- The paper presents a hardware-efficient compilation pipeline that employs Trotter decomposition and variational refinement to dramatically reduce entangling gate counts.
- The paper demonstrates that shallow, adaptive circuits on IBM hardware achieve higher process fidelity than deeper exact decompositions.
- The paper highlights the effectiveness of physics-informed, Trotter-structured ansätze in preserving trainability and mitigating barren plateau effects.
Structure-Aware Compilation for Hamiltonian Simulation on NISQ Devices
Overview and Motivation
The compilation of time-evolution operators U(t)=e−iHt into hardware-native gates is a critical bottleneck for digital quantum simulation in the NISQ regime. The prevailing practice—generic unitary synthesis via standard transpilers—results in circuit depths that exceed coherence limits, fundamentally constraining simulation fidelity. This paper introduces a structure-preserving compilation framework that leverages product-formula (Trotter–Suzuki) decompositions as synthesis primitives, rather than merely approximation tools. The approach combines native circuit placement, adaptive block discretization, and variational refinement initialized via Trotterization, yielding substantial reductions in entangling gate count while maintaining high process fidelity. Experimental validation on IBM Torino hardware demonstrates a regime where shallow approximate circuits outperform deeper exact decompositions, contradicting the conventional expectation that exactness optimizes hardware fidelity (2604.26663).
Compilation Pipeline Description
The compilation pipeline operates in three distinct stages:
- Native Decomposition: Hamiltonian terms are mapped to hardware-native gates respecting the device connectivity. This eliminates the routing overhead associated with generic all-to-all decomposition and SWAP insertions.
- Adaptive Product-Formula Synthesis: A greedy procedure selects Trotter–Suzuki blocks from a precompiled block library, constructing a non-uniform, Hamiltonian-informed discretization.
- Variational Refinement: When fixed product formulas are inadequate (e.g., in the strong-coupling regime), the pipeline employs a Trotter-structured ansatz, initialized near the identity, and refines the circuit via classical optimization with L-BFGS.
This structure-aware strategy restricts circuit construction to a submanifold generated by the local terms of H, leveraging both algebraic structure and device topology.
Experimental Results and Methodology
Hardware Validation: Depth–Noise Trade-off
On IBM Torino, the structure-aware pipeline produces circuits with dramatically reduced CX counts compared to Qiskit’s blackbox unitary synthesis. In the n=4 Heisenberg scenario, a 27-CX variational pipeline achieves hardware fidelity Fhw=0.987 for the ∣++++⟩ initial state, outperforming the 187-CX exact circuit (Fhw=0.974), despite the latter’s higher simulation fidelity. For computational basis states, the pipeline retains Fhw=0.828, while the blackbox circuit drops to Fhw=0.407.
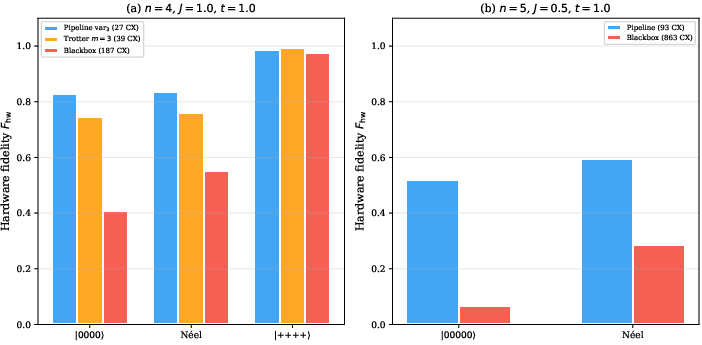
Figure 1: Fhw on IBM Torino: shallow variational circuits (27 CX) outperform exact decompositions (187 CX) across all initialization states, even when simulation fidelity is lower.
Noise Robustness
Simulations under depolarizing noise confirm the CX-count advantage. The adaptive pipeline (15 CX) maintains F>0.83 at pessimistic error rates, whereas blackbox circuits (217 CX) fall below H0. Even the fixed Trotter method (63 CX) is outperformed by the adaptive approach.
