On the Expressive Power of GNNs to Solve Linear SDPs
Abstract: Semidefinite programs (SDPs) are a powerful framework for convex optimization and for constructing strong relaxations of hard combinatorial problems. However, solving large SDPs can be computationally expensive, motivating the use of machine learning models as fast computational surrogates. Graph neural networks (GNNs) are a natural candidate in this setting due to their sparsity-awareness and ability to model variable-constraint interactions. In this work, we study what expressive power is sufficient to recover optimal SDP solutions. We first prove negative results showing that standard GNN architectures fail on recovering linear SDP solutions. We then identify a more expressive architecture that captures the key structure of SDPs and can, in particular, emulate the updates of a standard first-order solver. Empirically, on both synthetic and \textsc{SdpLib} benchmarks of various classes of SDPs, this more expressive architecture achieves consistently lower prediction error and objective gap than theoretically weaker baselines. Finally, using the learned high-quality predictions to warm-start the first-order solver yields practical speedups of up to 80%.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at a kind of math problem called a semidefinite program (SDP). You can think of an SDP as a puzzle where you have to fill in a big table of numbers (a matrix) so it follows some rules and makes a score as small as possible. These puzzles show up in many real-world tasks, like splitting a network into balanced groups (max-cut), picking the largest set of non-overlapping items (max clique or independent set), or designing stable controllers in engineering.
The problem is that solving big SDPs exactly can be very slow. The authors ask: can a graph neural network (GNN)—a type of AI that learns by letting parts of a graph “talk” to each other—learn to quickly predict good answers to these puzzles?
What questions did the authors ask?
They focus on two simple questions, phrased in everyday terms:
- How “smart” does a GNN need to be to tell apart the different parts of an SDP and predict the correct solution?
- Can such a GNN not only predict solutions accurately, but also help traditional solvers finish faster?
How did they approach it?
To make the ideas accessible, here are the key pieces and analogies:
- SDPs are “matrix puzzles”: Instead of choosing single numbers (like in many simpler problems), you choose a whole grid of numbers (a matrix). This matrix must be “positive semidefinite,” which you can picture like a smooth bowl: it never curves downward in a way that would make it unstable.
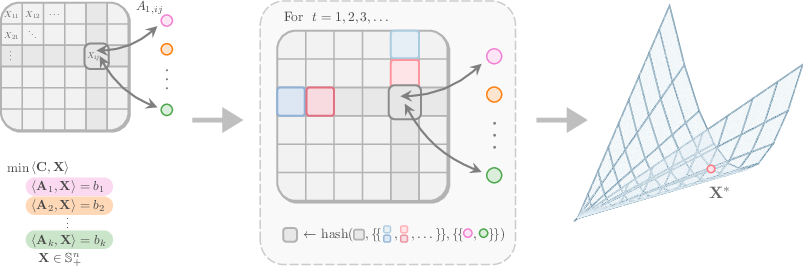
- GNNs as “message passing”: A GNN works on a graph (a network of dots and lines) where nodes send messages to neighbors. In optimization, you can build a graph with “variable nodes” (representing matrix entries you need to fill) and “constraint nodes” (the rules). The GNN tries to learn how to update variables by listening to their neighboring constraints.
- The challenge: symmetry and pairs. In SDPs, entries in the matrix are linked in special ways: the matrix is symmetric (the top-right and bottom-left entries match), and changing the order of rows/columns should change the solution in the same way (if you re-label rows and columns, the answer should just be re-labeled too). Basic GNNs that treat every entry separately tend to ignore these pair relationships and symmetries.
- A better idea: look at pairs together. The authors draw on a known idea from graph theory (the Weisfeiler–Leman, or WL, tests), which are ways to color or label nodes so you can tell structures apart. The basic version only looks at individual nodes; stronger versions look at pairs of nodes. Translating this to SDPs: instead of treating each matrix entry on its own, build a GNN that reasons about pairs that share a row or a column—capturing the “matrix geometry.”
- Three levels of GNN “expressiveness”: 1) A basic variable-constraint GNN (fast but not pair-aware). 2) A medium, pair-aware GNN that looks at rows and columns separately. 3) A stronger, joint pair-aware GNN that looks at row-and-column interactions together and respects symmetry automatically.
