- The paper introduces a framework that integrates adaptive, control-driven tree discretization with ILP-based matching to optimize ATT estimation.
- The paper employs an outcome-driven partitioning method with exact linear programming to minimize bias and ensure reliable covariate balance.
- The paper demonstrates superior performance on synthetic and CDC Diabetes datasets, delivering interpretable results with competitive computation times.
Tree-Based Discretization and ILP Matching for Causal Inference: An Expert Analysis
Introduction and Motivation
The central focus of this work is the development of a computational framework for causal inference that simultaneously addresses bias, computational tractability, and interpretability—challenges often at odds in observational studies. The proposed methodology integrates a control-based tree-structured discretization, inspired by the M5 model tree, with an integer linear programming (ILP) based matching algorithm. Existing approaches, such as coarsened exact matching, propensity score matching, and distance-metric learning, suffer various trade-offs: exponential growth in discrete strata, insufficient covariate balance, poor scalability, heuristic or black-box nature, or loss of interpretability. The present framework is designed to yield robust average treatment effect on the treated (ATT) estimation, optimized covariate balance, and computational scalability via problem decomposition and exact optimization.
Tree-Based Discretization via Causal M5 Model Tree
The discretization phase is motivated by the curse of dimensionality inherent in matching approaches. The proposed causal M5 model tree performs adaptive, outcome-driven partitioning of the covariate space using only controls for split selection and adjusted R-square as the splitting criterion.
By restricting splits to the control group, the approach enforces homogeneity in the response surface under the null, which theoretically ensures approximate linearity within leaves (as formalized in Theorem 1). This provides a local structure conducive to subsequent matching while protecting against overfitting through hyperparameterized minimum leaf sizes. The methodology effectively mitigates three primary sources of discretization error: arbitrary bin boundaries, within-stratum heterogeneity, and information loss from coarse stratification.
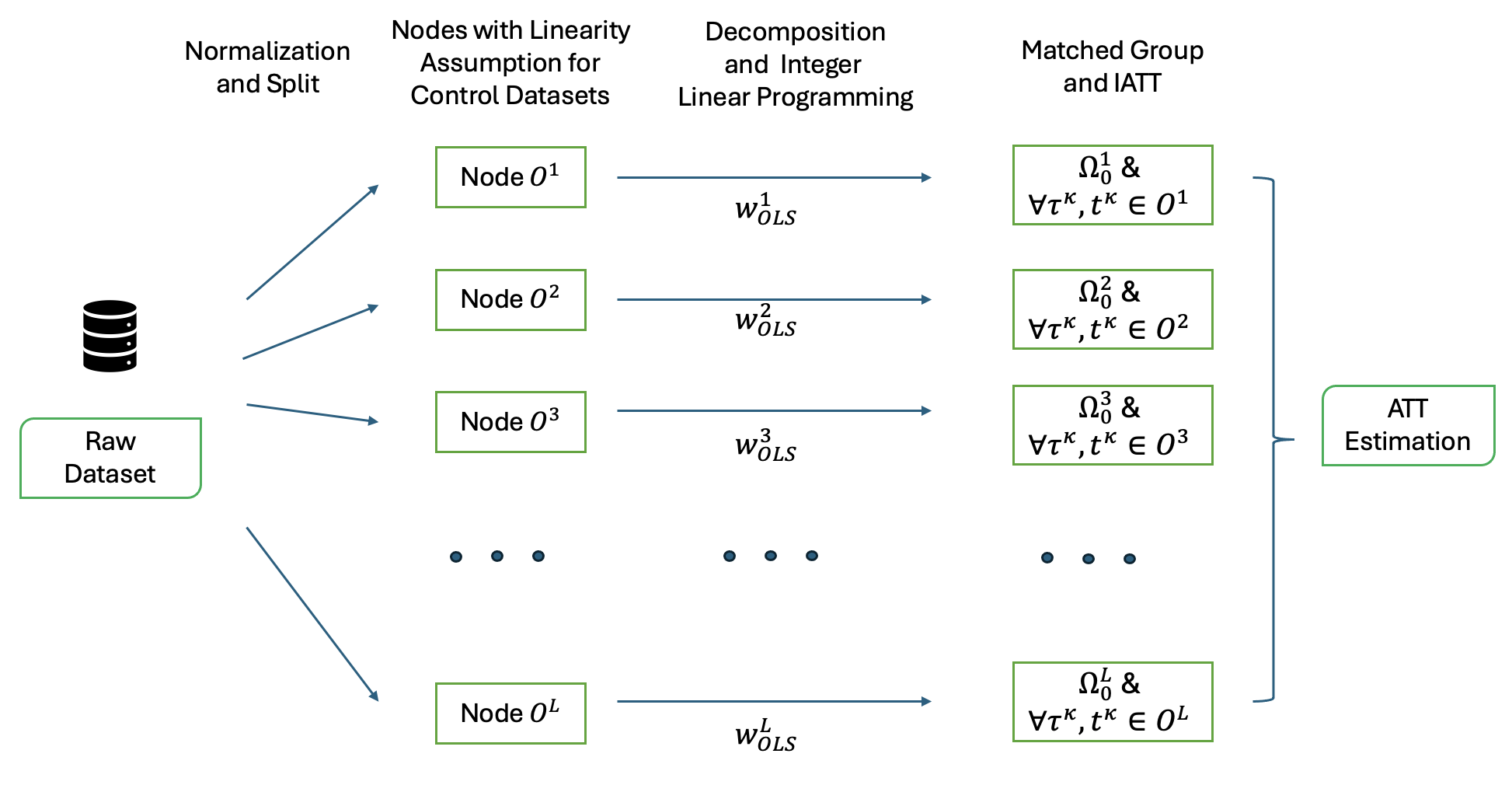
Figure 2: Flowchart for implementation of the proposed framework.