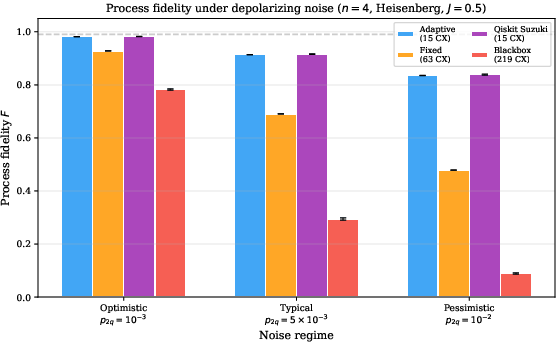
Figure 2: Process fidelity under depolarizing noise: native adaptive circuits retain high fidelity across noise regimes, while blackbox circuits collapse at moderate error rates.
Variational Stage: Optimization Landscape and Trainability
The variational refinement stage, using a Trotter-initialized ansatz, avoids barren plateaus ubiquitous in hardware-efficient, randomly initialized circuits. Gradient variance decays exponentially under random initialization (H1), but only polynomially for Trotter initialization (H2), preserving trainability up to H3.
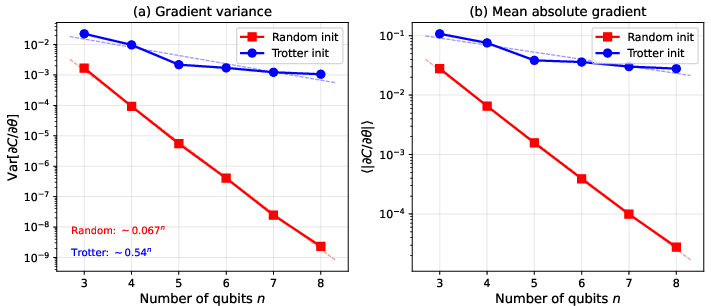
Figure 3: Gradient variance scaling: Trotter-initialized ansätze exhibit slower decay and larger absolute gradients compared to random initialization, mitigating barren plateau effects.
Parameter Sensitivity and Coverage
Across a grid of 36 Hamiltonian configurations (type, coupling, evolution time), the pipeline maintains H4, with variational refinement needed only for strong coupling regimes. Block selection and CX count adapt automatically, maximizing fidelity while minimizing entangling depth.
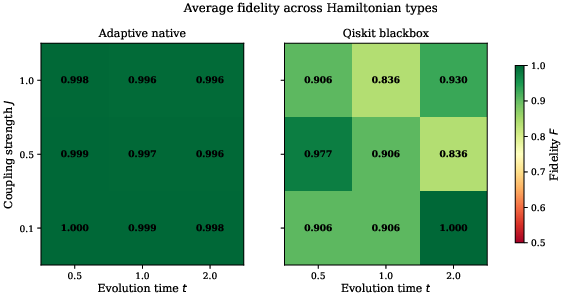
Figure 4: Fidelity heatmap for the adaptive pipeline across parameter regimes; variational refinement enables H5 in strong coupling cases where fixed Trotterization stalls.
Scaling Behavior
Gate counts for native methods scale linearly in H6, contrasting with blackbox synthesis, which grows exponentially and becomes infeasible above H7. For example, adaptive circuits require 50 CX gates at H8; blackbox circuits at H9 require 4345 CX.
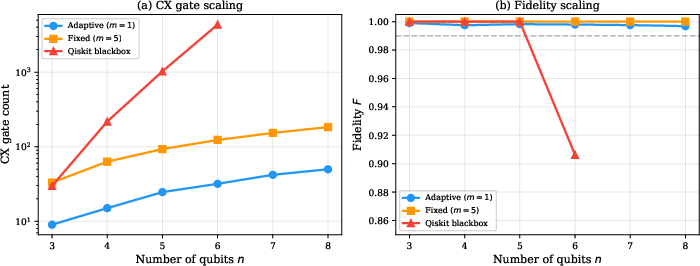
Figure 5: CX count (log scale) and fidelity as a function of n=40: native methods exhibit linear scaling, blackbox decomposition becomes impractical beyond n=41.
