- The paper presents Spin, a unified system that maps diverse sparse attention granularities into a page-based KV storage to enhance long-context LLM efficiency.
- It employs locality-aware GPU caching and a hierarchical two-level metadata structure to minimize PCIe transfers and reduce HBM usage.
- Quantitative results demonstrate up to 5.66× higher throughput and 7–9× lower time-to-first-token compared to existing sparse attention methods.
Unifying Sparse Attention with Hierarchical Memory for Scalable Long-Context LLM Serving
Motivation and Problem Statement
Expanding LLM context windows to hundreds of thousands or millions of tokens dramatically increases memory and bandwidth requirements for serving, as the key-value (KV) cache in Transformer attention grows linearly with sequence length. Dynamic sparse attention algorithms reduce compute and memory bandwidth requirements by only attending to a query-dependent subset of the context, while keeping the full KV cache. However, such theoretical algorithmic savings have so far failed to translate into system-level throughput improvements, largely due to two compounding issues: (1) extant systems lack unified abstractions and must rely on ad hoc, per-algorithm implementations unable to exploit common optimizations, and (2) moving fine-grained, irregularly accessed KV subsets between CPU and GPU during hierarchical KV storage is a severe bottleneck, often nullifying potential sparsity benefits.
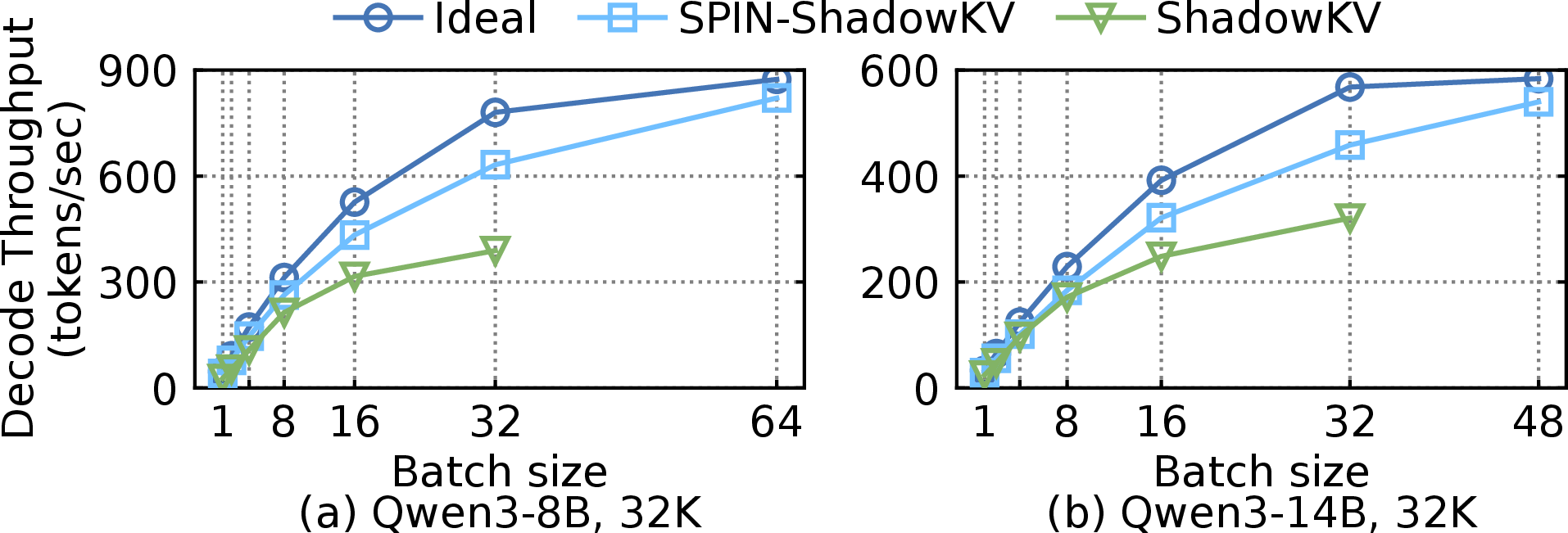
Figure 1: Existing sparse attention implementations are significantly below the ideal serving envelope due to data movement and memory management inefficiencies.
Empirical results confirm a large gap between Oracle-optimal sparse attention systems and current implementations ("Gap Between Theoretical and Realized Performance", Figure 1), motivating principled system-level solutions.
The Spin Framework: Design and Abstraction
The paper introduces Spin, a unified sparse-attention-aware inference engine that coordinates sparse attention computation and hierarchical memory. Spin provides:
These design decisions align system structure with the computation patterns of modern sparse attention, enabling the system to automatically orchestrate offload and retrieval operations, efficiently manage metadata, and facilitate integration of new sparse attention variants.
