- The paper establishes that state-of-the-art VLMs, particularly GPT-5.4, moderately approximate human gaze at longer exposure durations.
- The study employs the UEyes dataset with eye-tracking data across desktop, mobile, web, and poster interfaces for benchmark evaluation.
- Results indicate VLMs capture semantic attention better in structured UIs, though they underperform in modeling early, bottom-up visual saliency.
Evaluating VLMs as Predictors of Human Visual Attention on User Interfaces
Introduction
The delineation of human visual attention across user interfaces (UIs) is a foundational aspect of empirical HCI research and UX optimization. The ability to algorithmically generate accurate saliency maps without expensive eye-tracking studies would represent a significant efficiency gain for iterative UI design. "UIGaze: How Closely Can VLMs Approximate Human Visual Attention on User Interfaces?" (2604.26352) rigorously evaluates the extent to which contemporary Vision LLMs (VLMs) can serve as robust zero-shot predictors of gaze-based saliency on diverse UIs, benchmarking them with real human eye-tracking data. This essay reviews the paper's methodology, core results, and broader implications for computational modeling of visual attention.
Methods
The experimental protocol utilizes the UEyes dataset, which provides extensive, high-fidelity eye-tracking ground-truth on 1,980 screenshots spread over four UI categories: desktop, mobile, web, and poster. Gaze data was acquired from 62 participants, with fixation maps computed at 1s, 3s, and 7s intervals to approximate different stages of visual exploration.
Nine state-of-the-art VLMs, including flagship and lightweight versions from OpenAI (GPT-5.4, GPT-5.4-mini), Google (Gemini 3.1 Pro, Flash Lite), Anthropic (Claude Opus 4.6, Sonnet 4.6), Qwen (3.5 Plus, 3.5 Flash), and a UI specialist model (UI-TARS 1.5), are benchmarked in a uniform, zero-shot coordinate prediction setup. Each VLM, prompted to generate arrays of predicted fixation coordinates and relative intensities for each UI, provides output that is converted to dense saliency maps (via Gaussian blurring, σ=40px), matching the processing parameters of UEyes. Metrics include correlation coefficient (CC), similarity (SIM), and KL divergence quantifying spatial and probabilistic alignment with human ground truth.
Quantitative Results
GPT-5.4 demonstrates the strongest overall alignment to human gaze at the longest viewing interval (7s: CC=0.408, SIM=0.503, KL=1.345), with Anthropic's Claude Opus 4.6 and Qwen 3.5 Plus trailing but still providing moderate correspondence (CC > 0.33). Gemini models and UI-TARS 1.5 display minimal alignment (CC < 0.15, KL > 5.0), indicating that either limited visual-semantic reasoning (Gemini) or excessive task/action bias (UI-TARS) hinders gaze prediction, even in UI-centered domains.
Performance increases monotonically with the duration of visual exposure; on 1s maps (dominated by initial fixations), even the best VLMs show low CC (0.217–0.227), improving by approximately 88% at 7s (CC > 0.4), indicating that VLMs predominantly capture later, semantically-driven exploratory attention rather than bottom-up, salience-driven initial orienting.
Desktop UIs are most amenable to VLM-based prediction (GPT-5.4: CC=0.506), possibly due to pronounced visual hierarchy. Mobile and poster UIs, with denser or more idiosyncratic structure, yield lower alignment. Intriguingly, UI-TARS 1.5 demonstrates a near-zero correlation and, on mobile, even a negative one, reinforcing that operationalizing on actionable elements does not equate to modeling holistic human attention distribution.