Error Mitigation Observations
Applying dynamical decoupling or Pauli twirling does not substantially improve the fidelity gap between pipeline and blackbox circuits. For computational basis states, mitigation can even degrade performance due to added gate depth. For n=42, twirling modestly increases n=43, but does not alter the ranking.
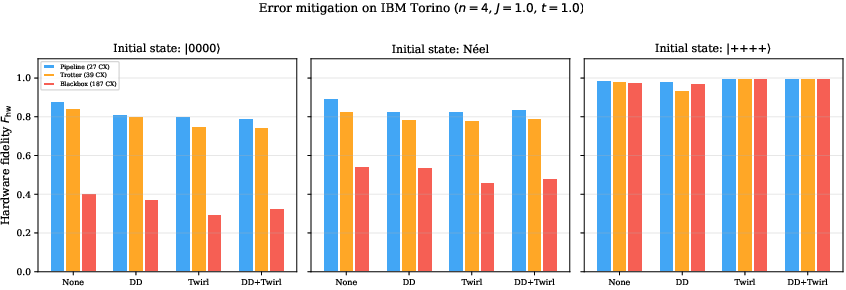
Figure 6: Error mitigation comparison: mitigation fails to close the depth-induced fidelity gap; circuit depth reduction is more effective than post-hoc error mitigation.
Discussion: Implications and Limitations
Practical Utility and Theoretical Implications
- Circuit Construction: By leveraging the algebraic and topological structure of n=44, the pipeline circumvents the exponential inefficiency inherent in generic unitary compilation. Each Trotter–Suzuki block advances the unitary along the geodesic defined by n=45, resulting in substantially greater fidelity improvement per step compared to gate-level synthesis.
- Trainability and Optimization: The use of physics-informed, Trotter-structured ansätze ensures that optimization starts in a region of parameter space with large, informative gradients, avoiding barren plateaus and enabling robust convergence for n=46.
- Hardware-Awareness: Native circuit placement not only eliminates routing overhead but also maximizes fidelity under realistic hardware error models.
- Universality–Performance Tradeoff: Structure-aware compilation exploits side information about n=47 to outperform universal transpilers; this is a necessary trade-off, given the principle that domain-specific knowledge enables more efficient solutions.
- Error Mitigation: Reducing circuit depth remains superior to post-execution mitigation techniques for NISQ hardware, especially as the number of entangling gates is the dominant noise source.
Limitations and Outlook
- Applicability: The framework presupposes knowledge of n=48 and is designed for nearest-neighbor Hamiltonians. Extension to more general connectivity graphs and Hamiltonian classes is a natural direction.
- Classical Cost: Classical optimization and unitary computation scale as n=49, restricting practical application to Fhw=0.9870. Future work may incorporate scalable tensor network methods or adjoint differentiation.
- Extension: Integration with higher-order product formulas, symmetry-adapted ansätze, and domain-specific compilers (e.g., Paulihedral, Rustiq) is feasible and may further improve resource efficiency.
Conclusion
This paper establishes that structure-aware, approximate compilation—rooted in physics-informed block decomposition and variational refinement—realizes a significant fidelity advantage over exact, structure-agnostic synthesis on NISQ hardware (2604.26663). The primary determinant of hardware simulation fidelity is entangling gate count, not simulation accuracy. By aligning compilation with the geometric, algebraic, and topological features of the Hamiltonian, the pipeline enables practical quantum simulation in the presence of realistic device constraints and noise. This framework provides a foundation for future developments in quantum software, emphasizing the value of domain-integration in algorithm design and compilation.

