- The paper demonstrates a novel approach by modeling policy gradients as Gaussian processes via Bayesian quadrature, significantly reducing variance compared to Monte Carlo methods.
- It introduces both vector-valued and scalar-valued GP models with Fisher kernels to yield closed-form posterior moments, ensuring analytical tractability and faster convergence.
- The study further proposes a Bayesian actor-critic framework that leverages transition-level data for robust performance under noisy rewards and sample constraints.
Bayesian Policy Gradient and Actor-Critic Algorithms: Technical Summary
Policy Gradient Foundations and Bayesian Quadrature
The paper develops two core innovations for reinforcement learning (RL): Bayesian approaches to policy gradient estimation and actor-critic algorithms. Conventional policy gradient (PG) methods utilize Monte Carlo (MC) techniques, yielding unbiased but high-variance estimates of ∇η(θ), where η(θ) is expected return. To address sample inefficiency, this work introduces Bayesian Quadrature (BQ), modeling the policy gradient as a Gaussian Process (GP). The Bayesian framework allows accurate estimation of gradient means, natural gradients, and posterior covariance, reducing required samples.
Two computational models for Bayesian policy gradient are established:
- Model 1 (Vector-valued GP): f(ξ;θ)=R(ξ)∇θlogp(ξ;θ) is modeled as a vector GP, with g(ξ) deterministic. Kernel selection (quadratic Fisher kernel) admits analytical posterior moments.
- Model 2 (Scalar-valued GP): f(ξ)=R(ξ) is scalar GP, with g(ξ;θ)=∇θlogp(ξ;θ). The Fisher kernel enables tractable closed-form posterior computations.
Both models partition the integrand for BQ to ensure analytical tractability of posterior mean and covariance of the gradient. Empirically, the BQ-based estimates consistently achieve lower variance and higher accuracy than MC-based counterparts, even under noisy reward perturbations, as demonstrated quantitatively in linear quadratic regulator (LQR) experiments.
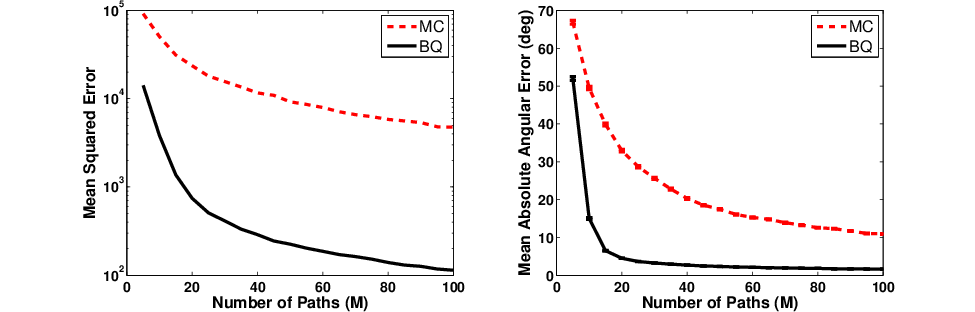
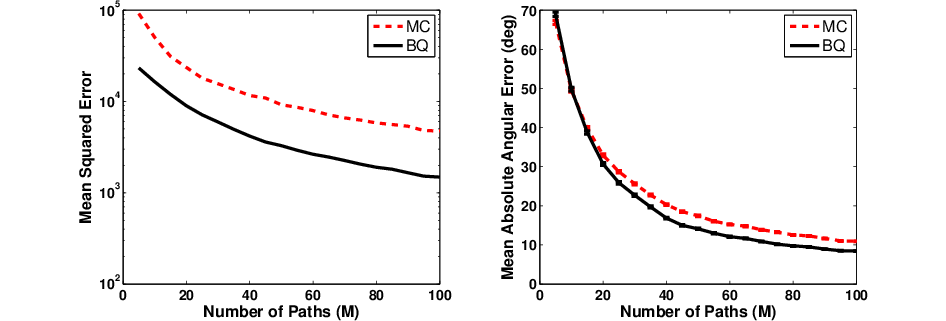
Figure 1: Mean squared error and mean absolute angular error for MC and BQ gradient estimates in LQR, comparing Model 1 and Model 2 under varying sample sizes.
Empirical Results and Comparative Analysis
Extensive experiments on bandit, LQR, random walk, mountain car, and ship steering domains rigorously benchmark Bayesian algorithms against MC-based methods. BQ estimates outperform MC estimators decisively, especially for moderate-to-large sample sizes (M≥10). The reduction in estimation variance is several orders of magnitude, leading to faster convergence in policy optimization. In noisy reward settings, BQ remains robust, with error profiles virtually unchanged by added Gaussian perturbations.
