Unified 4D World Action Modeling from Video Priors with Asynchronous Denoising
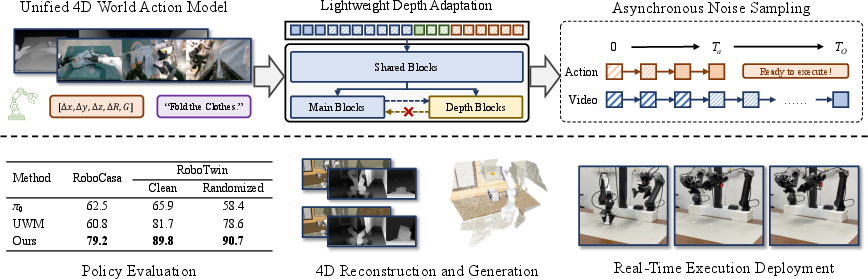
Abstract: We propose X-WAM, a Unified 4D World Model that unifies real-time robotic action execution and high-fidelity 4D world synthesis (video + 3D reconstruction) in a single framework, addressing the critical limitations of prior unified world models (e.g., UWM) that only model 2D pixel-space and fail to balance action efficiency and world modeling quality. To leverage the strong visual priors of pretrained video diffusion models, X-WAM imagines the future world by predicting multi-view RGB-D videos, and obtains spatial information efficiently through a lightweight structural adaptation: replicating the final few blocks of the pretrained Diffusion Transformer into a dedicated depth prediction branch for the reconstruction of future spatial information. Moreover, we propose Asynchronous Noise Sampling (ANS) to jointly optimize generation quality and action decoding efficiency. ANS applies a specialized asynchronous denoising schedule during inference, which rapidly decodes actions with fewer steps to enable efficient real-time execution, while dedicating the full sequence of steps to generate high-fidelity video. Rather than entirely decoupling the timesteps during training, ANS samples from their joint distribution to align with the inference distribution. Pretrained on over 5,800 hours of robotic data, X-WAM achieves 79.2% and 90.7% average success rate on RoboCasa and RoboTwin 2.0 benchmarks, while producing high-fidelity 4D reconstruction and generation surpassing existing methods in both visual and geometric metrics.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper introduces X-WAM, a powerful robot “brain” that can do two things at once:
- Plan and execute actions in real time (so the robot can move correctly), and
- Imagine and rebuild the future world in 3D as a video (so it “sees” what will happen next, in detail).
They call it a 4D world model because it handles 3D space over time (3D + time = 4D). Unlike older systems that only looked at flat 2D images, X-WAM understands depth and space, which helps it make more realistic predictions and better decisions.
Key questions the paper asks
- Can one model both decide what a robot should do next and also predict high-quality future videos and 3D scenes?
- How can we add true 3D understanding (depth) without making the model slow or breaking what it already learned from huge video datasets?
- How can we make action decoding fast (for real-time control) while still creating sharp, high-quality videos that usually take more time to generate?
How they did it (in simple terms)
Think of X-WAM as a smart movie maker and a robot controller combined:
- It watches a few camera views (like cameras around a kitchen and one on the robot’s wrist).
- It predicts the next frames of the scene as a video and also predicts what the robot should do (its actions and states).
- It also outputs depth, which tells how far things are from the camera. With depth from multiple views, you can build a 3D picture of the scene (like a point cloud).
