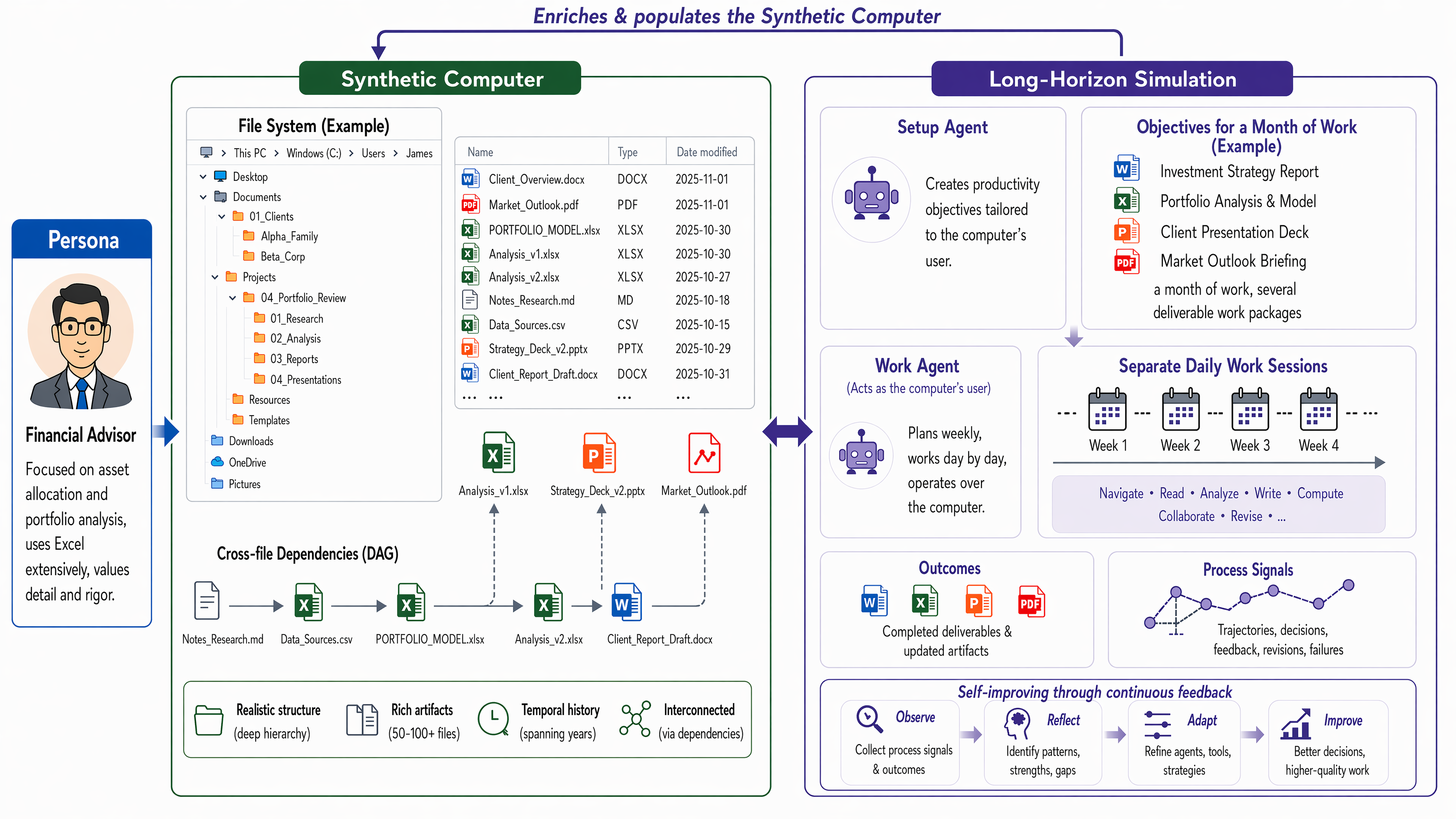
Synthetic Computers at Scale for Long-Horizon Productivity Simulation
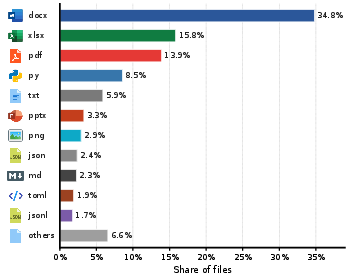
Abstract: Realistic long-horizon productivity work is strongly conditioned on user-specific computer environments, where much of the work context is stored and organized through directory structures and content-rich artifacts. To scale synthetic data creation for such productivity scenarios, we introduce Synthetic Computers at Scale, a scalable methodology for creating such environments with realistic folder hierarchies and content-rich artifacts (e.g., documents, spreadsheets, and presentations). Conditioned on each synthetic computer, we run long-horizon simulations: one agent creates productivity objectives that are specific to the computer's user and require multiple professional deliverables and about a month of human work; another agent then acts as that user and keeps working across the computer -- for example, navigating the filesystem for grounding, coordinating with simulated collaborators, and producing professional artifacts -- until these objectives are completed. In preliminary experiments, we create 1,000 synthetic computers and run long-horizon simulations on them; each run requires over 8 hours of agent runtime and spans more than 2,000 turns on average. These simulations produce rich experiential learning signals, whose effectiveness is validated by significant improvements in agent performance on both in-domain and out-of-domain productivity evaluations. Given that personas are abundant at billion scale, this methodology can in principle scale to millions or even billions of synthetic user worlds with sufficient compute, enabling broader coverage of diverse professions, roles, contexts, environments, and productivity needs. We argue that scalable synthetic computer creation, together with at-scale simulations, is highly promising as a foundational substrate for agent self-improvement and agentic reinforcement learning in long-horizon productivity scenarios.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What’s this paper about?