- Theory plus practice:
- The authors prove that the basic and medium GNNs can’t always tell apart entries that should get different values in the optimal SDP solution.
- They then design the stronger, joint pair-aware GNN and prove it’s expressive enough to mimic the update steps of a known first-order optimization method (a simple, fast solver called PDHG). In simple terms: their GNN can emulate a real solver’s moves.
- Finally, they train and test these GNNs on synthetic problems (like max-cut, max clique, independent set, vertex cover, max 2-SAT) and real benchmarks (SdpLib).
What did they find?
Here are the main results in simple terms:
- The basic GNNs fall short: They sometimes give the same “label” to different matrix spots that actually need different values, so they can’t reliably recover the right answers.
- The medium pair-aware GNN still misses key interactions: Looking at row and column information separately isn’t enough for SDPs.
- The strong joint pair-aware GNN works:
- In theory, it’s powerful enough to capture the structure of SDPs and imitate the steps of a standard solver.
- In experiments, it predicts solutions more accurately (lower error and smaller gap to the true best score) than the weaker GNNs, across many problem types.
- Its predictions are not only good in score but also “geometrically” close to valid SDP solutions (after checking the positive semidefinite requirement).
- When its predictions are used to “warm-start” a standard solver (give the solver a head start), the solver runs much faster—speedups of up to about 80% were observed on some benchmarks.
- It’s efficient in practice: The strong GNN runs quickly on a GPU and scales well, making it useful as a fast predictor or as a helper for classical solvers.
Why does this matter?
- Faster optimization: Many planning, scheduling, networking, and control tasks can be framed as SDPs. A GNN that quickly predicts high-quality solutions can save a lot of time, especially on big problems.
- Better AI design for math problems: This work gives a clear recipe for how expressive a neural network needs to be to handle matrix-shaped variables and symmetries. In other words, it’s a blueprint for building neural solvers that “think in pairs” when the problem demands it.
- Teamwork between AI and classic solvers: Instead of replacing solvers, the GNN can give them a strong starting guess, cutting down the time to reach a high-quality answer.
In short, the paper shows that to solve matrix-based optimization puzzles well, your neural network must reason about pairs of entries together and respect the problem’s symmetries. Doing so not only improves accuracy but can also make traditional solvers much faster.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list highlights concrete gaps and unresolved questions that remain after this work and can guide future research.
- Scope beyond linear SDPs:
- How to extend the expressivity results and architectures from equality-constrained linear SDPs (, ) to more general conic programs, including SDPs with inequality constraints, multiple PSD blocks, second-order and exponential cones, or general LMIs (e.g., constraints of the form )?
- Necessity vs. sufficiency of expressivity:
- Is folklore $2$-WL ($2$-FWL) not only sufficient but also necessary (up to mild assumptions) to recover optimal solutions of linear SDPs? Are there strictly weaker, yet practically simpler or cheaper, architectures that suffice on broad SDP subclasses?
- Subclass characterization:
- Precisely characterize SDP subclasses for which $1$-WL or standard $2$-WL would be sufficient (e.g., diagonal/block-diagonal structures, special sparsity patterns, or low treewidth instances). Can we give tight necessary and sufficient graph-structural conditions?
- Multi-solution regimes:
- The paper selects the minimum-Frobenius-norm optimal solution as a learning target. How does the approach behave when multiple optima exist in practice (e.g., different ranks)? Can the model learn to select solutions that are best for downstream rounding or application-specific criteria instead of Frobenius norm?
- Dual variables and certificates:
- Can the architecture be extended to predict dual variables and provide approximate or exact optimality certificates (e.g., dual feasibility, complementary slackness, small duality gaps) to yield trustable outputs and termination criteria?
- Feasibility guarantees in-network:
- The method does not enforce or by construction. Can we design layers or parameterizations (e.g., spectral/Cholesky parameterizations, constrained updates, differentiable projections) that guarantee PSDness and constraint satisfaction without post-hoc projection?
