- The paper systematically reviews the integration of LLMs in empirical software engineering by mapping 69 tasks across different research phases.
- It reveals that automation dominates LLM usage, with benefits in efficiency and classification offset by challenges in reproducibility and transparency.
- The study highlights the need for collaborative human-AI workflows and standardized reporting guidelines to strengthen ESE research rigor.
LLM-Assisted Empirical Software Engineering: Systematic Literature Review and Research Agenda
Introduction and Study Rationale
The proliferation and methodological complexity of empirical software engineering (ESE) has accentuated scalability and reproducibility challenges, increasingly necessitating computational assistance. LLMs, with their generalized capabilities for semantic analysis, classification, summarization, and code-related tasks, are proposed as promising adjuncts for ESE workflows. Despite extensive utilization across software engineering domains, comprehensive characterization of LLMs’ adoption, methodological integration, and impact in empirical research remains absent. This systematic literature review investigates the application patterns, supported tasks and phases, operationalization strategies, reported benefits and limitations, and transparency in reporting of LLM-assisted empirical studies across leading software engineering venues from 2020–2025.
Methodology and Corpus Construction
A rigorous multi-stage SLR protocol was employed, leveraging targeted proceedings from 12 CORE A*/A venues and filtering 8,641 papers using strategic full-text keyword search. Manual screening refined the corpus to 50 primary studies describing substantive ESE research use of LLMs, excluding studies focused only on software artifacts or technical benchmarks.
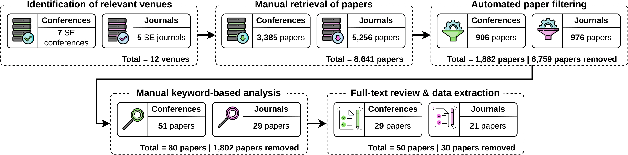
Figure 1: Study selection process detailing the curation pipeline from initial corpus to final included studies.
Data extraction captured fine-grained task descriptions, LLM model characteristics, prompt design, methodological settings, benefits/limitations, and reproducibility indicators, enabling both quantitative task mapping and qualitative thematic synthesis.
Empirical Task Landscape and Functional Roles
Analysis revealed 69 distinct LLM-supported tasks, with a strong orientation toward automated classification, filtering, and evaluation activities. These tasks cluster around roles such as semantic classifier, criteria-based screener, and evaluator (LLM-as-a-Judge), underlining the tendency to deploy LLMs for structured, decision-oriented functions. Generative operations (synthetic data generation, content transformation), extraction, and relational analysis are less prevalent, indicating a gap in higher-order applications such as reasoning, hypothesis generation, or synthesis.
Lifecycle Distribution and Operationalization Patterns
Distribution analysis mapped supported tasks to standardized empirical phases—planning/design, data collection, processing, analysis/synthesis, reporting—across controlled experiments, MSR, surveys, and secondary studies. LLM integration is concentrated in data processing and analysis, especially within MSR and controlled experiments, while support in planning, reporting, or human-centric qualitative tasks remains limited.
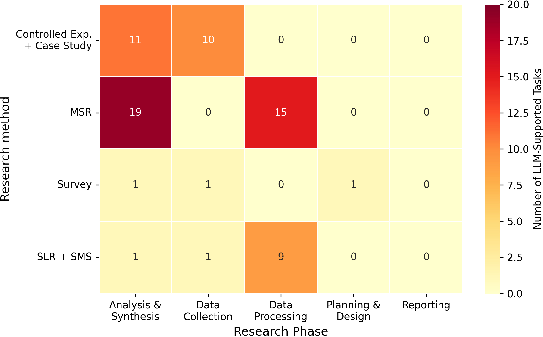
Figure 2: Heatmap illustrating the distribution of the identified LLM-assisted tasks across research methods and stages.
Detailed examination of operationalization reveals automation as the predominant integration paradigm. Forty-two out of 69 tasks are executed with minimal human oversight, often replacing manual effort in labeling, filtering, or evaluation. Augmentation and evaluation are present but less dominant; genuine decision-support, where LLMs assist rather than supplant human decisions, is rare.