Two big ideas make this work:
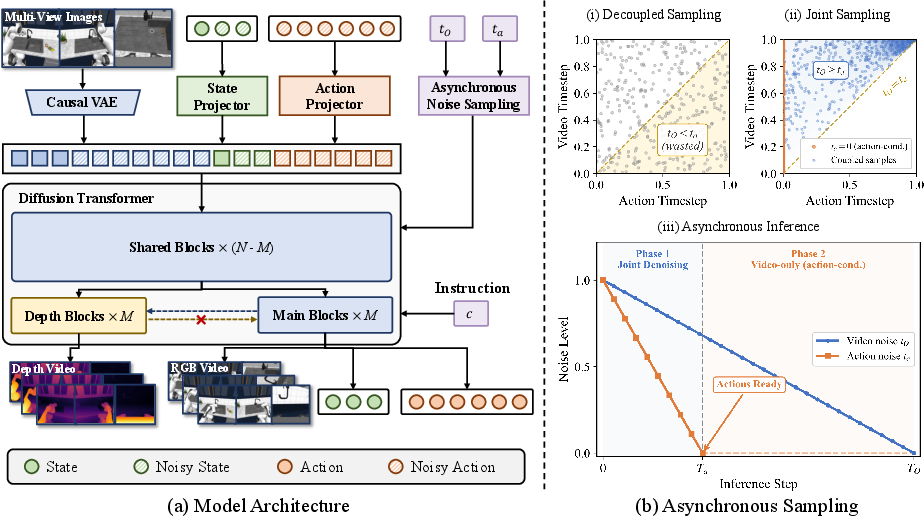
1) Lightweight depth module (adding 3D without slowing down)
- The base of X-WAM is a big pre-trained video model (a Diffusion Transformer). Diffusion models start from noisy images and slowly “denoise” them to produce realistic frames, like un-blurring a picture step by step.
- Naively adding depth as extra frames would nearly double the work. Instead, they copy just the last few layers of the model to create a small “depth branch.”
- This depth branch reads features from the main video branch (one-way attention), so it learns depth from the same visual cues, but it doesn’t interfere with the main model. It’s like adding a slim “depth reader” on top of an already smart video maker.
- Result: the model gets 3D awareness (depth) without becoming heavy or slow.
2) Asynchronous Noise Sampling (fast actions, high-quality video)
- Actions (robot movements) are simple and small; videos are big and detailed. So they shouldn’t take the same time to generate.
- During “denoising,” X-WAM uses fewer steps for actions and more steps for video:
- Actions get decoded quickly in a few steps and can be sent to the robot right away (so it moves in real time).
- The video keeps denoising for more steps to look crisp and realistic.
- During training, they match this behavior by sampling “noise levels” for actions and video together (not separately), so the model learns exactly the kind of timing it will use during real use. Think of it like downloading a small file (actions) fast while a big file (video) continues downloading in the background.
Other helpful details:
- Multi-view cameras: Some cameras are fixed; the wrist camera moves with the robot arm. Instead of predicting all camera positions directly, the model predicts the robot’s hand pose and uses a known offset to get the wrist camera’s pose. That makes 3D fusion across views simpler and more reliable.
- The model was fine-tuned from a large video model and trained on 5,800+ hours of robot data—so it has strong “visual common sense” about the world and how it changes.
Main findings and why they matter
- Better robot success: X-WAM completed tasks more often than previous methods.
- RoboCasa benchmark: 79.2% average success (about 12 percentage points better than the best baseline reported).
- RoboTwin 2.0 benchmark: up to 90.7% success under tougher, randomized setups.
- Higher-quality 4D predictions:
- Sharper, more realistic future videos.
- Much more accurate depth and 3D reconstructions (point clouds), meaning the model “understands” the scene’s geometry better.
- Real-time control with clear visuals:
- Thanks to Asynchronous Noise Sampling, actions come out fast (the robot doesn’t have to wait), while the video keeps refining to look great.
- In tests, this gave roughly a 4.5× speedup in action decoding latency without sacrificing video quality.
Why this matters:
- Robots need to act quickly and also understand the 3D world around them. Doing both well in one model is hard—but X-WAM shows it’s possible.
- Depth (3D understanding) doesn’t just help make pretty visuals; it also makes the robot’s decisions more reliable and physically sensible.
What this could lead to (impact and future ideas)
- Smarter, safer home and factory robots that can predict what will happen next in 3D and plan accordingly.