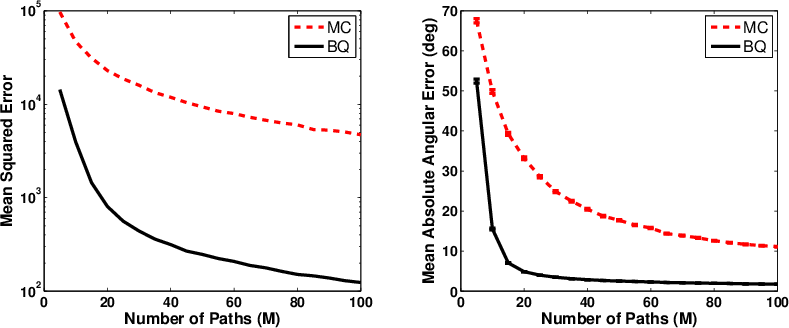
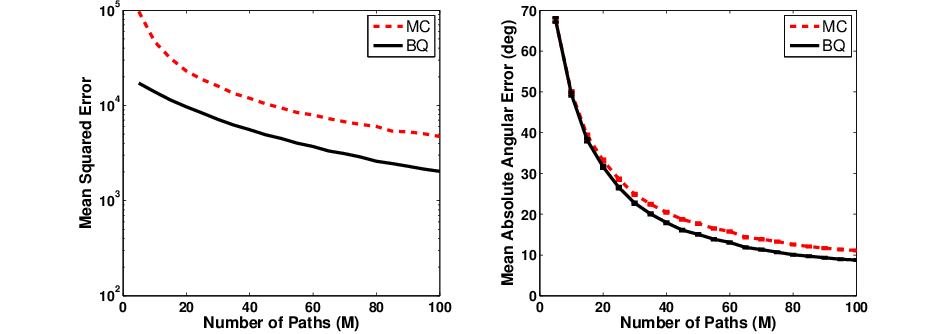
Figure 2: MSE and angular error for BQ gradient estimates in LQR under reward noise, showing minimal degradation relative to the noise-free case.
Policy optimization experiments reveal that Bayesian Policy Gradient (BPG) and its natural gradient variant (BPNG) dominate MC-based algorithms as sample sizes increase, except for extremely small M where prior dependency affects accuracy. When the posterior covariance is leveraged for adaptive step sizing (BPG-var), learning speed further increases, suggesting the utility of Bayesian second-order statistics in RL optimization.
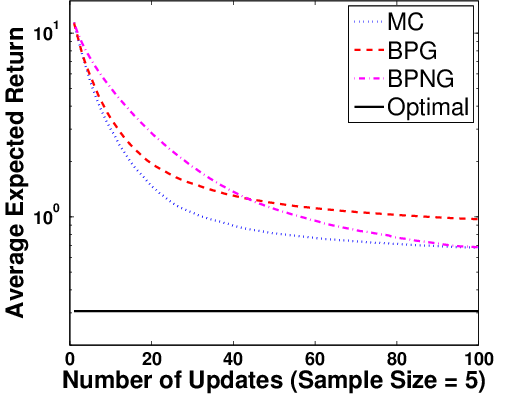
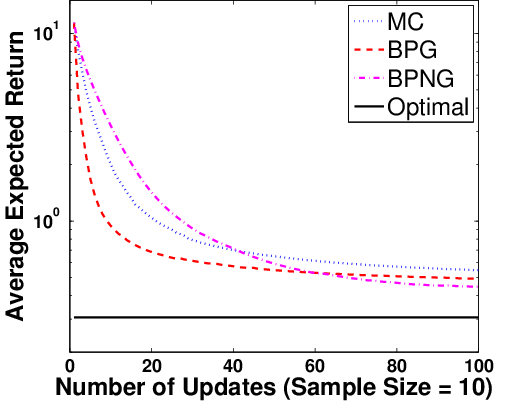
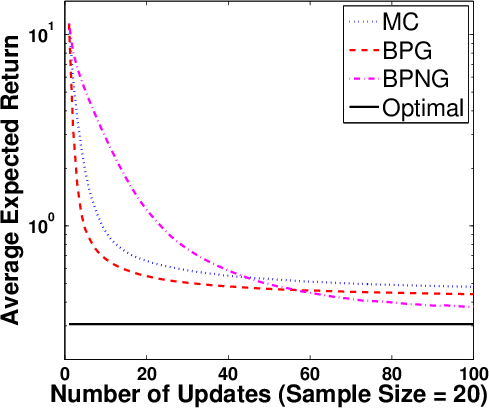
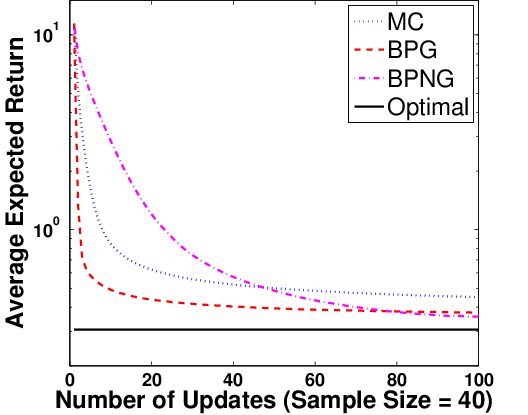
Figure 3: Expected returns versus policy updates for BPG (conventional and natural gradient) and MCPG, across multiple sample sizes M.
