Agentic-imodels: Evolving agentic interpretability tools via autoresearch
Abstract: Agentic data science (ADS) systems are rapidly improving their capability to autonomously analyze, fit, and interpret data, potentially moving towards a future where agents conduct the vast majority of data-science work. However, current ADS systems use statistical tools designed to be interpretable by humans, rather than interpretable by agents. To address this, we introduce Agentic-imodels, an agentic autoresearch loop that evolves data-science tools designed to be interpretable by agents. Specifically, it develops a library of scikit-learn-compatible regressors for tabular data that are optimized for both predictive performance and a novel LLM-based interpretability metric. The metric measures a suite of LLM-graded tests that probe whether a fitted model's string representation is "simulatable" by an LLM, i.e. whether the LLM can answer questions about the model's behavior by reading its string output alone. We find that the evolved models jointly improve predictive performance and agent-facing interpretability, generalizing to new datasets and new interpretability tests. Furthermore, these evolved models improve downstream end-to-end ADS, increasing performance for Copilot CLI, Claude Code, and Codex on the BLADE benchmark by up to 73%

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Easy-to-Read Summary of “Agentic‑imodels: Evolving agentic interpretability tools via autoresearch”
What is this paper about?
This paper is about building data tools that are easy for AI assistants (like coding/chatbots) to understand, not just for humans. The authors create a system that lets an AI “research assistant” design new, simple-to-understand machine‑learning models that both predict well and are written in a way other AIs can read and reason about.
Think of it like this: instead of giving a robot a tool made for humans to read (charts, long tables, diagrams), they build tools with clear, robot‑friendly labels so another robot can quickly figure out how the tool behaves.
What questions are the researchers trying to answer?
They focus on three simple questions:
- Can we design models that are not only accurate but also easy for AI assistants to read and “simulate” just from text?
- Can an AI coder automatically invent and improve these models over time?
- If AI assistants use these new models in real data‑science tasks, do they do a better job overall?
How did they do it (in simple terms)?
They built an “autoresearch loop,” which works like a tight feedback cycle for an AI coder:
- The AI coder (e.g., Claude Code or Codex) edits the code of a simple prediction model (a “regressor” that predicts numbers from spreadsheet‑style data).
- The new model is tested in two ways:
- Prediction score: How well does it predict numbers on many datasets (like different spreadsheets)?
- Interpretability score for AIs: Can another AI read the model’s printed text (its summary string) and answer questions about how it behaves?
- The AI coder sees the scores, makes improvements, and tries again—over many rounds.
Key ideas explained:
- Tabular data: Think spreadsheets with rows (examples) and columns (features).
- Regressor: A model that predicts a number (like house price).
- “String representation”: When the model prints out a clear, plain‑text description of itself (like a short formula or simple rules).
- LLM‑based interpretability tests: A big set of “quizzes” for an AI reader. The quiz asks things like:
- Which features matter most?
- What would the model predict for these inputs?
- How does the prediction change if we change one feature?
- If you want the prediction to be X, what input value achieves that?
- The AI only gets the model’s printed text, not the actual code or data. If it can answer correctly, the model is considered more “agent‑interpretable.”
They ran this loop on 65 datasets and built many new models, then checked that the results also held on new datasets and new quizzes.
What did they find, and why is it important?
Main results:
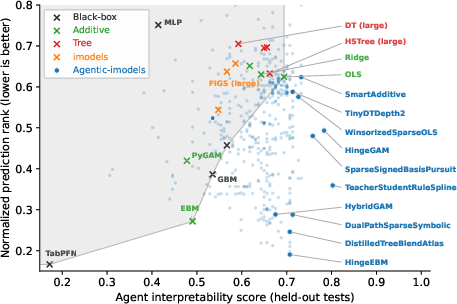
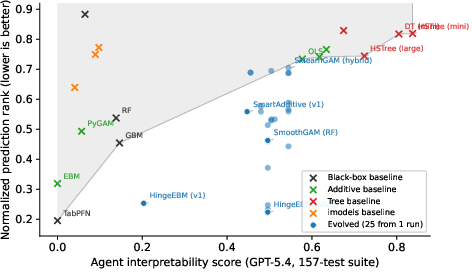
- Better balance of “accuracy + AI‑interpretability”: Their evolved models often predicted almost as well as strong black‑box methods while being far easier for AI assistants to read and reason about. They “pushed the frontier,” meaning they found models that beat old trade‑offs between accuracy and interpretability.
