- The paper presents a unified probabilistic framework that integrates multimodal EBMs, a shared latent generator, and a MoE joint inference model via MCMC-based revision.
- It demonstrates significant improvements in synthesis quality and cross-modal coherence, validated by metrics such as FID and classifier accuracy on datasets like CUB and PolyMNIST.
- The approach efficiently balances theoretical rigor and practical scalability, with MCMC revision ensuring accurate energy landscape exploration and robust performance on high-dimensional data.
Learning Multimodal Energy-Based Models with Multimodal VAE via MCMC Revision
Introduction
The paper "Learning Multimodal Energy-Based Model with Multimodal Variational Auto-Encoder via MCMC Revision" (2605.00644) proposes a unified probabilistic framework for multimodal generative modeling by integrating Energy-Based Models (EBMs), a shared latent generator, and a joint inference model. The approach leverages MCMC-based revision to tightly couple maximum likelihood (MLE) updates across data and latent spaces. This results in a cooperative learning paradigm where complementary models mutually benefit from each other's inductive signals, enabling improved synthesis quality and cross-modal coherence in challenging multimodal data regimes. Theoretical analysis, extensive experiments, and ablation studies demonstrate substantial performance gains over established baselines.
Methodology
The framework concurrently learns the multimodal EBM, a shared latent generator, and a mixture-of-experts (MoE) joint inference model via interleaved MLE and MCMC-based revision. The EBM parameterizes a joint energy function over all modalities and is optimized via contrastive divergence, where negative samples are generated by Langevin dynamics initialized with the generator’s outputs. The shared latent generator operates with a common latent space for all modalities and is critical for exploring coherent, semantically consistent regions in joint data space.
The generator's posterior is highly structured, with a Product-of-Experts (PoE) form, which is problematic for MoE-based amortized inference. To ameliorate this expressivity bottleneck, the joint inference network is refined via short-run Langevin MCMC in latent space. The interplay between these transition kernels and the base models defines “revision signals” that guide learning. The complete optimization traces a sequence of KL divergences measuring the match between MCMC-refined and base model distributions in both data and latent spaces. Gradients are propagated via stop-gradient computations on the transitions, ensuring stable updates.
Revision Signal Analysis
The two central transition kernels are:
- Langevin sampling on EBM density, initialized from generator samples, for improved negative sample diversity and cross-modal alignment.
- Langevin refinement on the generator’s posterior, initialized from the MoE inference model, for more accurate latent samples.
Using MCMC-revised densities as surrogates for the intractable EBM and generator posterior enables tractable, unbiased learning objectives in both spaces. The EBM gradients contrast data-anchored and generator-anchored samples, with the partition function analytically canceled. The generator and inference models, in turn, are updated to match these MCMC-revised densities.
Empirical loss curves (Figure 1, left and right) confirm that, without complementary models or with independent per-modality initializers, EBM training is unstable and yields inferior convergence, highlighting the necessity of structured multimodal initializations.
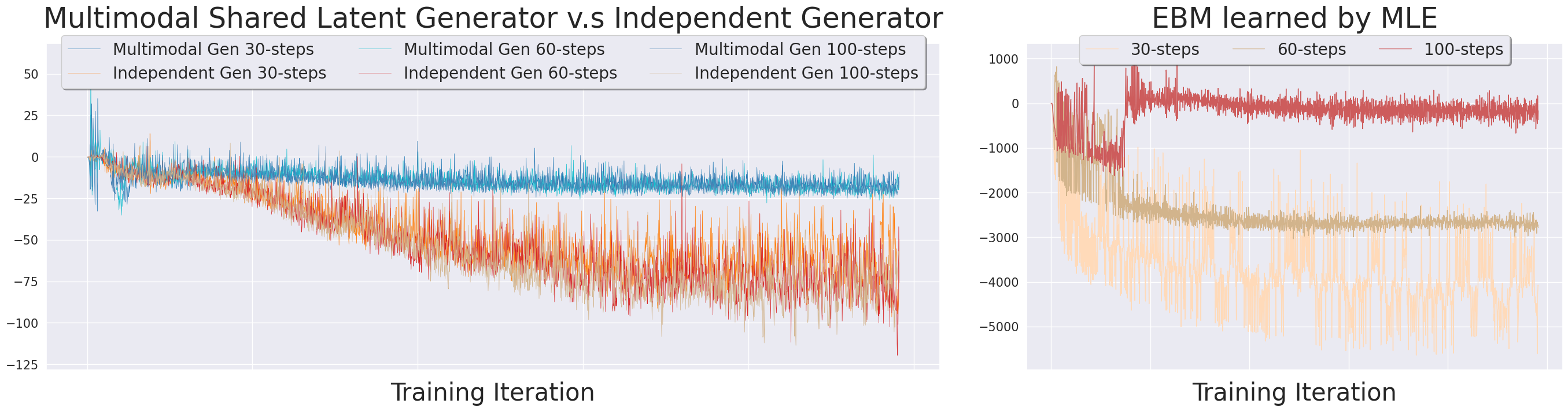
Figure 1: Left: Supervised EBM loss trajectories using shared latent generator versus independent generators. Right: Fluctuations and convergence behavior of EBM loss under increasing sampling step budgets in noise-initialized MLE training.