This paper is about teaching AI “office helpers” to handle real, months‑long work on a computer. Instead of giving an AI tiny, one‑off tasks, the researchers build full, pretend computers—complete with folders, documents, spreadsheets, and history—and let AI practice doing long projects inside them. They call these pretend setups “synthetic computers.”
What were the main questions?
The researchers asked three big questions, in simple terms:
- Can we build realistic, fake computer environments that look and feel like a real person’s work computer (with organized folders, past files, and ongoing projects)?
- If we let AI agents “live” in those computers for weeks of simulated time, planning, creating, and revising work like a real professional would, will the AI learn useful skills from the experience?
- Will that practice actually make the AI better at doing long, complicated work—both on similar tasks and on new, different ones?
How did they do it?
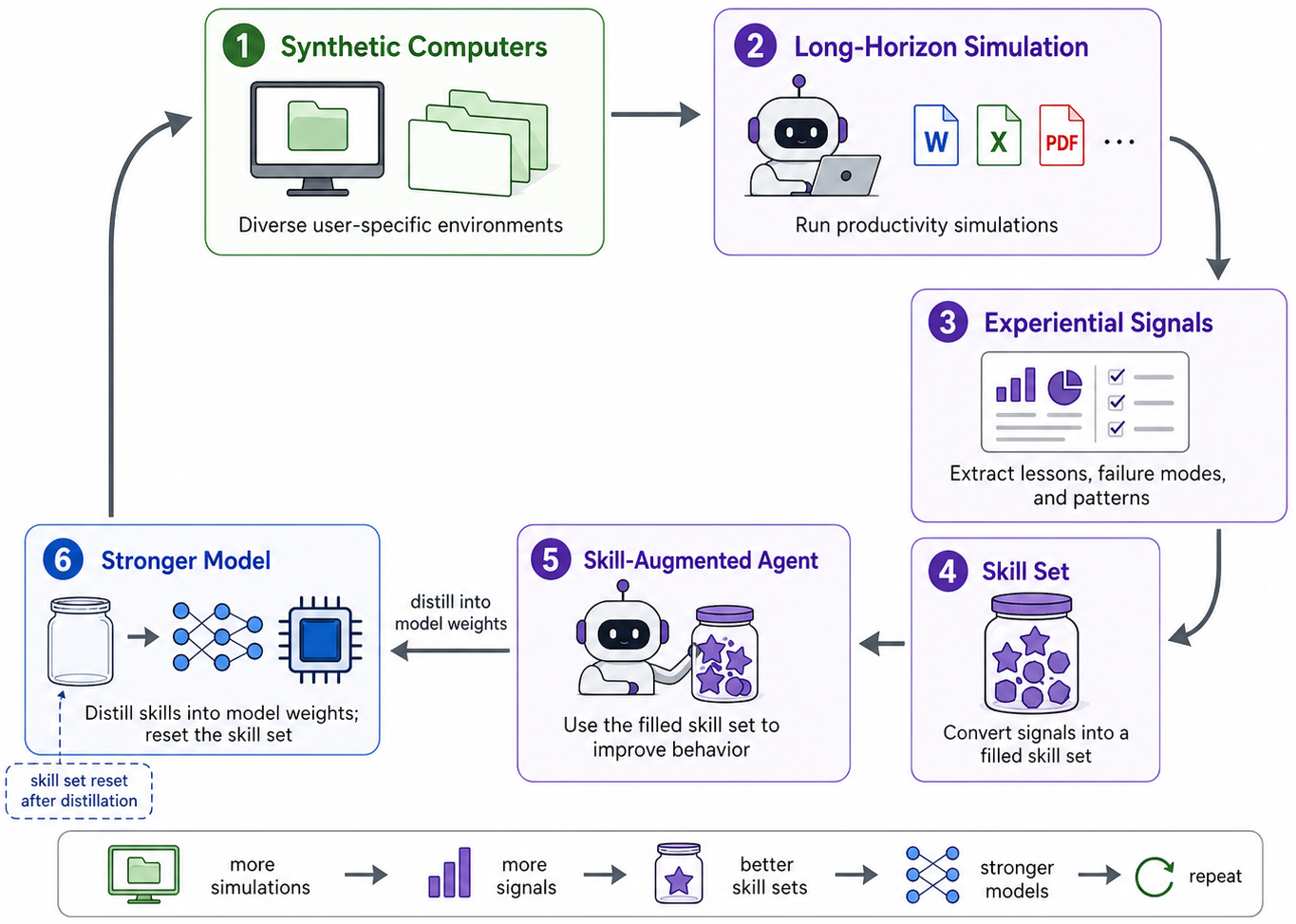
Think of this like building a movie set and then running a month‑long role‑play:
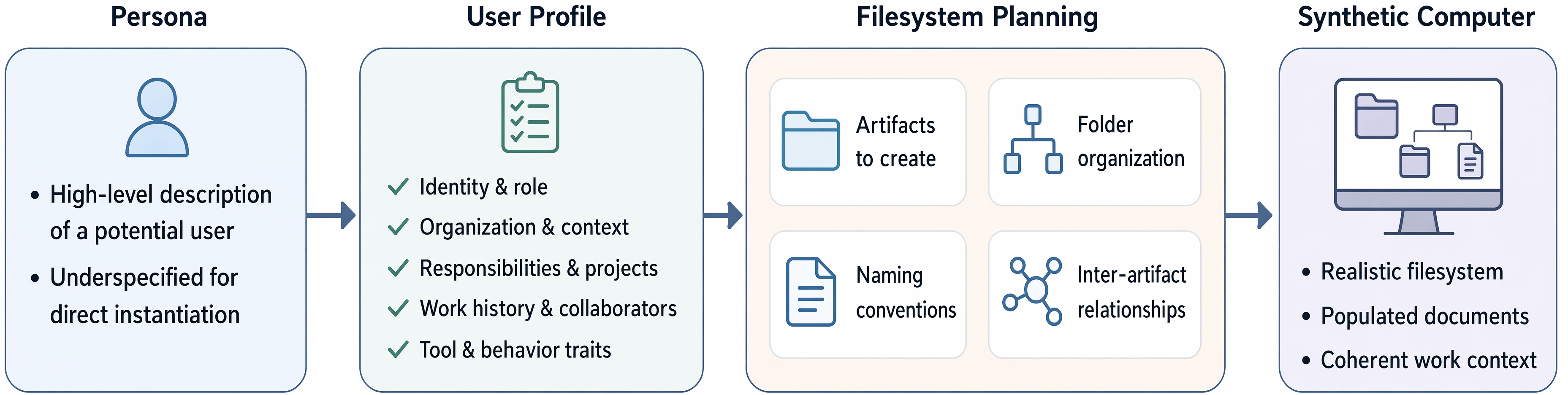
- Step 1: Create a believable “user” (persona)
- The team starts with a detailed character profile (for example, a senior financial advisor). This profile includes their job, tools they prefer (like Excel or Word), who they work with, and how they name and store files.