Memory Management Architecture
Spin's core memory manager virtualizes KV storage via partitions (logical units, possibly multi-token and head-specific), translating algorithmic access to physical pages, decoupling software granularity from hardware-efficient data movement. The GPU manages compact metadata (meta-partition table, GPU page table) for low-latency operations, while bulkier, capacity-limited metadata resides in pinned CPU memory, accessible to GPU kernels as needed.
When critical partitions are required, retrieval operates as follows:
- Residency of required partitions is checked via the meta-partition table.
- GPU buffer allocation is dynamically balanced between "mandatory" and "buffering" pages, allowing per-request elasticity.
- If needed, a bucketed-LRU on-GPU replacement policy selects victims, using bounded recency timestamps (e.g., 64-state counter), avoiding expensive global ordering.
- Buffered partitions are updated, and minimal, contiguous PCIe transfers are issued for misses.
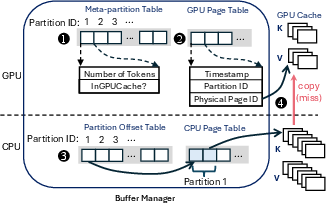
Figure 3: Overview of the hierarchical memory management and retrieval workflow in Spin.
Additionally, Spin's scalable two-level paging structure enables metadata to grow sublinearly and only with the number of mapped physical pages.
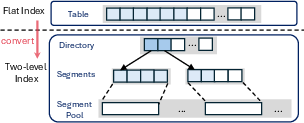
Figure 4: Two-level page table design reduces metadata overhead compared to flat allocation.
Integration with Sparse Attention Algorithms
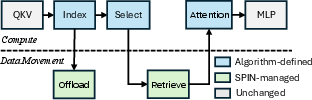
Spin supports direct integration of leading sparse attention algorithms (e.g., ShadowKV, RetroInfer, SeerAttention-R) via its five-stage pipeline (Index, Offload, Select, Retrieve, Attention), requiring only the index and select logic to be customized per-algorithm. Data movement and system optimization (Offload/Retrieve) are handled generically.
Quantitative Results
End-to-End Throughput and Latency
Experiments on A100/B200 GPUs with Qwen3 and Llama-3.1 models over LongBench-v2 and LongGenBench demonstrate large throughput improvements over dense vLLM and prior sparse attention implementations. Concrete results:
- $1.66$–5.66× higher throughput and $7$–9× lower TTFT (time-to-first-token) than vLLM.
- Up to 58% lower TPOT (time-per-output-token) vs original sparse-attention methods.
- Supports $2.5$–3.3× larger batch sizes due to smaller per-request HBM working set.

Figure 5: End-to-end throughput vs. request rate on LongBench-v2; Spin variants scale beyond vLLM and vLLM-Offload.

Figure 6: Spin sustains higher throughput on LongGenBench by supporting larger batches and higher concurrency at elevated request rates.
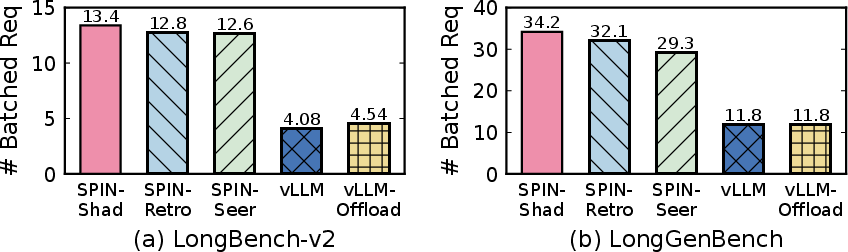
Figure 7: Average number of concurrently batched requests for Qwen3-14B. Spin variants admit significantly larger batches.
