- The paper introduces TreeBO, a recursive partitioning algorithm that achieves Bayesian optimization in linear time by employing local GP surrogates.
- It leverages binary space partitioning and SVM-based boundaries to decouple global GP fitting from local modeling, significantly reducing computational cost.
- Empirical evaluations across diverse benchmarks show TreeBO's superior performance and efficiency in locating global minima in multimodal, high-dimensional functions.
Linear-Time Bayesian Optimization via Recursive Partitioning: A Critical Essay
Introduction
"Bayesian Optimization in Linear Time" (2605.00237) introduces TreeBO, a recursive partitioning framework for Bayesian optimization (BO) with key algorithmic modifications enabling linear computational complexity with respect to the number of objective function evaluations. The primary technical advances concern a binary partitioning of the search domain, local fitting of Gaussian process (GP) surrogate models with data borrowing across partitions, and the use of flexible nonlinear support vector machines (SVMs) for partition boundaries. By decoupling the globally-trained GP surrogate and introducing local, bounded-size GPs structured in a binary tree, TreeBO addresses two persistent and orthogonal shortcomings of canonical BO: cubic complexity in the training set size and inadequate adaptation to the local nature of multimodal objective minimization.
Methodology: TreeBO Partitioning and Local Modeling
TreeBO operationalizes its partitioning strategy by recursively splitting the search domain based on clustering in observation-augmented space (x,f(x)), employing Partitioning Around Medoids (PAM) within each leaf node of the binary tree structure. For each partition (node), a flexible binary classifier (SVM with a Gaussian kernel) learns the boundary, yielding nonlinear and data-adaptive regions. Each leaf node maintains its own GP model fit on all points within its partition, supplemented (when necessary) by borrowing nearest points from neighboring partitions until a prescribed data quota is met.
The acquisition function within each node is a penalized expected improvement (EI), with the penalization mechanism rigorously defined using the SVM decision values to create a signed distance-like penalty for out-of-domain queries (see Eq.~(1) in the paper). The recursive definition of region membership ensures that points are only considered valid if they traverse the correct sequence of classifier decisions along the path from the root, resulting in arbitrarily shaped, highly adaptable search regions.
The main control parameter is the maximum number of observations per leaf node before a split; this governs tree depth and the local/global learning tradeoff. The partitioning process, data borrowing, and EI maximization (the latter via a modified particle swarm optimizer) are all performed with O(n) complexity per iteration.
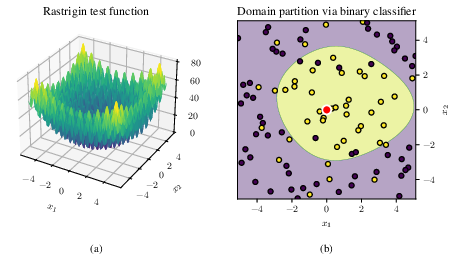
Figure 1: The TreeBO binary domain partitioning for the Rastrigin function (d=2), where nonlinear classification carves out a subregion capturing the global minimum.
Empirical Evaluation
Evaluation is conducted on seven benchmark functions (Ackley, Hartmann, Rastrigin, Schwefel, Levy, Michalewicz, and a high-dimensional constrained automotive mass-minimization benchmark, MOPTA08) spanning 6 to 124 dimensions and presenting diverse local/global structure and multimodality. TreeBO is compared against DiceOptim, a state-of-the-art R-based BO package implementing canonical GP-based BO with cubic complexity.
The results exhibit several important trends:
- Superior optimization performance: TreeBO achieves lower average minima than DiceOptim on all test problems. The improvements are substantial for highly multimodal and deceptive functions, such as Ackley, Rastrigin, Schwefel, and Levy. For Ackley (d=6), for example, TreeBO achieves a mean minimum of $0.657$ versus $3.829$ for DiceOptim.
- Runtime efficiency: Especially in the extreme regime, as for the d=124 automotive benchmark, TreeBO reduces total wall time by over 30% (9 vs 14 days) due to fitting GPs only on capped partition data.
