- The paper introduces the Learning-to-Theorize paradigm, constructing explicit, compositional theories from raw observations via latent program induction.
- The Neural Theorizer (NEO) framework achieves strong compositional and length out-of-distribution generalization across GridWorld, Arithmetic Factorization, and Image Editing benchmarks.
- The approach leverages state grounding and MDL-based adaptive explanation lengths to discover reusable primitives, enhancing systematic transfer and productivity.
Learning-to-Theorize: Explicit Programmatic Explanatory Structures in World Modeling
Motivation and Theoretical Foundation
The paper "Learning to Theorize the World from Observation" (2605.03413) redefines world understanding in artificial agents, moving beyond standard prediction-centric approaches typical of latent generative models and world simulators. Drawing inspiration from developmental cognitive science, it posits that genuine understanding emerges from the construction of explicit, compositional internal theories—latent executable programs that explain phenomena in terms of reusable primitives and their compositional structure. This theoretical shift addresses the limitations of prediction-only objectives, which often yield entangled, brittle representations lacking systematic generalization and transfer capacity.
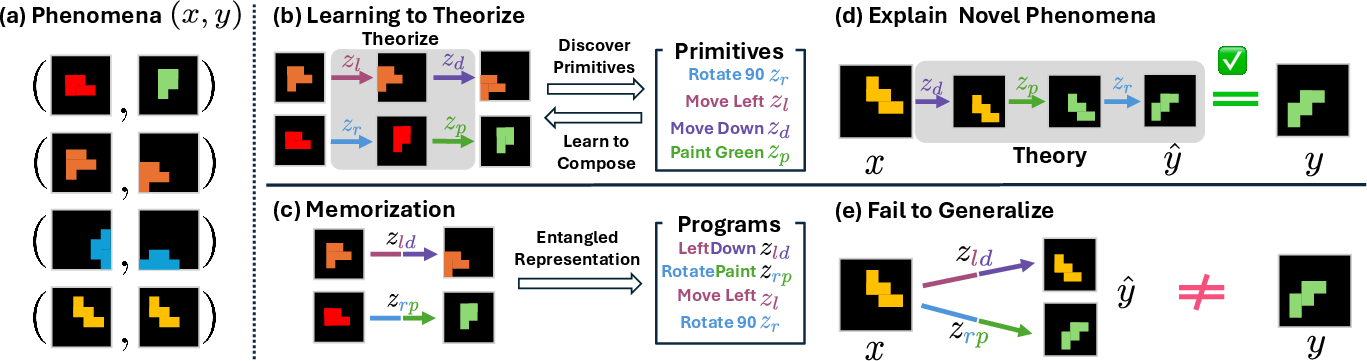
Figure 1: The L2T framework: under supervision-free compositional learning, reusable primitives are discovered and recomposed for novel phenomena, as opposed to entangled memorization strategies that fail on unseen programs.
Learning-to-Theorize Paradigm and Model Architecture
The L2T paradigm is formulated as an unsupervised neural program induction task: a phenomenon is modeled as an observation pair (x,y) generated by a latent program τ, itself a sequence of abstract primitives in a learned codebook. The training set comprises i.i.d. pairs without task grouping, language, or program supervision, thereby generalizing beyond curated symbolic domains. The model's objective is to discover primitive operations, learn their composition rules, and generate executable explanations for y from x that are transferable and generalizable.
Neural Theorizer (NEO)
NEO is instantiated as a probabilistic neural architecture maximizing the conditional likelihood pθ(y∣x) via two latent spaces: the program τ and its execution trace s. The Markovian generative process consists of encoding x to s1, sequentially sampling primitives via a "theory programmer" (a VQ-VAE-based discrete policy qϕ(zik∣sk,y)), and executing transitions τ0 with shared operators across examples. The resulting compositional program is decoded to reconstruct τ1. The framework is parameterized to support adaptive explanation length via the Minimum Description Length principle, favoring short, accurate programs and enabling productivity (generalization to longer, unseen compositions).