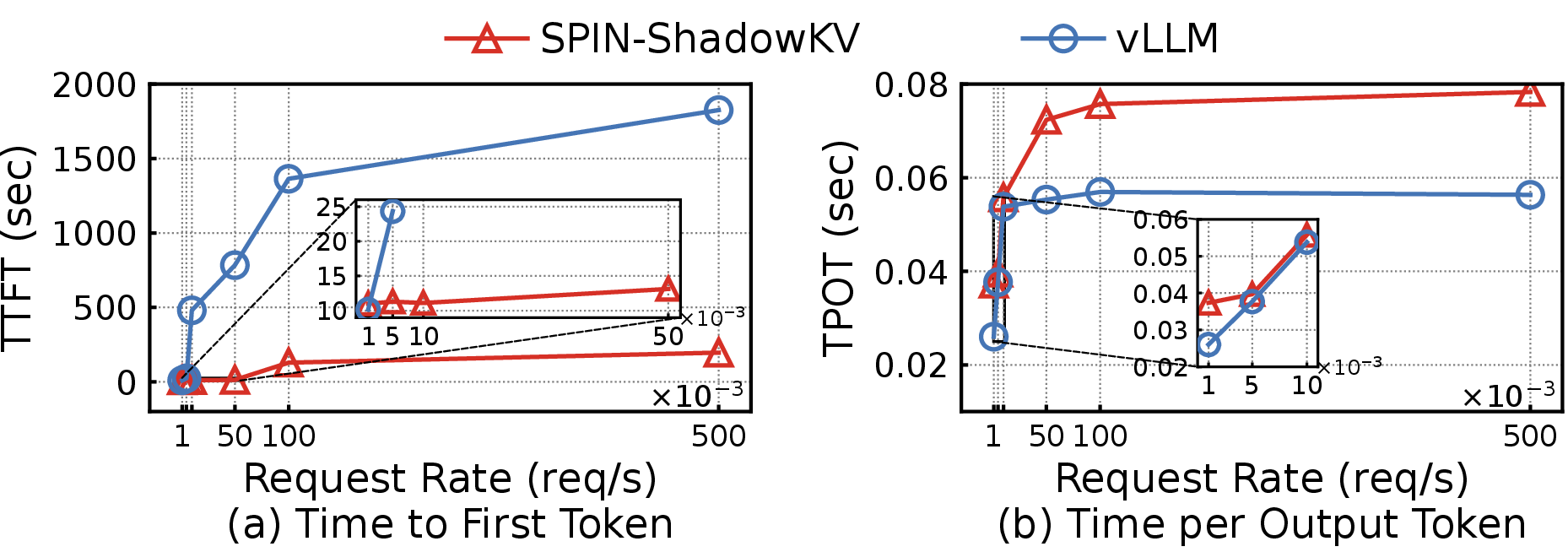
Figure 8: Spin reduces average TTFT and maintains efficient TPOT under high request rates compared to strong baselines.
Decode and Prefill Microbenchmarks
- Prefill latency is competitive due to asynchronous implementation (Figure 9).
- Decode throughput is much higher at all but smallest batch sizes (Figure 10).
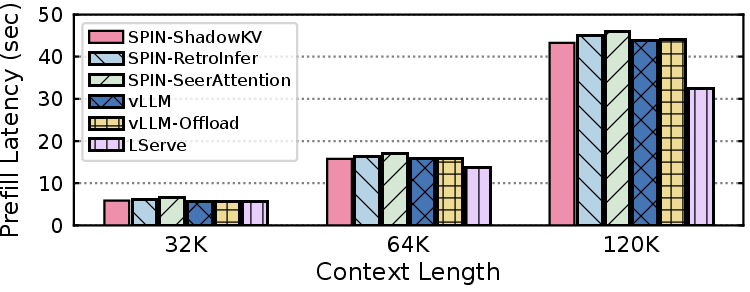
Figure 9: Prefill latency increases with context, but Spin remains on par due to offloading and parallel allocation.

Figure 10: Offline decode throughput as a function of batch size and context length. Spin outperforms all competitors at scale.
Comprehensive breakdowns show that the dominant improvements stem from system-level reductions in PCIe retrieval overhead for ShadowKV/RetroInfer, and more efficient GPU kernels in the case of SeerAttention-R.
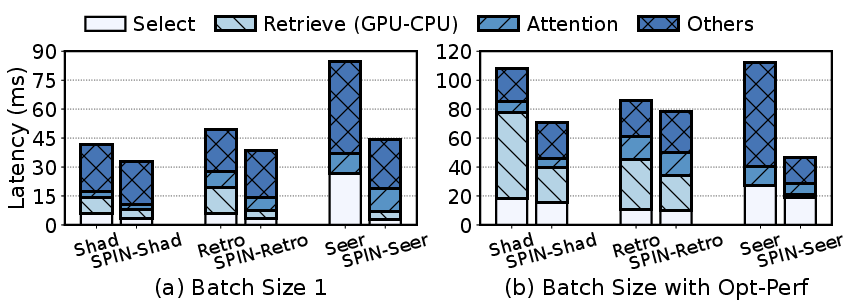
Figure 11: Spin consistently reduces decode-phase per-token latency for all integrated sparse attention algorithms.
Ablation Studies
- Buffer management: Buffering past partitions via bucketed LRU yields ∼50% further throughput improvement over single-step caching (Figure 12).
