- The paper introduces a decision-theoretic framework that distinguishes between true and perceived tool calling need and utility in LLMs.
- The framework demonstrates that optimal policies can significantly improve factuality while reducing unnecessary or costly tool calls.
- Latent-state-driven controllers are shown to enhance calibration and enable cost-sensitive management of tool usage.
Introduction and Theoretical Framework
The integration of tool calling into LLMs has become a defining feature of modern agentic AI architectures. Tool calls, such as external web search APIs, augment a model’s parametric knowledge with up-to-date or otherwise inaccessible information, offering substantial improvements in certain scenarios. However, indiscriminate or poorly managed tool invocation can lead to redundancy, degraded task performance, or excessive costs. The central challenge is optimizing the decision policy regarding when and whether to initiate a tool call for a given task input.
"To Call or Not to Call: A Framework to Assess and Optimize LLM Tool Calling" (2605.00737) proposes a mathematically grounded, decision-theoretic framework for analyzing, assessing, and ultimately optimizing LLM tool calling. This framework decomposes tool-use decisions into three operational dimensions: necessity (does the task instance require a tool?), utility (will a tool call improve performance?), and affordability (is the tool call justified given cost constraints?). The approach leverages three analytical lenses: a normative (oracle/optimal) perspective, a descriptive (model-behavioral) perspective, and a prescriptive (controller-driven) perspective. Through systematic experimentation across six open LLMs and three representative tasks, the work elucidates consistent gaps and misalignments in current tool-calling policies and offers latent-state-based controllers as a partial remedy.
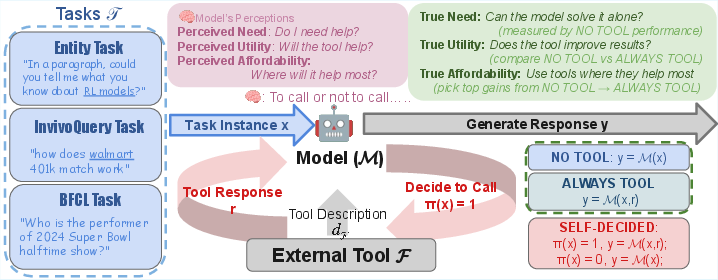
Figure 1: Given input x, the model M decides π(x)∈{0,1} to call a tool (response r) or not, producing y=M(x,r) or y=M(x). The comparison spans NO TOOL, ALWAYS TOOL, and SELF-DECISION, evaluated via need, utility, and affordability, and distinguishes perceived vs.\ true metrics.
The framework’s crux is a separation between true and perceived necessity/utility/affordability:
- True Need (N∗(x)): Binary; is self-predicted model quality for input x below a threshold when no tool is used.
- True Utility (U∗(x)): Ternary; is factuality increased, unchanged, or degraded by the tool call relative to the no-tool baseline.
- True Affordability: Given a call budget, selects the k highest-utility instances.
- Perceived Need/Utility: Elicited via model’s own self-reporting/prompted behavior under no-tool or self-decision setups.
- Perceived Affordability: Actual allocation of calls under explicit or implicit cost prompts.
This decomposition enables a direct quantification of suboptimal tool calling in existing LLM policies: most models demonstrate substantial misalignment between their perceived need/utility and the true benefit measured by factuality improvement. Tool calls on instances where the model has sufficient internal knowledge are frequently wasteful or actively detrimental (negative utility), and current models also fail to regulate tool use according to specified cost constraints.
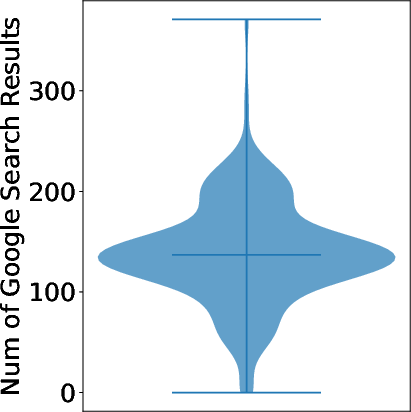
Figure 2: Distribution of Google search results for entity tasks, highlighting the prevalence of long-tail queries with limited web coverage.