- One unified model that can be used for:
- Generating realistic robot training videos,
- Reconstructing 3D scenes for mapping and understanding,
- Controlling robots in real time.
- A general recipe for balancing speed and quality: decode simple things fast (actions), keep refining complex things (video) longer. This idea could help many AI systems that mix small, urgent decisions with large, detailed outputs (like self-driving, AR/VR, or assistive robots).
In short, X-WAM shows that adding lightweight 3D understanding and smart timing to a large video model can produce a single system that both acts well and sees the world clearly—now and into the near future.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concrete, actionable list of what remains missing, uncertain, or unexplored in the paper, to guide future research.
- Long-horizon scalability: The model predicts only H=8 future frames and K=32 actions per rollout. It is unclear how performance and stability scale to substantially longer horizons, multi-step subtasks, or episodic tasks requiring hundreds of steps without drift or compounding errors.
- Real-time control latency: Even with 5 action denoising steps, reported action latency is ~1033 ms. It is unknown how to reduce latency to tens of milliseconds for high-frequency control, and whether techniques like KV caching, distillation, or fewer/lighter steps can preserve performance.
- Asynchronous schedule design choices: The ANS joint sampling uses a fixed mixture (p) and a Beta(1.5,1) prior; sensitivity to these hyperparameters is not analyzed. There is no principled criterion for choosing Ta/TO per task, horizon, or hardware budget.
- Modalities beyond actions and video: ANS ties states to actions with t_s=t_a and handles only two denoising rates. It is unclear how to generalize ANS to additional modalities (e.g., force/torque, audio, language streams) with distinct optimal step budgets, or to decouple states and actions if their optimal schedules differ.
- Training–inference distribution alignment under evolving scenes: During inference, video denoising continues after actions are fixed and executed. The extent to which this still mismatches real online execution (where the environment changes in response to executed actions and new observations arrive) is not quantified.
- Data source and supervision for depth in real data: The depth branch is trained with inverse depth MSE, but the paper does not specify how ground-truth depth is obtained for real-robot segments of the 5,800-hour corpus (e.g., sensor depth vs. pseudo-depth from monocular estimators) and how supervision quality affects performance.
- Robustness to depth and pose noise: The method is validated largely in simulation for 4D metrics. It remains unclear how robust the depth branch and 3D fusion are to realistic sensor noise, missing depth, multi-path interference, and calibration errors in real deployments.
- Camera pose assumptions and generality: The approach assumes static extrinsics for fixed cameras and derives wrist-camera pose from end-effector pose with a fixed hand–eye matrix. It is unknown how the model performs when camera extrinsics are unknown, drift over time, or when additional/mobile cameras (e.g., head-mounted) are present.
- Failure cases of wrist-camera alignment: Pixel metrics are omitted for the wrist view due to misalignment from end-effector pose errors. How to reduce this drift (e.g., tighter kinematic modeling, pose refinement, or joint optimization of camera and robot poses) is not explored.
- Variable or missing views at inference: Multi-view inputs are assumed with learnable view embeddings; the model’s robustness to missing views, variable numbers of cameras, or asynchronous streams is not evaluated.
- 3D fusion methodology and temporal consistency: The paper reports point cloud Chamfer Distance but does not detail the RGB-D fusion pipeline, temporal smoothing, or cross-time consistency measures (e.g., scene flow, geometry drift). Robust 4D scene consistency remains an open problem.
- Explicit physics and contact modeling: Despite improved geometry, the model lacks explicit physical constraints (e.g., contact dynamics, collision avoidance). Whether integrating differentiable physics or contact-aware priors could reduce hallucinations and improve policy reliability is untested.
- Action representation limits: The unified interface uses end-effector pose deltas and gripper positions. Applicability to joint-space control, mobile manipulation, legged locomotion, or tasks requiring force/torque control and compliance is not assessed.