- Projection-aware learning:
- Given that PSD projection can significantly alter the objective for weaker models, can losses be designed to account for projection effects (e.g., train on projected outputs, or include penalties/augmented Lagrangians) to maintain feasibility and objective quality simultaneously?
- Scalability and memory:
- The representation maintains features for variable pairs, with per-iteration costs scaling as and memory as ; this is challenging for . What architectural or algorithmic strategies (e.g., low-rank factorization outputs, block structures, Kronecker sparsity, sketching, locality constraints, or hierarchical models) can reduce memory and compute while preserving the required equivariances?
- Low-rank and Burer–Monteiro formulations:
- Can one design equivariant models that operate directly on low-rank factors (with variables) while respecting the orthogonal invariance of factorized SDPs? How does $2$-FWL-like expressivity translate to factor-space architectures?
- Invariance beyond permutations:
- The paper enforces equivariance to simultaneous row/column permutations. Many practical formulations (e.g., Burer–Monteiro, rotationally symmetric domains) exhibit continuous symmetries (orthogonal invariances). Can models be made equivariant to these larger symmetry groups, and does this change the minimal required expressivity?
- Solver alignment and theoretical guarantees:
- The sufficiency proof is tied to simulating PDHG-style updates. How sensitive are the results to solver hyperparameters and variants (step sizes, preconditioning)? Can we extend the alignment and sufficiency results to other first-order methods (ADMM, primal–dual methods beyond PDHG) and interior-point methods?
- Training without ground truth:
- The approach relies on supervised training using exact solutions, which is infeasible for very large SDPs. Can we devise unsupervised or weakly supervised objectives (e.g., primal–dual residuals, differentiable duality gap proxies, KKT residuals) that enable training without oracle solvers?
- Generalization across sizes and distributions:
- Empirical evaluation largely uses fixed-size synthetic instances (e.g., 100 nodes) and a single real-world class (max-cut from SdpLib). How well do models trained on one size or distribution generalize to different sizes, densities, weight distributions, or to other SDP classes (community detection, sensor localization, quantum information, SOS relaxations)?
- Robustness and conditioning:
- How robust are predictions to scaling, ill-conditioning, or noise in , , and ? Are normalization schemes or conditioning-aware layers needed to maintain stability and accuracy across diverse regimes?
- Constraint heterogeneity:
- Many practical SDPs have heterogenous/batch constraints (e.g., multiple PSD constraints, inequality and equality mixes, block-diagonal structure). How should the representation and message-passing adapt to heterogeneous cones and mixed constraint types while retaining necessary equivariances?
- Integration with diverse solvers:
- Warm starts are only evaluated for SCS; do similar gains hold for MOSEK/IPM, SDPLR/Burer–Monteiro, or state-of-the-art specialized SDP solvers? What is the best way to inject predictions (primal, dual, or both) into each solver class to maximize speedups?
- Certificates and stopping criteria for warm starts:
- Can learned warm starts be coupled with adaptive stopping rules or certificate-aware schedules to guarantee convergence and accelerate termination while preserving solver reliability?
- Computational trade-offs among expressive baselines:
- While $2$-FWL is shown sufficient and empirically strong, the computational trade-offs among $2$-FWL, -2-WL, 2-IGN, and attention-based models remain only partially explored. Under what regimes (sparsity, structure) is each architecture preferable?
- Minimal injectivity and finite-precision effects:
- Theoretical arguments assume injective “hashing”-like maps. In practice, MLPs approximate such maps with finite precision. What are the risks of aliasing/collisions, and can we bound approximation error or design provably injective layers for continuous features?
- Boundary cases with solver behavior:
- How does the approach handle infeasible or unbounded instances, degenerate constraints, or rank-deficient settings where standard solvers struggle? Can the model detect infeasibility or provide diagnostics?
- Objective-aware vs. solution-aware training:
- The method trains on entrywise MSE to ground-truth . Would training to directly minimize objective error or duality gap improve robustness and downstream performance (e.g., cut values after rounding)?
- Rounding and downstream combinatorial performance:
- While the work focuses on recovering continuous SDP solutions, eventual application quality depends on rounding schemes (e.g., Goemans–Williamson for max-cut). How do different learned solution characteristics (rank, geometry) affect rounding performance, and can training be made rounding-aware?