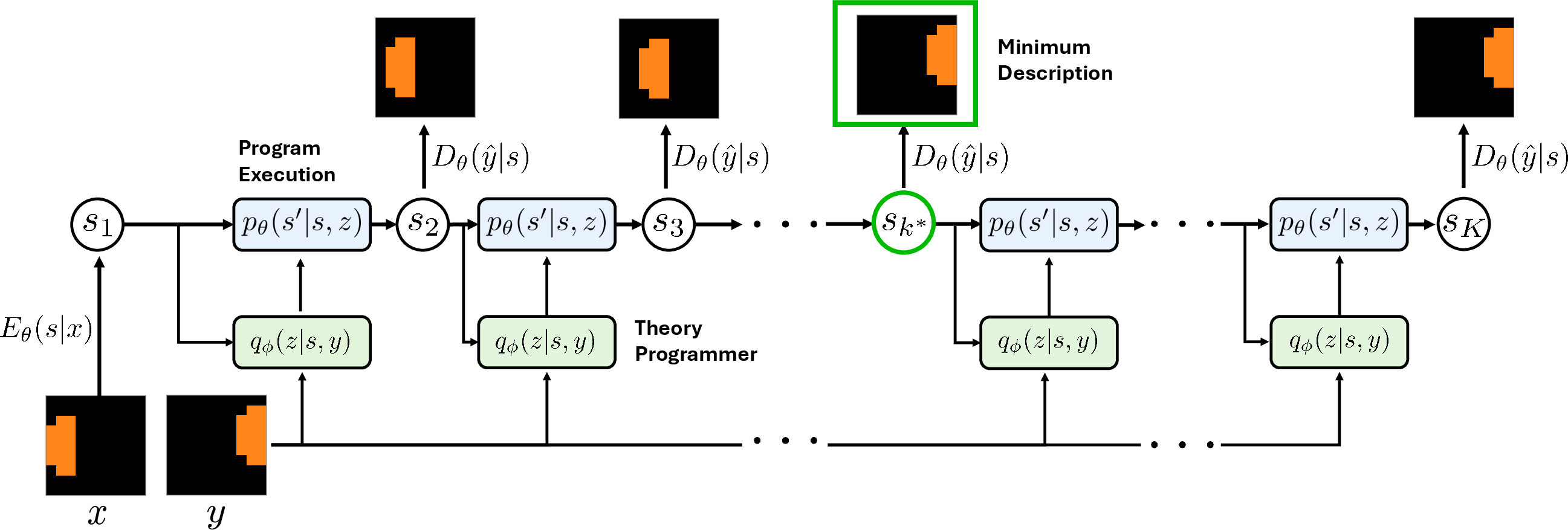
Figure 2: NEO’s computation graph: sequential primitive selection/composition with explicit state grounding and length selection via MDL.
State grounding regularizes intermediate states to valid representations, counteracting degenerate shortcut compositions. The entire architecture is trained end-to-end, with pretrained encoder/decoder for stability. Inference involves iterative greedy primitive selection (or stochastic sampling for test-time scaling), terminating when reconstruction criteria are met.
Experimental Evaluation and Empirical Results
Observation-to-Theory Induction Benchmark (OTIB)
A new benchmark, OTIB, evaluates transferable explanation, compositional OOD, and length OOD generalization in three domains: GridWorld, Arithmetic Factorization, and Image Editing. Key evaluation metrics are self-explainability and transferability, i.e., whether inferred theories generalize when applied to novel inputs generated by the same latent program.
GridWorld
NEO demonstrates robust compositional and length OOD transfer; at τ2 (hardest distributional shift), it achieves transfer scores of 0.933 (compositional OOD) and 0.845 (length OOD), while monolithic baselines fail (score τ3), even for discrete latent action models. Increasing the sampling budget in test-time scaling (NEO-S) yields near-perfect accuracy, indicating that the induced primitives and compositional structure are sufficient for explaining extended and unseen programs.

Figure 3: Test-time scaling: NEO's accuracy improves with sampling budget, outperforming monolithic baselines, and visualizing diverse compositional execution paths.
