- The paper introduces a hyper-parallel decoding method that exploits conditional independence in attribute extraction tasks to generate multiple tokens simultaneously.
- It demonstrates significant improvements with up to 13.8X speedup and cost reductions on large-scale e-commerce benchmarks while maintaining output quality.
- The methodology integrates seamlessly by manipulating position IDs and attention masks, enabling scalable applications across various domains.
Introduction
The computational bottleneck imposed by autoregressive decoding in LLMs restricts efficient offline processing of large-scale text generation tasks, such as Attribute Value Extraction (AVE) in domains like e-commerce. Despite prior efforts using quantization, pruning, and distillation, these methods remain constrained by the sequential token generation dependency in standard Transformer architectures. The work "Breaking the Autoregressive Chain: Hyper-Parallel Decoding for Efficient LLM-Based Attribute Value Extraction" (2604.26209) addresses this challenge with a novel inference method—Hyper-Parallel Decoding (HPD)—which exploits the conditional independence between output sequences to achieve parallel token generation, thus substantially improving inference throughput and reducing cost while preserving quality.
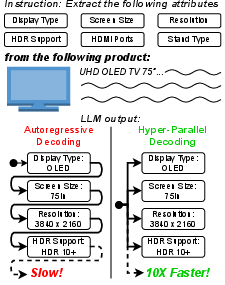
Figure 1: AVE on the e-commerce domain—HPD parallelizes value extraction to dramatically increase throughput and decrease cost compared to autoregressive decoding.
AVE entails extracting values for multiple predefined attributes from document contexts, typically resulting in independent attribute-value pairs. In e-commerce, this translates to processing massive product listings where attributes such as Display Type, Screen Size, and HDMI Ports are independently determined from noisy text data.
The fundamental insight underlying HPD is the conditional independence of attribute values given the document context. In typical autoregressive LLM inference, tokens are generated sequentially, each depending on previously generated tokens via the attention mechanism:
P(Y1:N∣p)=∏n=1NP(Vn∣p,V<n)
HPD breaks this chain, asserting:
P(Y1:N∣p)=∏n=1NP(Vn∣p)
This enables simultaneous generation of multiple values per inference step, realizing N parallel chains for N attributes, further amplified via document stacking to decode J × N tokens in parallel for J documents in a shared prompt.
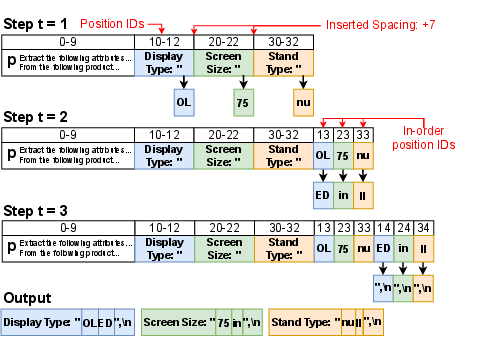
Figure 2: HPD process block diagram—multiple independent value tokens are decoded in parallel using position ID manipulation, leveraging conditional independence.
Algorithmic Details of Hyper-Parallel Decoding
HPD manipulates position IDs and causal attention masks within the prompt and skeleton output to insert gaps where value tokens are to be generated. During each inference step:
- Tokens for each attribute's value are generated in parallel.
- Tokens are appended to the sequence in memory out of logical order but ordered via position IDs.
- Causal attention is ensured by custom attention masks computed over position IDs rather than physical memory arrangement.
Fine-tuning is required to address train/test mismatch: LLMs are aligned to the HPD attention mask and skeleton input, ensuring position embeddings and causal dependencies are handled correctly during training.