- Occlusions and clutter: Performance under heavy occlusion, severe clutter, or deformable objects is not characterized. How explicit 3D modeling helps (or fails) in these regimes remains open.
- Language-conditioned generalization: Although the model accepts a language instruction c, the experiments do not report instruction-following generalization to novel prompts, synonyms, or long-form instructions.
- Domain and robot transfer: While a common state/action interface is defined, the paper does not test zero-shot or few-shot transfer to new robot morphologies, grippers, or environments not represented in training.
- Data efficiency vs. scale: The model is pretrained on 5,800+ hours of data. The trade-off between data scale and performance, and whether the gains persist under limited data or with synthetic augmentation, is unexplored.
- Computational footprint and deployability: Training and inference rely on a 5B-parameter video DiT (Wan2.2-TI2V-5B). The hardware requirements, energy footprint, and feasibility of deploying on typical robot compute platforms are not reported.
- Alternative 3D representations: The method predicts depth via a unilateral interleaved branch. Comparisons to native 3D world models (e.g., 3D Gaussians, NeRFs, point-based latent spaces) in the unified setting, including quality–latency–memory trade-offs, are missing.
- Depth-branch scheduling at inference: The paper states the depth branch can be toggled off during action decoding, but does not examine when to enable/disable it, the impact on action quality, or whether intermittent updates suffice for accurate 3D reconstruction.
- Action-conditioned video continuation: After actions are decoded and dispatched (Ta steps), video denoising continues conditioned on clean actions without incorporating new observations. The utility and fidelity of these continued predictions for planning/control is not quantified.
- Multi-rate and task-adaptive scheduling: The fixed ratio K/H=4 and global step budgets may not suit all tasks. Automatic selection of per-modality step counts or adaptive schedulers conditioned on task difficulty and resource constraints is unaddressed.
- Real-world 4D evaluation: 4D metrics are reported in simulation. There is no quantitative 4D evaluation on real-robot sequences with ground-truth geometry (e.g., RGB-D sensors, motion capture), leaving real-world reconstruction fidelity uncertain.
- Safety and failure analysis: The paper lacks analysis of failure modes (e.g., unsafe action proposals, geometry hallucinations near contacts) and does not discuss safeguards or uncertainty estimates for safe deployment.
- Statistical significance and generality of ablations: Ablations are conducted without large-scale pretraining due to compute limits. Whether the same conclusions hold for the fully pretrained model is not demonstrated.
- Sensitivity to hand–eye calibration: The approach relies on a fixed hand–eye transform. How sensitive the 4D reconstruction and control are to calibration bias or drift, and whether online calibration refinement is needed, is not studied.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can be implemented with current capabilities of X-WAM (as described), its training scale, and performance characteristics.
- Robotics workcells for assembly, kitting, and packing (manufacturing, consumer electronics, logistics)
- Use X-WAM as a real-time visuomotor policy with predictive lookahead to execute tasks like bin picking, connector insertion, cable routing, and packing (e.g., the earphone packing demo).
- Workflow/product: A ROS2-compatible “X-WAM Skill Server” decodes actions in a few diffusion steps (e.g., 5) while streaming higher-fidelity multi-view RGB-D predictions in the background for monitoring and logging.
- Assumptions/dependencies: Multi-view cameras (static + wrist), hand–eye calibration, adequate GPU for a 5B-parameter DiT, sufficient in-domain data for fine-tuning; safety interlocks for physical deployment.
- Predictive operator UI for teleoperation and supervision (industrial robotics, warehouse automation)
- Provide operators with a short-horizon preview of the robot’s intended 4D future (multi-view RGB-D + action traces) to anticipate contact, occlusions, or collisions.
- Workflow/product: An HMI overlay that renders the next 0.5–2 seconds of predicted video and reconstructed point clouds alongside the planned gripper and end-effector poses.
- Assumptions/dependencies: Low-latency video streaming and calibration; the ANS schedule configured so fast action decoding does not block visualization.