Experiments span six open models (3B–120B parameters, with both instruct and reasoning tuning) on three representative tasks: open-ended entity-centric QA, real-world factual queries (InvivoQuery), and atomic function-calling benchmarks (BFCL). Main findings include:
- Tool Calling Is Not Universally Beneficial: Across tasks and models, positive utility from tool calls strongly correlates with true need but, critically, is absent or even negative in other regimes. Figure 1 demonstrates that optimal policies achieve significant improvements in factuality with far fewer tool calls than either always-calling or self-decided strategies.
- Misalignment Between Perceived and True Need/Utility: As illustrated by Venn diagrams and confusion matrices, practical model decision policies deviate starkly from the normative oracle: many tool calls are either unnecessary or omitted when actually needed.

Figure 3: [Entity Task] Venn diagrams highlight the empirically observed misalignment between True Positive Utility (actual benefit), Perceived Need, and Perceived Utility across LLMs, illustrating failure to achieve the desired nested relationship.
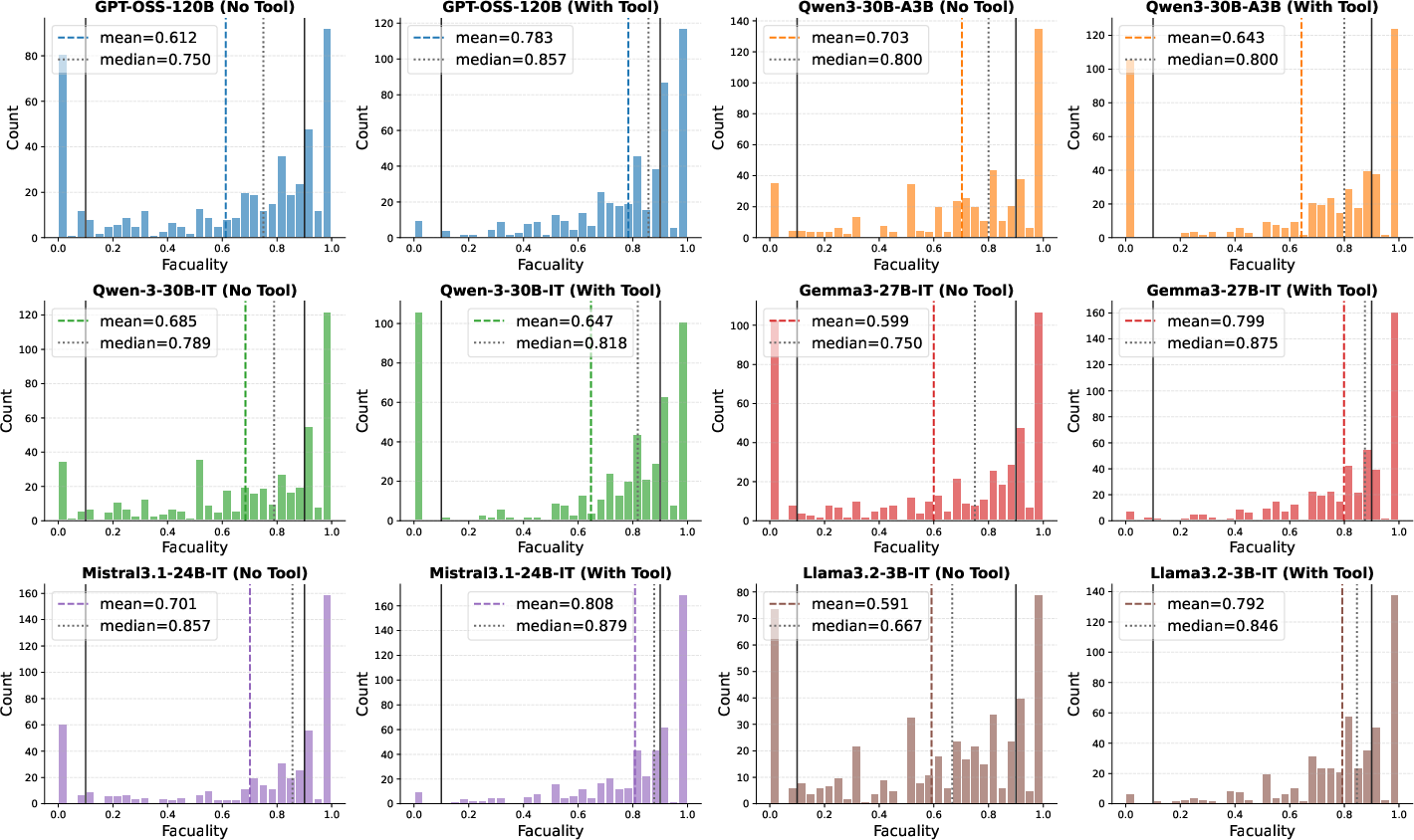
Figure 4: Entity Task: Distribution of factuality scores across different models, evidencing variance in tool-use benefit and calibration.
A critical operational dimension, affordability, exposes further weakness in LLM tool-use policies. Under both explicit and implicit cost prompts, models fail to reduce tool calls as per-call cost rises, leading to budget overruns and suboptimal utility/cost tradeoffs.
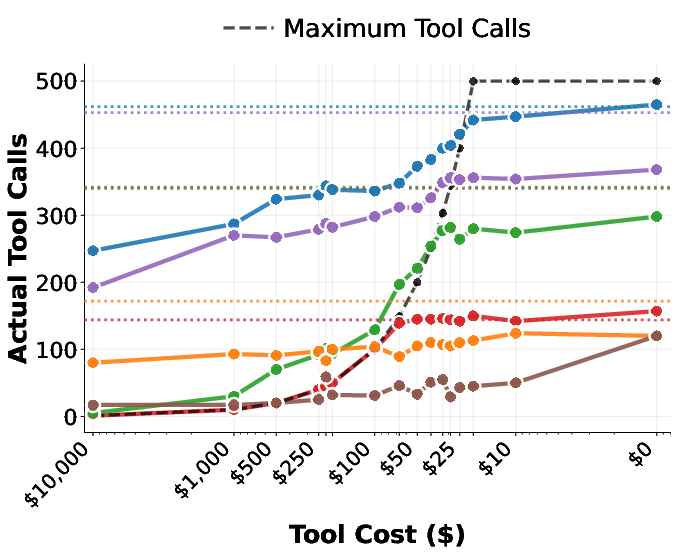
Figure 5: Actual tool use under budget enforcement; models do not reliably reduce or halt tool calls as costs increase, despite explicit cost and budget prompts.
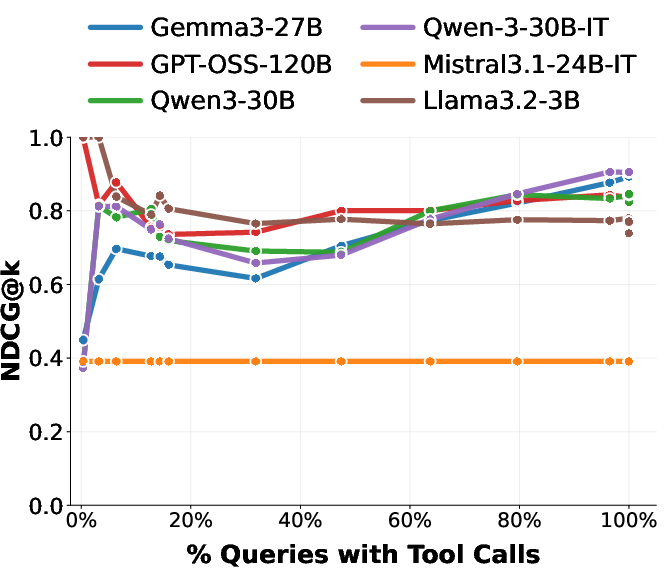
Figure 6: NDCG rank correlation for budget-constrained tool call allocation; low correlation values reflect poor selection of highest-utility tool calls.