- Cache size: Hit ratio improves sharply up to a critical buffer size; further increases yield diminishing returns (Figure 13).
- Metadata: Two-level indirection and CPU placement cuts HBM metadata footprint by $49$–78×.
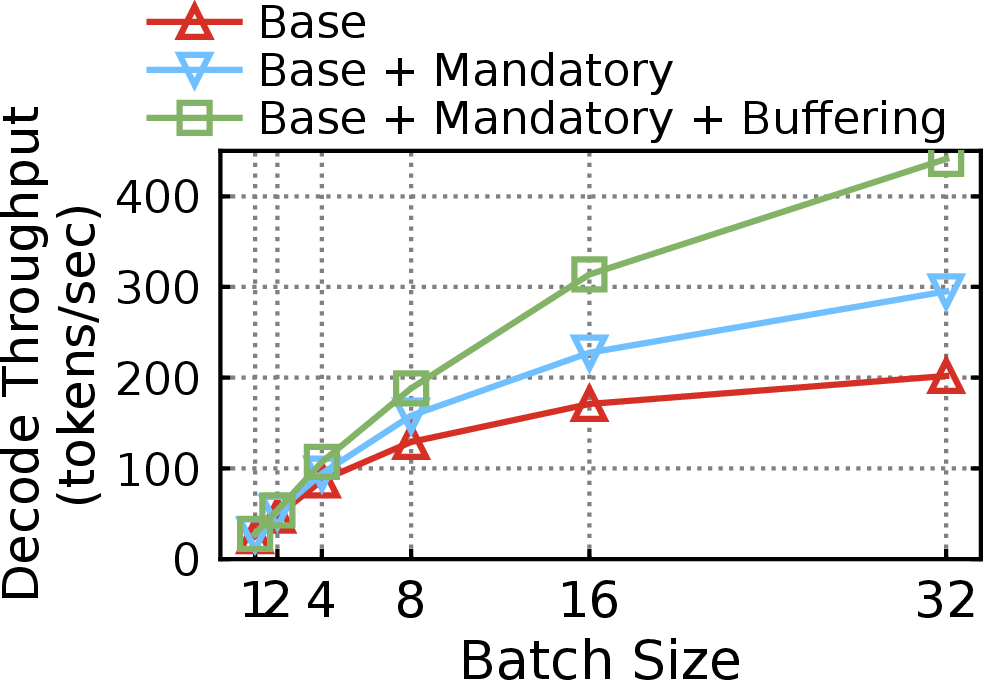
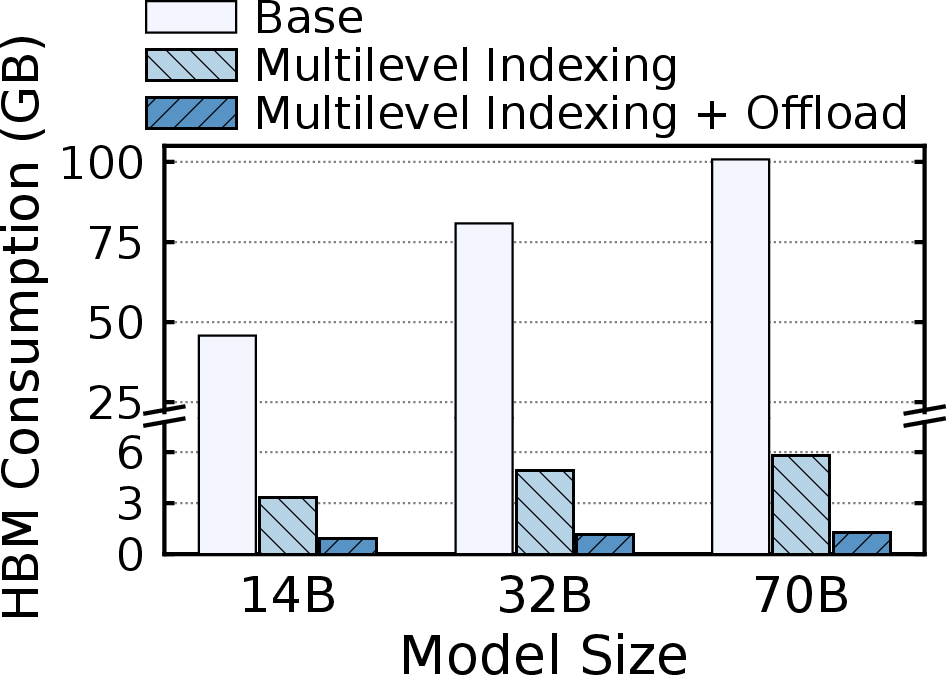
Figure 12: Throughput is maximized by exploiting cross-step locality via GPU-friendly buffer management.