- Benchmarks and coverage:
- Real-world evaluation is limited to max-cut in SdpLib. Additional domains (control LMIs with multiple PSD blocks, structural design, power systems, quantum SDP instances) are needed to assess practical generality and failure modes.
- Complexity constants and memory footprints:
- The bound is for color refinement; practical constants, GPU memory footprints, and batched-inference strategies at scale are not quantified. What are realistic resource limits and optimizations for ?
- Theoretical error-to-coloring links:
- Theorem-level statements relate stable color equality to equality of optimal entries. Can we bound the approximation error of learned networks (with finite width/depth) in terms of coloring refinement depth, graph parameters, or spectral properties of the instance?
- Constraint scaling and normalization:
- The impact of scaling , , and on learning dynamics and solver alignment is not analyzed. Are invariant or adaptive normalization schemes necessary to ensure stable training across heterogeneous datasets?
Practical Applications
Immediate Applications
Below are concrete, deployable uses that leverage the paper’s higher‑order, permutation‑equivariant GNN surrogate for linear SDPs (the 2‑FWL–equivalent architecture) and its demonstrated ability to warm‑start first‑order solvers with up to 80% runtime reduction.
- Sector: Software/Optimization Platforms
- What: Neural warm-start plugin for SDP solvers (e.g., SCS, MOSEK) to accelerate convergence on linear SDPs across domains.
- How: Use the paper’s 2‑FWL–equivalent GNN to predict a high-quality primal matrix X and optionally a PSD-projected variant; feed this as an initial iterate to a first-order solver (PDHG/ADMM/SCS) or an interior-point method; monitor residuals and duality gap; early stop.
- Tools/Products/Workflows: CVXPY/CVX “Neural Warm‑Start” module; a microservice that exposes GPU inference and returns X0; integration hooks for solver APIs; feasibility monitors (constraint residuals and PSD checks).
- Assumptions/Dependencies: Availability of representative training instances; predictions must be validated (feasibility/PSD cone projection) and corrected by the solver; GPU availability for inference; performance depends on distribution shift from training data.
- Sector: Energy/Power Systems
- What: Faster semidefinite relaxations for AC optimal power flow (OPF), state estimation, and contingency analysis where SDP relaxations are standard.
- How: Train the GNN on historical grid topologies and load scenarios to output warm-starts for OPF SDPs; run the classical solver to certify feasibility/optimality.
- Tools/Products/Workflows: Grid optimization pipeline with “SDP Surrogate + Solver”; scenario batching on GPU; operator dashboards showing runtime and residuals.
- Assumptions/Dependencies: Use of SDP relaxations in the workflow; grid changes must be within training distribution; safety requires solver verification; high-sparsity A tensor helps throughput.
- Sector: Wireless/Telecom
- What: Accelerated SDP-based beamforming and robust precoder design in MIMO systems.
- How: Train on channel realizations to predict near-optimal covariance/beamforming matrices; warm-start existing SDP solvers in the baseband optimization stack.
- Tools/Products/Workflows: RAN optimization module with a GNN pre-solver; batch inference per scheduling interval; on-device GPU/edge acceleration for rapid re-optimization.
- Assumptions/Dependencies: Channel models used in training must reflect deployment; solver must still enforce hard constraints and deliver certificates.
- Sector: Robotics/Automotive/Aerospace (Control)
- What: Speeding up LMI feasibility checks and controller synthesis (robust/stochastic control design often cast as LMIs/SDPs).
- How: Use GNN predictions as initial LMIs to reduce iterations for feasibility/optimality; integrate into toolchains for gain scheduling and robust MPC design.
- Tools/Products/Workflows: Control design IDE plugin that proposes LMI warm-starts; automated batch tuning over operating points.
- Assumptions/Dependencies: Certification remains the solver’s role; distribution shift across operating regimes needs monitoring; some MPC loops are QP—benefits apply where SDP/LMIs are used.
- Sector: Logistics/Supply Chain/Manufacturing (Combinatorial Optimization)
- What: Faster SDP relaxations for max-cut, MIS, vertex cover, and max-2SAT that support bounding/heuristics in larger pipelines.