The method is benchmarked on PolyMNIST and CUB (Caltech-UCSD Birds) datasets for both unconditional and cross-modal generation. Quantitative metrics, including FID for visual quality and cross-modal classifier accuracy for semantic coherence, establish that the proposed joint learning schema consistently outperforms VAEs, MMVAE+, MoPoE, MWBVAE, CoDEVAE, HELVAE, and even diffusion refiner-augmented models like Diff-CMVAE. FID scores are reduced by a significant margin (CUB: 25.98 vs. Diff-CMVAE's 28.00), and classifier-based coherence scores improve commensurately.
Analysis of model components confirms that the single shared latent generator is crucial: replacing it with independent latent spaces degrades energy matching and synthesis alignment (Figure 1, left). Similarly, independent inference networks lacking cross-modal aggregation significantly impair generator loss (Figure 1, right), corroborating the necessity of a coupled latent space for multimodal representation.
Visualization of MCMC Trajectories
Sampling trajectories show that generator initializations are semantically valid and only modestly refined by EBM Langevin steps; the joint inference model's latent initializations similarly require only slight correction via posterior MCMC. This indicates the generator and inference model are efficiently amortizing most of the complexity, while MCMC ensures accurate energy landscape exploration and posterior alignment.

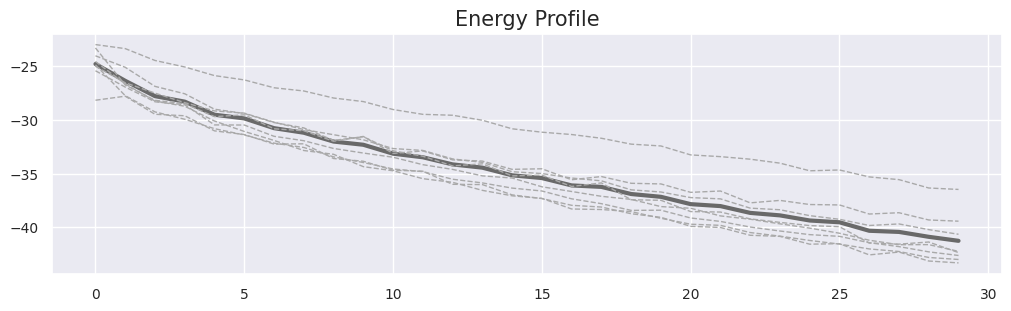

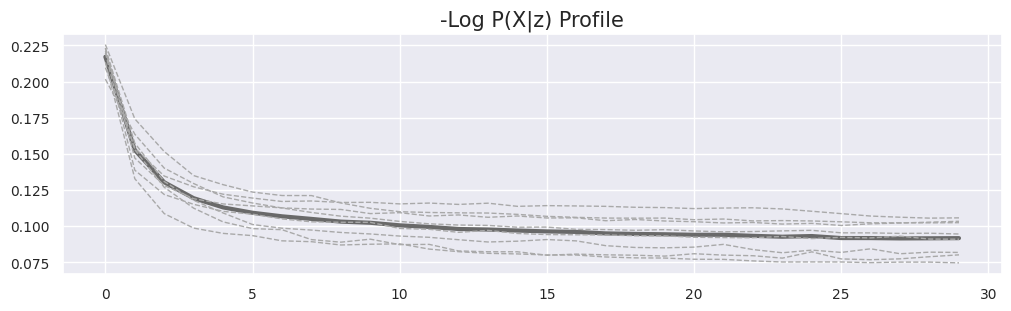
Figure 2: Trajectories of EBM sampling (left panels) and posterior sampling (right panels) across modalities: initializer outputs, intermediate samples, and final MCMC-refined outputs are displayed, demonstrating semantically consistent refinement.
Computational Trade-Offs
Although the introduction of MCMC incurs additional computational cost per training step, empirical analysis shows that reasonable trade-offs in the number of sampling steps achieve most of the gains (optimal around 30–60 steps). Moreover, the generator alone, after cooperative training, provides high-quality generations with one-step sampling. The overall parameter overhead and per-sample inference latency are orders of magnitude lower than those seen in two-stage diffusion decoders, preserving practical scalability.
Extension to High-Dimensional and Large-Scale Data
Scaling experiments on high-resolution CUB and MSCOCO validate the framework's robustness in large-scale, high-dimensional scenarios. FID scores remain substantially better than conventional VAEs across such regimes, demonstrating effective joint latent space utilization and cross-modal coherence.
Ablations and Theoretical Implications
Ablation studies on MCMC step counts provide evidence that expressive revision signals in both data and latent spaces are necessary for optimal performance. Theoretical analysis shows that the learning objectives circumvent intractable normalization via stop-gradient KL differences, and that the approach seamlessly generalizes to models with modality-specific latent variables.
The results have significant implications for the future of multimodal generative learning. The proposed framework demonstrates that tight interleaving of structured priors, flexible EBMs, and amortized inference, together with adaptive MCMC revision, yields robust representations and scalable models. This suggests that future generative models—especially for few-shot, compositional, or missing modality inference—will need to further blend latent variable adaptation, energy-based sampling, and cross-modal knowledge transfer.
Conclusion
This work introduces a technically rigorous framework for learning multimodal EBMs via mutual MCMC-based revision with a shared latent generator and coupled joint inference model. Experimental results validate strong generation quality, coherence, and scalability. Beyond practical synthesis, the methodology advances theoretical understanding of probabilistic inter-model coupling and marks a step toward more expressive, robust, and adaptable multimodal generative modeling platforms.