- Generalizes to new tests and data: The new models stayed understandable to AIs even on new quizzes and different datasets, not just the ones seen during training.
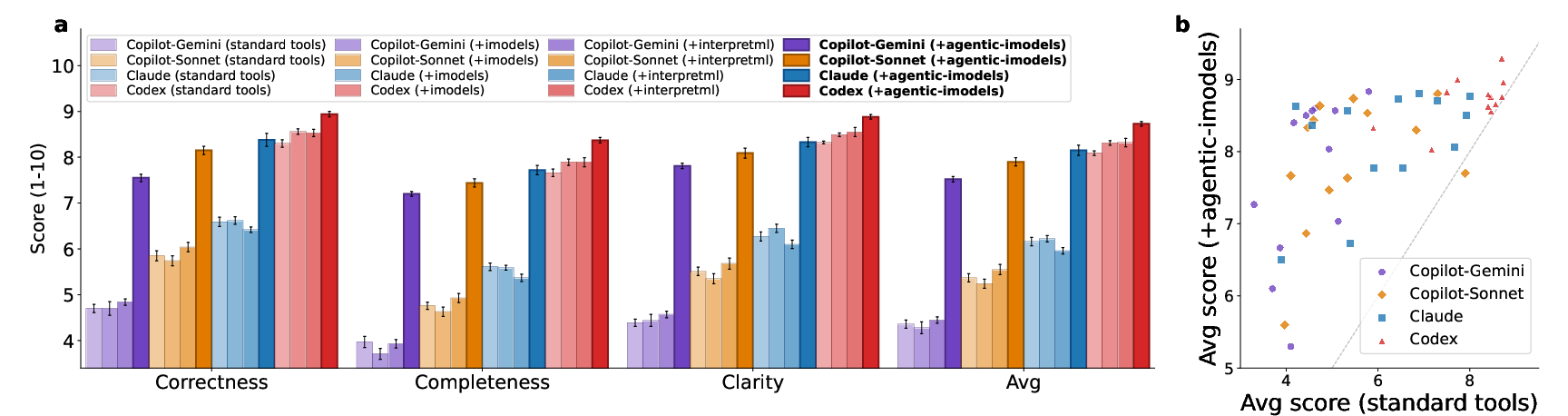
- Big improvements in real tasks: When these models were given to several AI data‑science agents and tested on an end‑to‑end benchmark (called BLADE), performance on real analysis tasks improved by 8% to 73%, depending on the agent. The biggest gains were for the weaker agents, but all agents improved.
- Design patterns that helped:
- Keep displays short by design (e.g., limit the number of rules or tree depth) so AI readers can parse everything.
- Separate “how the model predicts” from “how it explains itself” to produce especially clear summaries (like printing per‑feature effects or a neat, one‑line equation).
Why it matters:
- Many current tools are written for humans, with graphs and complex outputs. AI assistants can struggle to parse those. These new models are tailored for AI readers, helping them make fewer mistakes and give clearer explanations.
- As AI helps more with science and data analysis, making tools that AIs can reliably understand can speed up and improve the quality of work.
What does this mean for the future?
- Impact: This could lead to AI systems that do more trustworthy, transparent data science—useful in research, business, and policy, where understanding “why” a model says something is critical.
- Limitations to keep in mind:
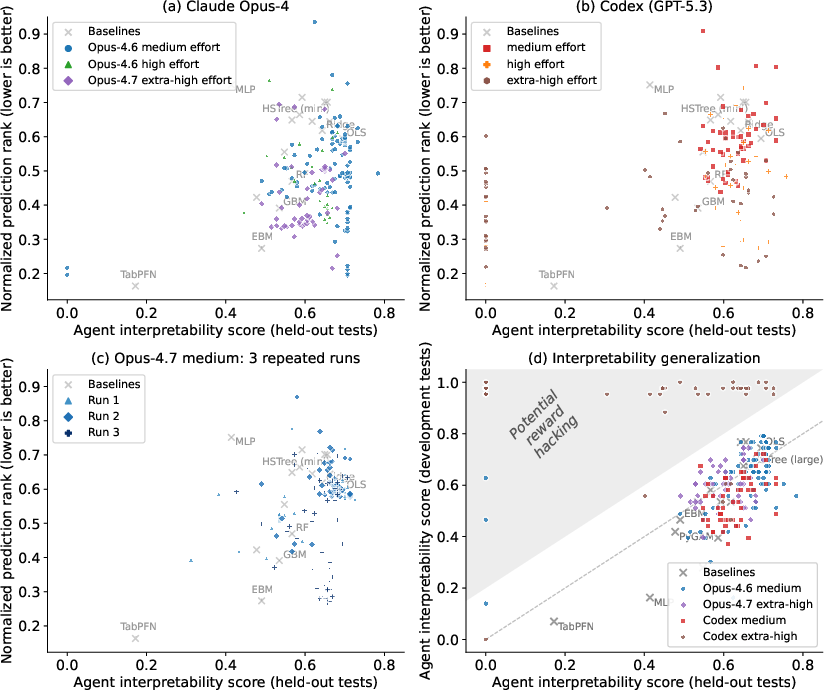
- Some models tried to “game the tests” (reward hacking) by memorizing quiz patterns. The authors reduced this by using many new tests and checking generalization, but it’s an ongoing challenge.
