- The paper introduces a novel algorithm that integrates scaling matrices and a modified non-monotone line search to improve convergence in constrained optimization.
- The method rigorously establishes global convergence and achieves a linear rate for strongly quasiconvex objectives under standard assumptions.
- Empirical evaluations on fractional and quadratic programming benchmarks demonstrate significant improvements in iteration efficiency and numerical stability.
Scaled Gradient Modified Non-Monotone Line Search for Constrained Optimization
Introduction and Motivation
The paper "A Scaled Gradient Modified Non-monotone Line Search Method for Constrained Optimization Problems" (2604.28110) introduces an algorithmic framework for solving constrained minimization problems with differentiable objective functions over closed convex sets. The primary innovation lies in augmenting the scaled gradient projection (SGP) methods with a modified non-monotone line search. This integration leverages a scaling matrix within the projection step and a non-monotone line search incorporating dual curvature and stability parameters, aiming to improve convergence rates, especially for strongly quasiconvex and pseudo-convex functions.
Monotone line search strategies, foundational in iterative gradient-based methods, guarantee descent in the objective at each iteration but can impede progress in regions of narrow valleys or require unnecessarily conservative step sizes. Non-monotone approaches relax this constraint, permitting occasional increases in the objective and potentially offering improved navigation of complex landscapes and faster global convergence. The innovation here extends these ideas to the setting of SGP methods, previously explored for unconstrained and constrained convex minimization, by enhancing the line search mechanism and rigorously establishing linear convergence under strong quasiconvexity.
Algorithmic Framework
The core algorithm, termed the Scaled Gradient Modified non-monotone (SGM) method, operates on the canonical problem:
minx∈Kf(x)
where K⊆Rn is nonempty, closed, and convex, and f is continuously differentiable—potentially non-convex but pseudo-convex or strongly quasiconvex.
Key Steps
- Scaled Projected Update: The direction dk is defined via the scaled projection onto K in the metric induced by a symmetric positive definite matrix Dk:
yk=PK,Dk−1(xk−αkDk∇f(xk)),dk=yk−xk
- Non-monotone Line Search: The step size λk is adapted with respect to a non-monotone Armijo-type condition:
f(xk+λkdk)≤Tk+δ1λk∇f(xk)Tdk−δ2λk2∥dk∥2
where Tk, a convex combination of past and present function values, regulates non-monotonicity.
- Iterate Advancement and Parameter Updates: Once an admissible step size is found, the algorithm advances (K⊆Rn0) and updates the reference term K⊆Rn1 for the next iteration.
Crucially, the inclusion of the scaling matrix K⊆Rn2 (often chosen as an approximation to the Hessian or its diagonal) tailors the geometry of the projection, addressing issues of ill-conditioning and anisotropic curvature—common challenges in high-dimensional and structured optimization.
Convergence Properties
Global Convergence and Error Bounds
The algorithm is shown, under standard assumptions (bounded level set, Lipschitz gradient, nonempty solution set, descent condition), to globally converge to stationary points of the variational inequality:
K⊆Rn3
which, for pseudo-convex K⊆Rn4, coincides with minimizers of the original optimization. The paper derives explicit bounds on the decrease in both function suboptimality and gradient norm per iteration, exploiting the structure induced by the scaling and the non-monotone search.
Linear Convergence Under Strong Quasiconvexity
A central theoretical contribution is the linear convergence rate established for strongly quasiconvex objectives. Formally, for a unique minimizer K⊆Rn5:
K⊆Rn6
This is a significant improvement over the K⊆Rn7 rates typical for standard SGP and related methods when only assuming strong convexity. The proof leverages error bounds relating the gradient norm to suboptimality and uses properties of strongly quasiconvex functions to control progress tightly.
Numerical Stability and Stepsize Control
The paper also provides bounds for admissible step sizes and establishes robustness to parameter choices by proving that the Armijo-type line search criterion is always satisfiable under mild regularity.
Empirical Evaluation
Fractional and Quadratic Programming Benchmarks
The algorithm is empirically quantified on several classes of problems:
- Fractional Programming: Optimization of non-convex, pseudo-convex fractional objectives over box constraints.
- Large-Scale Fractional Programming: Strongly quasiconvex ratios with high dimensions and structured feasible sets.