- Performance dynamics: On some benchmarks, DiceOptim outperforms TreeBO in early iterations (before the partitions are sufficiently populated and splits triggered), but post-partition, TreeBO shows rapid descent toward global minima, often with lower inter-trial variance. This effect is pronounced in multimodal functions where the global minimum occupies a small, isolated region.
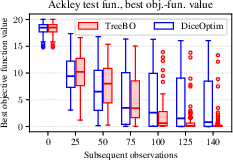
Figure 2: For Ackley (d=6), TreeBO quickly compresses the minimum found toward the global value, while DiceOptim continues to find significantly inferior solutions in many runs.
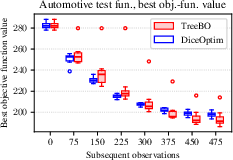
Figure 3: In the high-dimensional automotive benchmark, DiceOptim leads early but is overtaken by TreeBO after sufficient partitioning; TreeBO achieves markedly lower final minima and runtime.
The difference in performance is further substantiated distributionally (boxplots and trajectory plots), demonstrating TreeBO's ability to consistently localize minima across multiple challenging instances, while standard BO often stalls in local optima or fails to efficiently explore.
Theoretical and Practical Implications
The reduction from cubic to linear complexity in GP fitting per iteration, achieved via recursive partitioning and local data bounds, is a qualitative advancement. While sparse GP approximations offer sub-cubic scaling, they typically require more function evaluations and intricate kernel engineering. In contrast, TreeBO leverages flexible, data-driven regions and surrogates, preserving the expressive power of GPs for each local neighborhood.
By decoupling surrogate modeling from strict global fits, TreeBO also provides principled support for high-dimensional and highly-multimodal regimes, where the global structure is both expensive and potentially misleading to model. The recursive, data-driven partitioning approach is directly extensible to domains with unknown or dynamic structure and supports easy future incorporation of massively-parallel acquisition (since partitions can be evaluated independently).
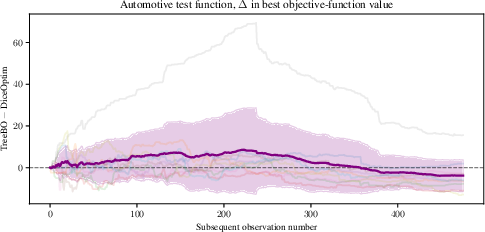
Figure 4: DiceOptim outperforms TreeBO until a threshold number of acquisitions, after which TreeBO consistently finds lower minima.
This paradigm aligns with recent advances in local surrogate modeling and search space decomposition for BO, yet TreeBO offers a novel penalization and node selection strategy that obviates the need for explicit confidence-bound parameters or tree-rebuilding heuristics.
Limitations and Future Directions
TreeBO parameterizes maximum leaf size relative to the total query budget; a poorly chosen balance can induce either underfitting (shallow trees) or computationally expensive partition chains. Further, the node split and classifier processes can occasionally fail due to highly imbalanced class membership—a direct consequence of agnostic clustering and flexible partitioning. Also, while the penalization mechanism for acquisition optimization is effective, it introduces discontinuities at node boundaries, which could potentially interfere with optimizers relying on smoothness assumptions.
Potential future enhancements include:
- Continuous penalization for acquisition functions to smooth the boundary discontinuity without sacrificing region fidelity.
- Parallelization at both the node evaluation and EI maximization stages.
- Adaptive or data-driven partitioning criteria, possibly incorporating global information or earlier signals for split necessity.
- Exploration of alternative local surrogate models or kernel sharing across classifiers and GP surrogates, with the caveat that current results show independence generally beneficial.
Conclusion
TreeBO demonstrates a principled solution to both the computational and statistical limitations of classical Bayesian optimization in black-box, expensive, and high-dimensional settings. By incorporating recursive, flexible partitioning via clustering and nonlinear classification, and decoupling surrogate fitting from a global GP constraint, TreeBO attains both strong empirical performance and theoretical computational scalability.
Its strong numerical results across a suite of challenging benchmarks—especially in the long-criticized high-dimensional, highly-multimodal regime—highlight the promise of adaptive, region-local modeling in BO. As the data-driven design of partition rules and modeling within partitions matures, TreeBO and similar architectures are poised to set the new practical limits of sample-efficient, computationally tractable black-box optimization.