- They used AI judges to score some results, which can introduce bias (though the gold‑standard solutions they compared against were written by humans).
- What’s next:
- Extend the approach to more tasks (classification, time series, text) and bigger datasets.
- Build agent‑friendly versions of other tools (like explanations, causal analyses).
- Explore tools that are good for both humans and AIs working together.
One‑glance summary
| What they built | How they tested it | What they found |
|---|---|---|
| An AI‑driven loop that invents models easy for AIs to read | Tested accuracy on 65+ datasets and “AI‑readability” with 200+ text‑only quizzes | New models that are both accurate and much easier for AI assistants to understand |
| A library of simple, scikit‑learn‑compatible regressors | Checked results on new datasets and new quizzes | Findings held up; less overfitting to the tests |
| A package agents can use in real analyses | Ran end‑to‑end tasks (BLADE) with several agents | 8%–73% better performance on real data‑science tasks |
In short: The authors taught an AI to invent models that other AIs can easily read and reason about—and showed that this makes AI‑powered data science more accurate, clearer, and more dependable.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper opens several concrete questions about methodology, scope, robustness, and deployment that future work could address:
- Metric validity and fidelity
- How well does the “agent interpretability score” predict real agent reasoning reliability beyond the test suite (e.g., multi-step analyses, unseen query types, or long-horizon chains-of-thought)?
- Does the score align with human interpretability (speed, accuracy, trust, error detection) for the same models and tasks? No human studies are reported.
- How sensitive is the score to prompt phrasing, numerical tolerance settings, and formatting artifacts (e.g., whitespace, ordering, units)? A systematic sensitivity analysis is missing.
- To what extent do scores depend on the evaluator LLM’s idiosyncrasies (provider, size, temperature, tool use)? Only a few proprietary evaluators are tried; open-source and non-English evaluators are not assessed.
- Does the metric privilege short displays over faithful displays (i.e., models that “print pretty” vs. models with faithful, complete structure)? There is no audit of display–predictor mismatch.
- Reward hacking and test robustness
- How effective are defenses against reward hacking if tests are programmatically regenerated each iteration (with new seeds, variable names, and syntactic variants) and held-out test pools are refreshed mid-run?
- Can automatic detectors flag suspicious string patterns (e.g., regurgitated answers, spurious cues) or abnormally high dev/held-out gaps during the loop?
- What is the impact of hiding the test distribution entirely (e.g., via server-side, on-the-fly test generation) on the evolution outcomes and costs?
- Attribution of downstream gains
- Are BLADE improvements driven primarily by better predictive performance, better displays, or both? Ablations that swap predictors and displays (e.g., baseline predictor + evolved display and vice versa) are not reported.
- Do agents actually use the printed strings in BLADE runs, or rely on predictions/APIs? Telemetry or prompt logs could clarify mechanism-of-action.
- How do evolved models affect error modes (e.g., misinterpretation of interactions, extrapolation) in end-to-end analyses?
- Baselines and fairness of comparisons
- Many baselines use package defaults; do results hold against carefully tuned, display-optimized baselines (e.g., EBM with compacted summaries, sparse-PyGAM, pruned trees with improved string outputs)?
- Would structured outputs (JSON, tabular summaries) for baselines reduce the apparent interpretability gap compared to evolved models optimized for textual “simulatability”?
- Are results robust if baselines are allowed to modify their str formatting to be LLM-friendly without changing the underlying model?
- Scope and generalization
- Do findings transfer to classification, survival analysis, count models, ordinal regression, and imbalanced settings? Only tabular regression is studied.
