- The paper presents a novel framework that dynamically adjusts distillation strength using entropy-aware modulation to tackle catastrophic forgetting in LT-CIL.
- It integrates a time-based scheduler with entropy scaling to balance new class adaptation and knowledge retention, yielding up to 5.0% accuracy improvements over strong baselines.
- The method stabilizes gradient updates at task boundaries through Gradient Consistency Regularization, refining minority class features with minimal computational overhead.
Dynamic Distillation and Gradient Consistency for Robust Long-Tailed Incremental Learning
Long-tailed class-incremental learning (LT-CIL) poses unique challenges at the intersection of continual learning and imbalanced classification. In contrast to standard class-incremental learning (CIL), LT-CIL exacerbates catastrophic forgetting by introducing highly skewed class distributions, causing under-learning of minority classes and overfitting to majority classes. The paper addresses these dual difficulties by reframing the knowledge retention versus plasticity trade-off as a distribution-sensitive optimization, incorporating techniques to explicitly regularize gradient stability and dynamically adapt distillation strength.
Existing approaches for CIL, such as replay buffers or prototype-based storage, are often infeasible under LT-CIL constraints due to their memory and privacy demands. Furthermore, direct application of classical class-imbalance remedies—such as loss reweighting or synthetic oversampling—can lead to increased interference between classes across tasks, exacerbating forgetting. Prior state-of-the-art methods, including Gradient Reweighting (GR), improve minority class learning by dynamically scaling gradients but suffer from instability due to uncompensated gradient shocks when tasks change.
Proposed Methodology
The framework integrates two principal innovations: Gradient Consistency Regularization (GCR) and entropy-aware dynamic distillation.
Entropy-Aware Dynamic Distillation
Knowledge distillation, a standard tool for mitigating forgetting, often accentuates imbalance by disproportionately preserving majority class knowledge. The paper introduces a dynamic distillation coefficient, λ, which is defined as the product of two terms: a time-based scheduler λtime and an entropy-based scaling λentropy. The time-based scheduler smoothly transitions the focus from new class adaptation (early epochs) to knowledge retention (later epochs) within each task using a sigmoid schedule. The entropy-based term uses normalized entropy of the cumulative class distribution to modulate the overall strength of distillation; higher class imbalance suppresses distillation strength, preventing overdominance of majority classes.
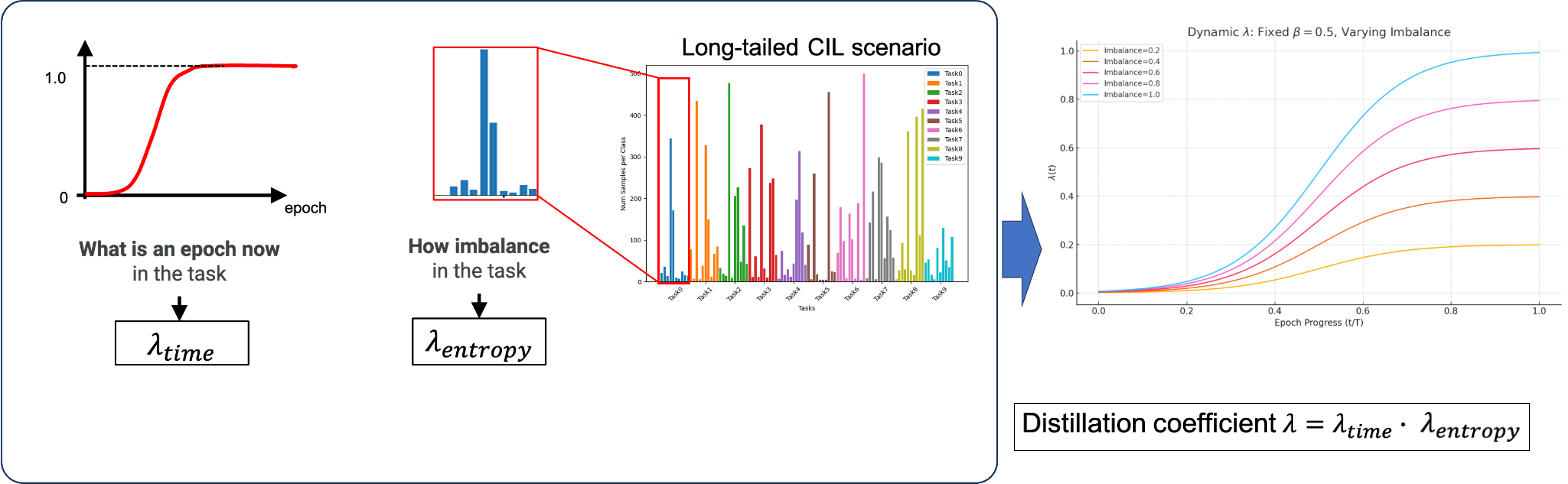
Figure 1: Conceptual diagram of the entropy-aware, dynamic distillation coefficient λ, integrating time-based and entropy-based scheduling to adaptively regulate knowledge retention during incremental training.
