- The paper demonstrates that integrating local with global attention unlocks richer logical fragments, enabling recognition of locally testable languages.
- The paper employs formal language theory, using LTL and automata-theoretic methods, to precisely delineate the roles of local, global, and hybrid attention.
- The paper shows that hybrid models with 1-local heads outperform pure local or global schemes, guiding practical transformer architecture design.
Introduction
The paper "Characterizing the Expressivity of Local Attention in Transformers" (2605.00768) provides an in-depth theoretical and empirical analysis of the role of local attention in transformer architectures, focusing specifically on its impact on the class of regular languages that can be recognized under fixed-precision computation. Existing literature establishes that global (full-sequence) attention corresponds to a certain fragment of Linear Temporal Logic (LTL) involving a single past operator. This work sharpens that picture by showing that the addition of local attention confers access to strictly richer logical fragments, making global and local attention expressively complementary. It further demonstrates, through formal language modeling and empirical experiments, the precise regimes where local, global, and hybrid attention patterns are necessary and sufficient to recognize various subclasses of regular languages, and evaluates these findings on synthetic and natural data.
Theoretical Expressivity Analysis
Logical Characterization
The authors ground their analysis in formal language theory and logic, exploiting LTL to capture what transformers with various attention patterns can (and cannot) represent. Specifically:
- Global Attention: Fixed-precision transformers with global attention are shown to characterize the logic fragment PTL (Past-time Temporal Logic with the past operator), aligning with left-deterministic regular polynomials as previously identified by [li2025].
- Local Attention: Restricting transformers to k-local attention aligns them with the fragment YTL[k], expressively equivalent to definite languages (i.e., those determined by bounded-length suffixes) for any fixed window size k. Increasing this window size, however, does not monotonically increase expressivity: 1-local attention is maximally expressive within the local family under unbounded computational depth.
- Hybrid Attention: Mixing global and local attention produces a strictly larger class, corresponding to the YPTL[k] logical fragment, which encompasses all locally testable languages—a well-studied class not accessible by either global or local attention patterns alone.
These relationships are made precise via algebraic (syntactic monoid) and automata-theoretic characterizations. The authors show that PTL and YTL are incomparable: there exist languages recognized by one but not the other, and their union is strictly weaker than the class defined by hybrid attention. For example, a language requiring access to the first token (a classic PTL task) cannot be recognized with bounded local attention, and a language checking the last token's identity (a definite language) cannot be recognized with global-only attention.
Empirical Consequences
One central corollary is that attention patterns fundamentally alter the types of compositional computations transformers can realize. In particular, the addition of local attention introduces recognition capability for locally testable languages and certain forms of bounded-memory computation, which have previously resisted implementation via global-attention transformers under finite-precision constraints.
Empirical Evaluation
The theoretical results are validated through a comprehensive suite of synthetic language recognition and generalization tasks, designed to probe expressivity across logical fragments.
The experiments deploy transformers with three attention modes: local, global, and hybrid (where heads are split between local and global masks), and systematically vary the local window size and positional encoding schemes (learned, sinusoidal, rotary). Performance is evaluated both as accuracy and as the longest input length for which the model achieves perfect generalization.
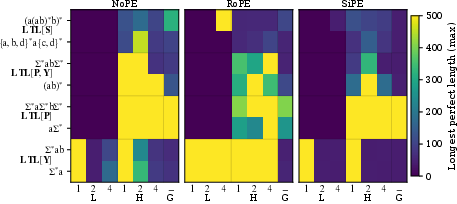
Figure 1: Maximum perfect generalization lengths across formal languages, attention types, and window sizes. Hybrid attention—especially with k=1—outperforms other modes on the broadest range of languages.
- Local-only models only generalize reliably to definite (suffix-determined) languages.
- Global-only models generalize to left-deterministic polynomials (i.e., the languages captured by PTL).
- Hybrid models correctly generalize to all locally testable languages, strictly subsuming the capabilities of the previous two.
Strong empirical evidence confirms the theoretical prediction that a single-step local (k0) attention head, when available in combination with global heads, maximizes expressivity.
Effect of Window Size and Positional Encoding
The superiority of k1 local attention is robust, with increasing window size often degrading perfect generalization in the absence of sufficiently expressive positional encodings. When positional encodings are added, certain patterns (e.g., rotary with rational frequencies) may partially close the gap between different window sizes, but do not negate the hybrid attention advantage.
Natural Language Modeling
Next-token prediction is evaluated on WikiText-2 using GPT-2-scale models, holding all architectural and optimization variables constant except the attention pattern and window size.
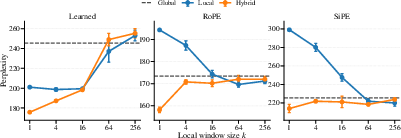
Figure 2: Perplexity curves on WikiText-2 for local, hybrid, and global attention under different positional encodings. The hybrid model with k2 consistently achieves the lowest perplexity.
Key observations:
- Hybrid attention with k3 consistently achieves the lowest perplexity, outperforming both global-only and local-only baselines.
- Increasing the local window size reduces performance, and sufficiently large windows can even be detrimental relative to the global-only case.
- In practice, local-only models sometimes outperform global-only ones, reflecting the formal incomparability of their expressivities.
- The effect of positional encoding on the advantage of local attention is nuanced and depends on both window size and encoding type.
Implications and Future Directions
The results establish that efficiency-motivated modifications to the transformer architecture—namely, the inclusion of local attention—have substantive theoretical and practical ramifications for the class of sequence computations that can be learned. This sheds light on the previously counterintuitive empirical observation that local/hybrid attention often improves model quality, even when total computation is matched.
The findings have immediate applications in transformer architecture design, suggesting that hybrid global-local attention with k4 should be a default design for models where expressivity matters and positional encodings may not fully compensate. The work cautions, however, that fixed-depth transformers or the presence of rich enough positional encodings can modulate these effects, indicating fruitful directions for investigating the interplay between architectural constraints, positional information, and learnability in sequence models.
From a theoretical perspective, the logical/automata-theoretic framework presented opens avenues for further refinement in characterizing the boundaries of transformer expressivity, especially under more realistic computational assumptions or in the context of hierarchical language classes.
Conclusion
This paper rigorously establishes—and empirically substantiates—that local and global attention impart fundamentally complementary forms of expressivity in transformer architectures operating at fixed precision. Hybrid global-local attention, particularly with 1-local heads, strictly expands the set of regular languages recognizable, capturing the class of locally testable languages and outperforming purely global or local configurations. The implications extend both to our conceptual understanding of neural sequence models and to practical recommendations for transformer architecture design in future AI systems.