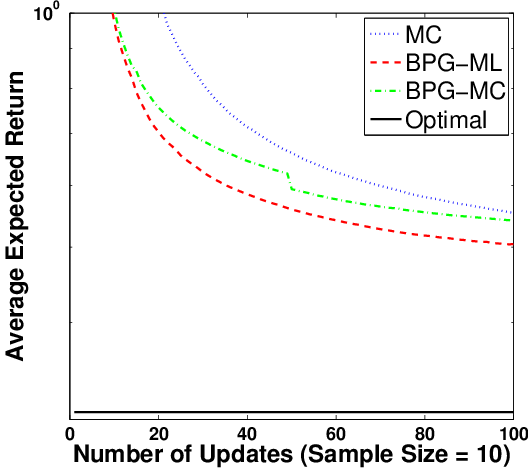
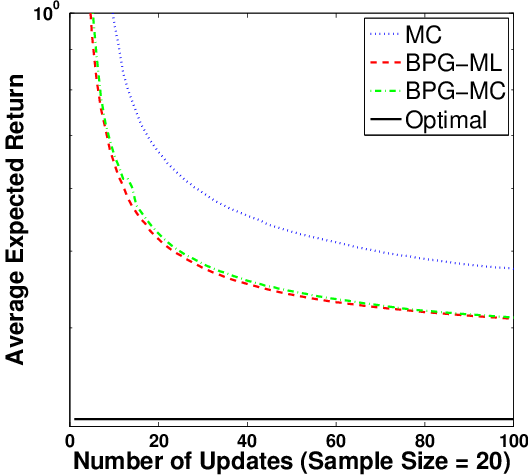
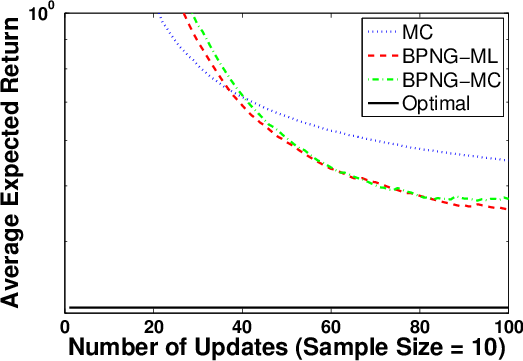
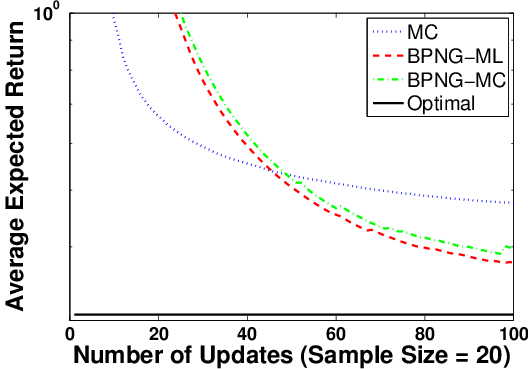
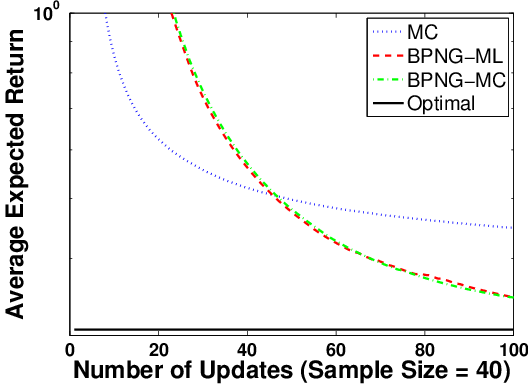
Figure 4: Performance of BPG when Fisher information matrix is estimated via maximum likelihood (ML) or MC, compared to MCPG.