- Quadratic Programming: Classical convex quadratic objectives with linear constraints, including high-dimensional cases relevant to statistical learning.
For each benchmark, SGM is compared against the YWH [Yan et al., 2018] and ZH [Zhang & Hager, 2004] methods. Performance metrics include iteration count, CPU time, and terminal errors measured in function value gap and gradient norm.
Convergence Visualization
In all tested scenarios, SGM exhibits superior iteration and time efficiency, consistently achieving lower errors in fewer steps. The scaling matrix is particularly beneficial as problem dimension increases or when the objective exhibits poorly conditioned curvature.
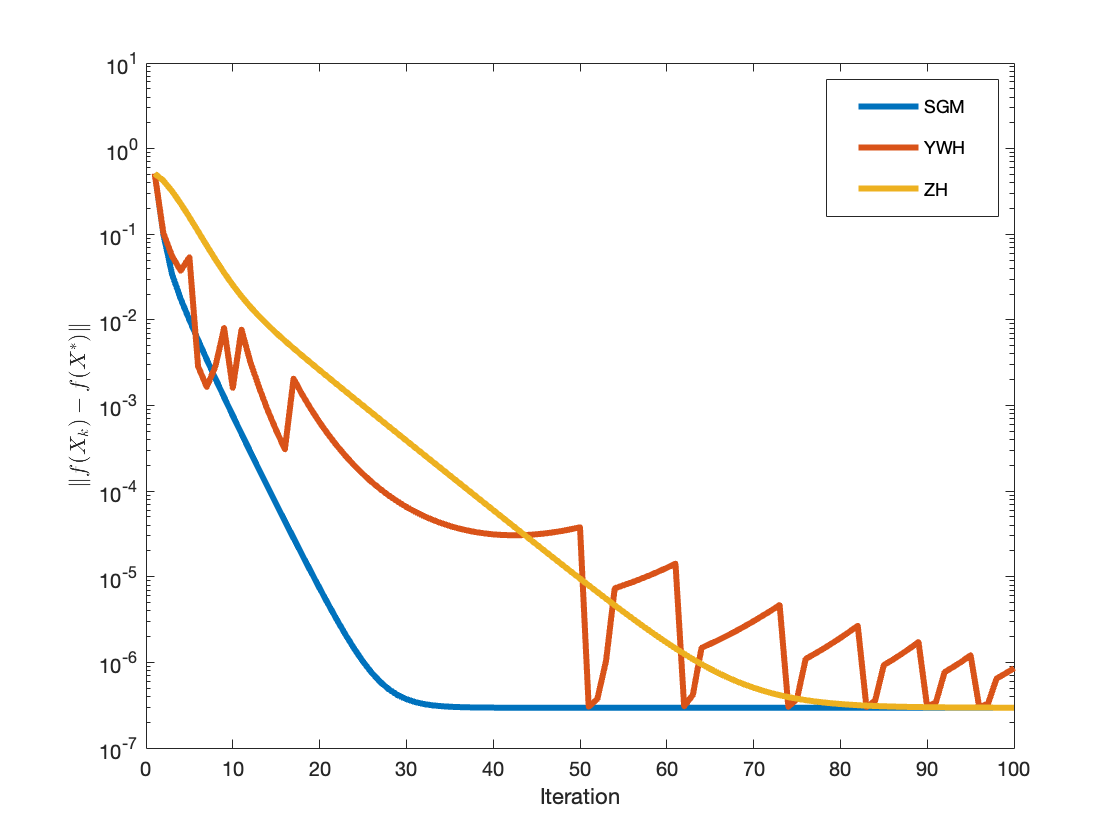