This design ensures that split rules are both interpretable and aligned with substantive domain understanding (e.g., a node with "if BMI > 30" is transparent for health practitioners). Furthermore, sufficient leaf sample size is enforced to guarantee reliable local fit and stable variance estimates. Limitations arise if treatment effect heterogeneity is driven by modifiers uncorrelated with controls: the model, while robust to imbalance, may underfit local heterogeneity not reflected in baseline outcomes.
ILP-Based Individual Matching Framework
Within each discretized stratum, the framework applies an ILP to select optimal control subsets for each treated unit (1:k matching with k≥1). The ILP objective is hierarchically structured: it first minimizes the maximum weighted absolute mean difference (to control SMD), then refines among ties by minimizing the maximum pairwise weighted distance (to limit variance ratio), both computed over features weighted according to OLS coefficients for outcome prediction. All relevant quantities are exactly linearized, enabling solution with standard ILP solvers.
Notably, when decomposing each leaf into nt strata of one treated and multiple controls, the approach yields both ATT and individual-level ATT (IATT) estimates—unlike traditional k:k group matching. Theoretical results establish equivalence between 1:k and k:k matching at the stratum level, motivating the selection of 1:k matching for greater flexibility and unit-level inference.
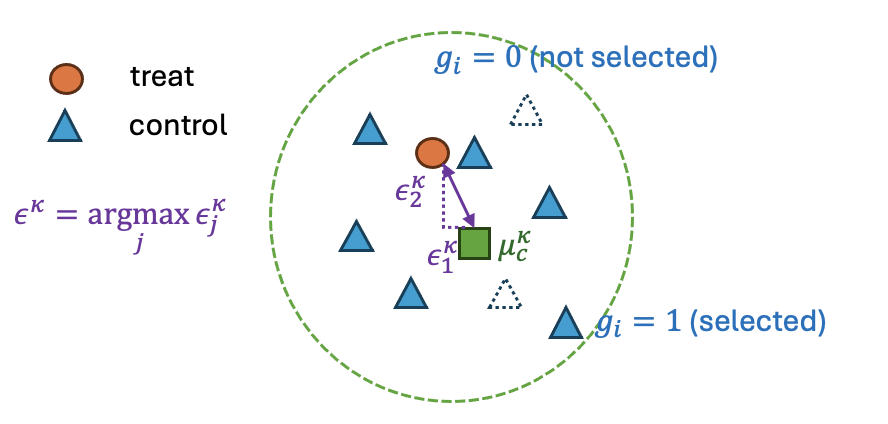
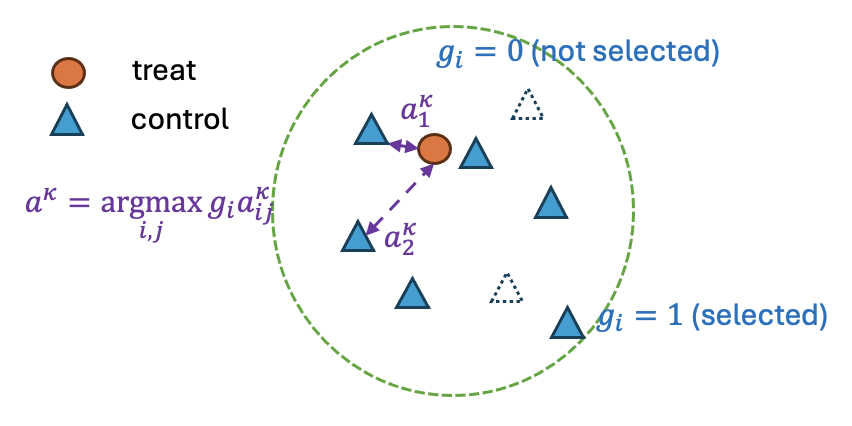
Figure 3: The Graph interpretation of ϵ (mean difference) and a (maximum pairwise deviation) in the ILP formulation.
Handling high-dimensional feature spaces is tractable due to the tree partitioning and candidate set limitation for each unit (default ψ=20 controls), ensuring efficient solution times even for large-scale datasets. Empirical findings indicate that omitting discretization may confer misleading balance diagnostics, highlighting the necessity of this hybrid approach for true bias reduction.
Experimental Evaluation on Synthetic and Real-World Data
The algorithm was benchmarked against IPTW, nearest neighbor propensity score matching, BART, random forests, R-learner, Genetic Matching, and FLAME on synthetic datasets with nonlinear outcome surfaces and high-dimensional covariates. On the hyb20var dataset (20,000 samples, 20 features, 7 outcome-generating), the M5C_MF method (M5 tree + ILP) consistently exhibited the lowest ATT estimation bias and the tightest confidence intervals, outperforming all baselines.