- 4D digital-twin building blocks for cell monitoring and QA (manufacturing, quality control)
- Use X-WAM’s multi-view RGB-D and reconstructed point clouds to detect state drift (misplaced parts, clutter) and verify step completion without extra depth sensors.
- Tools: A “4D scene differencing” module comparing predicted vs observed point clouds; automatic logging with PSNR/SSIM/LPIPS and Chamfer Distance as internal QA signals.
- Assumptions/dependencies: Stable static camera extrinsics; wrist camera pose derived from end-effector pose; point cloud fusion pipeline.
- Safer manipulation via plan plausibility checks (cross-industry robotics)
- Reject actions that imply physically inconsistent 3D outcomes (self-collisions, penetrations) using predicted depth/point clouds before execution.
- Tools: A lightweight collision/proximity checker that consumes predicted geometry and end-effector trajectories; rule-based guardrails on top of X-WAM outputs.
- Assumptions/dependencies: Accurate kinematics and calibration; conservative thresholds; fast geometric checks to fit the ANS real-time loop.
- Synthetic multi-view RGB-D data generation for training and benchmarking (robotics, simulation platforms)
- Generate task-conditioned 4D rollouts to augment datasets, improve representation balance across views, and benchmark multi-view consistency.
- Tools: A “Data Augmenter” that runs X-WAM in action-conditioned mode (ANS with t_a=0) to create high-fidelity video/depth for supervised learning or sim2real gap studies.
- Assumptions/dependencies: Licensing for base video model (Wan2.2) and generated data policies; domain-specific prompt/conditioning recipes.
- Drop-in depth adaptation for video diffusion models (software, vision)
- Apply the lightweight “replicate-last-DiT-blocks” depth branch to other pretrained video DiTs to obtain RGB-D outputs without doubling sequence length.
- Tools: A model surgery script that clones the final M blocks, adds unilateral cross-attention, and trains inverse-depth MSE with minimal hyperparameter tuning.
- Assumptions/dependencies: Access to the original DiT architecture and weights; availability of paired RGB–depth supervision or pseudo-depth.
- Low-latency control in resource-constrained robots via ANS (robotics platforms)
- Use ANS to decode low-dimensional actions in few steps while continuing video denoising off the critical path, reducing control latency ~4–5× (as shown in ablations).
- Tools: An “Async Scheduler” library (UniPC-based) with separate step budgets for actions/states (e.g., 5) and video (e.g., 25).
- Assumptions/dependencies: Separate scheduler instances; careful matching of training and inference noise distributions.
- Education and research curricula on unified 4D world-action modeling (academia)
- Course modules and lab assignments demonstrating: (i) unified modeling of video and actions, (ii) joint RGB-D prediction and 3D fusion, (iii) asynchronous diffusion for multimodal outputs.
- Tools: Starter kits with evaluation on RoboCasa/RoboTwin, ablation toggles for depth branch and ANS; visualization notebooks.
- Assumptions/dependencies: Access to GPUs, datasets, and permissible base model weights for educational use.
- Real-time assistive overlays for human–robot collaboration (HRC) (manufacturing, warehousing)
- Show workers a predicted path, grasp point, and occlusion map derived from the reconstructed depth to coordinate handovers and avoid interference.
- Tools: AR or screen-based overlays with predicted end-effector trajectories and risk heatmaps.
- Assumptions/dependencies: Accurate time synchronization; ergonomic HRC protocols; validated safety zones.
- Benchmarking suite for 4D policy models (academia, consortia)
- Standardize evaluation with joint policy SR and 4D metrics (PSNR/SSIM/LPIPS, AbsRel/δ1, Chamfer Distance) to measure both control and spatial fidelity.
- Tools: Reusable evaluation harnesses for multi-view logging, pose alignment, and reconstruction quality.
- Assumptions/dependencies: Consistent camera configs; canonical coordinate frames; openness of tasks and metrics.