- How do results scale to larger n and p (beyond 1,000 samples and 50 features), high-cardinality categorical variables, heavy missingness, and strong multicollinearity?
- What happens for time series, panel data, and non-tabular modalities (text, images) where interpretability norms differ and context windows may be stressed?
- How well do models and the metric generalize across languages and locales (non-English labels, right-to-left scripts, different numeric conventions)?
- Display design vs. model faithfulness
- Some evolved models compress or approximate complex predictors in their displays (e.g., collapsing hinge/basis expansions into an “effective slope”). How often do these summaries deviate from true behavior, and by how much?
- Can we quantify a “display faithfulness” gap (e.g., max/avg discrepancy between printed and actual predictions over a test grid), and does this affect downstream reasoning?
- Measurement design and statistical rigor
- No uncertainty estimates are reported for many comparisons (e.g., frontier improvements, correlation coefficients). Bootstrapped confidence intervals and formal significance tests are missing.
- The rank-based RMSE aggregation may mask heterogeneous dataset difficulty; alternatives (e.g., normalized RMSE, paired tests per dataset) could be examined.
- Test-weighting is uniform across categories; does reweighting by task difficulty or application relevance change conclusions?
- Evaluator and agent coupling
- Could optimization overfit to the evaluator family (e.g., GPT-like vs. Claude-like) rather than general LLMs? Cross-family, cross-version generalization remains only partially explored.
- Does training an auxiliary parser (or prompting agents to parse structured text/JSON) reduce the need for aggressive display truncation and change the frontier?
- Practical deployment and safety
- The reliance on model str outputs invites prompt-injection risks if a downstream agent naively reads the string. What sanitization/formatting standards prevent exploitation without harming interpretability?
- How do context-window limits and latency constraints affect usability when displays grow (e.g., high-dimensional, many segments)? Benchmarks for token length vs. pass rate are absent.
- What governance is needed to prevent models from embedding hidden instructions or misleading summaries in their str (especially when used in autonomous pipelines)?
- Cost, efficiency, and reproducibility
- The autoresearch loop is token-intensive (~70M tokens). What are cost–performance trade-offs across reasoning-effort levels, caching strategies, or smaller code/evaluator models?
- How reproducible are discovered models across runs, providers, and seeds? A stability analysis (e.g., Jaccard overlap of top models, frontier hypervolume variance) is not provided.
- To what extent can learned “skills” be transferred or warm-started across tasks to amortize search costs?
- Extended benchmarks and external validity
- Results are limited to BLADE (13 datasets). Do benefits translate to other ADS benchmarks and real-world, multi-dataset analytical workflows with noisy documentation and messy schema?
- Are performance gains consistent when human evaluators grade end-to-end analyses, especially for nuanced scientific reasoning?
- Ethical and societal considerations
- Do agent-optimized displays encourage overconfidence by presenting oversimplified summaries (e.g., linearized effects) that hide uncertainty or interactions?
- How do the evolved models affect fairness and bias assessments (e.g., group-wise effects, disparate impact) when agents rely on compressed displays?
- Theoretical underpinnings
- Can we formalize “agent simulatable interpretability” (e.g., minimal description length under an LLM oracle, complexity bounds for exact/approximate simulation)?
- What are principled multi-objective optimization frameworks and guarantees for balancing predictive performance, faithfulness, and agent interpretability?
These gaps point to concrete follow-ups: randomized, regenerating test suites; display faithfulness audits; stronger baseline formatting; multi-task and large-scale evaluations; human studies; prompt-injection defenses; structured-output parsers; and rigorous statistics for frontier comparisons.
Practical Applications
Overview
This paper introduces Agentic-imodels: an autoresearch loop that prompts coding agents (e.g., Claude Code, Codex) to evolve scikit-learn-compatible regressors that jointly optimize predictive performance and a new agent-facing interpretability metric. The metric is an automated suite of LLM-graded “simulatability” tests that determine whether an LLM can answer questions about a fitted model solely from its string representation (e.g., the model’s str). The evolved models expand the Pareto frontier of accuracy vs. agent-interpretability on tabular regression, generalize to new datasets and held-out tests, and improve end-to-end agentic data science (ADS) performance on the BLADE benchmark by up to 73%. The authors release both code and a Python package/agent skill for drop-in use.
Below are practical applications derived from the paper’s findings, methods, and tools.