Latent Prediction of Need and Utility: Controller Framework
To close the gap between descriptive and normative policies, the paper introduces two lightweight, supervised classifiers over internal model representations (latent states): the Latent Need Estimator (LNE) and Latent Utility Estimator (LUE). Trained as MLPs over hidden states (no model finetuning required), these estimators more accurately predict true need and true utility than the model’s natural language outputs or self-perception, especially for weaker models.
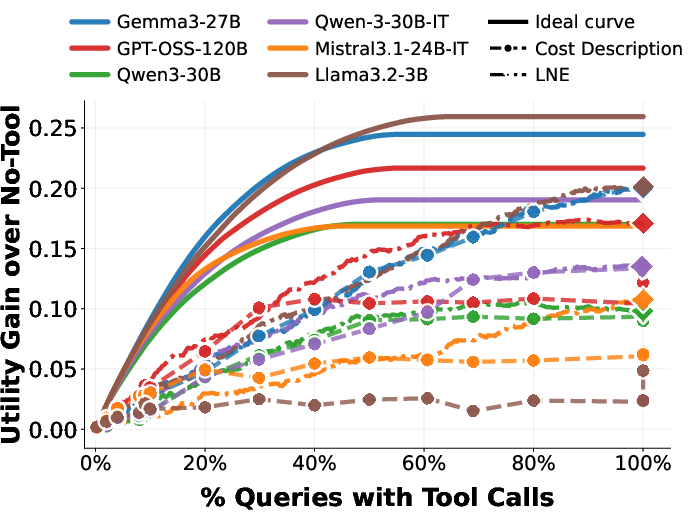
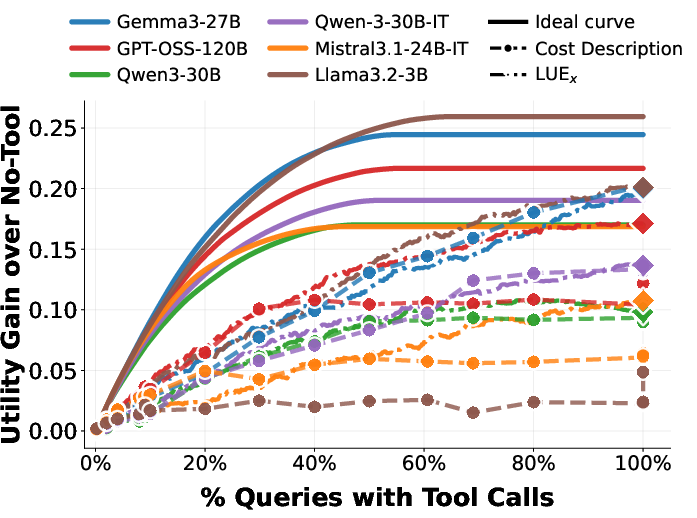
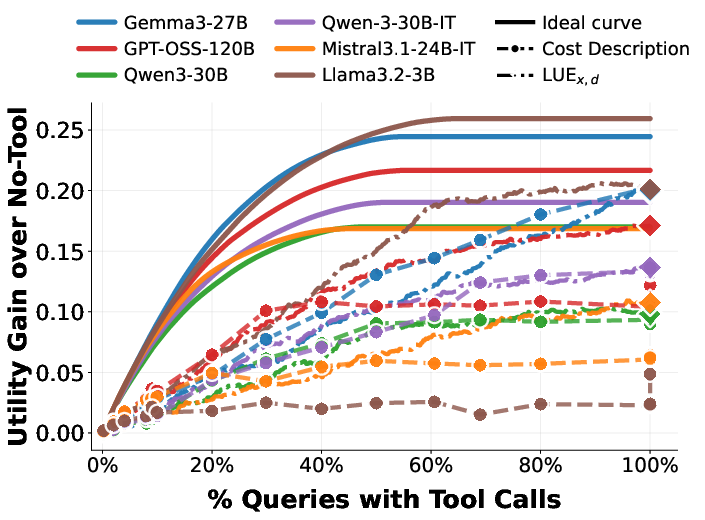
Figure 7: LNE accuracy is significantly higher than explicit model decisions, particularly for smaller LLMs; see confusion matrices for detailed breakdown.