Benefits and Limitations: Thematic Synthesis
Reported benefits are organized into four higher-order themes: analytical performance (semantic understanding, classification, extraction), efficiency/scalability, human-level evaluation quality, and workflow/methodological enhancement via human-AI collaboration. These are predominantly cited for tasks involving classification, screening, and data extraction.
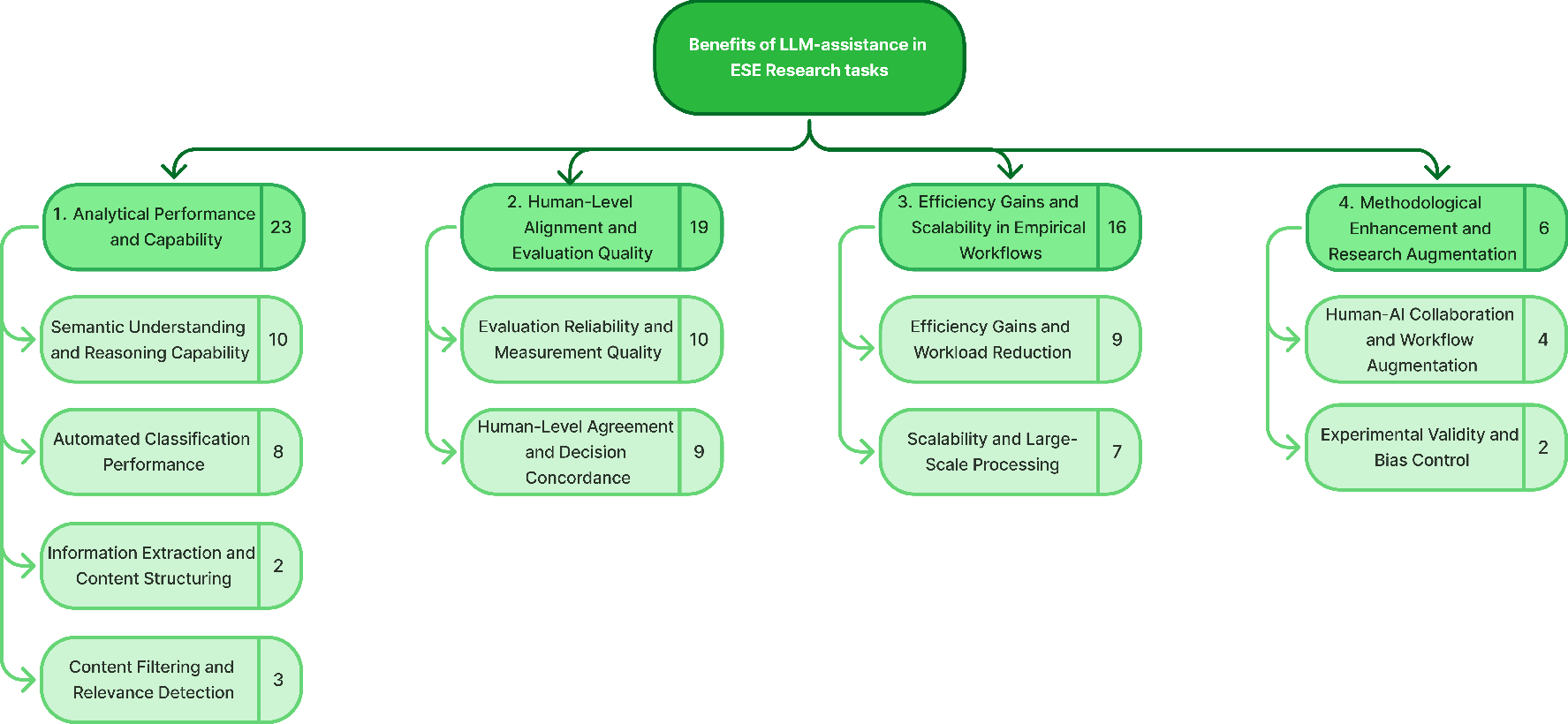
Figure 3: Thematic map of LLM benefits in software engineering research.
Conversely, limitations cluster around cognitive/knowledge gaps (hallucinations, domain errors), input sensitivity/prompt dependency, technical constraints (token limits, computational burden), reproducibility challenges (inconsistency, variability), and ethical/trust issues. Notably, hallucinations and context dependency directly undermine many claimed benefits.