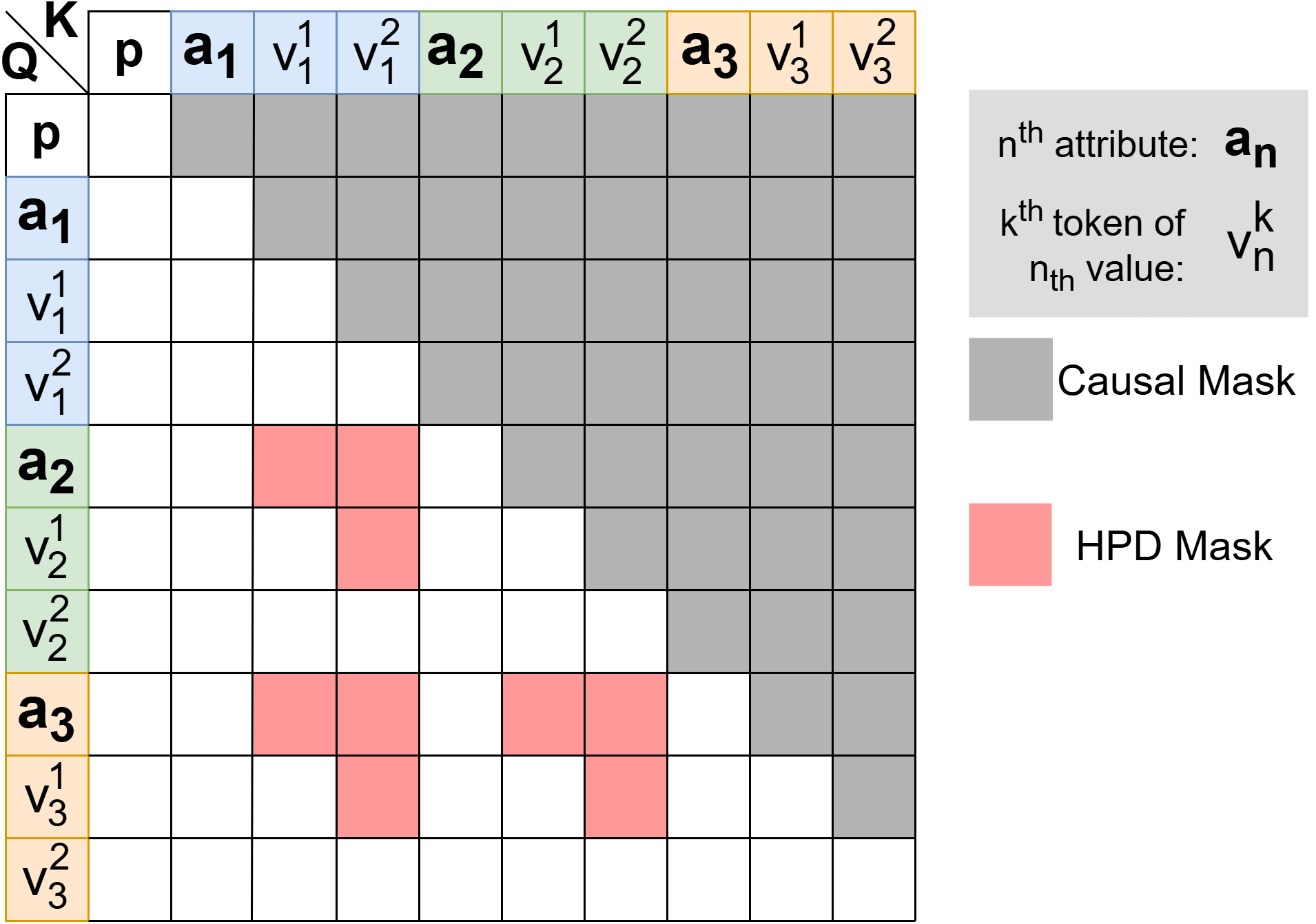
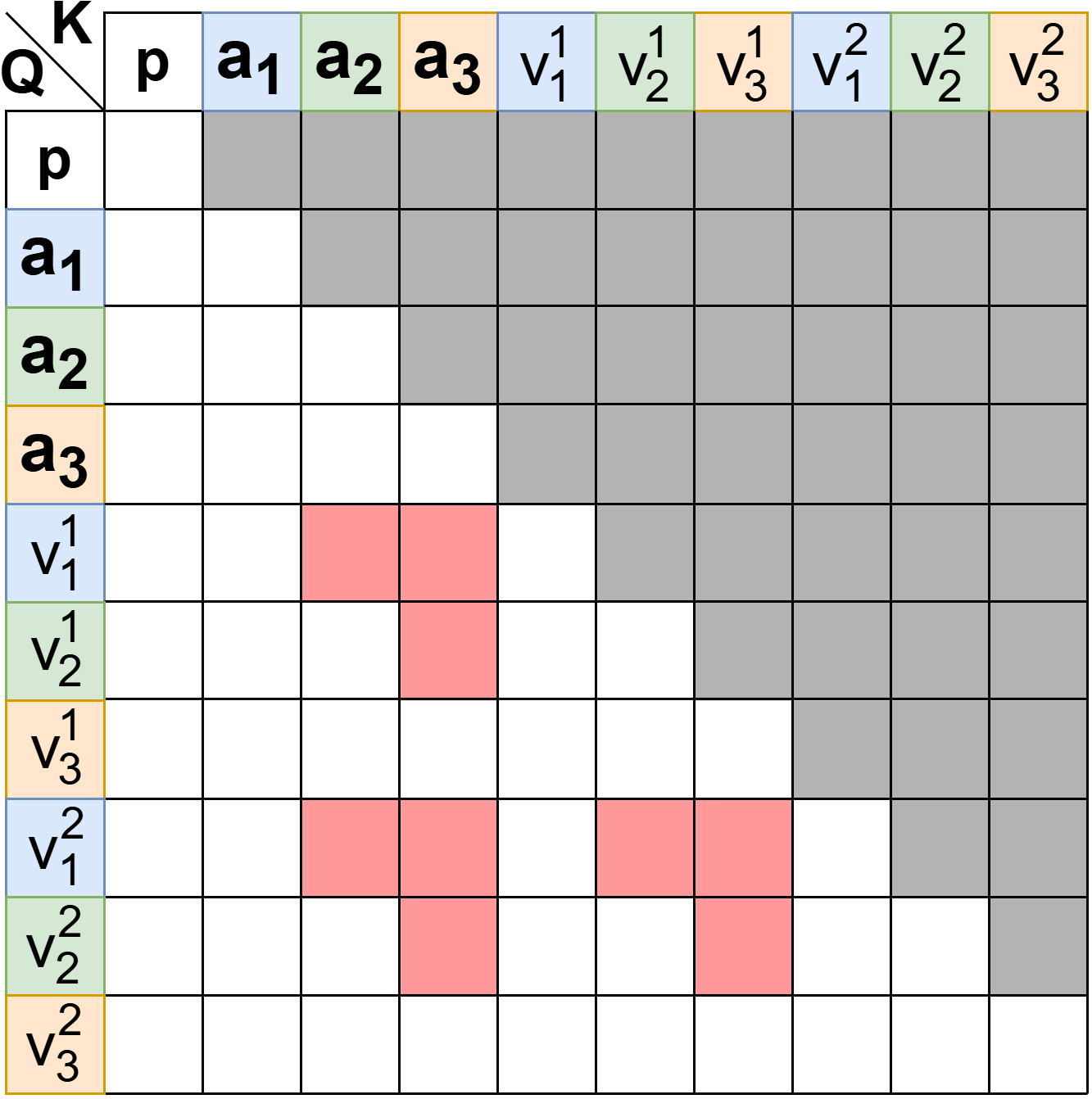
Figure 3: Attention mask adaptation—HPD mask enforces causality for parallel token generation, resolving train/test mismatch during fine-tuning.
Experimental Results
Evaluations were conducted on OA-Mine, AE110k, and a large-scale Amazon Reviews 2023 benchmark. HPD delivers substantial improvements:
- Throughput: HPD achieves up to 13.8X execution time reduction and linear throughput scaling with document stacking. On Amazon Reviews, HPD executes up to 10.78X faster than autoregressive decoding for Qwen3-32B (see Table 3).
- Cost: HPD proportionally reduces GPU/API inference costs. Extrapolated to 500M Amazon Reviews products, HPD saves approximately $597,000 compared to AR decoding and$486,000 versus GPT-4.1.
- Output Quality: F1 scores remain stable or improve—HPD models are, on average, within 0.7% lower for OA-Mine but are 4.5% and 0.7% higher for AE110k and Amazon Reviews respectively.
HPD's performance is consistent across model sizes and plug-and-play without intensive fine-tuning; document stacking proves more effective for throughput scaling than batch size increase alone.