Arithmetic Factorization Reasoning
NEO achieves compositional transfer superiority (e.g., 0.573 at τ4). In length-OOD scenarios requiring deep factorization (τ5 primitive steps), NEO with test-time search solves tasks (length-OOD accuracy 0.706 at τ6), whereas latent vector baselines remain nearly inert. The strong length extrapolation underscores the model's productivity and the completeness of primitive acquisition.
Image Editing
In the high-dimensional pixel domain, NEO consistently achieves the lowest L1 distance in compositional and length OOD settings (e.g., 0.09–0.12 versus baseline errors >0.17), showing robust programmatic generalization. Visualization reveals explicit sequence explanations for complex transformations, while monolithic models entangle behaviors and fail decomposition.
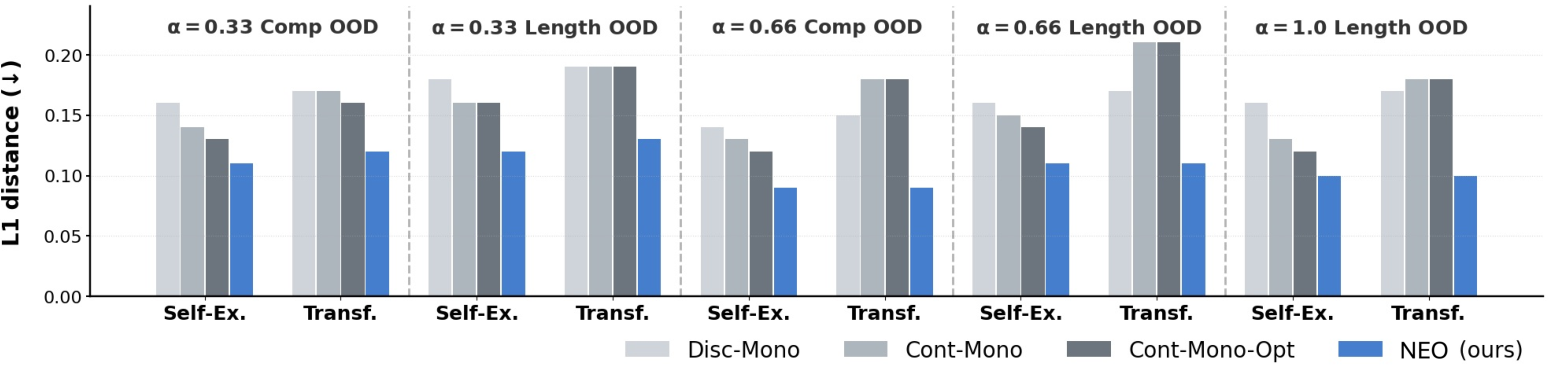
Figure 4: NEO outperforms baselines in image-editing OOD and productivity, with lower τ7 error on both self-explainability and transferability.
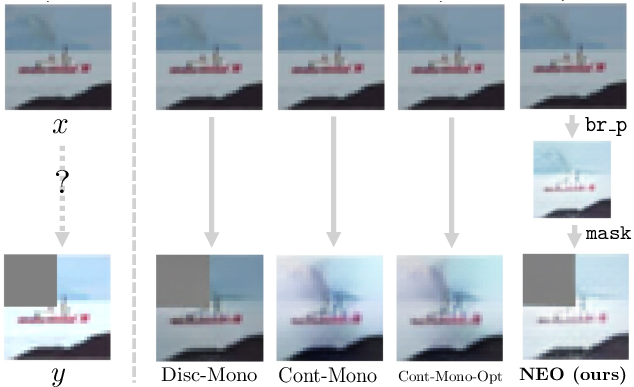
Figure 5: NEO generates explicit compositional explanations for OOD edits (e.g., Down-Paint-Rotate) via reusable primitives; baselines collapse.
Primitive Discovery and Analysis
NEO achieves maximal codebook primitiveness, often exceeding the fraction directly observable in training—a bold empirical claim. When only a partial subset of primitives is present (τ8 low), the model induces missing primitives from compositional evidence, demonstrating nontrivial unsupervised structure discovery.