- Analogy: It’s like writing a character sheet for a video game—job, habits, teammates, and missions.
- Step 2: Plan and build the computer’s folders and files
- They design a realistic folder tree (like C:/ClientWork, D:/Research) and decide which files should exist, when they were created, and how they link to each other.
- They draw a “dependency graph,” which is a map of what depends on what. For example, a presentation might be based on a spreadsheet, which is based on a downloaded report.
- Analogy: A dependency graph is like a recipe: you must chop vegetables before you can cook them.
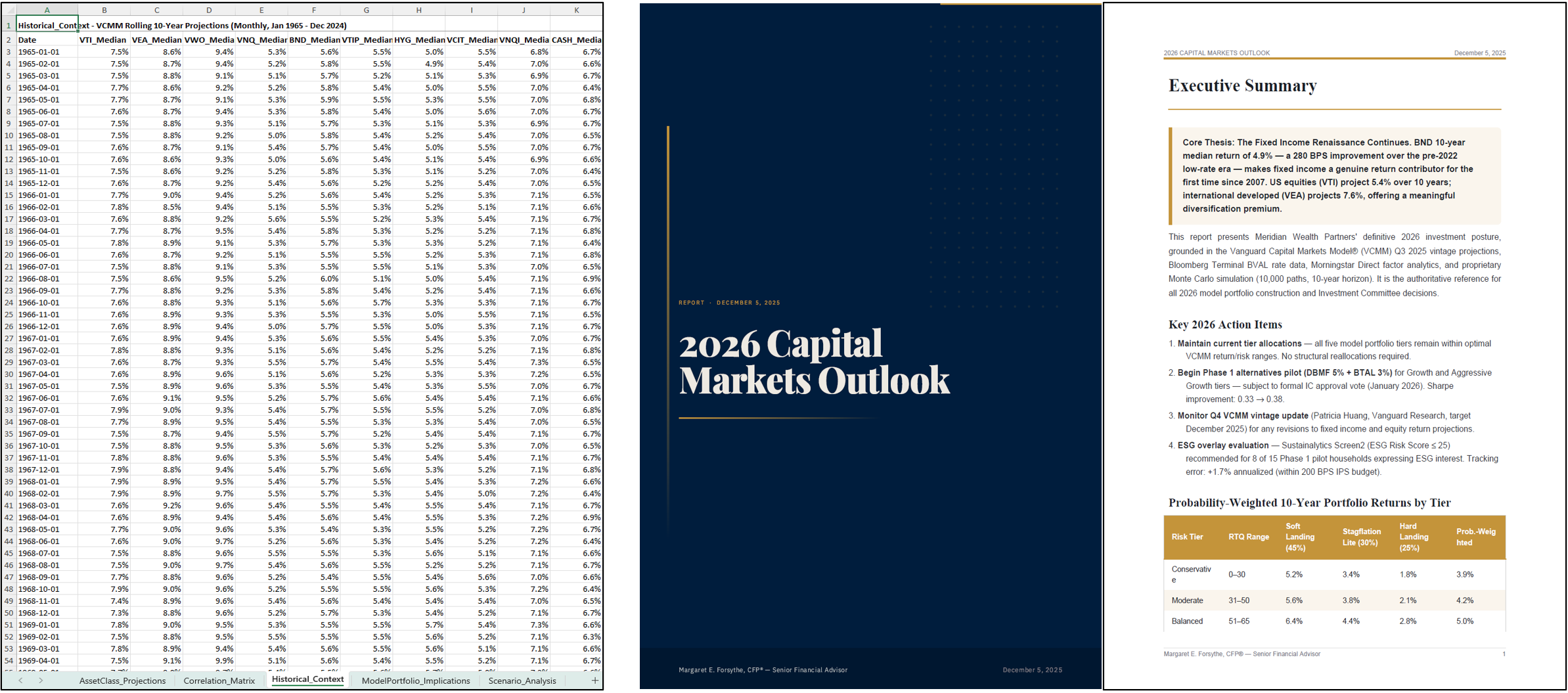
- Step 3: Fill the computer with actual content
- If a file is something public (like a real report on the web), they download it.
