- The paper introduces a dual-manifold framework to distinguish between density and support generalization in neural program synthesis.
- The study quantifies OOD performance, revealing that syntactic extrapolation incurs a >30% drop in pass@1 while semantic extrapolation remains robust.
- Findings indicate log-linear scaling with compute, highlighting limitations in transformer architectures and advocating for diverse training data.
Mapping Generalization Boundaries in Neural Program Synthesis
Introduction
The paper "Beyond the Training Distribution: Mapping Generalization Boundaries in Neural Program Synthesis" (2604.27551) addresses the core question of how transformer-based program synthesis models generalize beyond their training distributions. Motivated by critiques of widely-used code generation benchmarks and the opacity of large code model pre-training corpora, the authors develop a rigorous, controllable framework for evaluating model generalization. A context-free arithmetic grammar defines the program universe, enabling exhaustive enumeration, precise metric space embeddings, and exact quantification of out-of-distribution (OOD) distances.
Methodology: Dual Manifold Embedding for Generalization
To systematically distinguish between "density generalization" (resilience to probability mass shifts within a support) and "support generalization" (extrapolation to new regions), the authors construct two continuous program manifolds: syntactic and semantic. Each arithmetic program is embedded syntactically using PQ-Grams extracted from the abstract syntax tree, projected via SVD, and semantically by evaluating program outputs over a fixed input grid with PCA reduction after z-scoring.
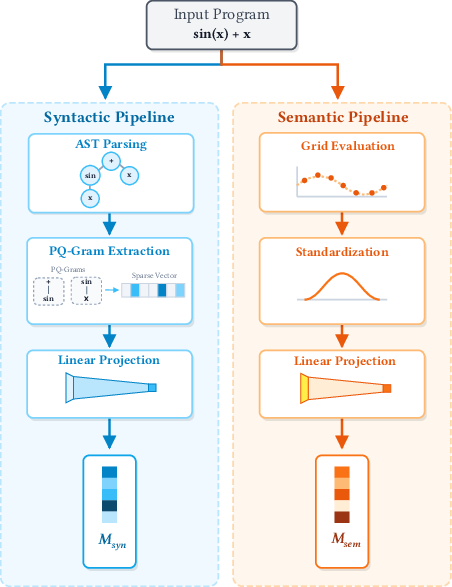
Figure 1: Dual manifold pipeline enables independent, interpretable quantification of OOD distances in both structural and behavioral program spaces.
By formalizing both manifolds, the framework supports sampling regimes that isolate syntactic diversity, semantic diversity, or their intersection (diverse sampling). This permits the construction of train-test splits for targeted OOD distributional shifts and controlled extrapolation boundaries.
Experimental Protocols and OOD Split Construction
The key generalization modalities are:
- Density Generalization: Training and test sets cover identical support but differ in sampling densities over that support.
- Support Generalization: Train and test sets have strictly disjoint supports, defined by geometric partitioning of the embedding manifolds.
In practice, three density sampling strategies are implemented: Syntactic (uniform over Msyn), Semantic (uniform over Msem), and Diverse (uniform over the equivalence classes of syntactically distinct programs). Support generalization is realized by partitioning the manifold by radial distance from the centroid.
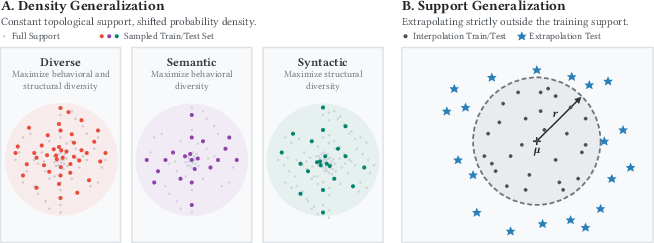
Figure 2: Illustration of both density and support OOD splits within the embedding manifolds. The controlled splits enable the measurement of interpolation versus extrapolation.