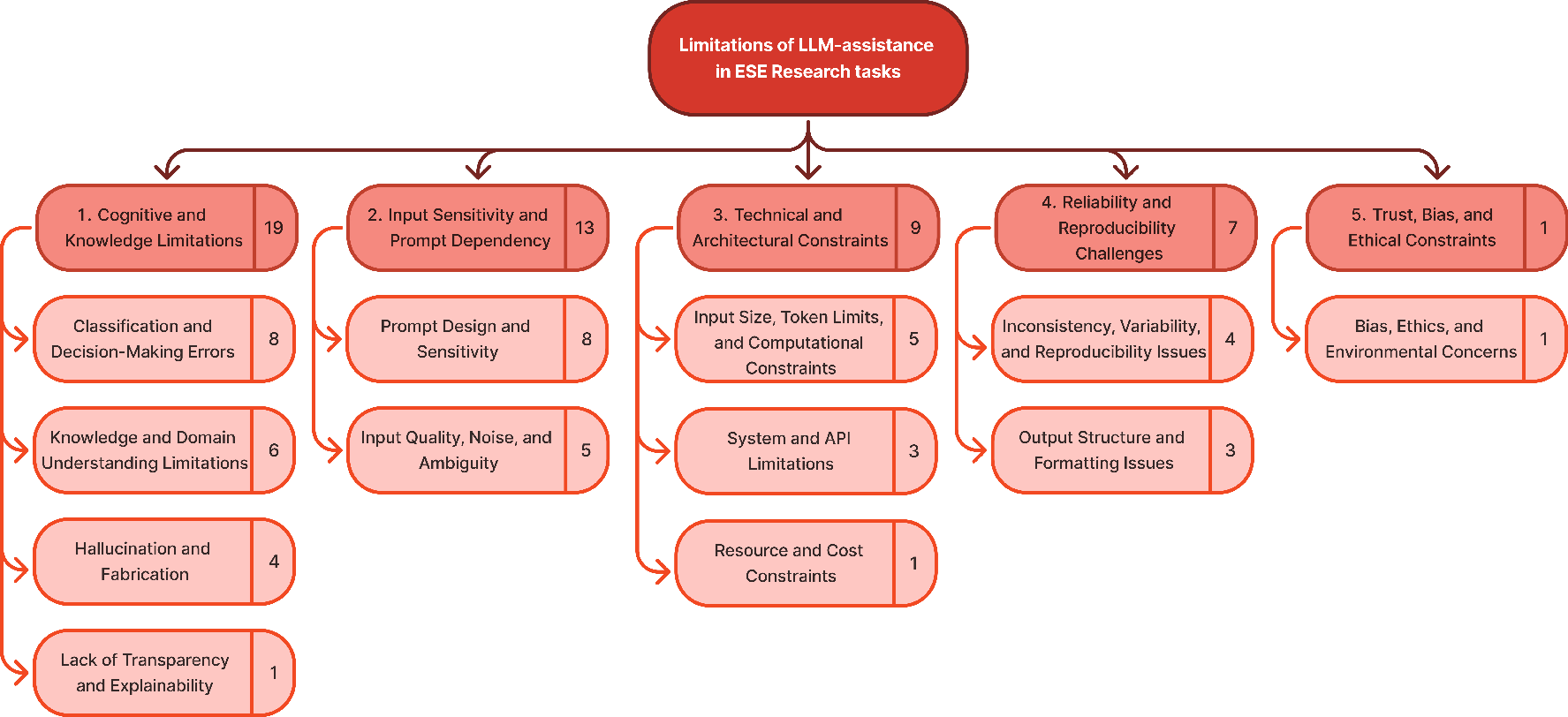
Figure 4: Thematic map of LLM limitations in software engineering research.
An observed contradiction is that efficiency, scalability, and human-level evaluation—often assumed as motivating advantages—are directly endangered by reproducibility lapses, prompt sensitivity, and model opacity.
Transparency and Reproducibility Assessment
Transparency in reporting remains suboptimal. While model versioning and LLM identification are typically disclosed, key methodological variables—prompt design, configuration, experimental parameters, human validation protocols—are inconsistently documented. Intersection analysis using UpSet plots indicates that comprehensive reproducibility practices are uncommon.
