- The paper meticulously quantifies the hidden energy, carbon, and water costs in LM development and post-training, highlighting substantial environmental impacts.
- It employs refined datacenter energy attribution and sub-second stage-wise measurements, revealing that 82% of compute is dedicated to experimentation and failed runs.
- The study underscores practical implications for infrastructure and policy, advocating for comprehensive reporting standards and greener AI development practices.
Comprehensive Analysis of the Hidden Environmental Cost in LLM Development
Overview and Motivation
The paper addresses a critical gap in environmental accounting for large LMs, specifically the overlooked costs of development and post-training. Traditional reporting practices in AI focus nearly exclusively on the energy, carbon, and water footprints of final model pretraining runs. However, modern LLM pipelines encompass a far broader suite of stages—mid-training, long-context expansion, synthetic data creation, supervised fine-tuning (SFT), direct preference optimization (DPO), and reinforcement learning with verifiable rewards (RLVR)—each of which demands extensive experimentation and computation. By providing the first detailed breakdown of these costs for the Olmo 3 model series, including both instruction-following and reasoning variants at 7B and 32B parameters, the paper quantifies the environmental impacts that most reporting omits.
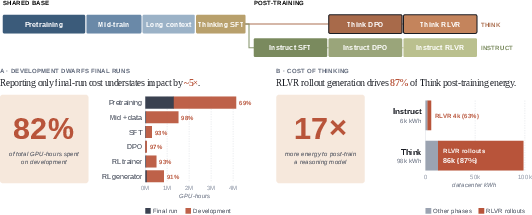
Figure 1: Total GPU-hours for Olmo 3 development and post-training, highlighting that 82% of compute is attributed to experimentation and failed runs, and that reasoning model post-training is approximately 17× more energy-intensive than instruction-tuned post-training.
Methodological Advancements
The paper’s methodology builds upon and extends previous environmental impact analytic frameworks by:
- Refined Datacenter Energy Attribution: Incorporating a 1.74× overhead multiplier to account for non-GPU hardware, network, and ancillary IT infrastructure, providing a more accurate estimate of total datacenter power draw compared to previous GPU-only calculations.
- Direct Stage-wise Measurement: Evaluating energy, CO2 emission, and water consumption at sub-second granularity, segmented across all pipeline phases.
- Comprehensive Hardware Coverage: Distinguishing impacts from both NVIDIA H100-80GB (for training and post-training) and AMD MI250X (for synthetic data generation on the Frontier supercomputer), including adjusted per-GPU-hour power ratings.
- Holistic Embodied Emissions Estimation: Amortizing hardware manufacturing emissions and water consumption over a four-year lifecycle.
This enables robust cross-stage comparison and evaluation of environmental drivers.
Key Findings
Post-Training Costs Are Substantial and Rapidly Rising
A central numerical result is the dramatic escalation in environmental impact during post-training, especially for reasoning models. Olmo 3 32B Think’s post-training (dominated by RLVR) required 17× the datacenter energy compared to its instruction-tuned sibling (98,464 vs. 5,659 DC~kWh), driven chiefly by RLVR rollout generation which itself accounted for 87% of total Think-specific post-training energy.
- Token Volume Disparity: Olmo 3 32B Think’s RLVR processed ∼18.7B tokens, 33× more than 564M for 32B Instruct, reflecting both longer reasoning trajectories and greater training demand.
- Compute Bottleneck: The RLVR generator, essentially analogous to inference at scale, operated at ∼600W per GPU and outpaced the RLVR trainer 8× in wall-clock consumption, despite the latter being highly optimized for throughput and batching.
Development Costs Dominate Pipeline Consumption
Experimentation and development—including hyperparameter sweeps, failed runs, ablations, and data mixture exploration—constituted 82.2% of total GPU hours (6.85M out of 8.34M), a substantial increase from the ∼50\% previously observed in pretraining-centric pipelines.
- Stage-wise Iteration: Post-training stages (SFT, DPO, RLVR) saw development fractions exceeding 91%, with mid-training and data mixing reaching 97.5%.
- Corroborating Financial Analyses: These results concur with independent financial disclosures from prominent AI companies, where final training runs represent only 10–23% of R&D compute expenditures.
Aggregate Impact: Energy, Carbon, and Water Consumption
The entire development pipeline for Olmo 3 (excluding inference) consumed ∼12.3~GWh of datacenter energy, emitted 4,251~tCO1.74×0eq, and used 15,887~kL of water. Notably, water consumption was dominated not by datacenter cooling but by power generation (thermo- and hydro-electric infrastructure), emphasizing that infrastructure choices largely determine environmental footprint.
Implications and Recommendations
Practical Infrastructure and Policy Impacts
- Reporting Standards: The paper recommends mandatory reporting of full pipeline environmental costs, with breakdowns at each stage (pretraining, post-training, development, synthetic data generation), and inclusion of datacenter efficiency metrics (PUE, WUE, energy mix).
- Infrastructure Focus: Water consumption attribution should shift from AI workloads to the infrastructural sources—power generation and cooling systems—encouraging transitions to closed-loop cooling and low-water-intensity energy (e.g., wind, solar).
- Manufacturer Accountability: Calls for GPU manufacturers to release precise embodied emissions and water consumption data, enabling accurate lifecycle assessments.
Theoretical and Research Consequences
- Model Development Trajectory: As LLM pipelines grow more sophisticated, particularly for agentic and tool-augmented models producing long outputs, both post-training and development cost fractions will likely continue to rise, challenging the efficacy of current environmental mitigation practices.
- Experimentation Automation: Emerging frameworks leveraging LLMs for automated recipe search and hyperparameter optimization may exacerbate experimentation-driven environmental costs, underscoring the urgency for research in sustainable exploration strategies.
- Deployment Impact: The paradigm of RL-based post-training is structurally similar to inference; thus, the environmental footprint of large-scale reasoning deployments can be inferred from RLVR rollout statistics.
Speculations on Future Developments
- Pipeline Transparency: Expect regulatory and community-driven shifts towards mandatory stage-wise environmental reporting for published models.
- Optimization Research: Increased focus on minimizing development and post-training compute through effective experiment design, adaptive data curation, and token-efficient RL generation, especially for reasoning models.
- Infrastructure Innovation: Accelerated adoption of water-neutral datacenter technologies and decarbonized power sources will become an essential factor in AI sustainability narratives.
- Lifecycle Impact Analysis: Interdisciplinary collaborations between AI, environmental science, and economics are likely to develop robust frameworks for integrated lifecycle impact assessment, encompassing both operation and hardware manufacturing.
Conclusion
The paper provides the first detailed accounting of the environmental cost of developing contemporary LMs, conclusively demonstrating that development and post-training—especially for reasoning and RL-optimized models—constitute the vast majority of compute, energy, carbon, and water footprint. By systematically quantifying these hidden costs and analyzing their infrastructural determinants, the work sets a new standard for transparency and rigor, directly informing both applied policy and theoretical research on sustainable AI development.