- If it’s personalized (like a client memo or a custom spreadsheet), they ask an AI to write or build it, making sure it references the right earlier files. They create files in the right order (like preparing ingredients before baking), using a technique that ensures “earlier” materials come first.
- Step 4: Run a month‑long work simulation
- Two AI “agents” are involved:
- A setup agent creates realistic month‑long goals based on the user and the computer’s contents (for example, “refresh the firm’s 2026 investment models and produce a report and slide deck”).
- A work agent plays the user day‑by‑day. It searches the computer, opens files, updates documents, builds new spreadsheets, and emails or messages simulated coworkers to ask questions and get feedback.
- The work agent plans each week and each day, then carries out tasks, logs what happened, and updates files. It keeps going until the goals are done.
What did they find, and why is it important?
Here’s what happened in their early tests:
- Scale and realism:
- They built 1,000 synthetic computers and ran a month‑long simulation on each.
- Each run took over 8 hours of agent “thinking time” and more than 2,000 back‑and‑forth steps on average.
- The simulations produced lots of useful data: not just final outputs (like reports and slide decks) but also the whole process (plans, searches, revisions, conversations, and fixes after mistakes).
- Better performance:
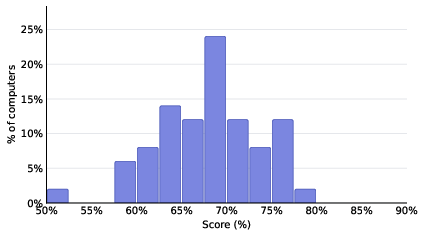
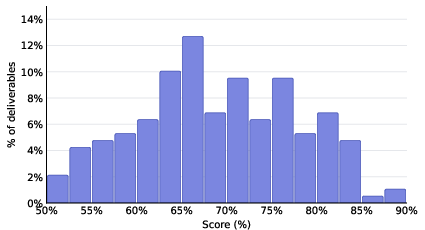
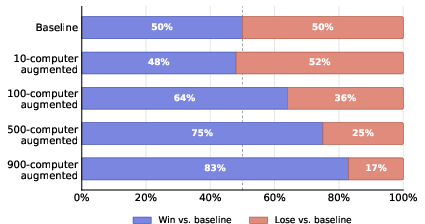
- Training on these “lived experiences” made the agents noticeably better at long, realistic work.
- The improvements showed up both on tasks similar to the practice ones (in‑domain) and on different tasks (out‑of‑domain), which suggests the skills generalized.
- Reusability and sharing:
- They released 100 synthetic computers (50 Windows‑style, 50 macOS‑style) and 500 analysis reports so others can study and build on this approach.
Why this matters:
- Real work is all about context—your old files, your ongoing projects, and your team. Collecting real user data is hard and private. These synthetic computers create a safe, scalable way for AI to practice the full flow of work without touching anyone’s actual files.
- The method can, in theory, scale to millions or even billions of “personas” and computers, covering many jobs and industries. That could help build much more capable, trustworthy productivity AIs.
What’s the bigger impact?
If AI can practice complex, months‑long projects in realistic, privacy‑safe “fake computers,” it can learn how to:
- Navigate messy folder systems and reuse past work
- Plan weeks of tasks, not just single steps
- Work with colleagues—ask the right questions and respond to feedback
- Produce professional files (documents, spreadsheets, presentations) that fit the user’s style and needs
In short, this research points toward AI helpers that are better at real office work—not just answering questions, but doing sustained projects from start to finish. It’s like giving the AI a realistic internship at scale, so it learns by doing and keeps getting better.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored, framed to guide follow-on research:
- Realism validation: No quantitative evidence that synthetic computers match real user machines in directory topology, artifact density/mix, naming/versioning patterns, and temporal activity; requires metrics and comparison against consented real-world baselines.
- Limited platform coverage: Only Windows/macOS-style filesystems are considered; Linux, mobile, and cross-device/cloud contexts (OneDrive/Drive/Dropbox/SharePoint) are not modeled.
- Narrow application surface: Focus on Office artifacts (Word/Excel/PowerPoint/PDF); excludes email/IM, calendar, browser history, code repos, notebooks, CAD/design files, BI dashboards, databases, and domain tools.
- Web-download verification gap: Availability/licensing checks for “public, web-downloadable” files occur after planning; fallback synthesis may introduce hallucinated or improperly licensed content; needs pre-validation, checksum pinning, and license tracking.
- Content fidelity in artifacts: No automated verification that generated spreadsheets contain correct formulas, references, and unit consistency; needs auditors for formula integrity, cross-tab coherence, dimensional analysis, and data lineage.
- Dependency semantics: The topological order ensures creation order but not semantic linking (e.g., Excel external links, citations, cross-file references); requires link-aware generation and validation of reference integrity across revisions.
- OS/application metadata realism: Authorship, “last opened,” edit histories, Office Track Changes, comments, and PDF metadata are not validated for plausibility; needs metadata synthesis consistent with narrative timelines.
- Collaboration realism: Simulated collaborators’ behavior, latency distributions, inconsistency, negotiation, and error/noise dynamics are not validated against human teams; needs user studies and empirical calibration of communication patterns.
- Human-in-the-loop grounding: No experiments with partial human feedback within simulations to calibrate or correct collaborator agents; open question on hybrid (human+sim) collaboration benefits and cost.
- Evaluation ablations: Reported gains lack clear attribution to environment grounding, artifact richness, collaborator dynamics, or horizon length; needs controlled ablations isolating each component.