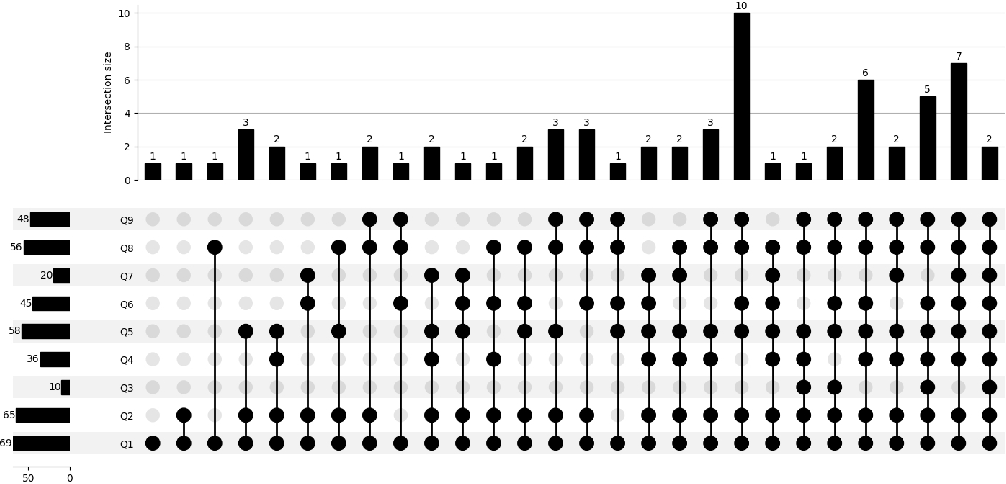
Figure 5: UpSet plot showing the frequency and co-occurrence of transparency and reproducibility reporting practices (Q1–Q9) across identified LLM-assisted ESE research tasks.
Given the dominance of automation, this reporting shortfall risks compromising not only interpretability but also the reliability of empirical findings—a threat amplified by ecosystem bias toward proprietary models (e.g., ChatGPT).
Practical and Theoretical Implications
Empirically, LLMs are shaping ESE by enabling scalable automation of structured analytic steps, but not yet supporting deeper epistemic integration such as hypothesis formation or context-sensitive synthesis. Theoretical implications include a capability-risk alignment: LLMs are preferentially adopted in tasks where their limitations are manageable and errors detectable. This constrains their utility to bounded phases, with minimal penetration into interpretive or collaborative research activities.
Practically, incomplete transparency hampers reproducibility and threatens methodological rigor. Standardized reporting guidelines (e.g., [baltesllm_guidelines], [wagner2025guidelines]) are urgently needed and currently under-adopted. Ecosystem concentration on proprietary LLMs further restricts generalizability and comparative benchmarking.
Speculation: Future Directions in AI-Enhanced Empirical Software Engineering
Advancing LLM integration in ESE requires:
- Diversification of tasks, including support for reasoning, synthesis, planning, and reporting;
- Transition from automation-centered to human-AI collaborative workflows, prioritizing decision support and iterative, interactive research pipelines;
- Adoption of agentic AI (multi-step orchestration, external tool use) for complex empirical workflows;
- Rigorous evaluation of human-LLM interaction, trust calibration, and bias mitigation;
- Universal transparency standards spanning prompt design, configuration documentation, and validation procedures;
- Broad empirical benchmarking across open and proprietary LLMs.
The evolution toward agentic and discovery-oriented workflows promises to reshape the epistemological landscape of ESE, enabling hypothesis generation, exploratory analysis, and collaborative synthesis with AI models as methodologically integral partners rather than mere automation tools.
Conclusion
LLMs are increasingly embedded within ESE research, chiefly operationalized as automated classifiers, screeners, and evaluators in data-intensive tasks. Methodological rigor and reproducibility face ongoing challenges due to incomplete transparency, model concentration, and prompt sensitivity. Substantial research gaps remain in human-AI collaboration, qualitative decision support, reporting standardization, and model diversity. The translation of LLMs from task executors to epistemic collaborators represents a critical frontier for empirical software engineering, demanding both methodological innovation and robust transparency protocols (2604.26192).