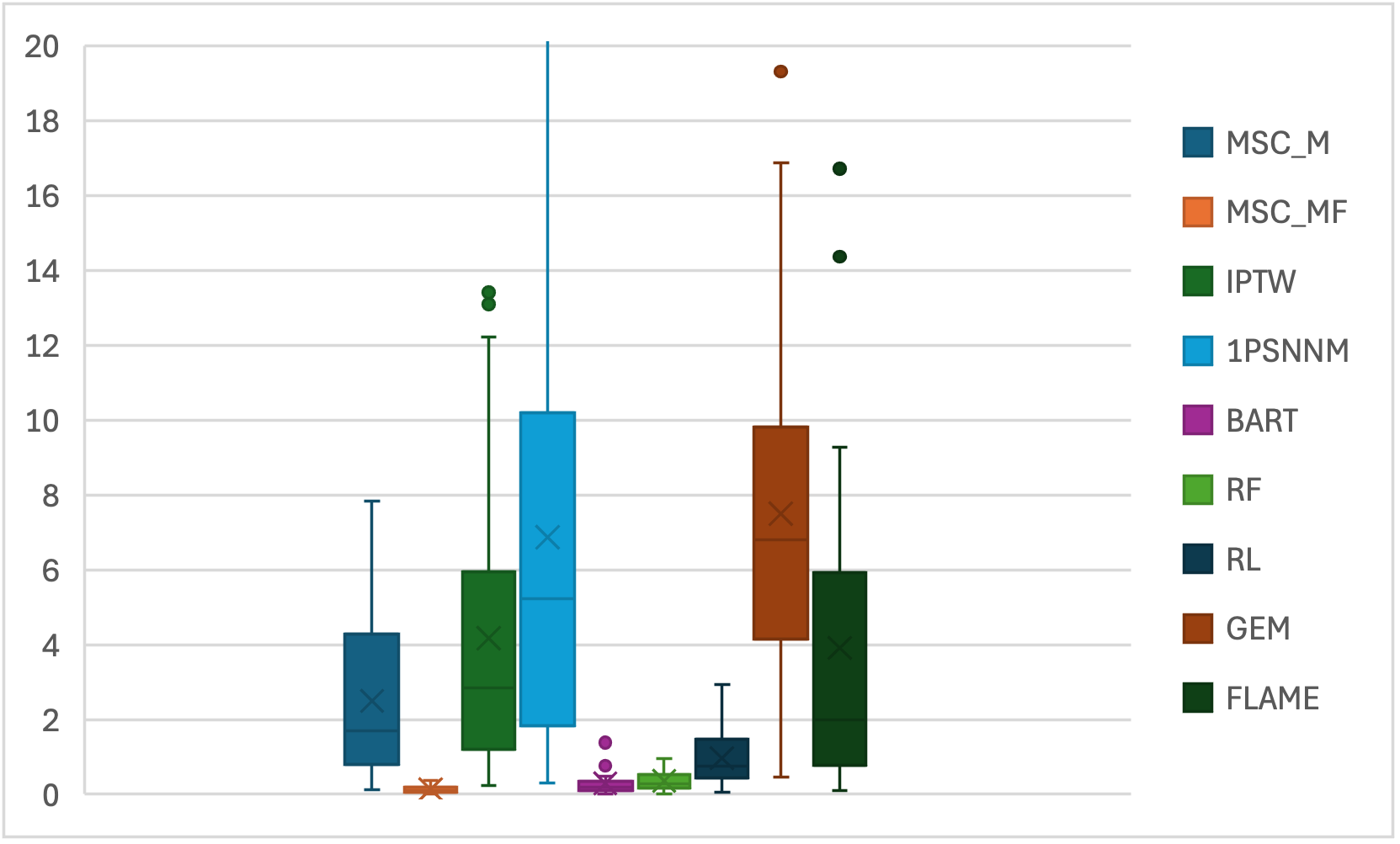
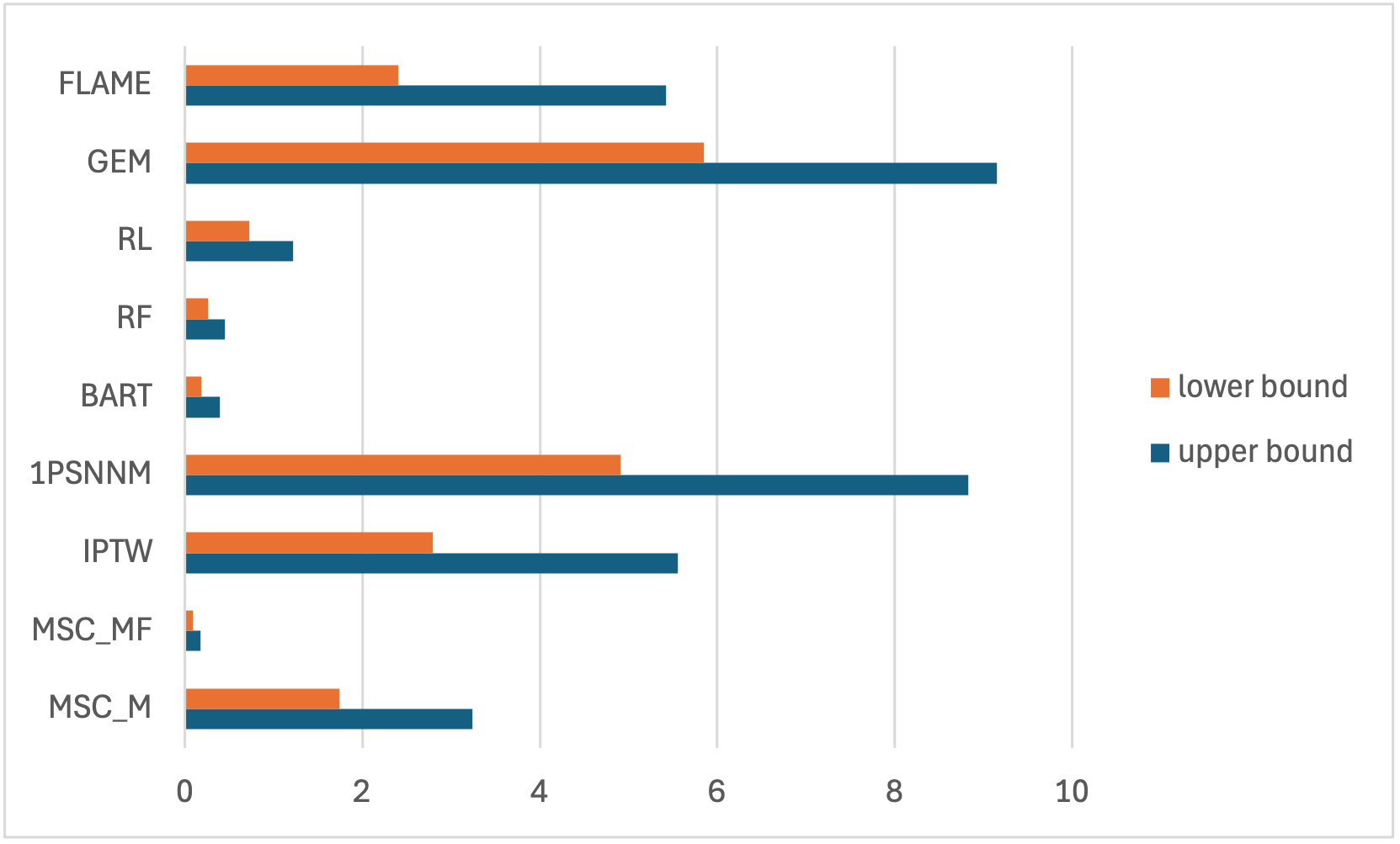
Figure 1: Absolute bias to ATT estimation for the hyb20var synthetic dataset.