Long-Term Applications
These use cases will likely require further scaling, validation in broader domains, regulatory engagement, or dedicated productization and hardware support.
- Home assistant and service robots with 4D foresight (consumer robotics, eldercare)
- Use X-WAM-like models for tidying, cooking prep, and assistive tasks, leveraging predictive RGB-D and low-latency control to operate safely around people.
- Potential product: A “predict-and-explain” home robot that previews intended actions and anticipated scene changes for user approval.
- Assumptions/dependencies: Robust generalization far beyond training data; dense household multi-view sensing; strong safety/certification; efficient on-device inference or edge offload.
- Surgical and medical robotics with predictive, 3D-aware control (healthcare)
- Apply unified 4D world-action modeling to delicate manipulation under visual occlusions (e.g., suturing) with action preview and 3D consistency checks.
- Tools: Certified ANS-like schedulers for low-latency micro-actions, high-fidelity endoscopic video synthesis for planning.
- Assumptions/dependencies: Strict regulatory approval, high-precision calibration, domain-specific datasets, fail-safe architectures.
- Autonomous driving, drones, and mobile manipulation with asynchronous control (transportation, logistics)
- Extend the ANS paradigm to decode control commands quickly (steering/thrust) while continuing high-fidelity scene predictions for situational awareness and logging.
- Tools: Multisensor fusion (RGB + depth/radar/LiDAR), 4D rollouts to anticipate occluded actors and multi-agent interactions.
- Assumptions/dependencies: Multimodal sensor alignment; real-time constraints at >50–100 Hz; training datasets with action labels.
- Plant-scale 4D digital twins with predictive maintenance (energy, manufacturing)
- Scale from workcells to facility-level, streaming predictive 4D reconstructions to detect anomalies, plan interventions, and schedule robots with foresight.
- Product: “Predictive Twin Orchestrator” that integrates X-WAM rollouts into CMMS/SCADA systems for maintenance planning.
- Assumptions/dependencies: Distributed multi-camera networks; data governance; scalable inference (cluster or edge); integration with legacy systems.
- Certified safety envelopes from predicted 3D geometry (policy, standards, safety)
- Use predicted depth/point clouds to derive probabilistic safety margins and certify policies against standardized scenarios (near-human, near-tool).
- Outcome: New standards for 4D-predictive policy validation and reporting, complementing ISO/TS and ANSI/RIA robot safety norms.
- Assumptions/dependencies: Consensus on 4D metrics, reproducible testbeds, regulatory buy-in.
- Generalist, multi-task world-action models for cross-domain robotics (academia, platform vendors)
- Train at larger scales to support broad families of robots (mobile, manipulators, dual-arm) via a universal state/action interface and multi-view sensing.
- Tools: Foundation-model “robot OS” with plug-and-play camera rigs and calibration-aware adapters.
- Assumptions/dependencies: Massive, diverse datasets; robust interface abstractions; standardized calibration formats.
- Integration with native 3D representations and neural rendering (software, graphics, robotics)
- Combine X-WAM’s RGB-D predictions with 3D Gaussian Splatting or neural fields for temporally consistent, editable world models used in planning and sim.
- Product: “4D Gaussian Planner” enabling faster re-planning by editing the 3D scene hypothesis directly.
- Assumptions/dependencies: Real-time 3D rendering on edge GPUs; differentiable interfaces between action tokens and 3D state.
- Human-intent prediction and shared autonomy (HRI, assistive tech)
- Condition X-WAM on human pose and gaze to forecast joint human–robot futures, mediating shared control with previewed outcomes.
- Workflow: The model suggests actions and shows predicted co-activity; the human approves/edits before dispatch.
- Assumptions/dependencies: Reliable human sensing; intuitive UIs; data for joint behavior modeling; privacy safeguards.
- Resource-efficient deployment via distillation and hardware co-design (chips, embedded AI)
- Distill 5B-parameter models to edge-suitable sizes and co-design accelerators optimized for ANS (faster low-dim decoding, amortized high-dim denoising).
