- The paper demonstrates that dual-head hierarchical supervision yields more structured latent representations, significantly improving both OA and KL grading, especially for the ResNet3D backbone.
- The methodology compares three 3D architectures in single-task versus dual-head settings, revealing that joint training can raise key metrics like KL macro-AUC, accuracy, and macro-F1 against noisy KL labels.
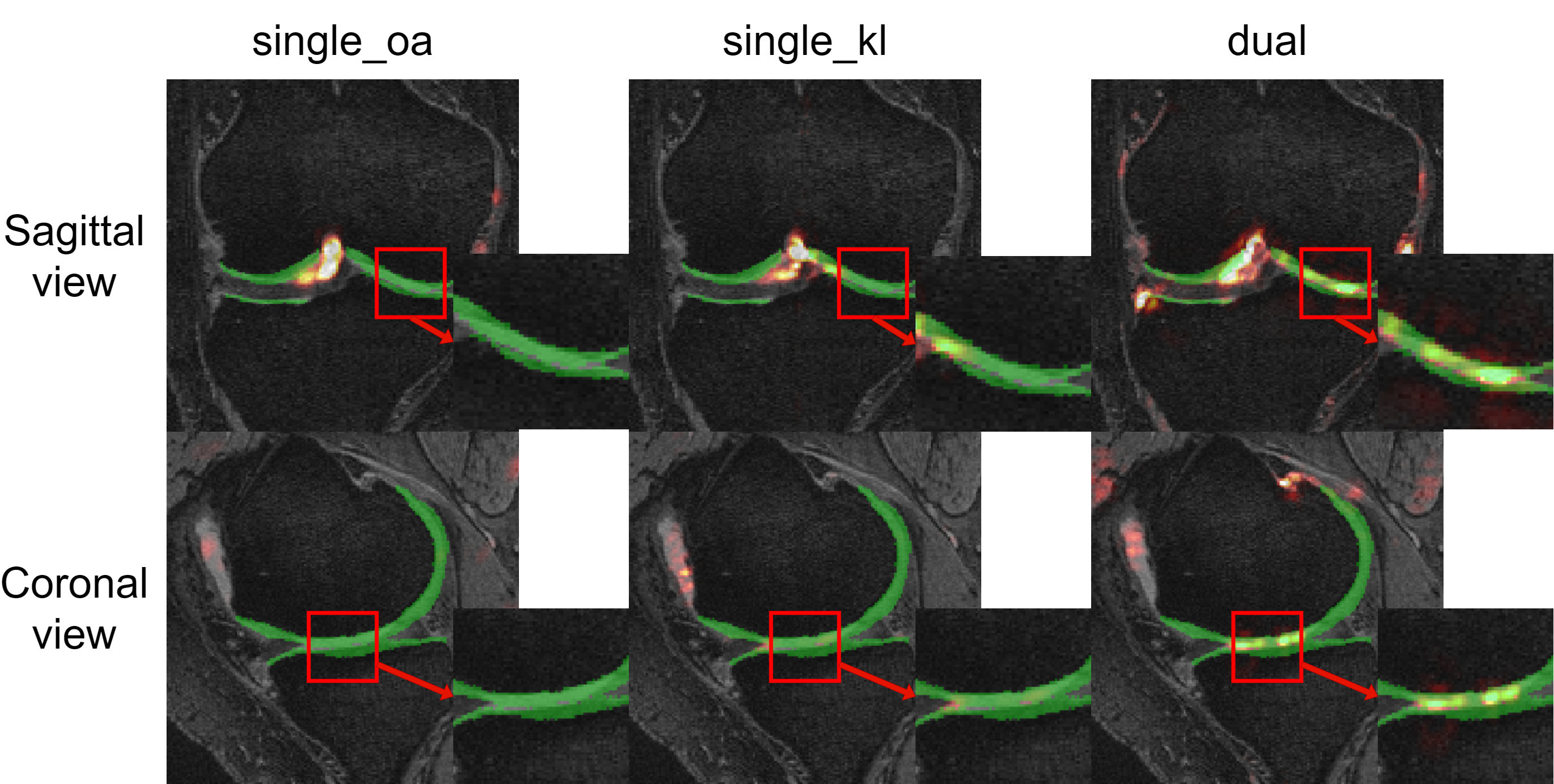
- Enhanced anatomical attribution is achieved with dual-head models, as saliency maps indicate a reallocation of focus to cartilage regions, supporting more clinically interpretable predictions.