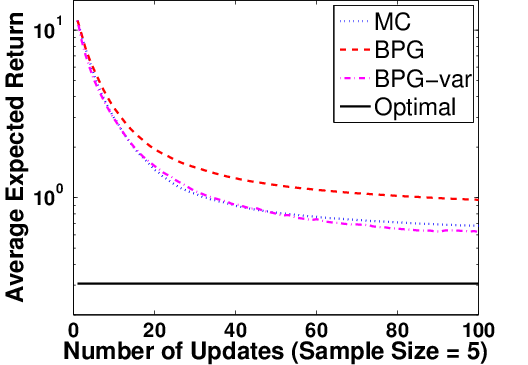
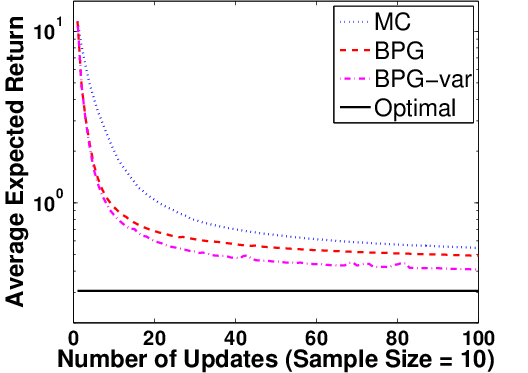
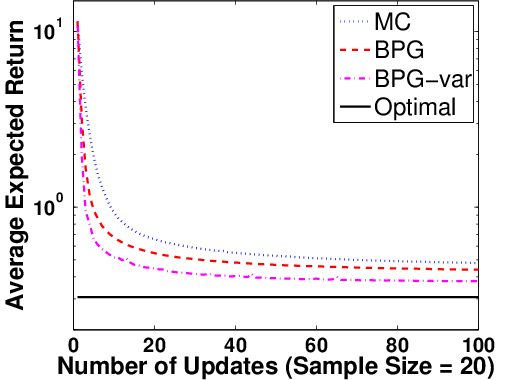
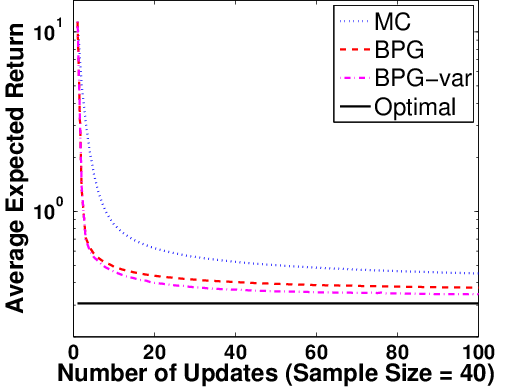
Figure 5: Policy returns for BPG-var (using posterior covariance for steplength), BPG, and MCPG, illustrating accelerated convergence.
Bayesian Actor-Critic Methodology
The second major contribution is a Bayesian actor-critic (BAC) architecture exploiting the Markov property by modeling action-value functions as GPs (Gaussian Process Temporal Difference, GPTD). The Fisher kernel guarantees compatibility, and actor updates are performed using closed-form posterior moments for the gradient. This approach achieves further variance reduction and learning acceleration compared to BPG, validated in sequential domains with variable trajectory lengths where BPG can underperform.
BAC utilizes state-action-reward transitions for gradient estimation, yielding substantial improvements in learning curves compared to trajectory-based Bayesian methods and MC. In evaluation tasks (random walk, mountain car, ship steering), BAC delivers more accurate gradient estimation and consistently superior policy learning, even under stringent sample constraints.