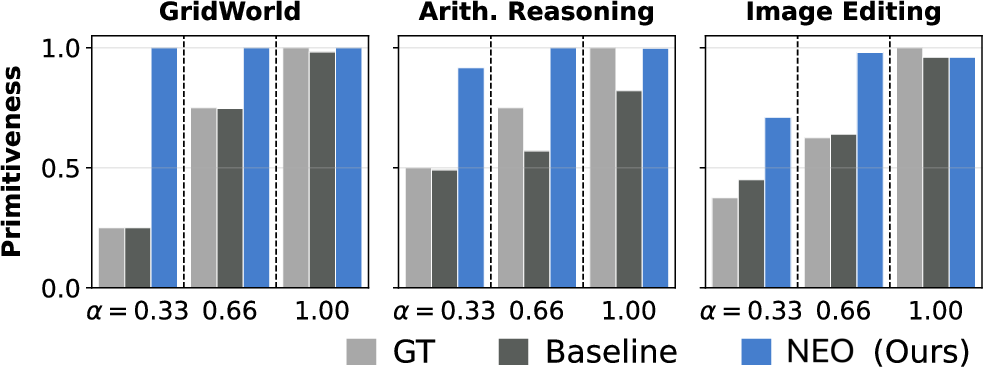
Figure 6: Primitiveness of learned codes: NEO recovers the full primitive set even under partial supervision, surpassing the GT bar.
Adaptive explanation length selection aligns with the ground-truth number of transitions, supporting variable-complexity theories and avoiding horizon overfitting.
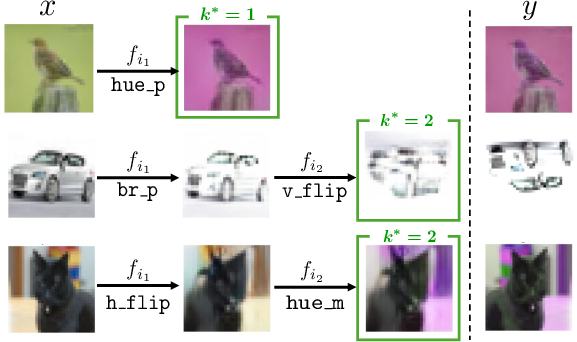
Figure 7: MDL-based program length selection yields explanation lengths matching ground truth—adaptive compositionality.
Ablation and Scalability
State grounding is critical—without it, compositionality collapses to near zero. MDL weight and codebook size control expressivity and simplicity bias; strong MDL penalty leads to entangled memorization, while moderate penalty yields correct primitive-level decomposition.
Test-time scaling via stochastic primitive sampling improves both explainability and transfer, ensuring productivity and systematic generalization across combinatorial unseen tasks.
Implications, Open Problems, and Future Directions
The study provides formal and empirical evidence that explanatory theories—executable programs composed from learned primitives—can be induced directly from raw observation without linguistic supervision, task grouping, or symbolic annotation. This shifts the learning objective from prediction to explanation, promoting interpretability, abstraction, and systematic generalization.
Practical implications include improved OOD robustness, transfer in environments with unseen dynamics, and intervention-capable world models. Theoretically, the approach bridges the gap between neural latent generative modeling and program synthesis perspectives, and introduces productivity and compositionality constraints central to cognitive and symbolic reasoning.
Limitations include scalability to long-horizon, continuous or hierarchical dynamics, interpretability of learned primitives, and brittleness under noise or ambiguity. Extension to open-ended, richly perceptual environments and connection with causal representation learning are future directions. The L2T paradigm and NEO are poised for integration with unsupervised symbolic abstraction, multi-modal learning, and causal discovery frameworks.
Conclusion
"Learning to Theorize the World from Observation" (2605.03413) establishes a new learning paradigm wherein world models acquire explicit, reusable, explanatory structure via latent program induction. The Neural Theorizer achieves explanation-driven compositional generalization, productivity, and strong primitive discovery, providing a foundation for explanatory and intervention-capable AI systems. The study opens avenues for unsupervised theory-building and systematic reasoning in general world modeling, moving beyond prediction-centric architectures.