Hierarchical Supervision Reshapes Latent Representations for Knee Osteoarthritis Assessment
Motivation and Problem Setting
The assessment of knee osteoarthritis (OA) in clinical imaging presents a naturally hierarchical target space—consisting of a coarse binary label (OA: present/absent) and a fine-grained ordinal severity label, the Kellgren–Lawrence (KL) grade (0–4). Traditionally, most deep learning models treat these as independent classification problems, optimizing either OA presence or KL severity without capitalizing on their hierarchical dependency. This approach disregards the complementary and hierarchical information inherent in clinical protocols: the binary OA diagnosis is relatively stable, whereas KL grading is finer but highly noisy due to subjectivity and inter-reader variability.
The core hypothesis investigated is whether joint hierarchical supervision—implemented by a simple dual-head architecture yielding both OA and KL predictions—can induce more structured, clinically meaningful latent representations, and whether these effects are dependent on backbone neural architecture.
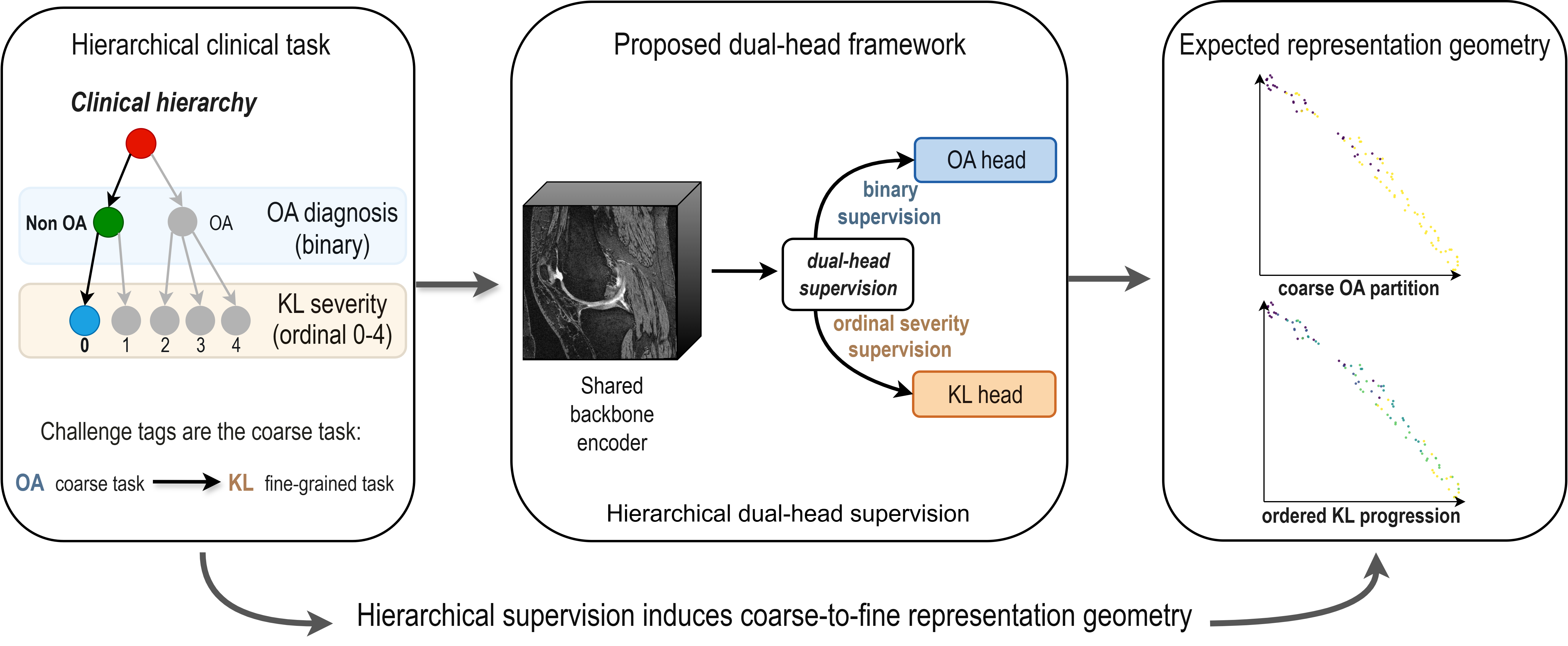
Figure 1: Coarse-to-fine label hierarchy for OA assessment and a dual-head setup to probe its effect on the learned representation and anatomical attribution.