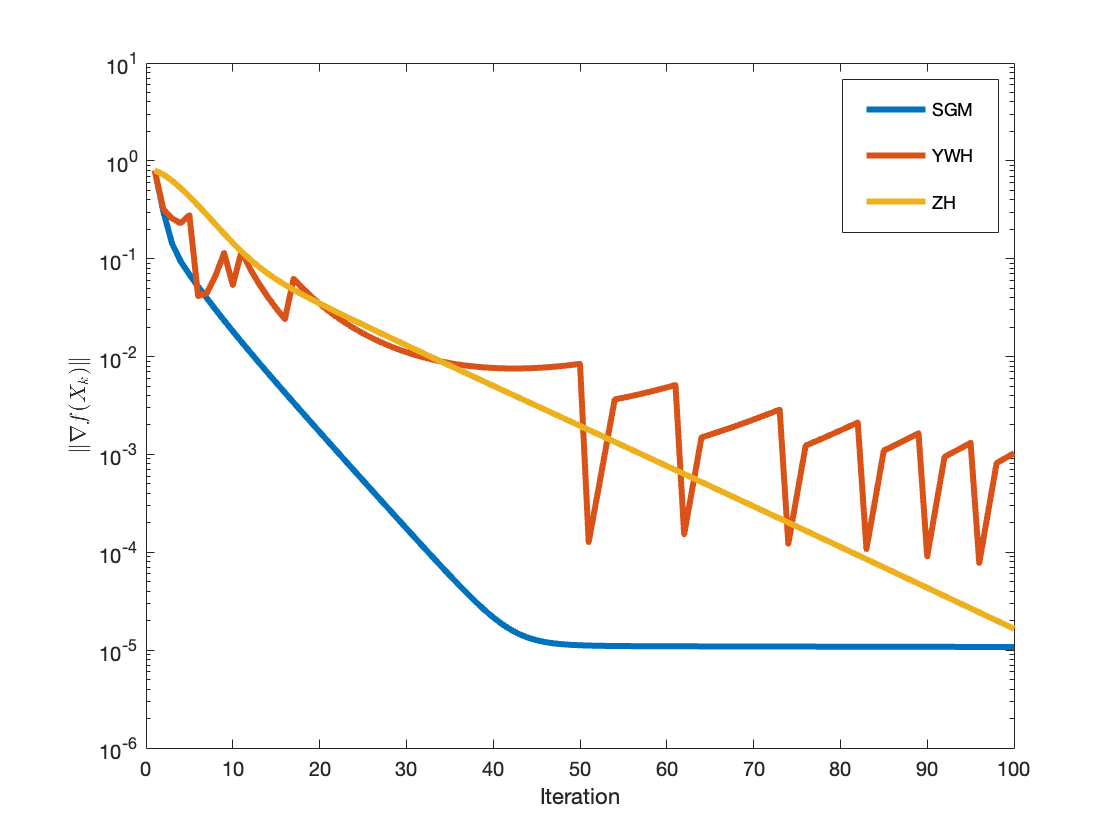
Figure 1: Convergence of function gap and gradient norm for Example 1 (fractional programming), SGM vs. YWH and ZH.
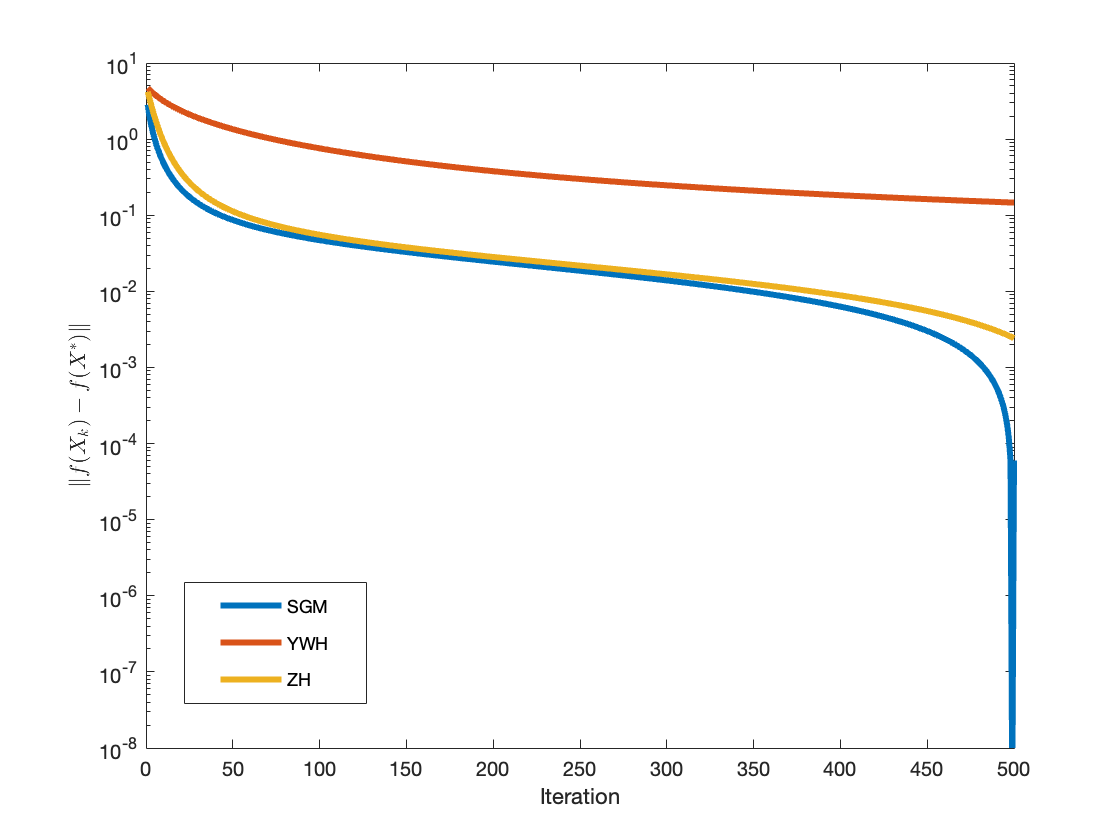
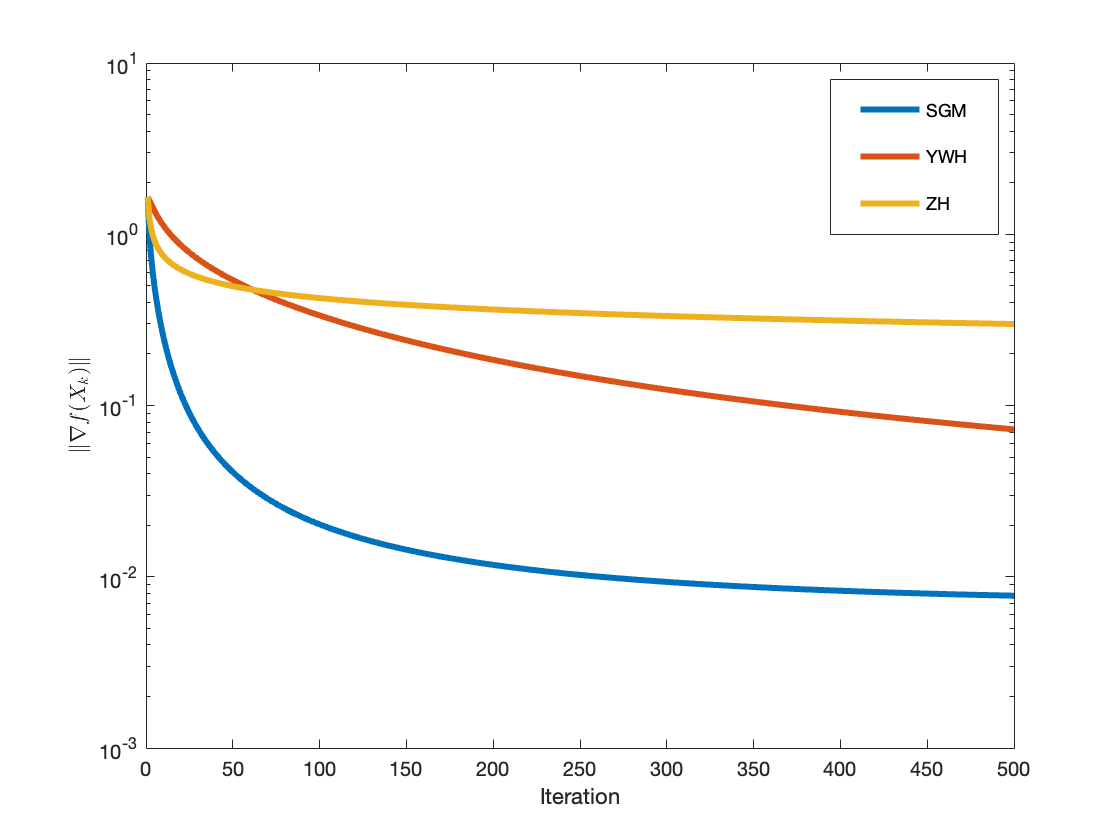
Figure 2: Convergence results for large-scale fractional programming (Example 2), comparing SGM, YWH, and ZH methods.