This formulation ensures that, under strong class imbalance, distillation does not overwhelm the parameter updates needed for minority class adaptation, enabling distribution-aware plasticity.
Gradient Consistency Regularization (GCR)
To counteract instability inherent to GR, GCR penalizes abrupt deviations of the current gradient from an exponential moving average of historical gradients. At each iteration, the updated gradient gt′ is computed as:
gt′=gt+λGCR(gt−gˉt−1)
with the moving average,
gˉt=βgˉt−1+(1−β)gt
where λGCR and β are hyperparameters. This regularization smooths transitions at task boundaries, leading to stable representation updates crucial for minority class feature refinement.
Experimental Protocol
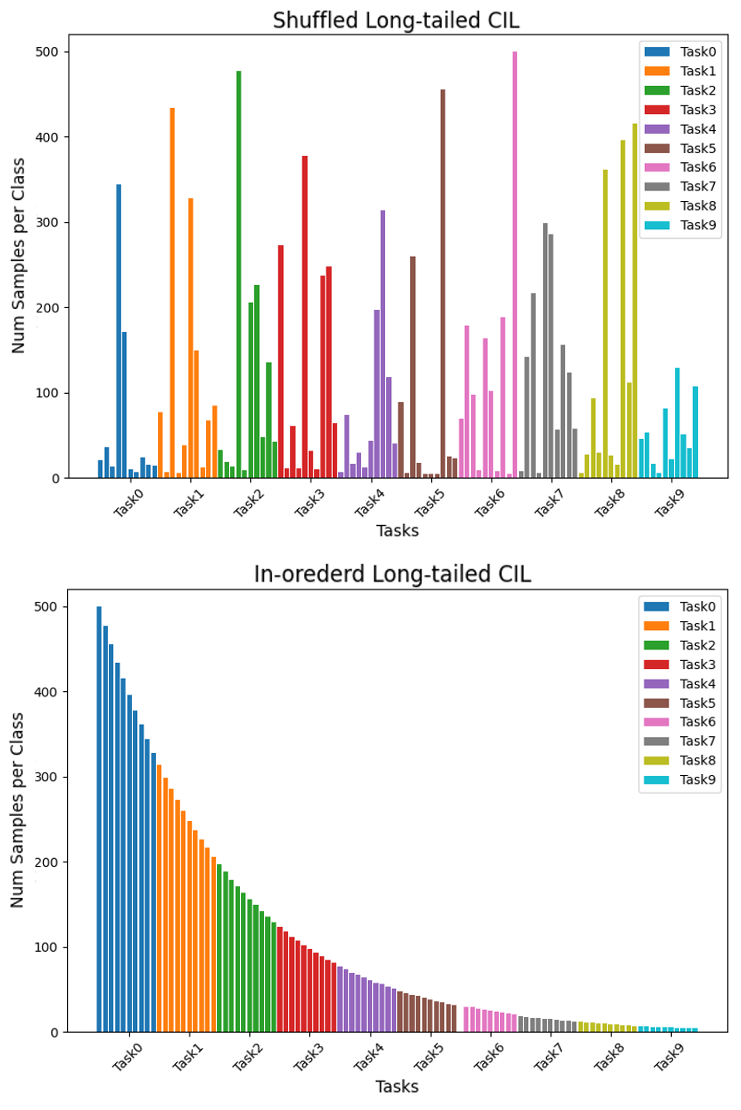
Empirical validation is conducted on CIFAR-100-LT, ImageNetSubset-LT, and Food101-LT, using severe imbalance ratios (up to 100:1) and incremental acquisition of 10 or 20 tasks, with balanced test splits for unbiased evaluation. The methodology is assessed under two class orderings:
Both "From Scratch" (random initialization) and "From Half" (pretraining on a subset) protocols are tested. Baselines include iCaRL and PODNet, with and without integration of the new framework, and GR.
Results and Analysis
The proposed framework consistently achieves relative improvements of up to 5.0% accuracy over strong baselines across datasets and protocols, with the most significant gains in In-ordered LT-CIL. The integration with GR (GR+Ours) yields the highest absolute improvements, particularly on minority groups, directly validating the distribution-aware distillation and gradient stabilization effect.
Ablation studies demonstrate the effect of dynamic distillation scheduling. Entropy-aware modulation of the distillation coefficient significantly enhances learning in scenarios with heightened class skew, outperforming fixed or purely temporal scheduling.