Real-World Data: CDC Diabetes Dataset
The method was further validated on the CDC Diabetes Health Indicators Dataset (253,680 subjects, 27 post-encoded features). The causal question focused on the effect of "poor" self-reported general health on diabetes incidence (binary outcome). Bootstrapped ATT estimation showed that the proposed approach robustly detects a positive, significant treatment effect with greater magnitude and statistical confidence than alternative approaches. Propensity-score-based algorithms occasionally produced counterintuitive or non-significant effects; BART and RF methods, while positive, showed notable shrinkage and larger uncertainty.
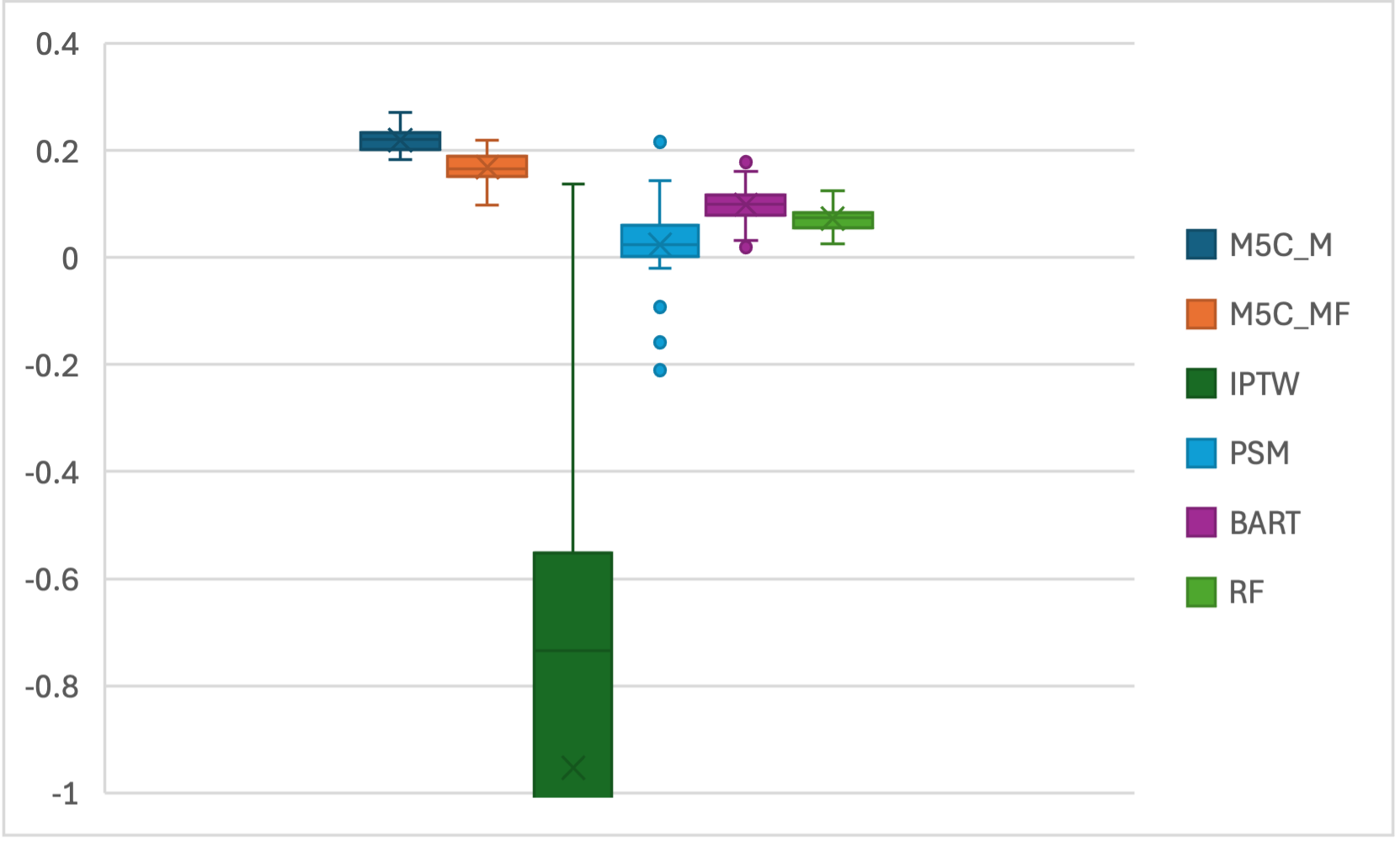
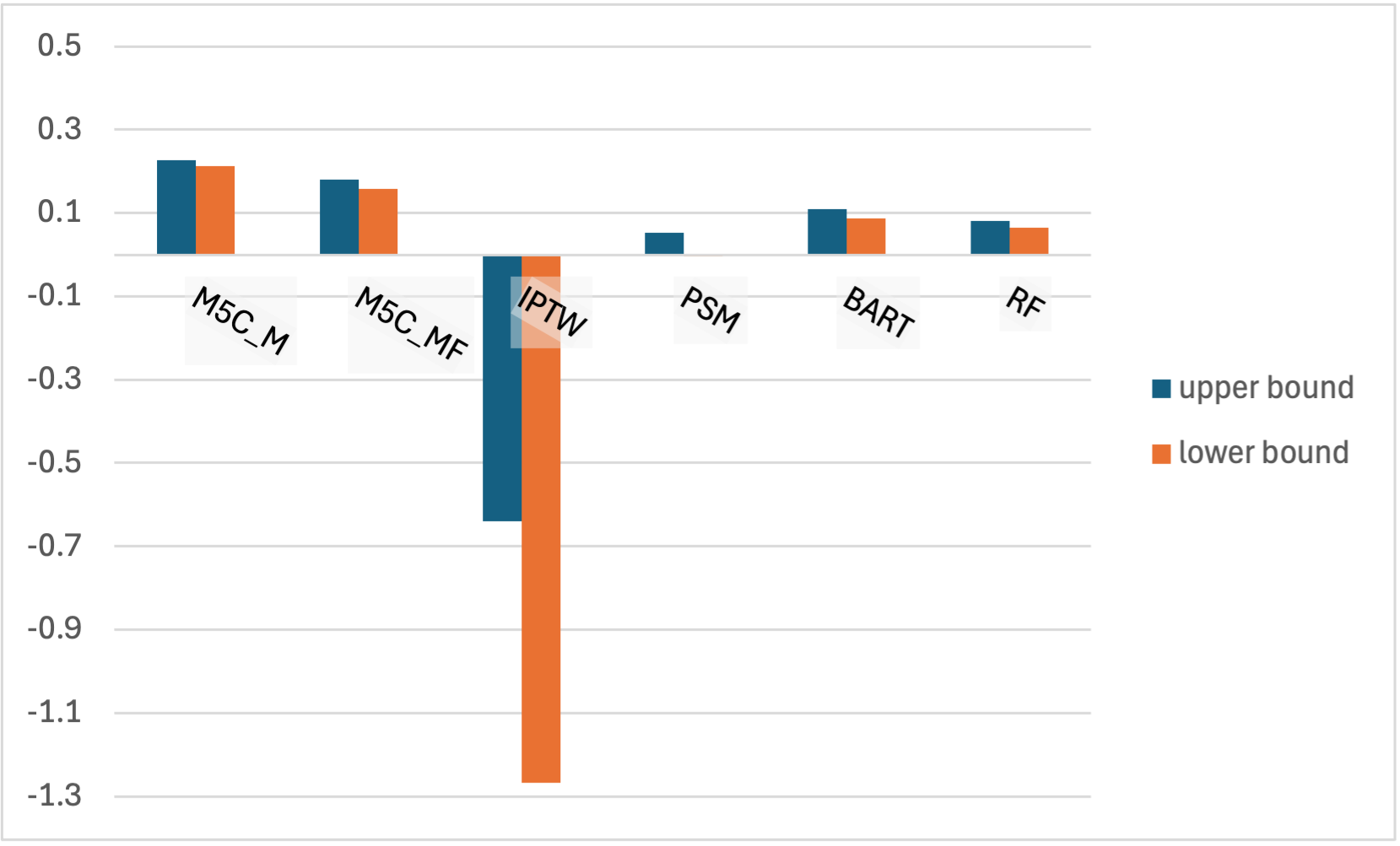
Figure 4: ATT estimation for CDC Diabetes dataset for each algorithm.
Distributional analysis of key features pre/post-matching indicated that the ILP matching yields low standardized mean differences (SMD < 0.01) and variance ratios tightly clustered around unity, confirming strong empirical covariate balance.
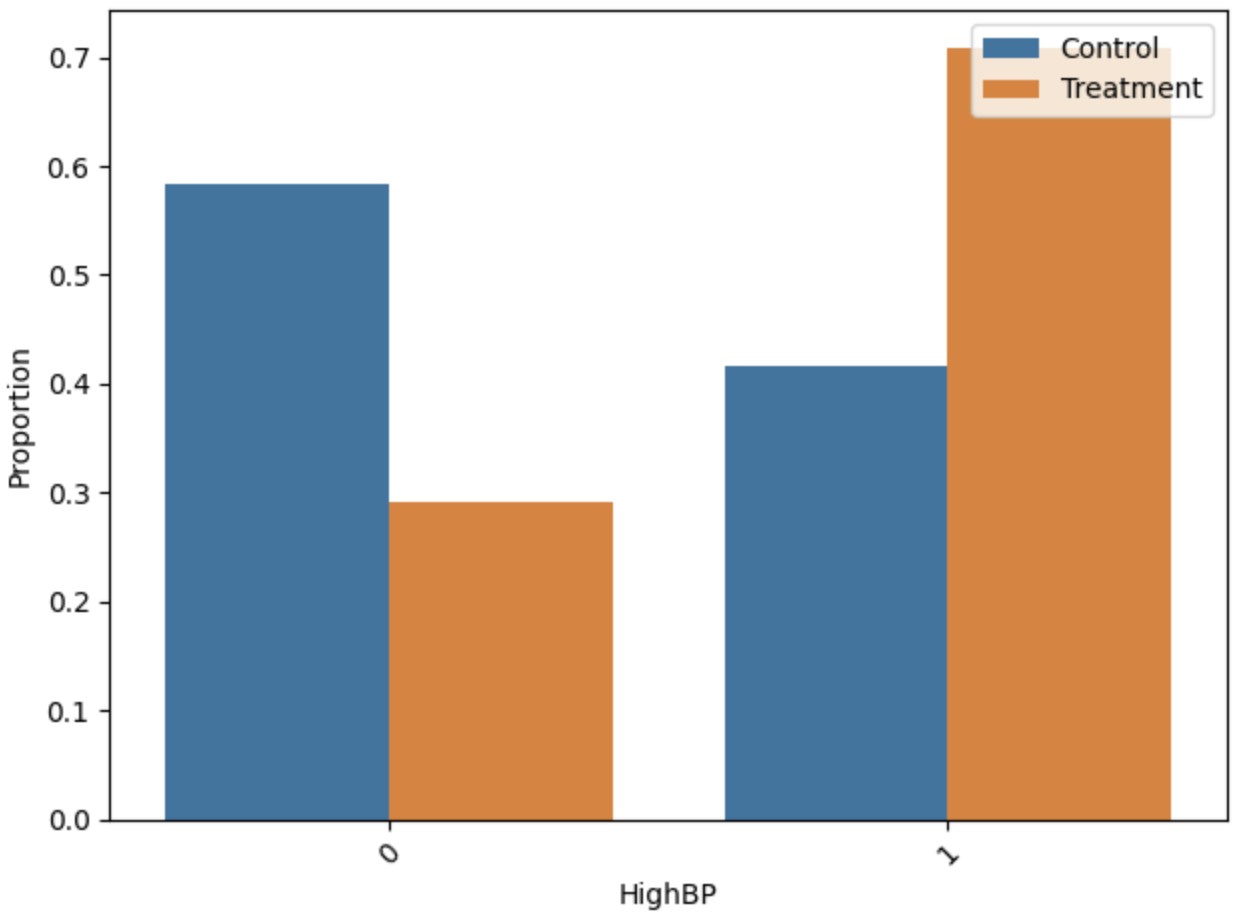
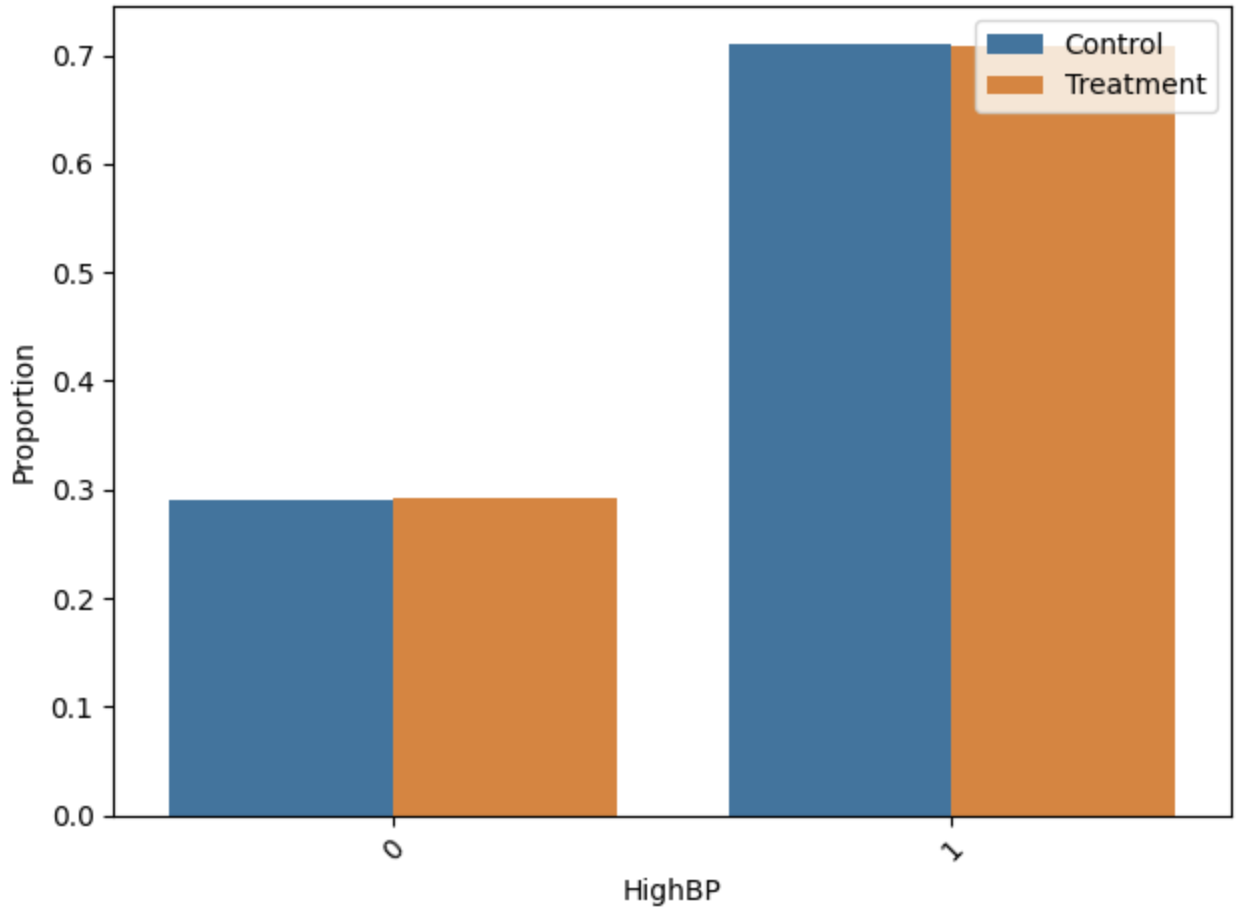
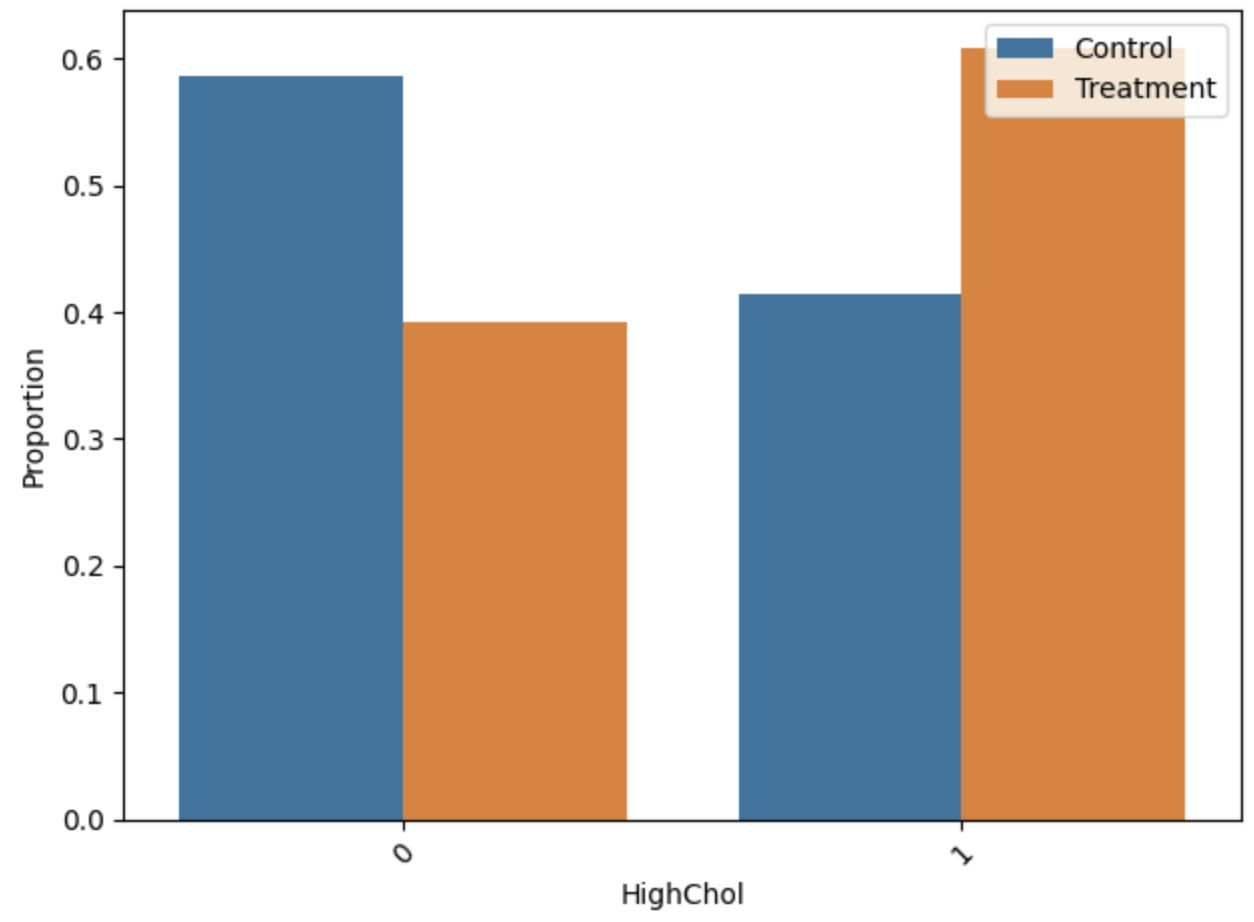
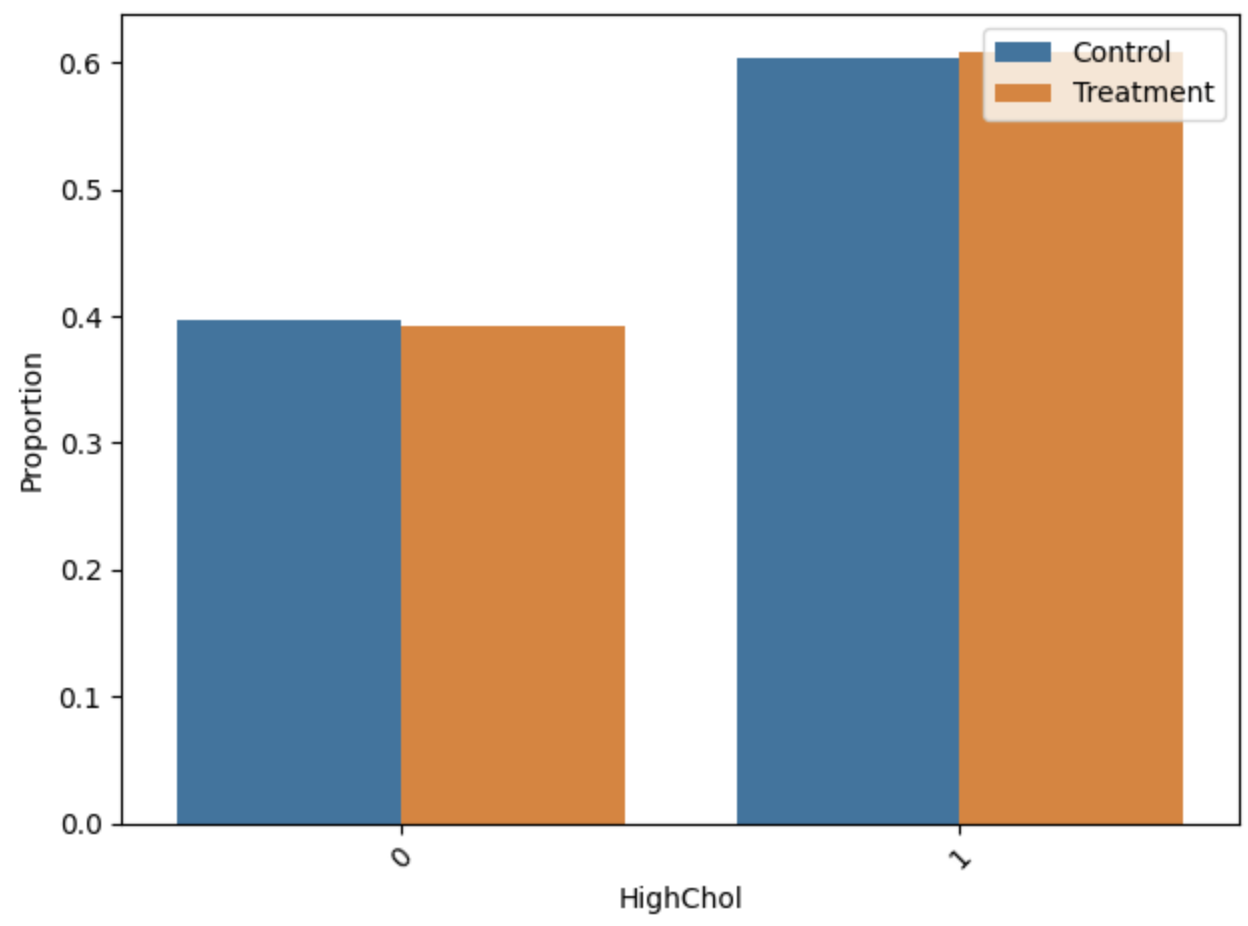
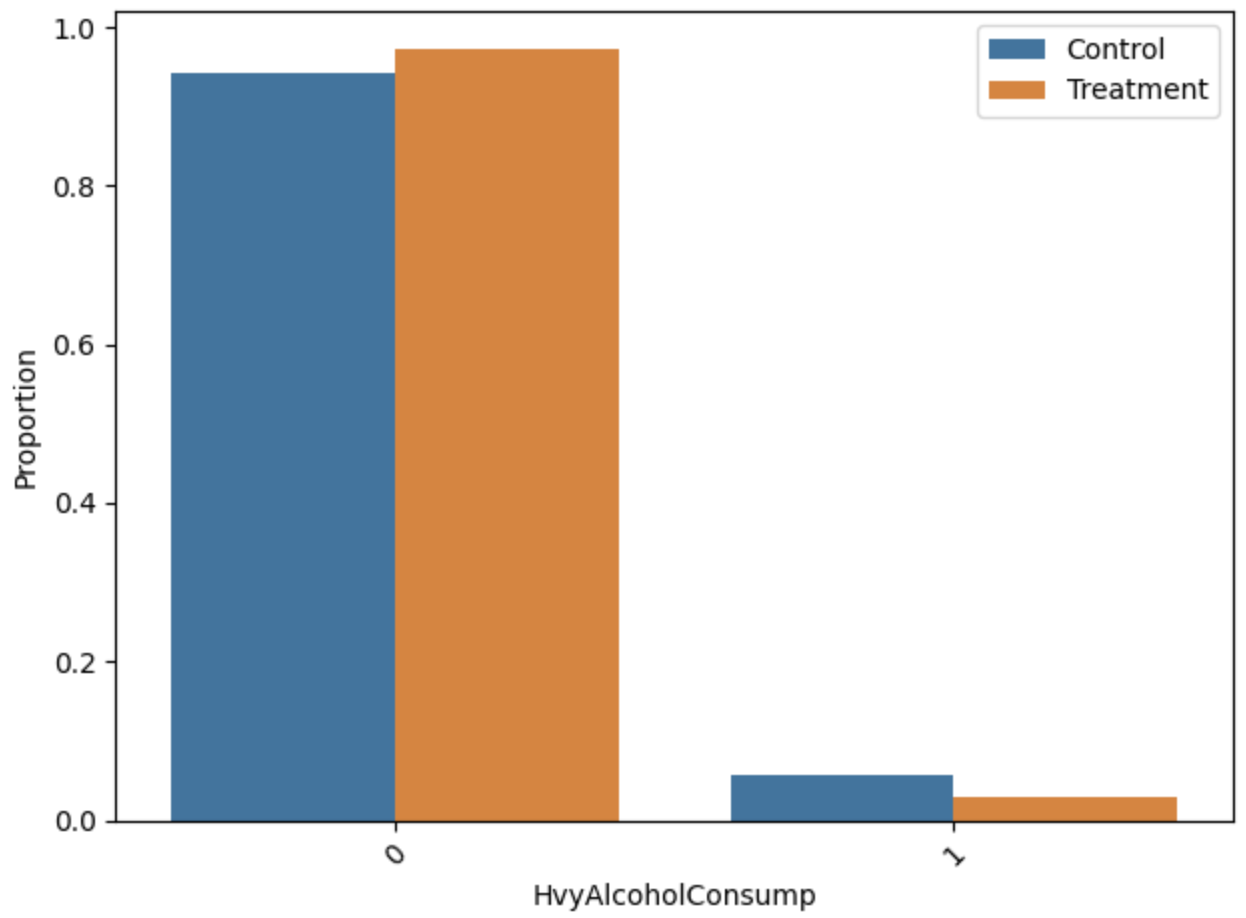