- How: Use the GNN to compute high-quality relaxations quickly, then round to discrete solutions or pass to branch-and-bound as bounds/warm-starts.
- Tools/Products/Workflows: OR pipeline node (“SDP‑Relax‑GNN”) that returns bounds and candidate solutions; hybrid solvers combining MILP/GNN/SDP.
- Assumptions/Dependencies: Rounding quality is problem-dependent; ensure final feasibility via traditional methods; dataset of typical instance families improves generalization.
- Sector: Quantum Information/Communications
- What: Accelerate large SDPs used for entanglement detection, channel capacity bounds, and device-independent certification.
- How: Pre-train on problem templates (e.g., symmetry classes) to seed solvers with strong primal matrices; reduce time per instance in large parameter sweeps.
- Tools/Products/Workflows: Research lab workflow integrating neural warm-start for iterative SDP experiments; batched GPU inference.
- Assumptions/Dependencies: Strong sensitivity to problem structure; final certificates must come from the solver.
- Sector: Finance/Risk
- What: Speed up robust portfolio optimization and covariance-aware risk models that are posed as linear SDPs (or close variants).
- How: Use neural predictions to initialize SDPs across many scenarios/backtests; solver refines to certified solutions.
- Tools/Products/Workflows: Portfolio analytics backtesting engine with neural warm-start; scenario farm with GPU inference.
- Assumptions/Dependencies: Applicability depends on the firm’s use of SDP formulations; regulatory compliance requires solver-verified outputs.
- Sector: Electronic Design Automation (EDA)
- What: Faster SDP-based subproblems (e.g., robust circuit sizing, timing/yield optimization) where convex relaxations arise.
- How: Train on design families/blocks to predict warm-starts for recurring SDP subproblems; iterate with solver until certified.
- Tools/Products/Workflows: EDA tool plugin for “Neural SDP Seed” in optimization loops; CI pipelines that retrain on new IP blocks.
- Assumptions/Dependencies: Availability of representative design data; IP confidentiality; maintain solver certification for sign-off.
- Sector: Academia/Education
- What: Teaching toolkit for optimization and graph ML expressivity; reproducible benchmarks connecting WL hierarchy to SDP solution quality.
- How: Use the codebase to demonstrate failure of 1‑WL/2‑WL and sufficiency of 2‑FWL‑style architectures; lab assignments comparing warm-start gains.
- Tools/Products/Workflows: Course modules with notebooks; open datasets covering LP/QP/SOCP/SDP families.
- Assumptions/Dependencies: GPU access for labs; curated instance distributions.
- Cross-cutting (Sustainability/Policy within organizations)
- What: Reduce compute time and energy for recurring SDP workloads by neural warm-starting.
- How: Track kWh saved via reduced iterations; integrate into internal sustainability dashboards.
- Tools/Products/Workflows: “Green Optimization” reporting; policy to retain solver-in-the-loop for safety.
- Assumptions/Dependencies: Benefits accrue when SDPs are frequent and structurally similar; auditable logs required.
Long-Term Applications
The following opportunities require further research, scaling, or ecosystem development before broad deployment.
- Sector: Software/Optimization Theory
- What: End-to-end neural SDP solvers with verifiable certificates (predictor–corrector hybrids that provide tight duality-gap bounds).
- How: Couple the 2‑FWL GNN with certified post-processing (e.g., dual reconstruction, robust PSD projection, interval bounds); design confidence metrics for automatic fallback.
- Assumptions/Dependencies: New theory for guaranteed feasibility/optimality bounds; robust uncertainty estimation; standardized certification protocols.
- Sector: Autonomous Systems/Robotics
- What: ML-accelerated SDP/LMIs inside real-time MPC loops with formal safety guarantees.
- How: Use neural warm-starts plus fast correctors in time-critical control cycles; verify constraint satisfaction online.
- Assumptions/Dependencies: Real-time deadlines; safety cases; hardware acceleration; predictable worst-case iteration counts.