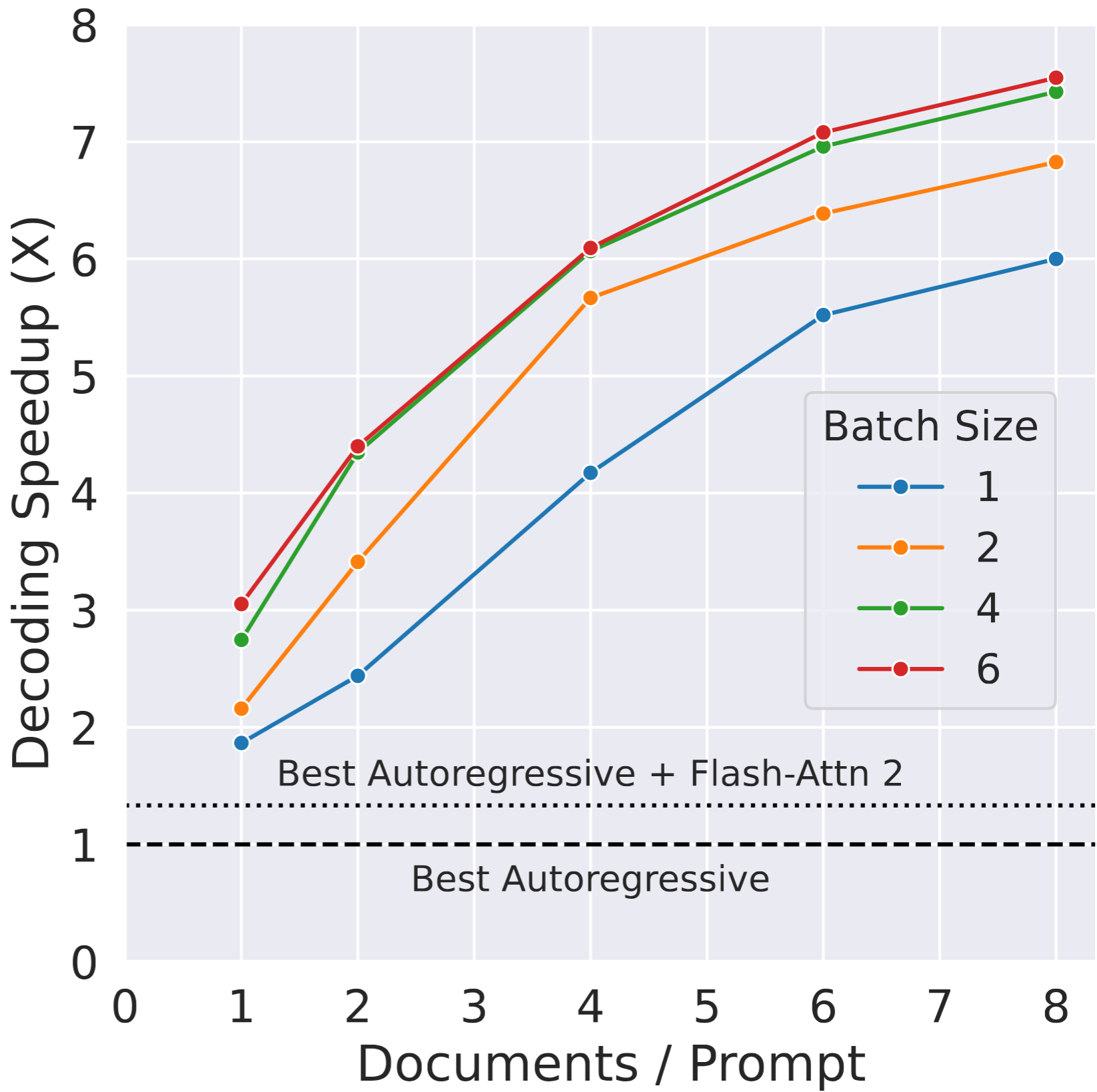
Figure 4: HPD achieves up to 7.55X product/s speedup relative to AR decoding with Qwen3-8B, maximizing throughput via document stacking and batch size.