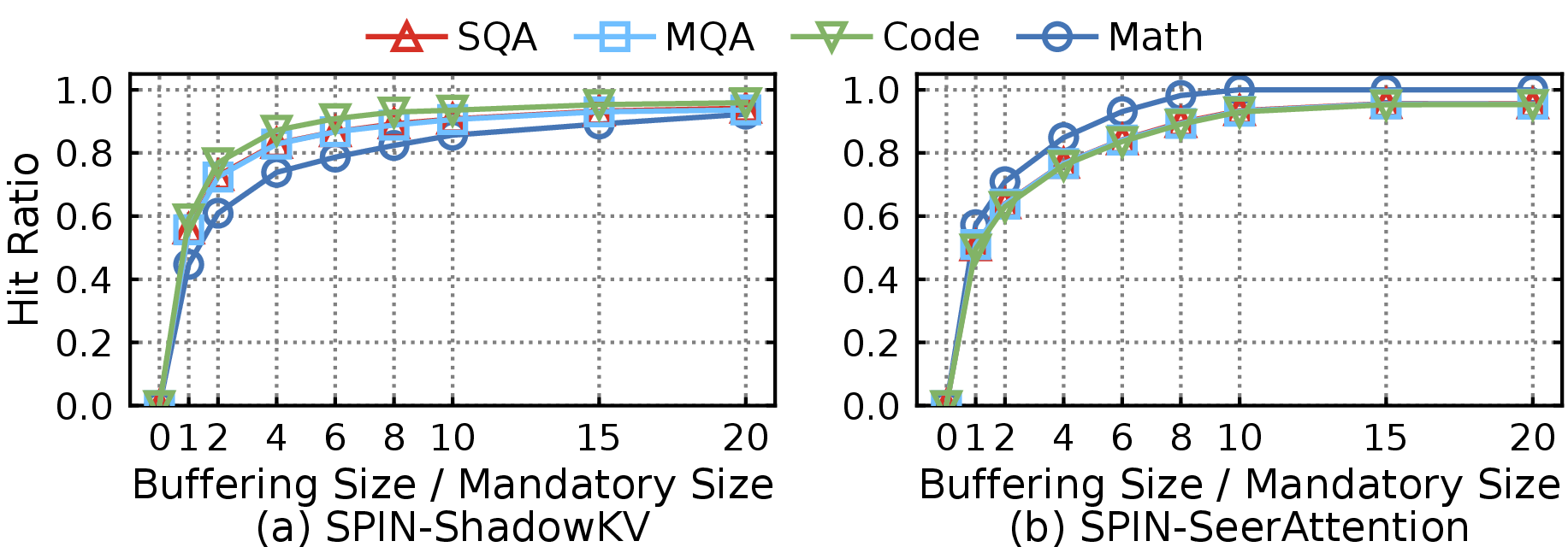
Figure 13: Cache hit ratio grows with cache size but saturates quickly, suggesting moderate buffering is optimal.
Practical and Theoretical Implications
By unifying algorithmic abstraction and system design, Spin closes much of the gap between theoretical sparsity-driven throughput and realized serving performance. Practically, this enables scalable serving of long-context LLMs on fixed GPU resources and provides a robust foundation for future sparse attention research to "plug in" new selection/indexing schemes with minimal engineering.
Theoretically, the critical insight is that end-to-end efficiency is governed by (a) the mapping of algorithmic sparsity granularity to system-level page and partition design, and (b) localized, dynamic, and scalable metadata and cache management. Spin's adoption of OS-style memory hierarchy, as well as exploitation of intra-step and inter-step locality, represents an effective generalization for future LLM system frameworks.
Looking ahead, the Spin abstraction facilitates straightforward extension to more advanced hardware (e.g., memory-centric Blackwell architectures), integration of train-time hardware-aware sparse attention, and adoption of speculative decoding strategies. The locality-aware scheme also admits further coupling with quantization, weight sparsity, and even utility-driven scheduling to balance quality and performance.
Conclusion
Spin provides a principled, unified execution substrate for sparse attention serving with hierarchical KV memory. Through its partition abstraction, locality-aware dynamic buffer management, and hierarchical metadata structures, it delivers substantial throughput and latency gains over existing LLM serving frameworks while preserving integration flexibility for diverse sparse attention algorithms. This architectural co-design is critical for scaling LLM inference across growing context sizes and model scales (2604.26837).