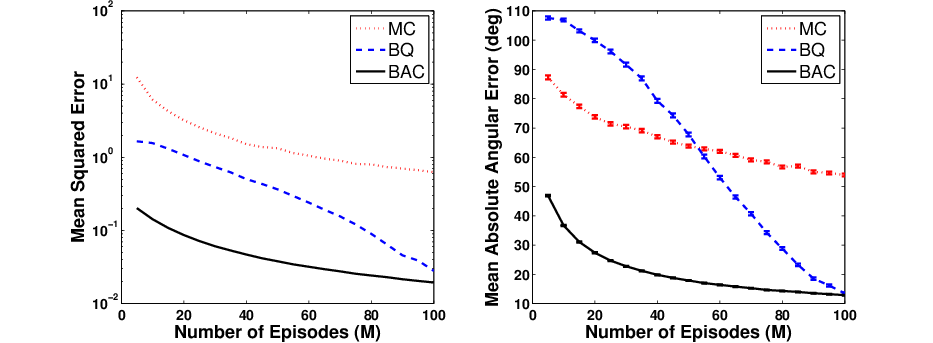
Figure 6: MSE and angular error of MC, BQ, and BAC gradient estimations in random walk, demonstrating BAC's advantage.
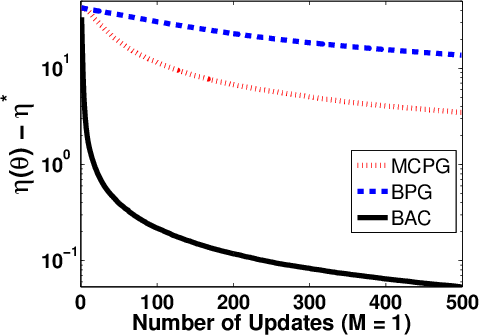
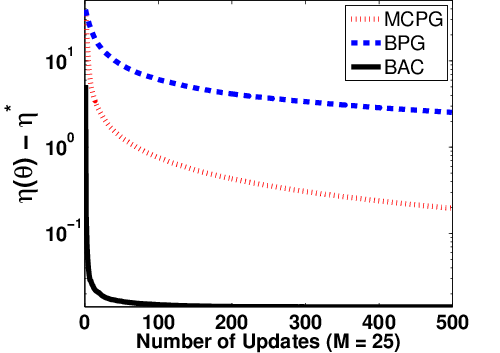
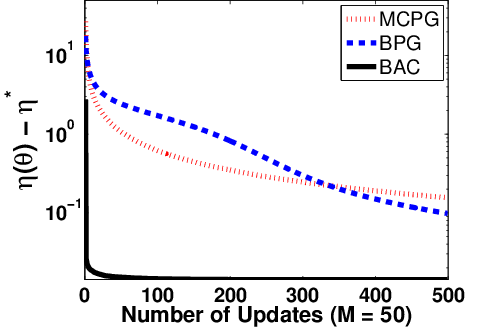
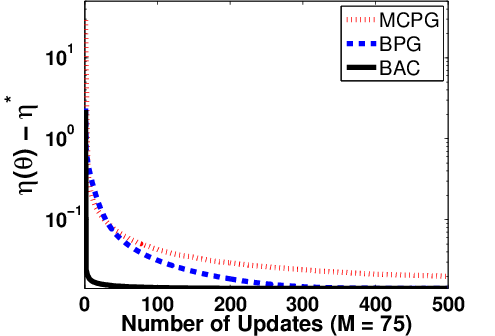
Figure 7: Policy learning performance for BAC, BPG, and MCPG with varying episode batch sizes in random walk.
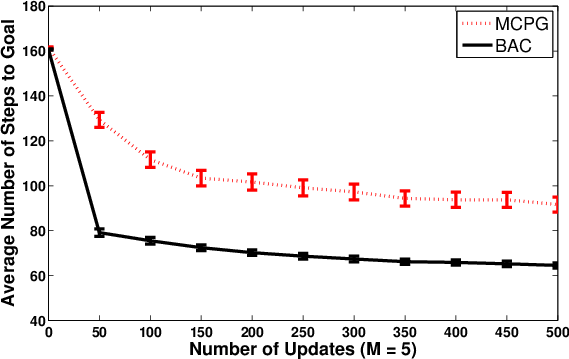
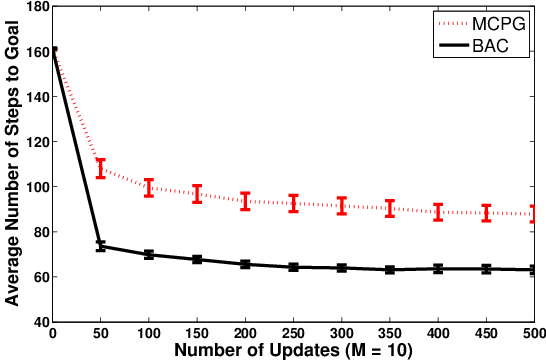
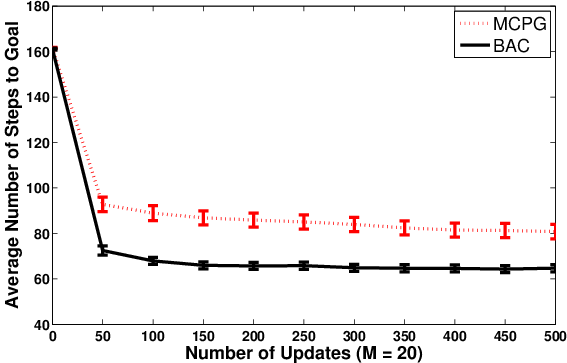
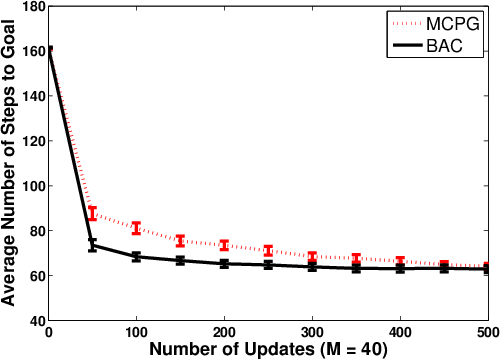
Figure 8: Policy learning curves for BAC and MCPG in mountain car, under different episode budgets.