- Tools: Student–teacher training for action heads; token-pruning or early-exit for video tokens.
- Assumptions/dependencies: Maintained policy SR after compression; hardware availability and toolchains.
- Standardized multi-view dataset and calibration protocols (policy, ecosystem)
- Establish data schemas for static and wrist-mounted cameras, end-effector pose labels, and hand–eye matrices to enable reproducible 4D policy training.
- Outcome: Open datasets and benchmarks spanning RoboCasa/RoboTwin-like tasks with 4D metrics.
- Assumptions/dependencies: Community coordination; IP/licensing clarity; common simulators or capture rigs.
- Compliance-friendly, privacy-preserving 4D modeling (policy, governance)
- On-device inference and redaction for multi-view household/enterprise video; secure logging of predicted futures for audit without exposing raw frames.
- Tools: Federated fine-tuning pipelines; differential privacy for action streams.
- Assumptions/dependencies: Efficient on-device models; regulatory frameworks for predictive records.
- Design-time task validation and automation planning (industrial engineering)
- Use 4D rollouts to validate fixtures, camera placements, and task feasibility before commissioning a cell; iterate virtually to reduce bring-up time.
- Tools: CAD-to-sim to X-WAM loop for predictive feasibility studies; automatic camera placement optimization based on reconstruction quality metrics.
- Assumptions/dependencies: Accurate digital cell models; bridging tools between CAD/PLM and robotics stacks.
Glossary
- 3D Gaussian Splatting: A neural rendering technique that represents scenes with Gaussian primitives for fast, high-fidelity 3D rendering. "utilizing the neural rendering technique of 3D Gaussian Splatting~\cite{3dgs} to build high-fidelity 3D world models."
- 4D World Model: A model that predicts spatial 3D structure over time (3D + time), enabling both generation and reconstruction of dynamic scenes. "We propose X-WAM, a Unified 4D World Model that unifies real-time robotic action execution and high-fidelity 4D world synthesis (video + 3D reconstruction) in a single framework"
- AbsRel (Absolute Relative Error): A depth estimation metric measuring average absolute relative error between predicted and ground-truth depths. "We adopt three groups of metrics: PSNR, SSIM, and LPIPS for visual fidelity, absolute relative error (AbsRel) and accuracy for depth quality, and Chamfer Distance (CD) for the quality of the reconstructed point clouds."
- Action-conditioned world model: A world model that generates future observations conditioned on known or predicted actions. "In this regime, the inference process naturally becomes an action-conditioned world model."
- Asynchronous denoising schedule: A scheduling strategy where different modalities are denoised for different numbers of steps to balance speed and quality. "ANS applies a specialized asynchronous denoising schedule during inference"
- Asynchronous Noise Sampling (ANS): A coupled noise scheduling and training strategy for jointly generating videos and actions with mismatched denoising horizons. "Moreover, we propose Asynchronous Noise Sampling (ANS) to jointly optimize generation quality and action decoding efficiency."
- Bidirectional full attention: A Transformer attention pattern where tokens attend to all others in both temporal directions, enabling joint reasoning across the entire sequence. "which is processed with bidirectional full attention, with depth reconstructed from the generated RGB video sequence."
- Causal attention masks: Attention masks that restrict each token to attend only to past tokens, enabling autoregressive or causal computation. "leverage causal attention masks and KV caching to reduce inference latency."
- Causal VAE encoder: A variational autoencoder with causal (temporal) structure used to encode video frames into latent tokens for diffusion. "RGB videos are encoded into latent representations via the original causal VAE encoder "
- Chamfer Distance (CD): A geometric metric measuring the distance between two point clouds by averaging nearest-neighbor distances. "and Chamfer Distance (CD) for the quality of the reconstructed point clouds."