Methodology
The study employs three 3D backbone architectures: ResNet3D, M3T (multi-plane transformer), and nnMamba (state-space model), each instantiated in three variants:
- Single-OA: Trained for binary OA classification.
- Single-KL: Trained solely for 5-class KL grading.
- Dual-head: Joint training with separate OA and KL heads from a shared encoder, leveraging the hierarchical relation (OA=I(KL≥2)).
Models are trained and evaluated on the OAI-ZIB-CM knee MRI dataset with strict pre-defined train/test splits and identical protocols across backbones. Performance is assessed by standard metrics (AUC, accuracy, macro-F1), but the primary analytical thrust lies in representation geometry and anatomical attribution:
- Latent axis analysis: Principal component analysis (PCA) of penultimate-layer features, focusing on the organization and monotonicity of severity ordering.
- Saliency–cartilage overlap: Quantification of attribution in cartilage regions using several mass and Dice metrics.
Paired statistical tests (McNemar’s for binary OA, bootstrapped CI/p-values for others) evaluate gains relative to matched single-task baselines.
Numerical Results and Backbone Dependence
Dual-head supervision yields strongly backbone-dependent effects. Most notably, the ResNet3D backbone demonstrates clear and statistically significant improvements: KL macro-AUC increases by Δ=0.1195 (p=0.004), accuracy by Δ=0.2149 (p<0.001), and macro-F1 by Δ=0.2071 (p<0.001) vs. the single-KL baseline. M3T benefits are more moderate, with significant increases in OA AUC and KL macro-AUC/ macro-F1, but effects are reduced compared to ResNet3D. For nnMamba, dual supervision provides minimal or negative gains; the architecture appears less able to harness the benefits of hierarchical signal.
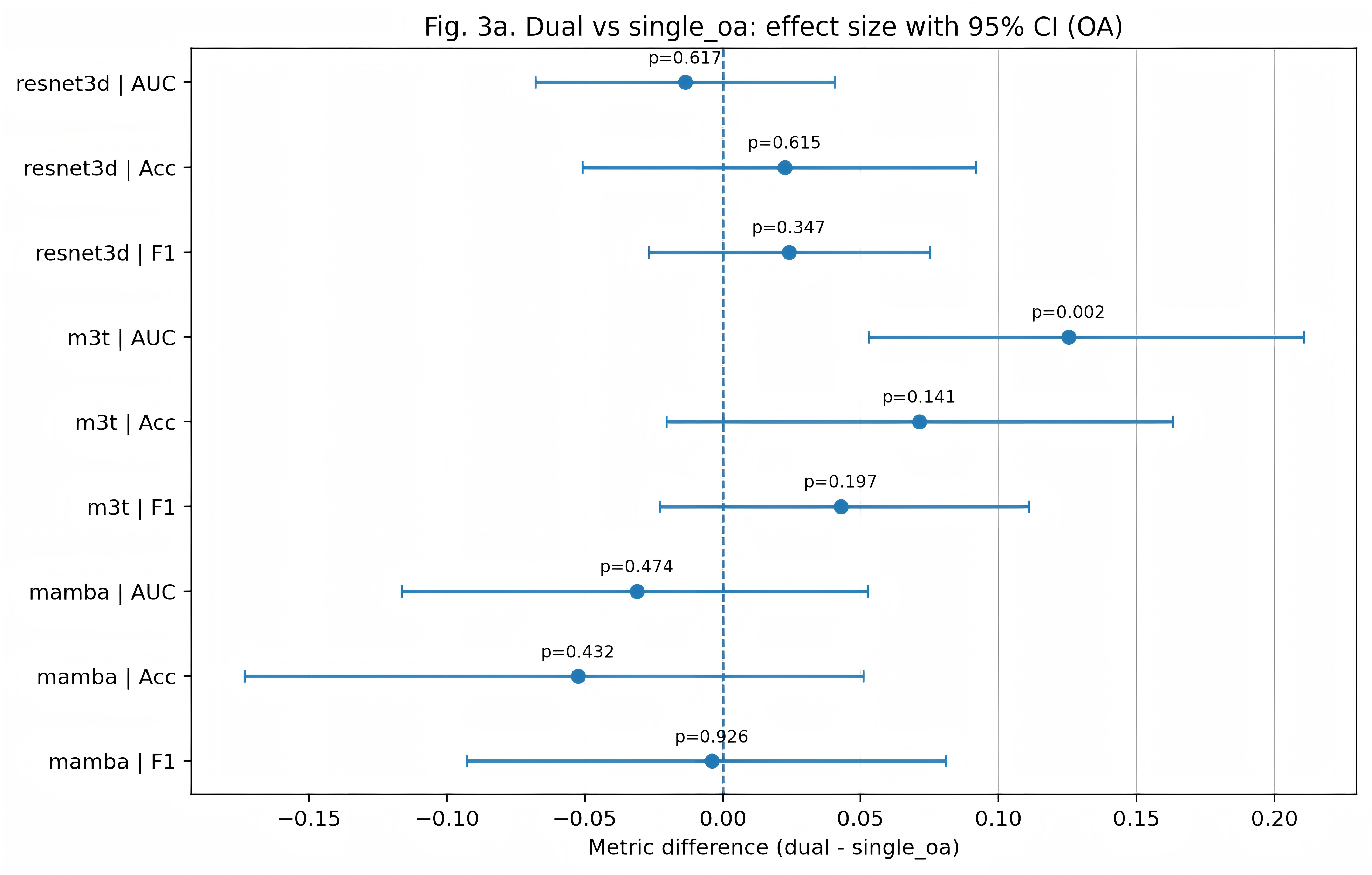
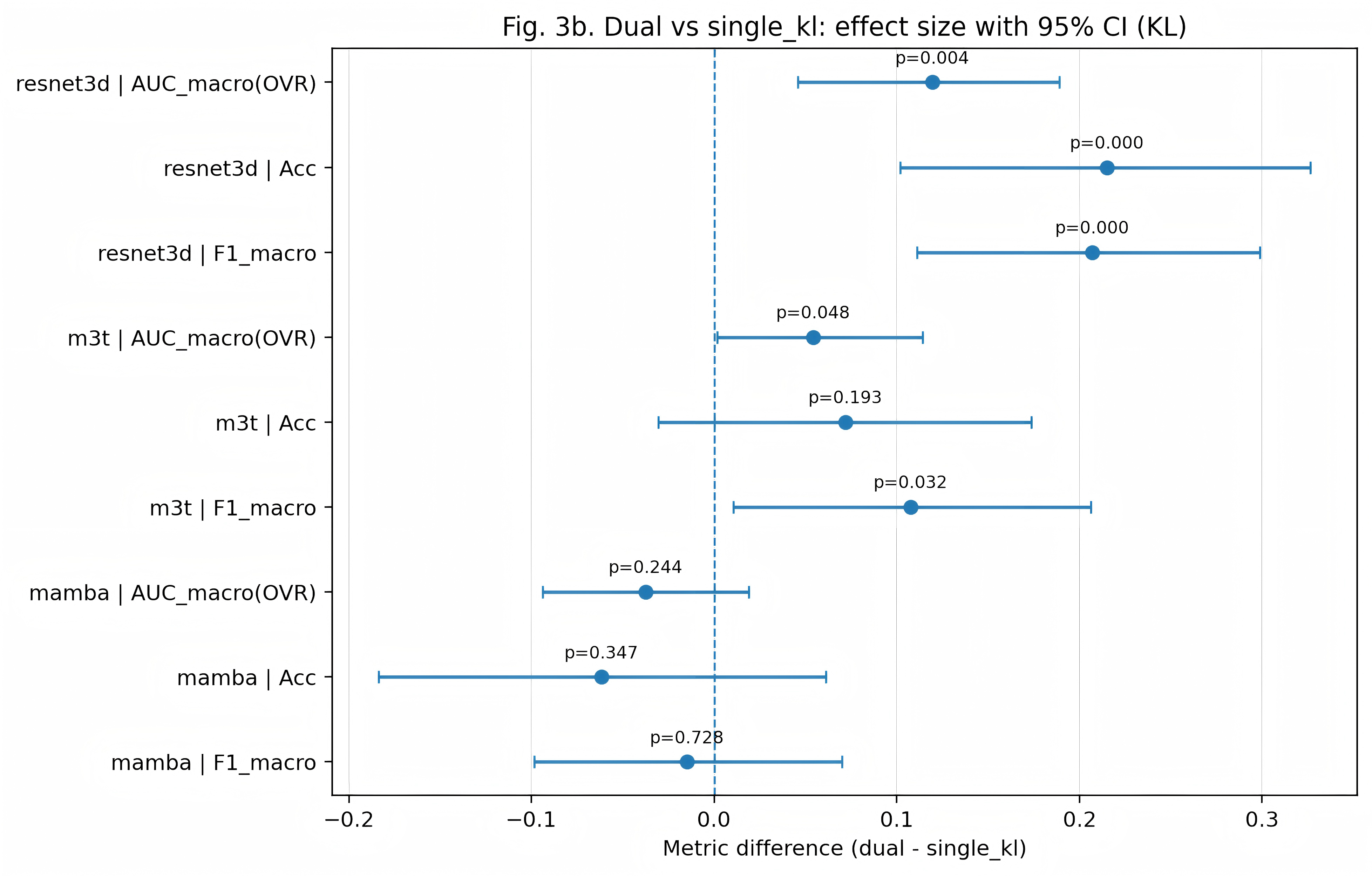
Figure 2: Dual-head vs. single-task performance deltas for OA and KL tasks across backbone architectures.
Latent Space Organization
Representation geometry is central to the claims of this work. PCA of penultimate features reveals:
- Coarse global separation: Single-OA reliably forms a dominant OA presence/absence axis, but this reduces granularity with respect to severity.
- Ordered fine-grained stratification: Single-KL heads form severity axes, but these often lack clear global structure, likely due to KL label noise.
- Coarse-to-fine disentanglement: Dual-head supervision, especially for ResNet3D and M3T, produces representations where PC1 correlates strongly with both KL severity (ρPC1,KL=0.748 for ResNet3D Dual) and OA status, and demonstrates a monotonic arrangement of class centroids.