- Sim-to-real transfer: No evidence that training on synthetic computers improves performance for real users in live deployments; requires A/B tests or field trials with consenting users.
- Reward and credit assignment: “Agentic reinforcement learning” is proposed, but how process/outcome signals become learnable rewards is unspecified; needs reward models, success/failure annotations, and hierarchical credit assignment strategies.
- Long-horizon metrics: Reliance on “turns” and runtime lacks task-quality granularity; needs standardized metrics (task completion, rework/churn, path efficiency, defect rates, reviewer acceptance, time-to-approval).
- Failure analysis: No taxonomy or measurement of pipeline and agent failure modes (broken links, malformed files, tool errors, recovery strategies); needs telemetry, fault injection, and robustness benchmarks.
- Temporal realism limits: Month-scale simulations only; missing multi-quarter/year evolution, software updates, archival/cleanup behaviors, concept drift, and changing organizational constraints.
- Coverage and diversity: Persona sampling breadth across professions, seniority, industries, languages/locales, and regulatory regimes is not quantified; needs coverage metrics, stratified sampling, and fairness audits.
- Multilingual contexts: Non-English filesystems, artifacts, and collaborator communications are not addressed; open question on multilingual generation and evaluation fidelity.
- External system integration: References to Bloomberg/Morningstar/CRMs/compliance portals are not operationalized; needs API stubs or high-fidelity simulators with realistic data schemas and rate/permission constraints.
- Scheduling and interruptions: Meeting calendars, conflicting priorities, urgent requests, and stochastic events are not explicitly modeled; needs event generators and resource/availability constraints.
- Versioning/provenance: File version suffixes exist, but formal provenance (change logs, diff tracking, authorship, VCS-like history) is absent; needs provenance graphs with verifiable diffs and change rationales.
- Safety/compliance: No systematic analysis of harmful or noncompliant outputs (e.g., financial advice errors, regulatory breaches) or guardrails; needs policy checkers, red-teaming, and compliance audits.
- Bias and contamination: Same/similar LLMs appear to generate environments and train/evaluate agents, risking circularity and leakage; needs cross-model generation, held-out generators, and contamination checks.
- Scalability economics: Claims of million/billion-scale generation lack compute/storage/energy cost models, orchestration strategies, caching, and failure recovery plans; requires concrete scaling curves and SLOs.
- Data release granularity: Only 100 computers and 500 retrospective reports are released; availability of raw trajectories, collaborator messages, and editable artifacts (with licenses/redactions) is unclear; open question on reproducible, privacy-safe releases.
- Legal/ethical provenance: Handling of copyrighted/PII content in downloaded sources and synthesized artifacts is not detailed; needs dataset cards, license inventories, and automated PII scrubbing.
- Reproducibility controls: Prompts, seeds, model versions, and toolchains for both environment and artifact generation are not fully specified; needs configuration manifests for deterministic regeneration.
- OS/tool realism: Details on Office automation, macro security, file locks, permissions, and cross-version compatibility are sparse; needs tests across software versions and security settings.
- Security posture: No modeling of permissions, access control, or adversarial events (phishing, malicious macros); requires sandboxed security scenarios and safe tool-use policies.
- Latency and resource constraints: Agent step timing and compute quotas are not tied to realistic user/enterprise constraints; needs resource budgets and latency-aware planning behaviors.
Practical Applications
Immediate Applications
Below are actionable, sector-linked use cases that can be deployed with current tools and the paper’s released assets (synthetic computers, logs, and methodology), along with practical dependencies to consider.
- Software/AI — Long-horizon agent QA and benchmarking on OS-grounded tasks
- Application: Use the released synthetic computers and activity logs to evaluate copilots/agents (e.g., office, coding, desktop) on end-to-end workflows requiring file navigation, versioning, collaboration, and multi-artifact deliverables.
- Potential tools/products/workflows: “Agent QA Harness” integrating headless Office (e.g., LibreOffice, MS Office APIs), filesystem sandboxing, trace-based scoring; CI pipelines that run 8-hour simulations as regression tests.
- Assumptions/dependencies: Access to strong LLMs with tool-use and file I/O; reproducible VM/containerized environments; cost budget for multi-hour runs; Office-format I/O libraries (e.g., python-docx, openpyxl, python-pptx, PDF toolkits).
- Software/AI — Experiential fine-tuning and agentic RL bootstrapping
- Application: Train/evaluate agents using the process signals (plans, revisions, feedback, recovery from failure) and outcome artifacts to improve planning, tool-usage, and collaboration behaviors.
- Potential tools/products/workflows: SFT/RL pipelines (e.g., DPO, GRPO, A-RLHF) on trajectory logs; curriculum derived from weekly/daily plans; reward models that score deliverable quality and process adherence.
- Assumptions/dependencies: Licenses permitting training on released data; scalable training compute; reliable parsers for Office/PDF; stable reward definitions to avoid reward hacking.
- Enterprise IT (cross-industry) — Privacy-safe pre-deployment evaluation of desktop copilots
- Application: Build firm-specific synthetic computers mirroring internal folder conventions, workflows, and document types to vet agents before granting access to production machines.
- Potential tools/products/workflows: “Synthetic PC Lab” service; IT security review workflows; red/blue team test suites for permissioning, file access policies, and DLP.
- Assumptions/dependencies: SME time to encode realistic policies and artifacts; governance around any templated internal content; integration with corporate MDM/VDI.
- Finance — Workflow rehearsal and tool validation for advisory teams
- Application: Simulate client onboarding, IPS drafting, allocation modeling, and compliance review (as in the paper’s finance persona) to test spreadsheet agents and compliance-aware copilots.