Figure 5: Distributions of HighBP, HighChol, and HvyAlcoholConsump before and after matching.
The algorithm’s run times, while higher than for simple IPTW, were competitive relative to advanced tree-based meta-learners and scalable to large observational datasets given parallel solution of per-unit ILPs.
Interpretability and Theoretical Considerations
The proposed method stands apart in offering both process-level and diagnostic interpretability. Stratification is governed by explicit, outcome-informed splits, and matching groups are observable, auditable, and validated via standard balance statistics on observed data—unlike black-box counterfactual prediction models. The methodological framework adheres to established causal inference axioms (SUTVA, unconfoundedness, positivity) and provides robustness to confounding via direct balance optimization.
Implications and Future Directions
The fusion of tree-based local discretization with provable, hierarchical ILP matching offers a tractable route to accurate and interpretable ATT estimation in high-dimensional observational studies. The approach is applicable to large-scale epidemiological, policy, or social science data where computational, statistical, and stakeholder transparency concerns are paramount. Future developments may explore extensions to multi-valued or continuous treatments, direct integration with sensitivity analysis for unobserved confounding, or adaptation to dynamic treatment regimes and longitudinal designs.
Conclusion
This study establishes a unified, interpretable, and empirically validated framework for causal effect estimation, combining adaptive tree-based discretization (ensuring local linearity) and integer programming-based matching (guaranteeing exact covariate balance). The method delivers superior or competitive ATT estimation accuracy with practical computational burden, offering a compelling option for robust causal inference in large and complex observational datasets.