- Sector: Energy and Telecom (At Scale)
- What: City- or nation-scale deployment for grid and RAN optimization with federated or privacy-preserving learning of warm-start models.
- How: Train site-specific surrogates locally; share model updates without raw data; centralize certification policies.
- Assumptions/Dependencies: Privacy, data governance, and interoperability standards; robust handling of distribution shift (storms, outages, new hardware).
- Sector: Combinatorial Optimization (Decision Quality)
- What: Rounding-aware learning that produces low-rank, structure-preserving SDP solutions tailored to superior discrete solutions after rounding.
- How: Jointly train surrogate and rounding heuristics; incorporate rank-minimization priors; learn problem-specific rounding maps.
- Assumptions/Dependencies: Nontrivial training signals for discrete objectives; careful evaluation to avoid heuristic brittleness.
- Sector: Hardware Acceleration
- What: Specialized kernels for 2‑FWL‑style message passing on symmetric matrix variables and joint row/column aggregations.
- How: Implement fused GPU primitives or FPGA/ASIC blocks for pairwise feature aggregation and PSD-aware operations (eigendecompositions).
- Assumptions/Dependencies: Engineering effort and ecosystem support; economic justification via workload scale.
- Sector: Scientific Computing/Math Programming
- What: Automated relaxation advisor that selects/designs SDP (or SOCP/LP) relaxations guided by learnability and solver performance.
- How: Learn mappings from problem templates to relaxation choices and warm-start policies; meta-learn across problem families.
- Assumptions/Dependencies: Large corpora of solved problems; metrics for “learnability” vs. tightness; human-in-the-loop oversight.
- Sector: Large-Scale and Sparse SDPs
- What: Scaling to n>104 through block structure, chordal decomposition, and graph partitioning integrated with higher-order GNNs.
- How: Hierarchical surrogates on decomposed SDPs; cross-block message passing; distributed multi-GPU inference and solver coupling.
- Assumptions/Dependencies: Reliable detection of sparsity/structure; communication-efficient training/inference; compatible decomposed solvers.
- Sector: Reliability/Trustworthiness
- What: Runtime monitors and formal audits for ML-in-the-loop optimization (alerts for constraint violations, drift, or certification failures).
- How: Shadow-solving on a subset of instances; conformal prediction of objective gaps; automated escalation and fallback rules.
- Assumptions/Dependencies: Organizational policies; telemetry standards; incident response playbooks.
- Sector: Education/Community Standards
- What: Benchmark suites unifying WL-expressivity with optimization tasks (LP/QP/SOCP/SDP), plus standardized reporting of speedups, gaps, and feasibility.
- How: Community challenges; leaderboards tracking objective gap, residuals post-projection, and solver time saved.
- Assumptions/Dependencies: Broad community adoption; reproducibility infrastructure.
- Cross-cutting (Policy and Governance)
- What: Guidelines for deploying neural accelerators in critical optimization (energy, transport, healthcare) with safety and accountability.
- How: Require solver verification; document training distributions and known failure modes; mandate fallback and audit trails.
- Assumptions/Dependencies: Sector-specific regulation; consensus on acceptable residuals/gaps and certification thresholds.
Key Assumptions and Dependencies (common across applications)
- Problem scope: The method targets linear SDPs; extensions to nonlinear or nonconvex problems require further research.
- Data: Effective training requires representative instance distributions; benefits degrade under large distribution shifts.
- Feasibility: Predicted matrices may be near‑feasible but still require solver correction; PSD projection and constraint residual checks are necessary.
- Compute: Inference is fast on GPUs; training cost must be amortized over recurring workloads.
- Guarantees: Final guarantees (feasibility, optimality) come from classical solvers; ML components should be positioned as accelerators, not replacements, in safety‑critical contexts.