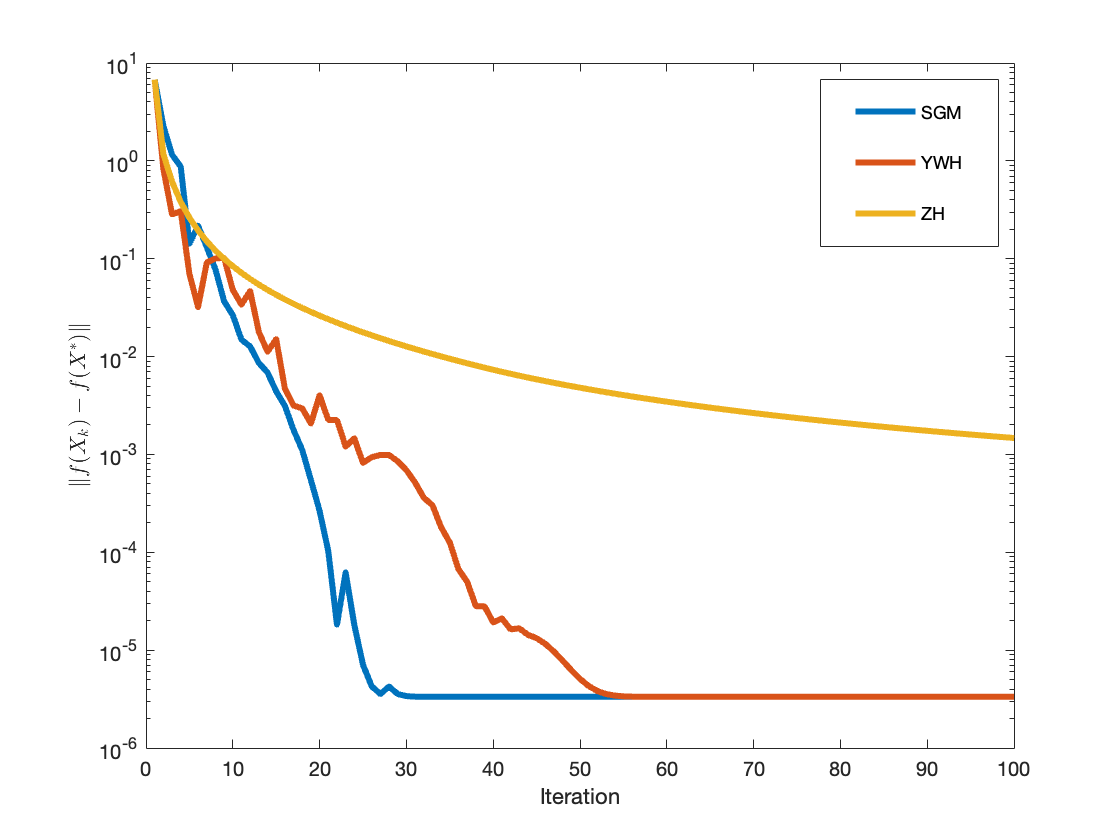
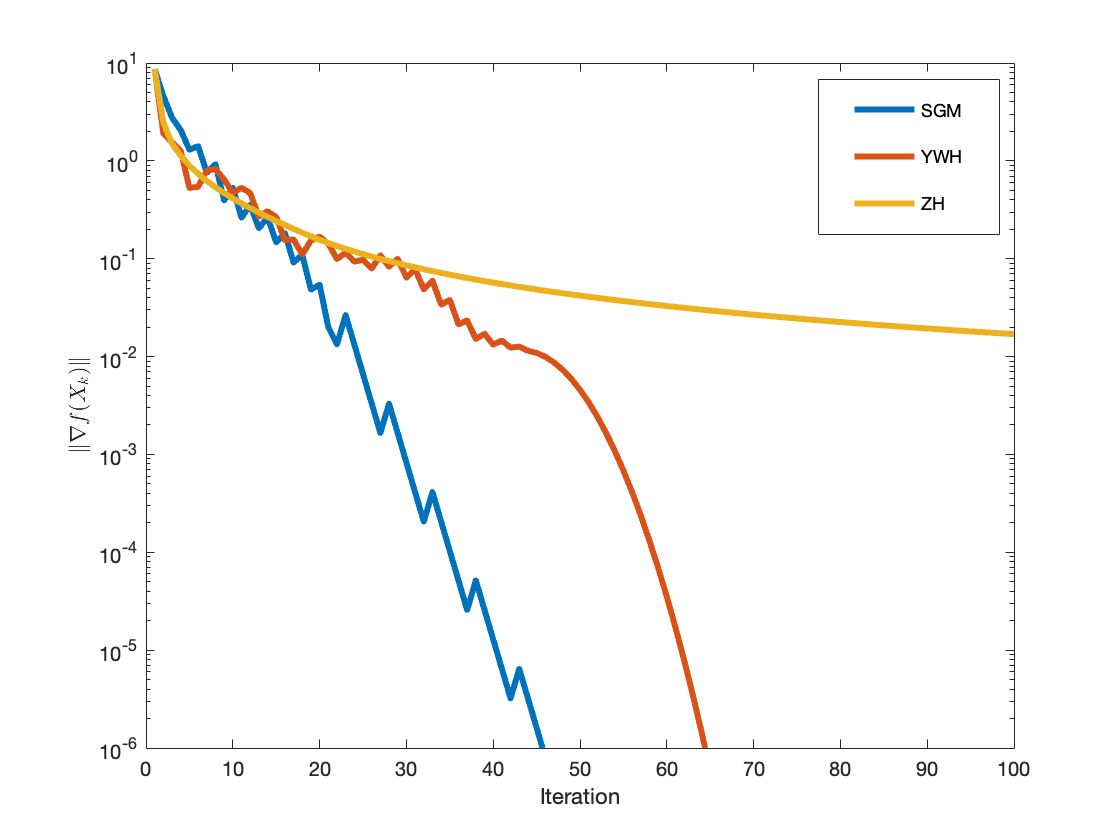
Figure 3: Convergence behaviour for quadratic programming (Example 3), highlighting rapid progress of SGM over alternatives.
The empirical results highlight marked acceleration in convergence and convergence stability when non-Euclidean projections are utilized, validating the theoretical claims.
Practical and Theoretical Implications
- Adaptation to Curvature and Sparsity: The inclusion of scaling matrices in the update step enables better adaptation to the intrinsic geometry of the feasible region and objective, especially valuable for large, sparse, or highly anisotropic problems common in signal processing, statistical learning, and image reconstruction.
- Generalization Beyond Convexity: By accommodating pseudo-convex and strongly quasiconvex objectives (via variational inequality connections), the method extends applicability to broader classes of non-convex programs encountered in engineering and machine learning.
- Algorithmic Robustness: The non-monotone line search, coupled with dynamic reference functionals and curvature penalization, provides greater flexibility against stalling and erratic progress as compared to monotone linesearch or step-restricted methods.
- Scalability: The method is computationally competitive even for K⊆Rn8, with minimal per-iteration overhead compared to classical projections.
Future Directions
