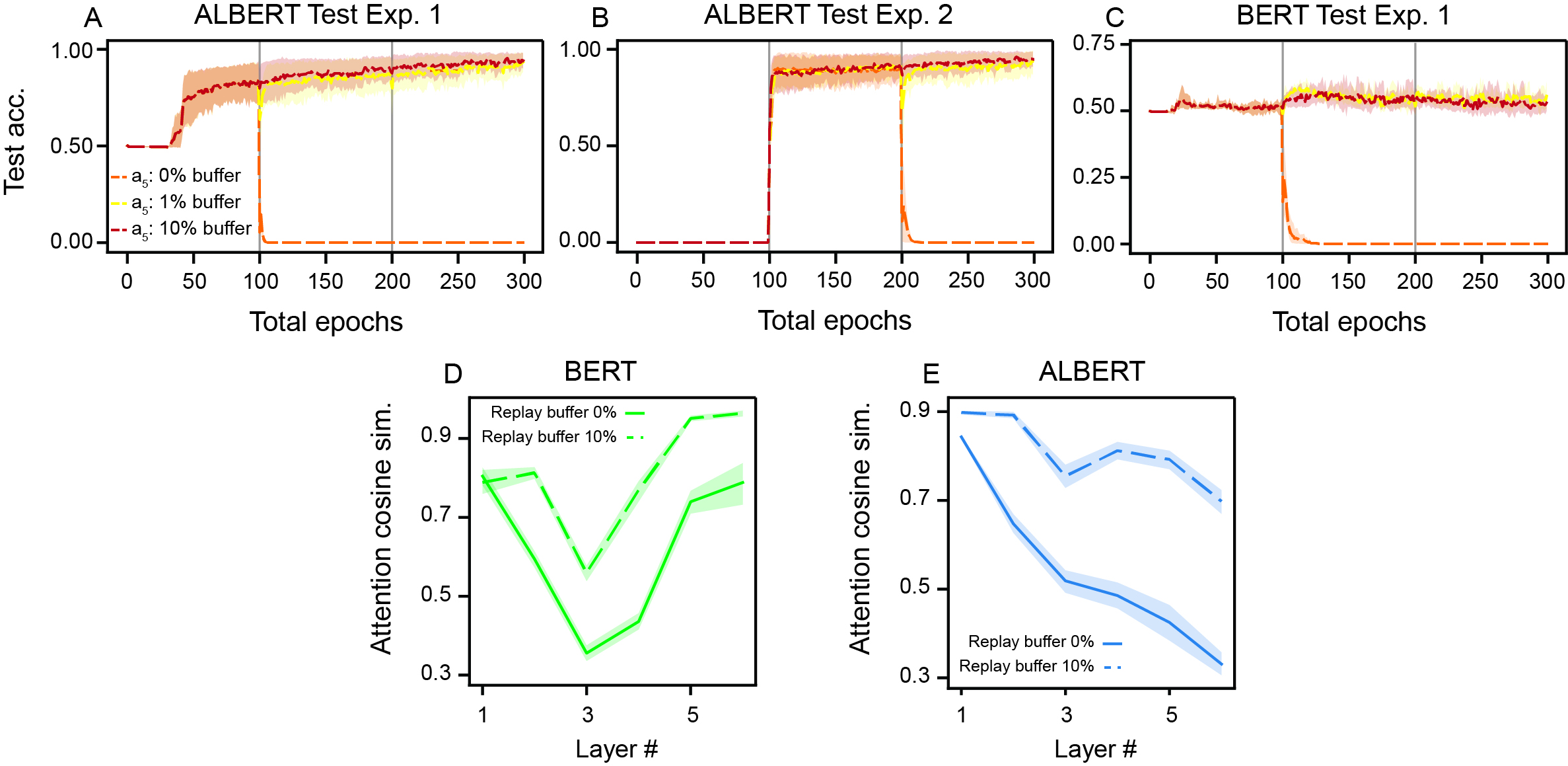
Figure 5: Replay buffer efficacy in mitigating catastrophic forgetting in ALBERT and BERT minimal models, shown by accuracy retention and attention similarity over experiences.
Compositional Generalization: Incremental and Generative Data Mixing
Despite the benefits of replay, neither BERT nor ALBERT can fully integrate knowledge across experiences when the test set demands compositional reasoning that bridges independently acquired subtasks. This failure persists when only naive episodic replay is used. For ALBERT, training on incrementally combined or generatively replayed experience data substantially rescues compositional generalization performance, but BERT remains limited by entrenched shortcut behaviors even with such interventions (Figure 6).