Gradient norm analysis reveals that the proposed method reduces the amplitude and abruptness of gradient changes at task boundaries, especially when new classes are first introduced—indicative of improved optimization stability.
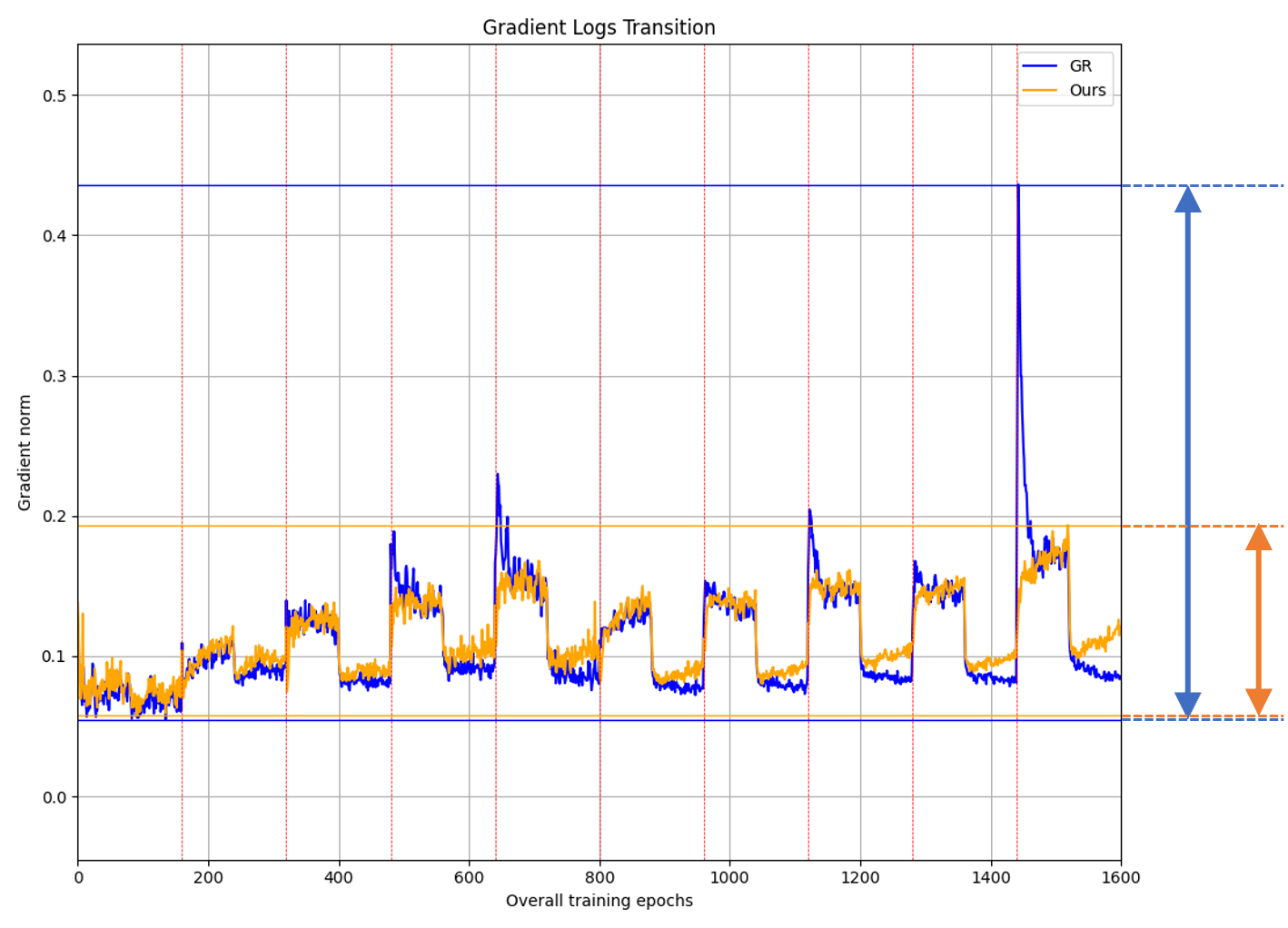
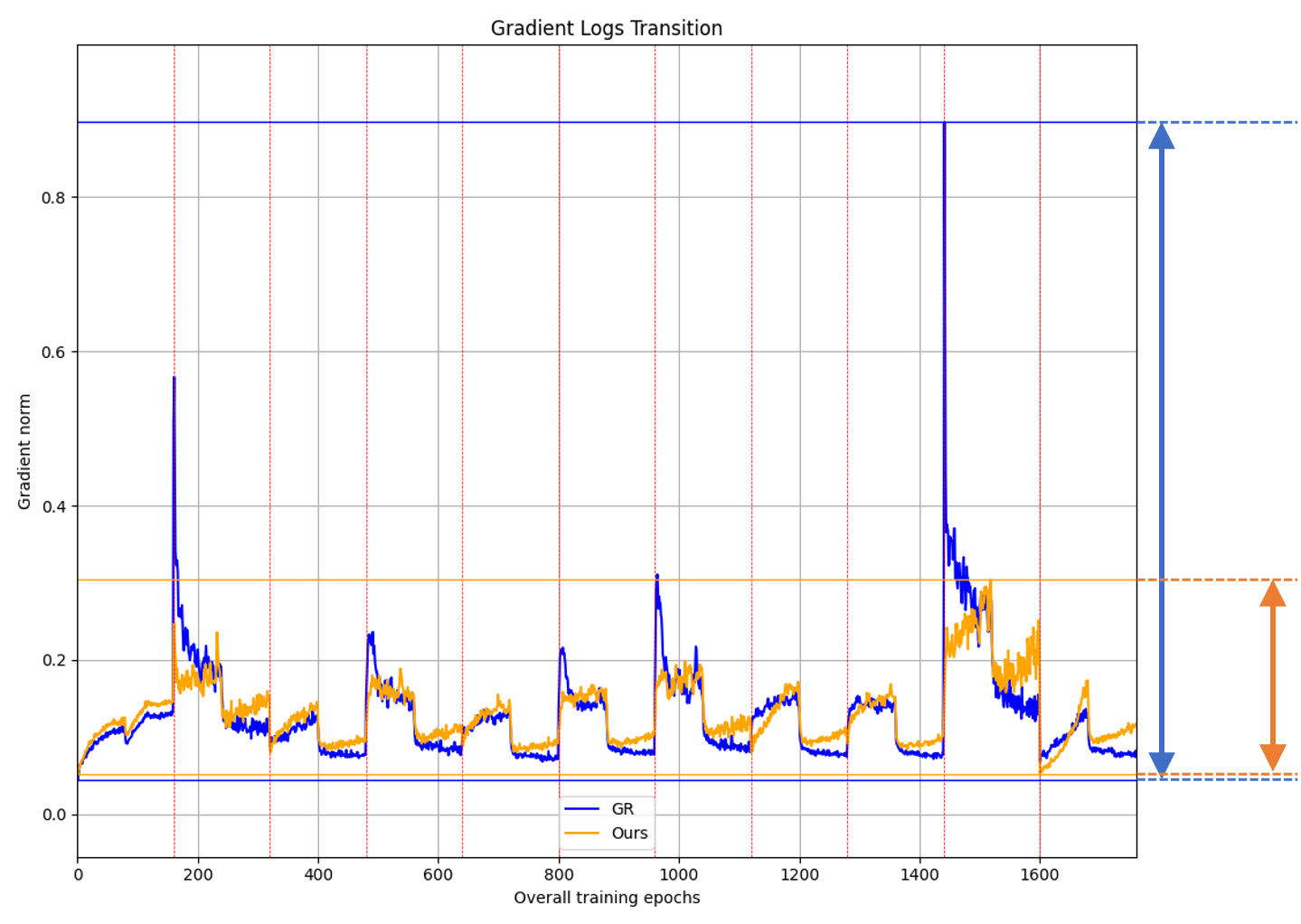
Figure 3: Training evolution of average gradient norms, showing that gradient consistency regularization (orange) suppresses spikes at incremental task transitions relative to the standard GR baseline (blue), implying improved optimization smoothness and feature retention.
Efficiency benchmarks confirm that the method adds negligible computational overhead (1.3% training time increase, no inference penalty) and does not require access to stored data between tasks.
Implications and Future Directions
The dissociation of distillation strength from fixed scheduling to a distributionally adaptive rule allows for robust performance under extreme task and class imbalance, advancing LT-CIL towards more realistic and stringent deployment scenarios. Stabilizing gradients via GCR is particularly impactful for minority class retention, addressing a primary pain-point for real-world continual learning systems.
Potential future work includes automatic adjustment of GCR hyperparameters, integration with transformer-based backbones, and extension of entropy-aware loss modulation to other forms of self-regularization in incremental learning. The paper’s results suggest that distribution- and history-aware loss reweighting mechanisms are decisive in overcoming the glass ceiling observed in prior LT-CIL approaches.
Conclusion
The study systematically addresses the intersection of catastrophic forgetting and class imbalance in long-tailed class-incremental learning. By coupling entropy-aware distillation with gradient consistency regularization, it provides a scalable and computation-efficient framework that achieves strong, stable performance across several challenging benchmarks, particularly enhancing accuracy on minority classes without external replay or complex memory footprints (2605.03364).