Glossary
- ADMM (Alternating Direction Method of Multipliers): A first-order optimization method that splits problems into subproblems solved iteratively with dual updates. Example: "a first-order solver based on the ADMM algorithm"
- adjoint operator: The linear operator that reverses the action of another linear operator with respect to an inner product. Example: "its adjoint operator"
- atomic type: In WL tests, the initialization labeling that indicates whether two nodes are identical and/or adjacent. Example: "the #1{atomic type}"
- Burer–Monteiro method: A low-rank factorization approach for solving SDPs by optimizing over matrix factors. Example: "Burer-Monteiro method"
- color refinement: The 1-dimensional WL procedure that iteratively refines node colors based on neighbor colors. Example: "#1{color refinement}"
- combinatorial optimization (CO): Optimization over discrete structures such as graphs, often NP-hard. Example: "#1{combinatorial optimization} (CO)"
- convex optimization: Optimization of convex objectives over convex sets, guaranteeing global optima. Example: "convex optimization"
- equivariance (permutation equivariance): A property of mappings that commute with input permutations, producing correspondingly permuted outputs. Example: "permutation-equivariant functions"
- first-order solver: An optimization algorithm that uses gradient (and possibly simple proximal) steps without second-order information. Example: "a standard first-order solver"
- folklore 2-dimensional Weisfeiler–Leman (2-FWL): A more expressive WL variant on node pairs that aggregates joint configurations with a third node. Example: "#1{folklore $2$-dimensional Weisfeiler--Leman} ()"
- Frobenius norm: The square root of the sum of the squares of all entries of a matrix; the Euclidean norm of the matrix viewed as a vector. Example: "minimum Frobenius norm"
- graph isomorphism tests: Algorithms that attempt to distinguish non-isomorphic graphs, such as WL refinements. Example: "graph isomorphism tests"
- graph neural networks (GNNs): Neural architectures operating on graphs via permutation-invariant/equivariant operations. Example: "Graph neural networks (GNNs) are a natural candidate"
- interior point method (IPM): A class of second-order convex optimization algorithms that traverse the interior of the feasible region. Example: "#1{interior point method} (IPM) solvers"
- KKT conditions: Necessary optimality conditions (Karush–Kuhn–Tucker) for constrained optimization problems. Example: "KKT conditions"
- learning-to-optimize (L2O): Using learned models to replace or accelerate optimization routines. Example: "#1{learning-to-optimize} (L2O)"
- linear matrix inequality (LMI): A constraint of the form A(x) ⪰ 0 where A is an affine matrix function; a central object in control and SDP. Example: "linear matrix inequality (LMI) problems"
- message-passing neural networks (MPNNs): GNNs that update node features by aggregating and transforming messages from neighbors. Example: "#1{Message-passing neural networks} (MPNNs)"
- objective gap: The difference (often relative) between a predicted objective value and the optimal objective value. Example: "objective gap"
- positive semidefinite (PSD) cone: The set of symmetric matrices with nonnegative eigenvalues; the feasible cone in SDPs. Example: "#1{positive semidefinite} (PSD) cone"
- primal–dual hybrid gradient (PDHG): A first-order primal–dual algorithm for convex optimization using alternating gradient-like updates. Example: "#1{primal-dual hybrid gradient} (PDHG) algorithm"
- semidefinite programming (SDP): Convex optimization over the cone of PSD matrices with linear objective and constraints. Example: "#1{Semidefinite programming} (SDP) is a cornerstone"
- spectral decomposition: The eigenvalue–eigenvector factorization of a symmetric matrix, often used for PSD projections and solver steps. Example: "spectral decomposition"
- stable coloring: The fixed-point coloring produced when a WL refinement no longer changes. Example: "#1{stable coloring}"
- standard 2-dimensional Weisfeiler–Leman (2-WL): The WL variant on node pairs that aggregates separate multisets of pairwise interactions with a third node. Example: "the #1{folklore} () and #1{standard} () variants differ"
- variable–constraint (V–C) graph: A bipartite representation where variables and constraints are nodes with edges encoding nonzero coefficients. Example: "variable-constraint (V-C) graph"
- warm-start: Initializing an optimization algorithm with a nontrivial, often high-quality, starting point to speed convergence. Example: "warm-start the first-order solver"
- Weisfeiler–Leman (WL) hierarchy: A family of increasingly powerful color-refinement procedures for graph representation and isomorphism testing. Example: "Weisfeiler--Leman (\textsf{WL}) hierarchy"
Collections
Sign up for free to add this paper to one or more collections.