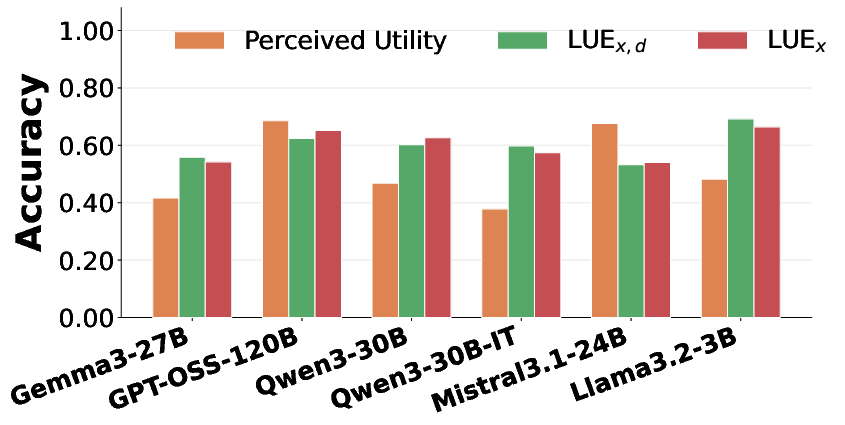
Figure 8: LUE can predict true utility more reliably across most models, demonstrating improved calibration versus self-decided policies.
Latent estimators enable externally controlled, budget-constrained tool-calling policies that yield higher factuality and fewer wasted calls under fixed cost limits. However, even with these estimators, optimality is limited by the difficulty of modeling tool behavior and contextualized tool utility.
Implications, Limitations, and Future Outlook
This work establishes a rigorous methodology for analyzing and improving LLM tool-calling decisions. Notably, it demonstrates that model-internal representations encode reliable signals for need and utility prediction—signals that current prompting setups do not successfully externalize or utilize. The main practical implication is that tool-use control should be offloaded to specialized, latent-state-driven controllers rather than delegated to the LLM’s own self-reflective decision process.
Model-agnostic controllers leveraging latent states open the path toward broader, safer, and more cost-effective tool-augmented AI systems. However, this approach still falls short of normative optimality: perfect allocation would require accurate forward modeling of tool outcomes, which is an open challenge given the non-determinism and noise in external APIs such as web search. Improved tool descriptions, more robust estimation of downstream benefit, and dynamic controller architectures are all promising directions.
From a theoretical perspective, the clear separation between necessity and utility, and between models’ epistemic self-knowledge and their decision policies, has foundational relevance for reinforcement learning, rational metareasoning, and cost-sensitive agent design.
Conclusion
The framework presented in this work offers a principled, experimentally validated path to dissect and remedy failures in LLM tool-use policy. By distinguishing true and perceived need, utility, and affordability, and by demonstrating the promise of latent-state-driven external controllers, the study provides both a diagnostic toolkit and concrete technical advancements. Effective and efficient tool-augmented AI agents will require continued advances in introspective uncertainty estimation, accurate modeling of tool impact, and robust controller integration to approach normative optimal performance.