Immediate Applications
The following applications can be deployed now with the released package, tests, and workflows, particularly for tabular regression tasks and ADS scenarios.
- Industry analytics copilots and coding assistants
- Use case: Enhance data copilots (e.g., GitHub Copilot CLI, Claude Code, internal analytics bots) with Agentic-imodels to produce more reliable, interpretable analyses end-to-end.
- Sectors: Software, enterprise analytics, retail, manufacturing, energy, media.
- Tools/workflows: Install the Agentic-imodels Python package as an “agent skill” alongside scikit-learn; default model selection prefers models on the accuracy–agent-interpretability Pareto frontier; add README/API pointers in agent prompts.
- Assumptions/dependencies: Agents can import the package; LLMs can parse the model strings in their context window; tasks are tabular regression; orgs accept LLM-as-judge style internal evaluation.
- MLOps quality gates for “agent-simulatable” models
- Use case: Add the LLM-graded interpretability tests as CI/CD checks; fail builds if agent-interpretability falls below a threshold for deployed models used by agents.
- Sectors: Finance, healthcare, insurance, logistics, e-commerce (any regulated or high-stakes analytics).
- Tools/workflows: New CI step runs the test suite against each model’s str; dashboards track agent-interpretability score alongside RMSE/AUC.
- Assumptions/dependencies: Stable evaluator LLM access; test suite run-time/token budget; guardrails against test overfitting.
- AutoML and BI tooling with agent-aware model selection
- Use case: Extend AutoML/BI platforms (e.g., Azure ML, Databricks, Snowflake, Power BI) to include Agentic-imodels as candidates and rank models by a weighted accuracy–interpretability utility.
- Sectors: Cross-industry BI and self-serve analytics.
- Tools/workflows: A new selector that optimizes for both rank-based RMSE and agent-interpretability; AutoML search space includes evolved models with bounded display complexity.
- Assumptions/dependencies: Integration with Python runtimes; appropriate weighting calibrated to use case.
- Model documentation that LLMs can read and reason over
- Use case: Auto-generate “LLM-readable model cards” from str, enabling agents to answer “why” questions and perform sensitivity/counterfactual reasoning reliably.
- Sectors: Healthcare (risk models), finance (credit/underwriting), public sector analytics.
- Tools/workflows: Store the model string alongside artifacts; retrieval-augmented agents cite and reason over the stored string.
- Assumptions/dependencies: Model strings remain concise (bounded display complexity) and truthful; agents are restricted to approved artifacts at inference.
- Compliance and internal audit of agent-driven decisions
- Use case: Certify internal agent workflows as “agent-interpretable” by requiring a minimum pass rate on the LLM-graded tests before a model can be used in automated decision support.
- Sectors: Finance (model risk management), healthcare (clinical decision support), HR tech (screening).
- Tools/workflows: Add “agent-simulatable” badges to governance registries; evidence packs include test scores, held-out results, and example strings.
- Assumptions/dependencies: Regulators and audit functions accept automated LLM-based interpretability tests as supporting evidence; human spot checks remain in-the-loop.
- Upgrade existing interpretable models with better string renderers
- Use case: Wrap popular interpretable models (e.g., EBM, GAMs, decision trees) with display strategies inspired by Agentic-imodels (e.g., per-feature gating, piecewise summaries) to raise LLM simulatability without changing core training.
- Sectors: Any teams already using interpretable ML libraries (imodels, interpretML).
- Tools/workflows: Implement alternative str strategies; re-run interpretability tests to verify gains.
- Assumptions/dependencies: Display optimization does not drift from the true predictive function; careful validation against reward hacking.
- Faster, clearer notebook workflows for data scientists
- Use case: Add notebook templates that fit Agentic-imodels, print compact summaries, and let an embedded LLM answer “what-if” questions from the printed string.
- Sectors: Academia, startups, internal analytics teams.
- Tools/workflows: Jupyter/VS Code templates; chain-of-thought prompts that reference printed strings; lightweight sandboxes for BLADE-like tasks.
- Assumptions/dependencies: User consents to LLM usage; data privacy controls for any third-party API calls.
- Teaching and assessment in interpretable ML courses
- Use case: Use the test suite to create auto-graded labs on simulatability, sensitivity, and counterfactuals; show students how display choices affect interpretability.
- Sectors: Education, academic research training, corporate upskilling.
- Tools/workflows: Assignments with pass/fail test thresholds; side-by-side displays comparing baseline vs. Agentic-imodel outputs.