Qualitative manifold diagrams corroborate these findings, displaying enhanced order along the severity axis for dual-head models in responsive backbones.
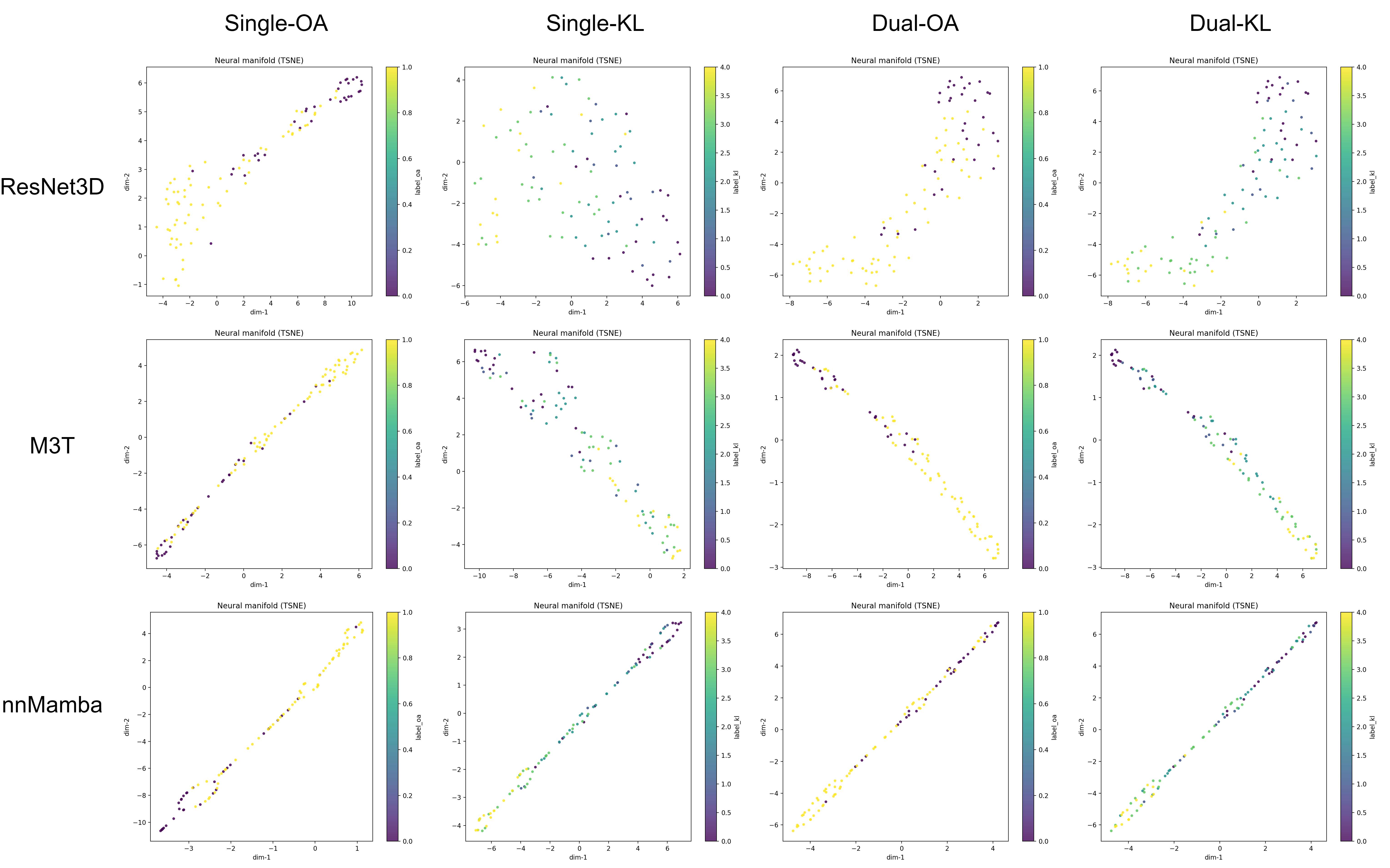
Figure 3: Penultimate-layer manifold embedding showing improved severity-axis ordering with dual-head supervision for selected backbones.
Anatomical Plausibility: Saliency and Cartilage Attribution
Clinically meaningful representation learning requires not only numerical performance but anatomical interpretability. Saliency analysis shows that—particularly in ResNet3D and M3T—dual-head supervision reallocates model attention to cartilage regions:
Implications and Future Directions
These results indicate that even under substantial label noise (KL grading), coarse-to-fine hierarchical supervision can serve as a powerful inductive bias—improving not only scalar performance metrics (especially on finer-grained tasks) but fundamentally restructuring the latent geometry and anatomical attribution of neural representations. However, the effect is not universal: its utility is gated by backbone architecture and potential task interference.
Major theoretical implications include:
- Hierarchical supervision as regularizer: Imposing clinical hierarchy through joint heads moves latent feature organization towards more disentangled and interpretable axes, facilitating downstream clinical tasks such as progression modeling or personalized prognosis.
- Guidelines for model selection: The effectiveness of hierarchical dual-head setups is architecture-dependent; careful empirical comparison is needed before deployment.
- Bridge to ordinal and uncertainty-aware modeling: KL label noise remains a limiting factor; architectures or loss functions attuned to ordinal uncertainty may leverage the coarse-to-fine axis more robustly.
Future research should explore integration of explicit ordinal losses, backbone architectures that are robust to inter-task interference, and longitudinal/semi-supervised extensions to capture disease progression over time.
Conclusion
The study demonstrates that harnessing the coarse-to-fine structure of clinical OA/KL labels via dual-head hierarchical supervision systematically improves fine-grained disease representation and anatomical attribution—when supported by the underlying backbone. The work underscores the importance of considering label hierarchy not merely as a labeling artifact, but as a source of supervisory signal central to medical representation learning. These findings encourage broader adoption of hierarchical supervision in vision-based disease modeling and motivate further investigation into backbone-agnostic strategies for integrating noisy clinical label hierarchies.