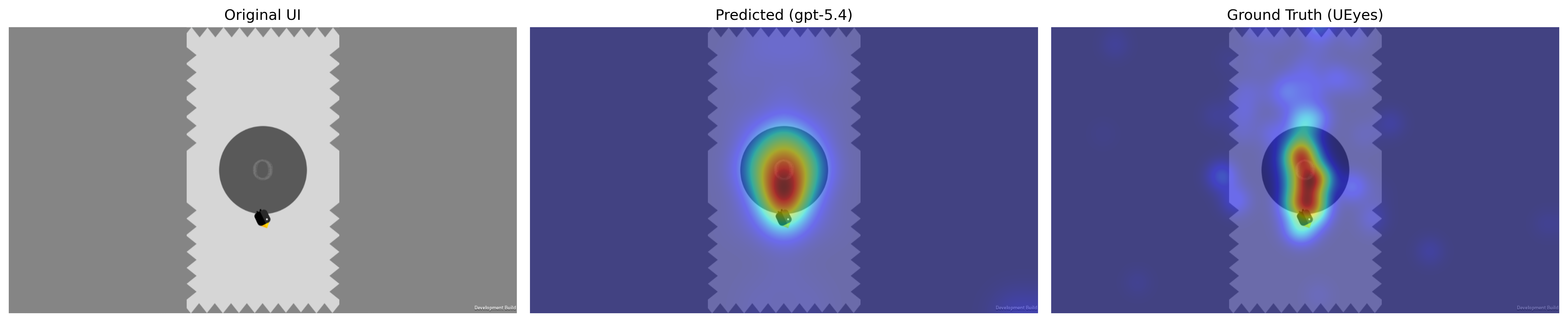
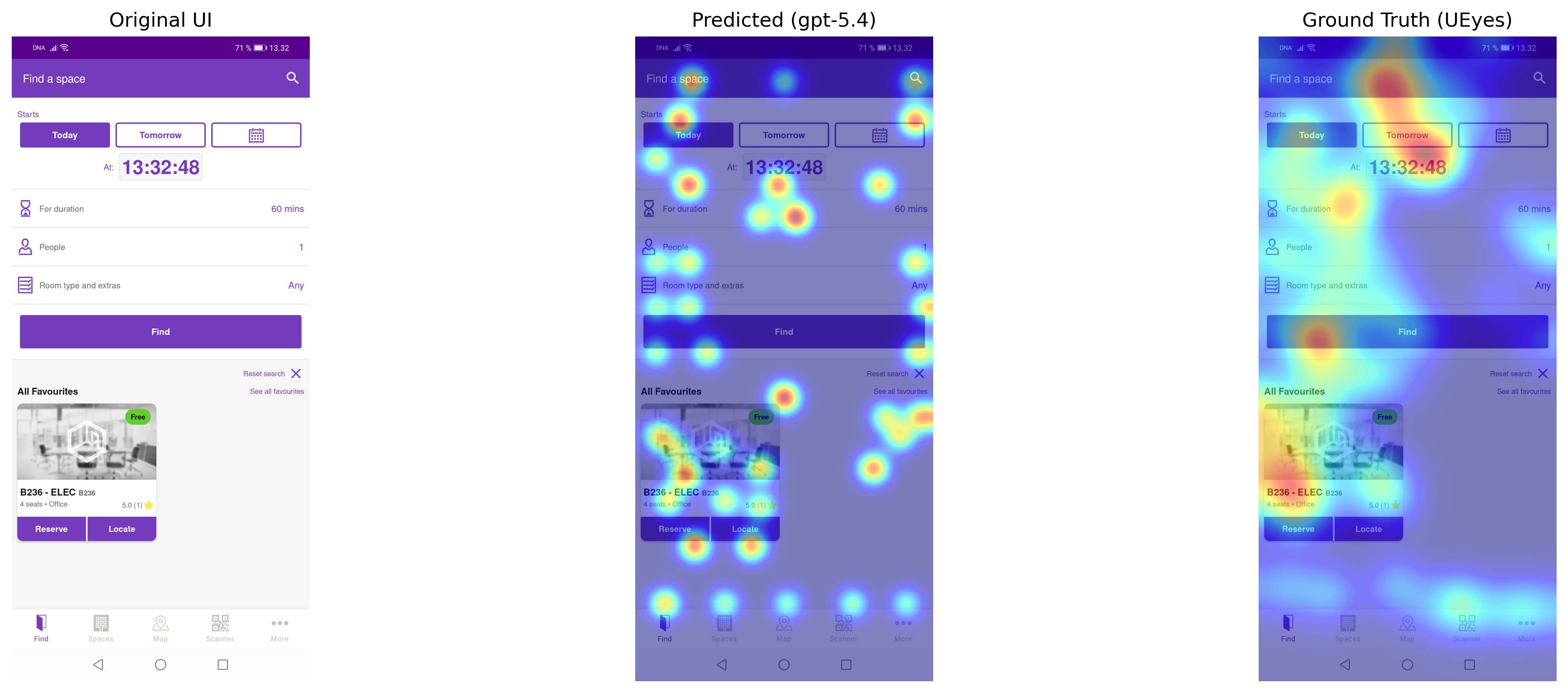
Figure 1: Best (top) and worst (bottom) saliency prediction cases for GPT-5.4 at 7s duration, contrasting high and low behavioral alignment with human gaze.
Qualitative Assessment
Qualitative inspection (Figure 1) reveals that VLMs localize well to prominent, hierarchically-organized desktop features but struggle with complex, element-rich mobile UIs. In cases with straightforward structure, predicted saliency aligns tightly with empirically-determined heatmaps; for dense or poorly-cued UIs, predictions disperse or mis-prioritize regions, likely conflating semantic with perceptual salience.
Theoretical and Practical Implications
From a theoretical perspective, the results provide direct evidence that contemporary VLMs encode implicit models of high-level UI semantics which, in longer viewing durations, correlate moderately with population-level attention patterns. However, VLMs fail to model the low-level, preattentive mechanisms (e.g., contrast, proximity) that dominate initial fixations, contrasting with the inductive biases embedded in convolutional saliency models or models fine-tuned on gaze data. The weak—and sometimes inversely correlated—performance of action-trained UI agents like UI-TARS 1.5 further decouples operational UI interaction from predictive modeling of visual attention.
Practically, strong VLMs (e.g., GPT-5.4) offer a scalable, training-free method for initial UI saliency estimation, valuable during early-stage design when large-scale eye-tracking is infeasible. Their outputs are not, however, a replacement for empirical studies if precise quantification of early attention or fine-grained gaze allocation is required. Notably, VLM predictions could support rapid layout iteration, heuristic attention optimization, or serve as proxies for formal A/B eye-tracking testing.
Limitations and Future Work
The study operates strictly in a zero-shot setting; further work should explore few-shot or instruction-finetuned VLMs, especially for approximating initial fixations. Prompt engineering and the simulation of demographic/persona-specific gaze patterns represent promising directions. Also, direct comparative benchmarks against domain-adapted CNN saliency models (e.g., UMSI, DeepGaze) on identical test sets would better quantify the performance cost of generality and zero-shot learning. Incorporation of additional attention metrics (such as NSS or AUC-Judd) may illuminate qualitative differences in region prioritization not captured by global correlation measures.
Conclusion
This paper establishes a strong quantitative and qualitative baseline for zero-shot VLM-based modeling of human visual attention on UIs. While best-in-class VLMs yield moderate alignment with human exploratory gaze, particularly on regular, hierarchical layouts, they underperform trained saliency models and do not capture early, bottom-up attention allocation. The behavioral divergence of UI-specialized interaction agents underscores that operational and attentional models cannot be conflated. Adoption of VLM-based saliency mapping should thus be viewed as a pragmatic, design-stage supplement rather than an HCI gold standard. The public release of code and predictions facilitates transparent benchmarking and future extension in both vision-language and UI-specific saliency research.