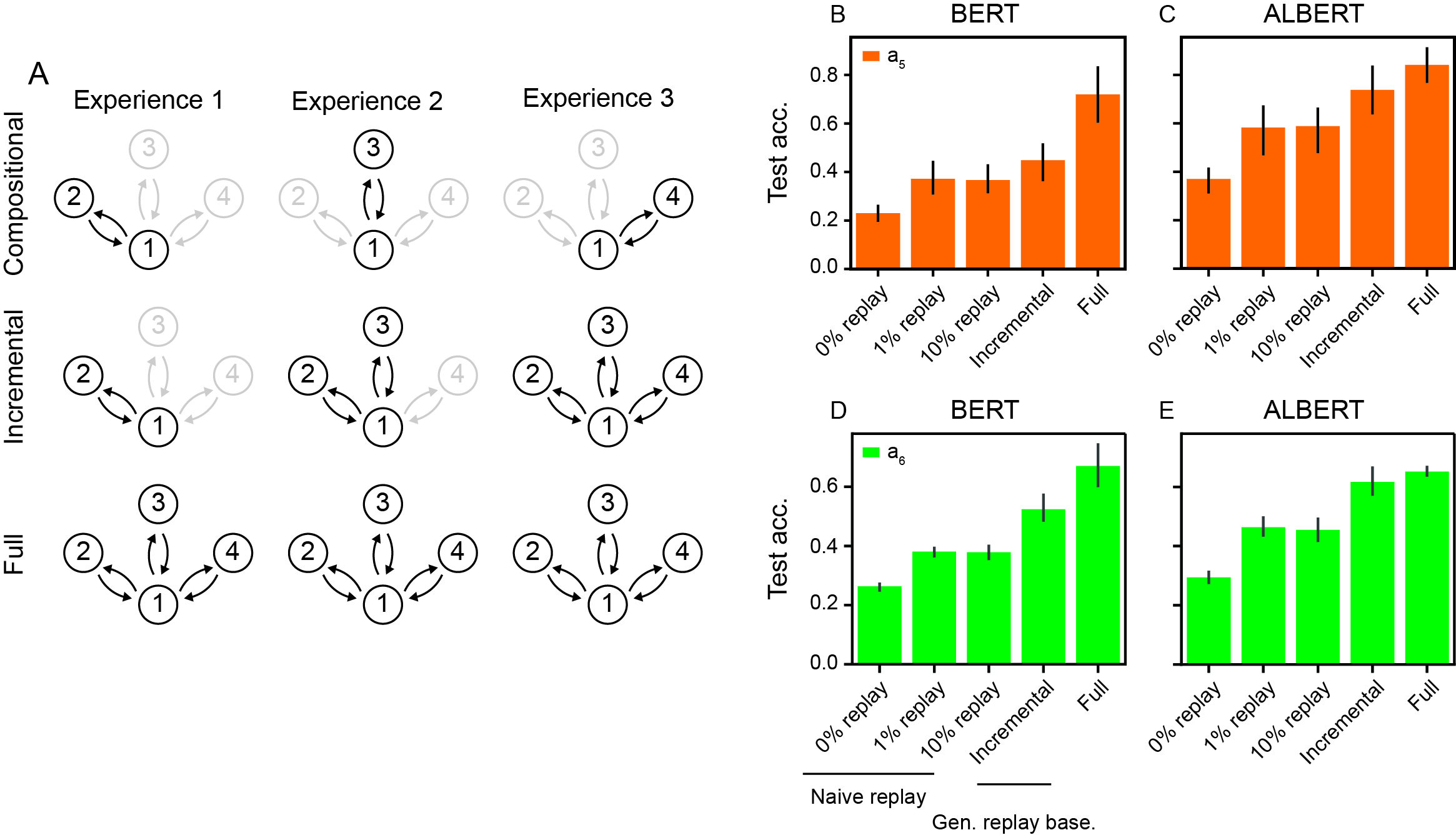
Figure 6: Effects of naive replay and incrementally combined experiences on the ability of minimal ALBERT and BERT to generalize compositionally across the full task.
Theoretical and Practical Implications
These results supply clear mechanistic evidence that recurrent inductive biases, as instantiated in ALBERT, enable the formation of generalizable, compositional routines that favor continual adaptation and transfer in structured reasoning domains. Feedforward BERT, in contrast, is prone to memorization strategies that undercut compositional learning. The work establishes that even when global test accuracy can be superficially achieved, underlying attention mechanisms may represent fundamentally distinct (and not equivalently adaptable) solutions.
Practically, this exposes limitations in relying on standard feedforward Transformer architectures for scenarios requiring transfer, continual updating, and compositional reasoning—settings ubiquitous in both real-world applications and theoretical cognitive models. Architectures embedding recurrence or weight-sharing thus warrant prioritization in CL deployments requiring robust reasoning over sequential, related tasks.
From a theoretical standpoint, the results highlight a mismatch between model expressiveness and the ability (or tendency) to converge on structurally invariant solutions, reinforcing the significance of task-aligned inductive biases and interpretation of emergent circuit-level mechanisms.
Future Perspectives
The study motivates several future directions: (1) rigorous causal dissection and surgical intervention in attention mechanisms to establish necessity/sufficiency for algorithmic generalization; (2) porting the continual LEGO framework to autoregressive and larger-scale models, thereby examining if and how shortcut behaviors persist under the training regimes of modern LLMs; (3) systematic comparison and hybridization of alternative CL mechanisms beyond replay, such as modularity, distillation, or adaptive plasticity, and (4) generalization of findings to real-world, non-synthetic compositional tasks such as multi-step logical inference or graph navigation.
Conclusion
This paper provides compelling empirical and mechanistic evidence that shortcut solutions learned by Transformer architectures can significantly impair continual and compositional reasoning, with pronounced negative effects in feedforward variants like BERT. Recurrent architectures like ALBERT serve as a partial remedy by encouraging algorithmic, transferable computation strategies, although they too have compositional limitations without sophisticated CL interventions such as incremental data mixing. The findings underscore the complexity of continual compositional learning in deep architectures and offer concrete guidance for the design and analysis of future models intended for robust, reasoning-centric, lifelong learning scenarios.