- Delta-1 (δ1) accuracy: A depth metric measuring the fraction of pixels whose predicted depth is within a fixed ratio threshold of ground truth. "We adopt three groups of metrics: PSNR, SSIM, and LPIPS for visual fidelity, absolute relative error (AbsRel) and accuracy for depth quality, and Chamfer Distance (CD) for the quality of the reconstructed point clouds."
- Diffusion Transformer (DiT): A Transformer-based diffusion model architecture for image/video generation via iterative denoising. "pretrained Diffusion Transformer (DiT)~\cite{dit}"
- End-effector pose: The 6-DoF pose (position and orientation) of a robot’s tool or hand in space. "predicts the end-effector pose $\mathbf{T}_{\text{ee} \in SE(3)$"
- Flow matching framework: A training objective for generative models that learns a velocity field to transport noise to data along continuous-time paths. "we fine-tune X-WAM using the flow matching framework~\cite{flowmatching}."
- Hand-to-eye calibration matrix: A fixed rigid transform relating the robot end-effector frame to a wrist-mounted camera frame. "and derives the wrist camera pose via the fixed hand-to-eye calibration matrix"
- KV caching: Storing Transformer key/value tensors from prior steps to accelerate autoregressive or incremental inference. "leverage causal attention masks and KV caching to reduce inference latency."
- LPIPS: A learned perceptual image similarity metric that correlates with human judgment of visual similarity. "We adopt three groups of metrics: PSNR, SSIM, and LPIPS for visual fidelity"
- Mixture of Transformer: An architecture that uses separate Transformer components per modality, potentially with independent timesteps and parameters. "employ a Mixture of Transformer architecture with independent parameters and denoising timesteps for each modality."
- Multi-view RGB-D: Synchronized color (RGB) and depth (D) observations captured from multiple camera viewpoints. "predicting multi-view RGB-D videos"
- Proprioceptive states: Internal robot states (e.g., joint positions, end-effector pose, gripper status) sensed by the robot itself. "multi-view RGB observations, proprioceptive states, and noisy actions are encoded"
- Rotary Position Embeddings (RoPE): A positional encoding method that injects relative position via complex rotations, here extended to 3D spatiotemporal tokens. "employing 3D Rotary Position Embeddings (RoPE)~\cite{rope} to encode temporal and spatial positions within the sequence."
- SE(3): The Special Euclidean group in 3D, representing 3D rigid body motions (rotations and translations). "predicts the end-effector pose $\mathbf{T}_{\text{ee} \in SE(3)$"
- UniPC multistep scheduler: A diffusion sampling scheduler that improves speed-accuracy tradeoffs via multi-step predictor-corrector updates. "During inference, we employ the UniPC~\cite{unipc} multistep scheduler recommended by Wan2.2"
- Unilateral attention: A one-way cross-attention design where one branch reads from another without reciprocal influence. "We term this asymmetric connectivity unilateral attention: the depth branch can read from the main branch, but not vice versa"
- Unified World Model (UWM): A prior unified video-action modeling framework, here noted as limited to 2D pixel-space. "addressing the critical limitations of prior unified world models (e.g., UWM) that only model 2D pixel-space"
- Velocity field: In flow matching, the vector field mapping noisy samples toward clean data along a continuous-time trajectory. "The model is trained to predict the velocity field "
- Vision-Language-Action (VLA) models: Models that map visual and language inputs to robot actions for control. "Vision-Language-Action (VLA) models~\cite{rt2, octo, openvla, pi0, pi0.5, gr00t, gr1} fine-tune pretrained Vision-LLMs (VLMs) to output motor commands"
- World Action Model (WAM): A unified framework that predicts future observations (videos) and robot actions jointly. "World Action Models (WAMs)~\cite{lingbotva, dreamzero, fastwam, cosmospolicy, gigaworldpolicy} further leverage video generation models to jointly predict future observations and actions"
Collections
Sign up for free to add this paper to one or more collections.