- Potential tools/products/workflows: Excel modeling agents; compliance checkers that redline IPS/ESG text; templated “new client onboarding” synthetic desktops for training.
- Assumptions/dependencies: Availability of public/placeholder data (or licensed feeds); legal vetting to avoid misrepresenting proprietary models; alignment with internal suitability/compliance standards.
- Education — Project-based learning sandboxes for professional practice
- Application: Provide students with synthetic desktops populated with realistic artifacts (reports, spreadsheets, decks) to practice multi-week projects (e.g., finance, marketing, ops).
- Potential tools/products/workflows: LMS integration; auto-assessment rubrics based on deliverables and process logs; peer-review exercises seeded by collaborator personas.
- Assumptions/dependencies: Faculty-curated personas aligned to curricula; academic licensing for software; guardrails to prevent students from submitting AI-only work as human effort.
- Productivity SaaS/Office suites — End-to-end feature testing for copilots
- Application: Regression-test document-generation, revision, citation, and version-control features across long-horizon tasks (e.g., multi-version reports, meeting feedback incorporation).
- Potential tools/products/workflows: Synthetic scenario packs for release QA; telemetry dashboards showing error rates across document types and workflows.
- Assumptions/dependencies: Stable API/SDK for document ops; automated diff/quality metrics for Office artifacts; test data governance.
- Policy/Government — Procurement and certification benchmarks for AI assistants
- Application: Use standardized synthetic computers to evaluate vendor agents on realistic, privacy-safe, multi-week workloads before procurement or deployment in agencies.
- Potential tools/products/workflows: “Long-Horizon Productivity Benchmark Suite” with scoring protocols; third-party test labs; RFP attachments with sector-specific desktops (finance, health admin, legal).
- Assumptions/dependencies: Consensus metrics for process quality and deliverable adequacy; reproducible infrastructure; agency-specific accessibility and security constraints.
- Cybersecurity/GRC — Red teaming of data access and leakage
- Application: Populate synthetic computers with sensitive-but-fake files (e.g., PII-like placeholders, compliance docs) to test whether agents respect permissioning and minimize data leakage in outputs.
- Potential tools/products/workflows: Policy engines for allowable content; automated probes that attempt prompt-injection and exfiltration; audit trails for regulatory evidence.
- Assumptions/dependencies: Clear safety policies encoded in agent system prompts/tools; secure isolation of test environments; internal approval for red-team activities.
- Process mining/Operations — Derive process models from logs
- Application: Mine weekly/daily plans and activity logs to identify bottlenecks, failure recovery patterns, and coordination overhead; compare across personas to optimize workflows.
- Potential tools/products/workflows: Event-log ETL to BPMN/PM4Py; dashboards correlating process variants with deliverable quality; A/B tests on plan templates.
- Assumptions/dependencies: Consistent, timestamped logs; mapping from synthetic KPIs to real business KPIs; analyst time to interpret findings.
- RPA/Automation — Generate training sequences for desktop/UI agents
- Application: Convert simulated multi-app workflows into step-by-step automations for RPA tools (e.g., UiPath, Power Automate) and test resilience to file versions and directory changes.
- Potential tools/products/workflows: “Workflow distillation” from agent traces; synthetic exception scenarios (missing files, version conflicts).
- Assumptions/dependencies: UI automation compatibility with OS/app versions; robust selectors and file watchers; error-handling templates.
- Knowledge management/Search — Bootstrap retrieval corpora from artifact graphs
- Application: Use the inter-file dependency graph to build retrieval indices that respect citation/version chains and evaluate RAG agents’ ability to ground on the correct artifacts.
- Potential tools/products/workflows: Vector indices with metadata filters (version, project, dependency lineage); “grounding correctness” metrics.
- Assumptions/dependencies: Reliable content extraction for embeddings; index freshness as simulations evolve; evaluation gold standards.
- Academia/AI research — Controlled studies of planning, tool-use, and collaboration
- Application: Reproduce and compare agent strategies across identical synthetic computers; test ablations (tool skills on/off, collaborator latency, file graph density).
- Potential tools/products/workflows: Open datasets and evaluation harnesses; leaderboards for long-horizon productivity tasks; replicable OS images.
- Assumptions/dependencies: Agreement on task definitions and metrics; access to multiple foundation models for comparison.
- HR/Learning & Development — Role-specific onboarding environments
- Application: Provide new hires with synthetic desktops reflecting role-specific tools, templates, and “in-progress” projects to practice before accessing real systems.
- Potential tools/products/workflows: “Day-0 Sandbox PCs” per role; checklists scored by deliverables; mentor review of practice outputs.
- Assumptions/dependencies: Time to curate role-accurate artifacts; alignment with IT policies; measurement of training efficacy.
- Data governance — DLP and retention policy testing on realistic structures
- Application: Validate scanning/classification pipelines on multi-version document trees and mixed storage locations (Desktop, Documents, network drives).
- Potential tools/products/workflows: Synthetic PII patterns; retention-expiry scenarios; policy-rule regression suites.
- Assumptions/dependencies: False-positive/negative tolerance; mapping synthetic to real risk categories; compliance sign-off.
Long-Term Applications
These use cases extend the methodology with additional research, scaling, and integrations before broad deployment.
- Cross-industry — Digital twins of knowledge work at organizational scale
- Application: Maintain always-on, role-accurate synthetic desktops across departments to continuously evaluate, optimize, and certify AI assistants and workflows.
- Potential tools/products/workflows: “Org Twin Lab” platform; scheduling of periodic long-horizon runs; KPI-linked dashboards.