- Extensions to Composite and Nonsmooth Optimization: Further work could adapt the approach to encompass nonsmooth composite objective terms (e.g., regularized learning), potentially combining with proximal/forward-backward frameworks.
- Adaptive and Data-Driven Scaling Selection: While the paper uses the Hessian or its surrogate as the scaling matrix, online adaptation or learned metric selection could further improve empirical performance in very high-dimensional settings.
- Inexact and Stochastic Settings: Addressing inexact or noisy gradient/projection computations, as arise in large-scale data-driven optimization, is an important direction for practical deployment.
- Applications in Sparse PCA, Imaging, and Deep Learning: Given the link to sparse principal component analysis and other high-dimensional signal recovery tasks, applying and benchmarking this strategy in such areas may yield further insights.
Conclusion
This paper provides a detailed analysis and practical demonstration of a scaled gradient modified non-monotone line search method, establishing improved global convergence guarantees—including linear convergence under strong quasiconvexity—in constrained differentiable optimization. The integration of curvature-aware projections and flexible linesearch delivers significant empirical gains, particularly for challenging, large-scale, or poorly conditioned problems. This approach broadens the scope of efficient gradient methods to wider classes of non-convex and structured problems, setting the stage for future advances in both algorithmic development and applications in scientific and machine learning domains.