Results: Quantifying and Diagnosing Generalization
Density Generalization
Models trained using diverse sampling show the highest robustness to OOD density shifts. Pass@1 performance is stable across splits, reaching approximately 19%, whereas models optimized for semantic or syntactic diversity are brittle under domain shift, despite sometimes achieving peak in-domain performance of 30.5% (Semantic).
Support Generalization
A salient, rigorously quantified result is that extrapolation to functions outside the semantic training support incurs almost no penalty relative to in-domain interpolation. In contrast, extrapolating to unseen syntactic structures results in a marked pass@1 performance drop—over 30%.
Scaling Laws
All generalization metrics scale log-linearly with increased compute (FLOPs). This scaling law holds regardless of sampling regime or the type of OOD shift.
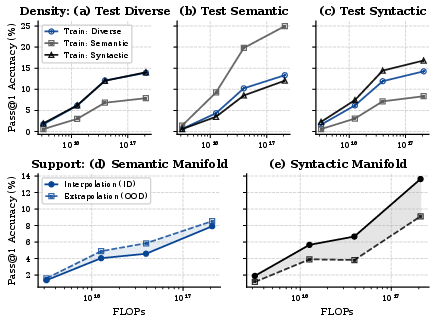
Figure 3: All generalization performance improvements with added compute scale strictly log-linearly, particularly exposing architectural bottlenecks for syntactic extrapolation.
Manifold Proximity and Generalization Mechanisms
Analysis of test instance distances to the nearest training neighbor in the embedding spaces reveals that successful OOD synthesis is fundamentally local. Solved OOD cases are clustered near training instances, while failures are relatively isolated.
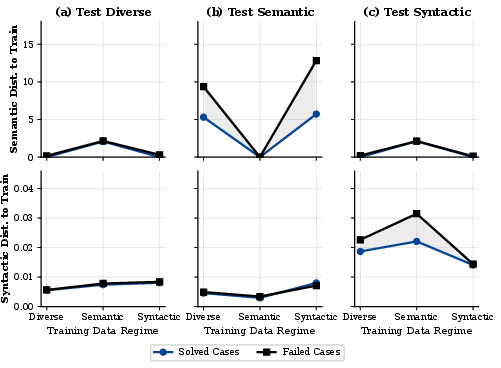
Figure 4: Test cases solved by the model are significantly closer to the training manifold, highlighting interpolation dependence and an inability to synthesize far-removed solutions.
Discussion: Implications, Limitations, and Theoretical Insights
The empirical findings decisively identify that transformer-based program synthesizers, even at large scales, behave as local interpolators. Effective generalization is bounded by the density and spread of the training data across both syntactic and semantic manifolds. For support generalization in syntax, transformers' extrapolation capability is inherently limited, and increasing model scale only yields marginal, log-linearly diminishing returns.
Practically, these insights support the deliberate construction of training datasets with maximal manifold coverage for robust code generation. However, they also suggest that future advances in program synthesis—especially for structurally novel or longer programs—must incorporate search-based or hybrid neural-symbolic techniques to breach this log-linear bottleneck. There is clear motivation for integrating evolutionary strategies, as in AlphaEvolve and FunSearch, to explore structurally remote program regions that pure LLM decoders cannot reach.
The framework's strict control and quantification offer rare clarity but are currently constrained to a bounded arithmetic DSL; extending this approach to broader, Turing-complete environments remains a significant technical challenge.
Conclusion
This study introduces a mathematically grounded, dual-manifold metric approach for evaluating the generalization limits of neural program synthesis models. Strong experimental evidence demonstrates notable robustness gains from diversely sampled training data, but also highlights the fundamental, scaling-invariant bottleneck faced by transformer architectures in syntactic extrapolation. Both theoretical and practical implications strongly favor hybrid or search-augmented approaches, with the results providing concrete guidance on training data construction and future research in generalization for AI-driven program synthesis.