- Assumptions/dependencies: Significant compute budgets; integration with realistic email/calendar/IM simulators; continuous content refresh.
- Consumer/SMB — Personalized assistant pretraining on mirrored local computers
- Application: Build a local, privacy-preserving mirror of a user’s computer for an agent to practice and adapt before limited real-world access.
- Potential tools/products/workflows: One-time snapshot and redaction tool; on-device training; staged permissioning rollout.
- Assumptions/dependencies: Strong privacy guarantees; efficient on-device fine-tuning; secure isolation and data lifecycle management.
- AI Safety/ML — Large-scale agentic reinforcement learning for productivity
- Application: Run millions of synthetic computers and month-long trajectories to create a self-improvement loop for long-horizon planning, collaboration, and tool-use.
- Potential tools/products/workflows: “LongHorizonGym” with standardized rewards; curriculum scheduling; safety monitors for autonomy constraints.
- Assumptions/dependencies: Stable RL training with long credit assignment; robust reward models for process and outcome; cost-effective infrastructure.
- Sector-specific “AI apprentices”
- Healthcare: Admin/ops desktops (scheduling, prior auth packets, discharge summaries) for training hospital admin agents.
- Legal: Case-matter desktops with versioned briefs, exhibits, and redlines for legal drafting agents.
- Energy/Manufacturing: Maintenance logs, BOMs, and shift handover docs for planning and reporting agents.
- Assumptions/dependencies: Domain data availability or realistic synthesis; regulatory compliance (HIPAA, attorney-client privilege, safety standards); domain-tool integrations (EHR, DMS, CMMS).
- Regulators/Standards bodies — Compliance sandboxes and certification suites
- Application: “Compliance-in-a-box” synthetic desktops reflecting sectoral regulations (e.g., SEC Marketing Rule, procurement rules) for vendor certification and ongoing compliance checks.
- Potential tools/products/workflows: Standardized tasks, violation probes, and audit artifacts; third-party accredited test centers.
- Assumptions/dependencies: Inter-agency consensus on test scope; legal frameworks recognizing synthetic evaluations; update cadence for regulatory changes.
- Workforce augmentation — Multi-agent teams coordinating with simulated collaborators
- Application: Agents that negotiate requirements, request missing data, and incorporate redlines to deliver multi-artifact projects with minimal supervision.
- Potential tools/products/workflows: Collaboration simulators with realistic latencies; automatic role assignment; escalation policies to humans.
- Assumptions/dependencies: Reliable intent grounding; robust failure recovery; human-in-the-loop oversight and liability frameworks.
- Software lifecycle — Agent regression testing across OS/app versions and histories
- Application: Validate that model or app updates do not degrade long-horizon behaviors across varied OS images, app versions, and evolving file graphs.
- Potential tools/products/workflows: Version matrix scheduler; change-impact analysis; anomaly detection on process metrics.
- Assumptions/dependencies: Licensing for OS/app images; snapshotting/restore at scale; standardized scoring.
- Continuous process optimization and A/B testing
- Application: Iterate on playbooks and toolchains within synthetic desktops, then port best practices to production teams.
- Potential tools/products/workflows: Auto-generation of alternative weekly plans; statistical comparison of outcomes; reinforcement of winning strategies.
- Assumptions/dependencies: Validity of synthetic-to-real transfer; linkage to business KPIs; change management.
- Data ethics and safe-handling training for agents
- Application: Train agents to request consent, minimize PII exposure, and comply with redaction policies using realistic-but-fake sensitive artifacts.
- Potential tools/products/workflows: Policy feedback loops; “consent required” gates; auditability reports for external review.
- Assumptions/dependencies: Mature policy ontologies; measurement of policy adherence; alignment methods to avoid prompt-exploit circumvention.
- Autonomous knowledge base maintenance
- Application: Agents that keep models, policies, and templates fresh by detecting stale references and regenerating updated artifacts across file dependency graphs.
- Potential tools/products/workflows: Dependency-aware refresh schedulers; approval workflows for changes; change logs linking sources to updates.
- Assumptions/dependencies: Trust and verification pipelines; human review for critical artifacts; version-control systems for documents.
- Education/Workforce development — Scalable virtual internships across professions
- Application: Students and reskilling workers complete multi-week projects within sector-specific synthetic desktops, graded on both process and deliverables.
- Potential tools/products/workflows: Credentialing tied to long-horizon performance; mentor AI feedback; interoperability with job platforms.
- Assumptions/dependencies: Fairness and accessibility considerations; anti-cheating mechanisms; ongoing content curation.
- Consumer productivity — Household digital twin for task planning
- Application: Simulate budgeting, tax prep, home projects, and trip planning with synthetic documents and calendars to train/personalize home assistants.
- Potential tools/products/workflows: Personal “home office” synthetic desktops; connectors for safe synthetic-to-real transitions; explainable plans with citations.
- Assumptions/dependencies: Data privacy and consent; secure connectors to financial/tax providers; clear boundaries on autonomous actions.
Glossary
- Agent runtime: The wall-clock compute time the agent requires to execute a full simulation run. "each run requires over 8 hours of agent runtime"
- Agentic reinforcement learning: Reinforcement learning approaches where autonomous agents improve through their own experience and interactions. "agentic reinforcement learning in long-horizon productivity scenarios."
- Alternatives sleeve: A dedicated portfolio allocation slice for alternative assets (e.g., real estate, commodities, liquid alternatives). "hold a 5--10\% alternatives sleeve."
- Assets Under Management (AUM): The total market value of assets an advisor or firm manages on behalf of clients. "Manages \$285M AUM."