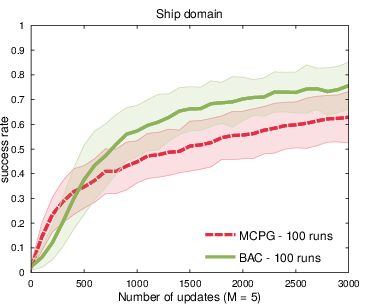
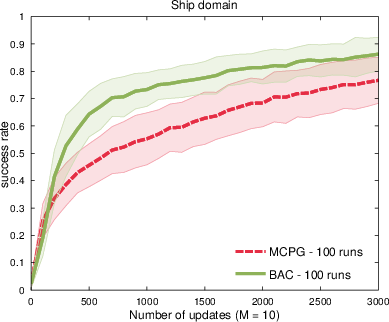
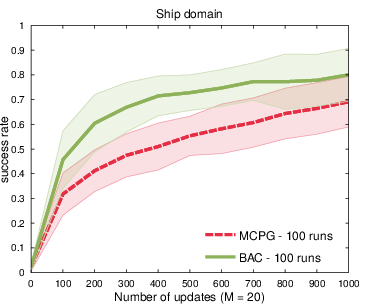
Figure 9: Success rate trajectories in ship steering for BAC vs. MCPG.
Practical and Theoretical Implications
This research establishes Bayesian inference as an effective tool for policy gradient estimation in RL, especially in high-variance and data-constrained settings. The ability to leverage trajectory or transition-level information, and analytically compute natural gradient updates, opens pathways for improving sample efficiency and learning speed. Empirical evaluations confirm these claims, with Bayesian methods consistently outperforming common MC-based algorithms across diverse RL domains.
Theoretical implications include:
- Demonstration that Fisher-type kernels provide sufficient structure for analytical posterior computation in Bayesian PG and actor-critic models.
- Evidence that Bayesian estimation, including adaptive use of posterior covariance, leads to steeper learning curves and more reliable convergence.
From a practical standpoint, the Bayesian actor-critic framework facilitates variance reduction, robust learning under noisy rewards, and scalability to continuous and high-dimensional domains. Furthermore, sparse online dictionary methods increase computational tractability for large-scale applications.
Future Directions
Key avenues for future work include:
- Extension to fully non-parametric actors for gradient search in function spaces, e.g., RKHS-based policy optimization.
- Exploration of alternative kernel functions, including sequence kernels for trajectory modeling.
- Integration with model-based RL for knowledge transfer across policies (model-based Bayesian policy gradient).
- Improved techniques for Fisher information estimation and utilization of higher-order Bayesian statistics in actor and critic updates.
Conclusion
The paper provides rigorous, principled algorithms for Bayesian policy gradient and actor-critic reinforcement learning, demonstrating substantial empirical gains in accuracy, convergence speed, and robustness. By leveraging Gaussian process modeling of policy gradients and action-values, and utilizing Fisher kernels for compatibility and analytical tractability, these methods enhance both the theoretical understanding and practical capability of policy search in RL. Bayesian estimation emerges as a viable approach for efficient and reliable RL in complex domains, with promising prospects for future algorithmic innovations and scalability.