Comparative Evaluation and Human Assessment
HPD outperforms speculative decoding, which is limited by proposal quality and verification steps. Speculative decoding achieves only 2.08X speedup, while HPD achieves 10.78X under comparable conditions. Human evaluation further corroborates HPD's quality: in blind pairwise comparisons, annotators slightly prefer HPD's outputs over both AR decoding and GPT-4.1, aligning with LLM judge scores.
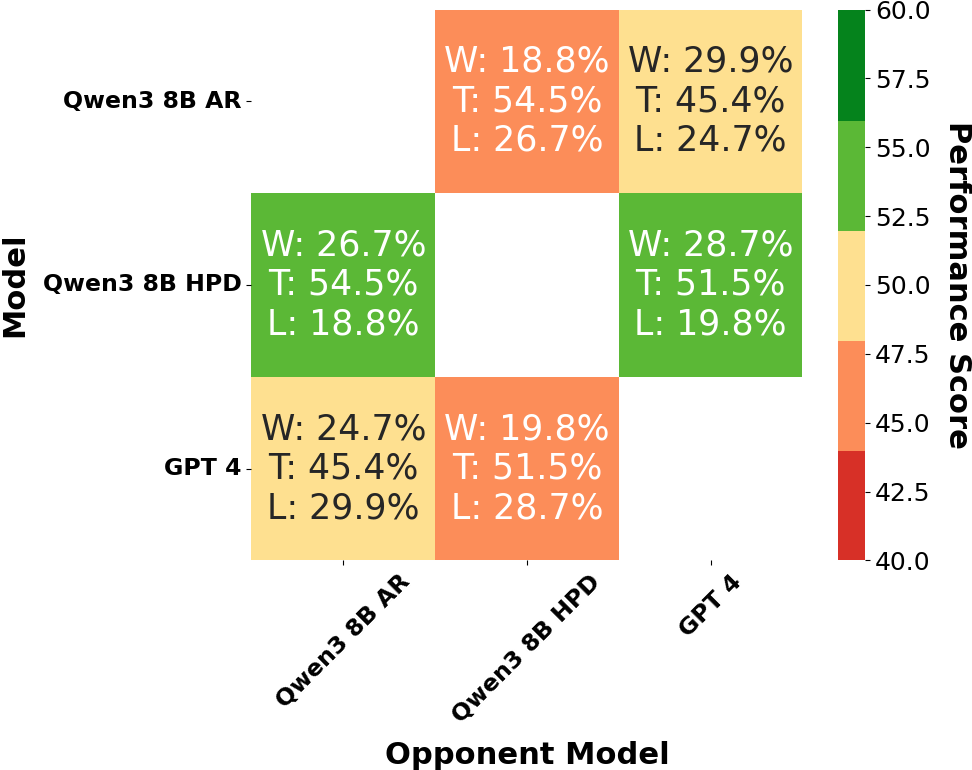
Figure 5: Human evaluation matrix—Qwen3-8B HPD surpasses standard AR and GPT-4.1 in win rate and performance score on Amazon Reviews.
Implications and Future Directions
Practically, HPD delivers a zero-compromise acceleration for AVE—compatible with quantization, distillation, and batched inference—without architectural or weight changes. Theoretical implications suggest more tasks, provided their outputs are conditionally independent, can benefit from parallel decoding. HPD generalizes beyond AVE, potentially impacting generative IE, multi-answer QA, and other multi-chain reasoning paradigms.
Advances in flexible attention mechanisms (e.g., FlexAttention) further enhance HPD's compatibility with optimized hardware. Limitations include evaluation domain restriction, GPU/model choices, and incomplete compatibility demonstrations with paged attention and MoEs. Future research should expand HPD's applicability to broader tasks, larger models, and diverse domains.
Conclusion
Hyper-Parallel Decoding decisively breaks the autoregressive constraint in LLM-based AVE, harnessing conditional output independence for parallel decoding. The method yields order-of-magnitude gains in throughput and cost savings with no quality degradation and demonstrates extensibility across LLM families and batch modes. HPD's methodology—position ID manipulation, custom attention masking, and document stacking—sets a new reference for efficiency in offline generative extraction, primed for further generalization in multi-output LLM tasks.