- Basis points (bps): One hundredth of a percentage point (0.01%); used to measure small changes in rates or allocations. "any model change 150\,bps requires sensitivity analysis."
- Bloomberg terminal: A professional financial data and analytics platform used for market data and analysis. "Bloomberg terminal exports"
- Capital market assumptions: Long-term forecasts for returns, risk, and correlations across asset classes used in portfolio design. "10-year capital market assumptions"
- CFA charterholder: A professional designation from the CFA Institute denoting expertise in investment management. "CFA charterholder (2013)"
- CFP (Certified Financial Planner): A professional certification for financial planners indicating proficiency in personal financial advising. "CFP certified (2010)"
- CIO (Chief Investment Officer): The executive responsible for overseeing an organization’s investment strategy. "Nathaniel Ortiz --- CIO and IC voting member."
- Crisis-regime correlations: Correlation patterns between assets during market stress periods, which can differ from normal times. "crisis-regime correlations"
- Delta table: A tabular summary showing changes (deltas) between two datasets or models across categories. "summary delta table"
- Dependency-aware order: An execution sequence that respects dependencies among items (e.g., files), so prerequisites are handled first. "we use a dependency-aware order"
- Directed dependency graph: A graph where edges encode directional dependencies (e.g., file A is derived from file B). "we construct a directed dependency graph over planned files."
- Drift-band asymmetry: Using unequal tolerance bands for deviations from target allocations, often varying by risk tier. "drift-band asymmetry"
- Drift thresholds: Predefined tolerances for how far portfolio allocations may deviate from targets before triggering rebalancing. "drift thresholds"
- DOL guidance: U.S. Department of Labor regulatory guidance affecting investment advice and plan management. "2024 DOL guidance"
- ESG (Environmental, Social, and Governance): Investment considerations that account for sustainability and ethical factors. "ESG equity overlay evaluation."
- Experiential learning signals: Training signals derived from the process and outcomes of agents’ real or simulated experiences. "These simulations produce rich experiential learning signals"
- Filesystem policy: A set of conventions governing directory layout, naming, storage, and organization on a machine. "generate a user-specific filesystem policy"
- Forward-return differentials: Differences in expected forward-looking returns between assets or configurations used for allocation decisions. "forward-return differentials"
- Grounding: Tying an agent’s actions or reasoning to concrete, context-specific data or files to maintain relevance. "navigating the filesystem for grounding"
- High-net-worth (HNW): A client segment characterized by substantial investable assets (commonly $1M+). "Robert Castellano HNW Onboarding Package"
- Investment Committee (IC): A governance body that reviews and approves investment policies and portfolio changes. "Investment Committee for formal adoption."
- Investment Policy Statement (IPS): A formal document outlining a client’s investment objectives, constraints, and strategy. "IPS v1"
- LDI (Liability-Driven Investing): An investment approach aligning portfolios with the timing and size of liabilities. "LDI specialist."
- Liquid alts: Liquid alternative investments (e.g., mutual funds or ETFs) providing alternative exposures with daily liquidity. "liquid alts"
- Long-horizon: Referring to tasks or simulations spanning extended timeframes and many steps/turns. "long-horizon productivity simulation"
- Monte Carlo: A stochastic simulation method that estimates outcomes by repeated random sampling. "incorporating Monte Carlo and VCMM outputs"
- Morningstar Direct: An institutional investment research and data platform used for analysis and reporting. "and Morningstar Direct."
- Out-of-domain evaluations: Tests conducted on tasks or data distributions that differ from those seen during training. "out-of-domain productivity evaluations."
- Persona-driven synthetic data creation: Generating data by expanding high-level user personas into detailed, context-rich environments. "persona-driven synthetic data creation methodology"
- REITs (Real Estate Investment Trusts): Investment vehicles that own or finance income-producing real estate. "REITs, commodities, liquid alts"
- Repository-grounded coding agents: Coding assistants that operate with direct access to code repositories for context. "repository-grounded coding agents (e.g., Cursor)"
- Rebalancing trigger framework: A rule-based system defining when portfolio rebalancing should occur based on drift and other signals. "Systematic Rebalancing Trigger Framework v3"
- Roth conversion: Moving funds from a traditional retirement account to a Roth account, triggering taxation in exchange for future tax-free growth. "Roth conversion"
- SEC Marketing Rule 206(4)-1: A U.S. Securities and Exchange Commission rule governing investment advisor marketing and advertising. "under SEC Marketing Rule 206(4)-1 and 2024 DOL guidance."
- Sustainalytics: A prominent ESG data and ratings provider used for screening and analysis. "Sustainalytics-screened ESG overlays"
- Synthetic computer: A fully populated, user-specific virtual computer environment constructed for simulation. "Given a synthetic computer, we run a long-horizon simulation"
- Tax-lot awareness: Recognizing individual purchase lots for assets to account for tax implications when trading. "tax-lot awareness"
- Tax-lot scoring: A method to rank or score lots based on tax costs to guide tax-efficient trading. "tax-lot scoring formula"
- VCMM (Vanguard Capital Markets Model): Vanguard’s multi-asset forecasting model producing long-term return and risk projections. "VCMM 2026 dataset"
- VBA (Visual Basic for Applications): A scripting language embedded in Microsoft Office used for automating tasks. "with VBA macros"
- Virtual time axis: A simulated timeline used to timestamp files and events to mimic real work histories. "virtual time axis"
- Web-downloadable artifact: A file planned to be retrieved directly from the public web rather than synthesized. "a public, web-downloadable artifact"
Collections
Sign up for free to add this paper to one or more collections.