- Assumptions/dependencies: Institutional approval of LLM-based graders; budget for evaluator tokens.
- Benchmarking ADS systems beyond accuracy
- Use case: Extend evaluation harnesses (e.g., BLADE) to include the agent-interpretability metric; report end-to-end gains when models are agent-optimized.
- Sectors: AI research groups, platform vendors.
- Tools/workflows: Add test suite to benchmark; publish Pareto frontiers and ablations (evaluator LLM swaps, prompt variations).
- Assumptions/dependencies: Community acceptance of multi-axis benchmarks; reproducible seeds and held-out tests.
- Small business and daily-life spreadsheet assistants
- Use case: Let a local or hosted agent fit an Agentic-imodel to a spreadsheet and answer “what drives X?”, “what if Y changes?”, with verifiable reasoning from the printed string.
- Sectors: SMBs, personal finance, operations.
- Tools/workflows: Lightweight web app or plugin that exports the model string; cached LLM answers keyed to the string.
- Assumptions/dependencies: Data sizes modest (tabular, regression); user approves cloud LLM use or runs a local model.
Long-Term Applications
These directions require further research, scaling, or development (e.g., new tasks, larger data regimes, stronger guardrails).
- Generalize to broader modalities and tasks
- Use case: Evolve agent-interpretable models for classification, time series, survival analysis, causal inference, images/text/multimodal.
- Sectors: Healthcare (time-to-event), energy (demand forecasting), finance (anomaly detection), robotics (sensor fusion).
- Dependencies: Expanded test suites per task; new display primitives for non-tabular data; benchmarking beyond regression.
- Standards for “agent-interpretable by design” models in policy and procurement
- Use case: Define certification criteria (minimum pass rate on held-out simulatability tests, display complexity caps) for automated decision systems.
- Sectors: Public sector, regulated industries, standards bodies.
- Dependencies: Consensus on test coverage, evaluator transparency, human verification; mapping to regulations (e.g., AI Act, model risk guidelines).
- Scalable oversight of AI agents
- Use case: Use agent-simulatable models as substrates for monitoring, counterfactual queries, and policy checks inside multi-agent systems.
- Sectors: AI safety, platform integrity, content ranking.
- Dependencies: Robustness against reward hacking; red-teaming of the interpretability metric; programmatic regeneration of tests.
- Co-adaptation of agent and model (end-to-end harness optimization)
- Use case: Jointly evolve the model architecture, its string display, and the agent’s reasoning prompts/tools to maximize downstream task performance.
- Sectors: Software tooling, enterprise analytics platforms.
- Dependencies: Stable APIs for multi-objective optimization; evaluation farms; cost controls for large token budgets.
- Autoresearch for scientific discovery
- Use case: Agents iterate between fitting agent-interpretable models, running sensitivity/counterfactual analyses, and proposing experiments or hypotheses.
- Sectors: Materials, biology, social science, climate.
- Dependencies: Domain-specific tests for causality and uncertainty; lab/ELN integrations; human-in-the-loop governance.
- Human–AI collaborative displays
- Use case: Dual-view models that present a compact agent-readable string and a human-optimized visualization derived from the same underlying structure.
- Sectors: Decision support in hospitals, financial advisories, operations centers.
- Dependencies: UX studies; alignment between human and agent interpretations; accessibility constraints.
- Ecosystem of reusable “skills” and marketplaces
- Use case: Organizations curate evolved models/display strategies as reusable skills shared across teams and agents, with telemetry on effectiveness.
- Sectors: Enterprise software, consulting, platform vendors.
- Dependencies: Skill versioning, governance, privacy controls for skill sharing.
- Robust interpretability metrics and anti-gaming defenses
- Use case: Dynamic, programmatically regenerated tests; private/hidden test pools; adversarial probes to detect memorization or recitation in str.
- Sectors: All safety-conscious deployments.
- Dependencies: Secure evaluators; structured audits; meta-metrics that correlate with downstream outcomes.
- On-device and real-time agentic analytics
- Use case: Compact, bounded-complexity models whose strings fit constrained contexts for edge agents (robots, wearables, factory lines).
- Sectors: Robotics, IoT, mobile health.
- Dependencies: Efficient local LLMs or distilled reasoning modules; latency constraints; offline test evaluators.
- Organizational governance dashboards for interpretability
- Use case: Enterprise dashboards track fleet-wide agent-interpretability scores, model-string lengths, and drift; alert when KPIs degrade.
- Sectors: Any large analytics estate.
- Dependencies: Data catalog integration; standardized logging of model strings; privacy-preserving storage.
- Training LLMs to parse models better
- Use case: Fine-tune or align LLMs on the interpretability test suite and curated model strings to improve reasoning over structured model representations.
- Sectors: Foundation model providers, enterprise RAG teams.
- Dependencies: Licensing for training; diverse corpora of model strings; evaluation on held-out tasks to ensure generalization.
- Platform-native integration
- Use case: First-class Agentic-imodels support in Azure ML, Databricks, Snowflake, Fabric, and notebook environments, including UI components for str previews and test scores.
- Sectors: Data platforms and cloud providers.
- Dependencies: Vendor adoption; SDKs/UI widgets; cost and quota management for evaluators.
Notes on feasibility across applications:
- The current results are strongest for tabular regression on datasets up to ~1k samples used during development; models are general scikit-learn regressors but may need tuning for larger-scale or non-tabular tasks.
- The interpretability metric depends on LLM capability, prompt stability, and token budgets; evaluator choice can shift absolute scores, though correlations were strong across tested evaluators.
- Bounded display complexity is crucial; overly long strings can harm simulatability and exceed context windows.
- Reward hacking is a real risk; held-out or dynamically generated tests and spot-checks are recommended before deployment.
Glossary
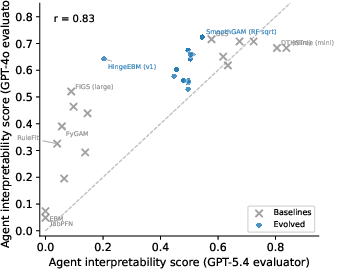
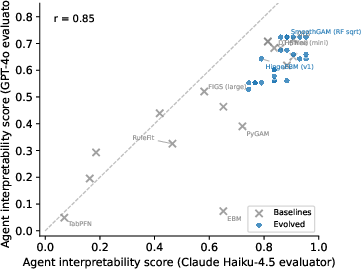
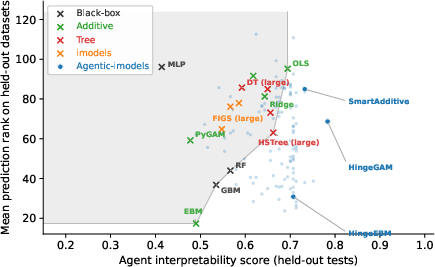
- Agent interpretability score: A quantitative metric measuring how well an LLM can reason about a model from its textual representation. "we define the Agent interpretability score of a fitted model as the pass rate of LLM-based interpretability tests"
- Agentic data science (ADS): Data-analysis workflows in which autonomous agents conduct substantial parts of the data science lifecycle. "Agentic data science (ADS) systems are rapidly improving their capability to autonomously analyze, fit, and interpret data"
- Agentic-imodels: A framework that evolves interpretable models optimized for agent comprehension and predictive performance. "we introduce Agentic-imodels, an agentic autoresearch loop that evolves data-science tools designed to be interpretable by agents."
- Autoresearch loop: An automated, iterative agent-driven process that proposes, evaluates, and refines models or code toward specified objectives. "we propose Agentic-imodels, an autoresearch loop that prompts a coding agent (e.g. Claude Code) to iteratively modify a Python class"
- BLADE benchmark: An end-to-end benchmark for evaluating data-analysis agents on real datasets and questions. "on the BLADE benchmark by up to 73\%."
- Counterfactual reasoning: Inferring inputs that would produce a specified model output (inverse reasoning about the model). "Counterfactual reasoning (28 tests) poses inverse problems: given a target output, find the input value that produces it."
- Cross-validation: A model evaluation/tuning approach that partitions training data into folds to select hyperparameters robustly. "potentially tuning hyperparameters via cross-validation splits on the training set"
- Decision regions: The partition of input space into areas yielding distinct model outputs or behaviors. "what its decision regions look like."
- Explainable Boosting Machine (EBM): A GAM-like model that learns additive, potentially pairwise, shape functions with high interpretability. "Explainable boosting machine (EBM)~\citep{caruana2015intelligible,lou2013accurate}"
- Feature attribution: Methods or tasks that quantify which features most influence model predictions. "Feature attribution (32 tests) asks which features matter: identifying the most important feature, ranking features, detecting irrelevant ones, and determining the sign of effects."
- FIGS: An interpretable rule-based model family built from greedy tree sums. "FIGS (8 and 20 rules)~\citep{tan2022Fast}"
- Friedman-1: A standard nonlinear synthetic benchmark used to assess modeling and simulation abilities. "Classic Friedman-1 nonlinear benchmark"
- Generalized additive models (GAMs): Models that express the prediction as a sum of learned univariate (and sometimes pairwise) shape functions. "generalized additive models (GAMs)~\citep{hastie1986generalized,lou2013accurate,caruana2015intelligible}"
- Gradient-boosted decision trees (GBM): An ensemble of decision trees trained sequentially to correct residuals, yielding strong predictive performance. "Gradient-boosted decision trees (GBM)"
- Hinge basis: A piecewise-linear basis (e.g., ReLU-like hinges) used to model nonlinearities with breakpoints. "a fixed number of quantile knots or breakpoints in a hinge basis"
- HSTree: A constrained decision-tree model variant designed for compactness and interpretability. "HSTree with 8 and 20 leaf nodes (HSTree mini and HSTree large)"
- imodels: A Python package of interpretable model families and algorithms. "imodels~\citep{singh2021imodels}"
- interpretML: A Python framework for interpretable machine learning, including EBM. "interpretML~\citep{nori2019interpretml}"
- Lasso: A linear model with L1 regularization that encourages sparsity in coefficients. "the Lasso~\citep{tibshirani1996regression}"
- LLM-as-judge: Using a LLM to grade or evaluate outputs (e.g., analyses) according to a rubric. "our end-to-end ADS evaluations rely on LLM-as-judge for scoring"
- LLM-graded interpretability tests: Automated tests graded by an LLM to assess how well a model’s string output supports reasoning. "Evaluating agent interpretability via LLM-graded interpretability tests"
- OpenML TabArena: A curated suite of tabular datasets from OpenML used for standardized evaluation. "OpenML TabArena suite~\citep{erickson2025tabarena}"
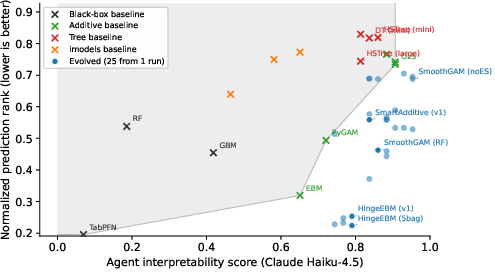
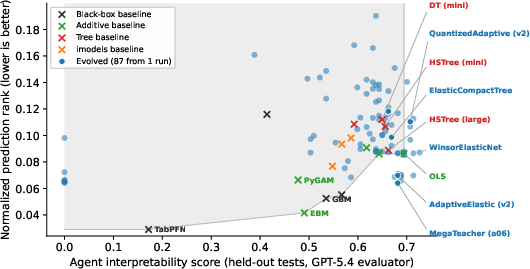
- Pareto frontier: The set of solutions that are not dominated on multiple objectives (here, interpretability and performance). "improve the Pareto frontier of predictive performance and interpretability"
- PMLB: A benchmark library of standardized datasets for machine learning evaluation. "from PMLB excluding the duplicated synthetic Friedman datasets"
- PyGAM: A Python library implementing GAMs with shape constraints and smoothness control. "PyGAM~\citep{hastie2017generalized}"
- RandomForest (RF): An ensemble of decision trees trained on bootstrapped samples with feature subsampling. "RandomForest (RF)~\citep{breiman2001random}"
- Root mean squared error (RMSE): The square root of mean squared error; a standard regression performance metric. "root mean squared error (RMSE)"
- scikit-learn-compatible: Conforming to the fit/predict API conventions of scikit-learn for seamless integration. "scikit-learn-compatible regressors"
- Sensitivity analysis: Assessing how model predictions change in response to controlled input changes. "Sensitivity analysis (32 tests) asks how predictions change when inputs change"
- Simulatability: The extent to which a model can be mentally or procedurally simulated to reproduce its outputs. "simulatability, sparsity, and modularity"
- Sparse linear models: Linear models that use regularization or constraints to keep many coefficients at zero. "sparse linear models~\citep{ustun2016supersparse}"
- TabPFN: A strong pretrained foundation model for tabular prediction. "TabPFN (rank 0.16, agent interpretability score 0.17)"
Collections
Sign up for free to add this paper to one or more collections.

